 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Control with Coarse-to-fine Reinforcement Learning
Jul 10, 2024Despite recent advances in improving the sample-efficiency of reinforcement learning (RL) algorithms, designing an RL algorithm that can be practically deployed in real-world environments remains a challenge. In this paper, we present Coarse-to-fine Reinforcement Learning (CRL), a framework that trains RL agents to zoom-into a continuous action space in a coarse-to-fine manner, enabling the use of stable, sample-efficient value-based RL algorithms for fine-grained continuous control tasks. Our key idea is to train agents that output actions by iterating the procedure of (i) discretizing the continuous action space into multiple intervals and (ii) selecting the interval with the highest Q-value to further discretize at the next level. We then introduce a concrete, value-based algorithm within the CRL framework called Coarse-to-fine Q-Network (CQN). Our experiments demonstrate that CQN significantly outperforms RL and behavior cloning baselines on 20 sparsely-rewarded RLBench manipulation tasks with a modest number of environment interactions and expert demonstrations. We also show that CQN robustly learns to solve real-world manipulation tasks within a few minutes of online training.
Render and Diffuse: Aligning Image and Action Spaces for Diffusion-based Behaviour Cloning
May 28, 2024In the field of Robot Learning, the complex mapping between high-dimensional observations such as RGB images and low-level robotic actions, two inherently very different spaces, constitutes a complex learning problem, especially with limited amounts of data. In this work, we introduce Render and Diffuse (R&D) a method that unifies low-level robot actions and RGB observations within the image space using virtual renders of the 3D model of the robot. Using this joint observation-action representation it computes low-level robot actions using a learnt diffusion process that iteratively updates the virtual renders of the robot. This space unification simplifies the learning problem and introduces inductive biases that are crucial for sample efficiency and spatial generalisation. We thoroughly evaluate several variants of R&D in simulation and showcase their applicability on six everyday tasks in the real world. Our results show that R&D exhibits strong spatial generalisation capabilities and is more sample efficient than more common image-to-action methods.
The Power of the Senses: Generalizable Manipulation from Vision and Touch through Masked Multimodal Learning
Nov 02, 2023



Humans rely on the synergy of their senses for most essential tasks. For tasks requiring object manipulation, we seamlessly and effectively exploit the complementarity of our senses of vision and touch. This paper draws inspiration from such capabilities and aims to find a systematic approach to fuse visual and tactile information in a reinforcement learning setting. We propose Masked Multimodal Learning (M3L), which jointly learns a policy and visual-tactile representations based on masked autoencoding. The representations jointly learned from vision and touch improve sample efficiency, and unlock generalization capabilities beyond those achievable through each of the senses separately. Remarkably, representations learned in a multimodal setting also benefit vision-only policies at test time. We evaluate M3L on three simulated environments with both visual and tactile observations: robotic insertion, door opening, and dexterous in-hand manipulation, demonstrating the benefits of learning a multimodal policy. Code and videos of the experiments are available at https://sferrazza.cc/m3l_site.
Guide Your Agent with Adaptive Multimodal Rewards
Sep 19, 2023Developing an agent capable of adapting to unseen environments remains a difficult challenge in imitation learning. In this work, we present Adaptive Return-conditioned Policy (ARP), an efficient framework designed to enhance the agent's generalization ability using natural language task descriptions and pre-trained multimodal encoders. Our key idea is to calculate a similarity between visual observations and natural language instructions in the pre-trained multimodal embedding space (such as CLIP) and use it as a reward signal. We then train a return-conditioned policy using expert demonstrations labeled with multimodal rewards. Because the multimodal rewards provide adaptive signals at each timestep, our ARP effectively mitigates the goal misgeneralization. This results in superior generalization performances even when faced with unseen text instructions, compared to existing text-conditioned policies. To improve the quality of rewards, we also introduce a fine-tuning method for pre-trained multimodal encoders, further enhancing the performance. Video demonstrations and source code are available on the project website: https://sites.google.com/view/2023arp.
Language Reward Modulation for Pretraining Reinforcement Learning
Aug 23, 2023Using learned reward functions (LRFs) as a means to solve sparse-reward reinforcement learning (RL) tasks has yielded some steady progress in task-complexity through the years. In this work, we question whether today's LRFs are best-suited as a direct replacement for task rewards. Instead, we propose leveraging the capabilities of LRFs as a pretraining signal for RL. Concretely, we propose $\textbf{LA}$nguage Reward $\textbf{M}$odulated $\textbf{P}$retraining (LAMP) which leverages the zero-shot capabilities of Vision-Language Models (VLMs) as a $\textit{pretraining}$ utility for RL as opposed to a downstream task reward. LAMP uses a frozen, pretrained VLM to scalably generate noisy, albeit shaped exploration rewards by computing the contrastive alignment between a highly diverse collection of language instructions and the image observations of an agent in its pretraining environment. LAMP optimizes these rewards in conjunction with standard novelty-seeking exploration rewards with reinforcement learning to acquire a language-conditioned, pretrained policy. Our VLM pretraining approach, which is a departure from previous attempts to use LRFs, can warmstart sample-efficient learning on robot manipulation tasks in RLBench.
Accelerating Reinforcement Learning with Value-Conditional State Entropy Exploration
May 31, 2023A promising technique for exploration is to maximize the entropy of visited state distribution, i.e., state entropy, by encouraging uniform coverage of visited state space. While it has been effective for an unsupervised setup, it tends to struggle in a supervised setup with a task reward, where an agent prefers to visit high-value states to exploit the task reward. Such a preference can cause an imbalance between the distributions of high-value states and low-value states, which biases exploration towards low-value state regions as a result of the state entropy increasing when the distribution becomes more uniform. This issue is exacerbated when high-value states are narrowly distributed within the state space, making it difficult for the agent to complete the tasks. In this paper, we present a novel exploration technique that maximizes the value-conditional state entropy, which separately estimates the state entropies that are conditioned on the value estimates of each state, then maximizes their average. By only considering the visited states with similar value estimates for computing the intrinsic bonus, our method prevents the distribution of low-value states from affecting exploration around high-value states, and vice versa. We demonstrate that the proposed alternative to the state entropy baseline significantly accelerates various reinforcement learning algorithms across a variety of tasks within MiniGrid, DeepMind Control Suite, and Meta-World benchmarks. Source code is available at https://sites.google.com/view/rl-vcse.
Imitating Graph-Based Planning with Goal-Conditioned Policies
Mar 20, 2023Recently, graph-based planning algorithms have gained much attention to solve goal-conditioned reinforcement learning (RL) tasks: they provide a sequence of subgoals to reach the target-goal, and the agents learn to execute subgoal-conditioned policies. However, the sample-efficiency of such RL schemes still remains a challenge, particularly for long-horizon tasks. To address this issue, we present a simple yet effective self-imitation scheme which distills a subgoal-conditioned policy into the target-goal-conditioned policy. Our intuition here is that to reach a target-goal, an agent should pass through a subgoal, so target-goal- and subgoal- conditioned policies should be similar to each other. We also propose a novel scheme of stochastically skipping executed subgoals in a planned path, which further improves performance. Unlike prior methods that only utilize graph-based planning in an execution phase, our method transfers knowledge from a planner along with a graph into policy learning. We empirically show that our method can significantly boost the sample-efficiency of the existing goal-conditioned RL methods under various long-horizon control tasks.
Multi-View Masked World Models for Visual Robotic Manipulation
Feb 05, 2023



Visual robotic manipulation research and applications often use multiple cameras, or views, to better perceive the world. How else can we utilize the richness of multi-view data? In this paper, we investigate how to learn good representations with multi-view data and utilize them for visual robotic manipulation. Specifically, we train a multi-view masked autoencoder which reconstructs pixels of randomly masked viewpoints and then learn a world model operating on the representations from the autoencoder. We demonstrate the effectiveness of our method in a range of scenarios, including multi-view control and single-view control with auxiliary cameras for representation learning. We also show that the multi-view masked autoencoder trained with multiple randomized viewpoints enables training a policy with strong viewpoint randomization and transferring the policy to solve real-robot tasks without camera calibration and an adaptation procedure. Videos demonstrations in real-world experiments and source code are available at the project website: https://sites.google.com/view/mv-mwm.
HARP: Autoregressive Latent Video Prediction with High-Fidelity Image Generator
Sep 15, 2022
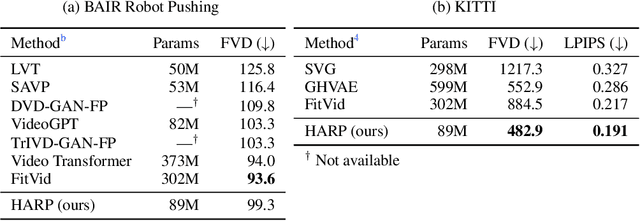
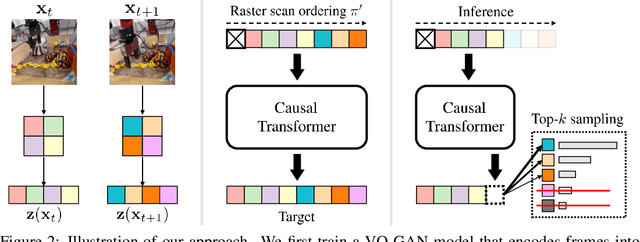
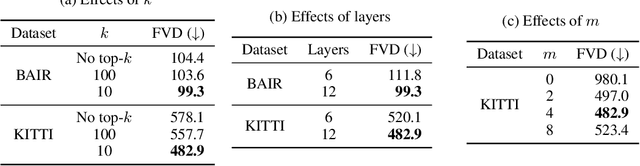
Video prediction is an important yet challenging problem; burdened with the tasks of generating future frames and learning environment dynamics. Recently, autoregressive latent video models have proved to be a powerful video prediction tool, by separating the video prediction into two sub-problems: pre-training an image generator model, followed by learning an autoregressive prediction model in the latent space of the image generator. However, successfully generating high-fidelity and high-resolution videos has yet to be seen. In this work, we investigate how to train an autoregressive latent video prediction model capable of predicting high-fidelity future frames with minimal modification to existing models, and produce high-resolution (256x256) videos. Specifically, we scale up prior models by employing a high-fidelity image generator (VQ-GAN) with a causal transformer model, and introduce additional techniques of top-k sampling and data augmentation to further improve video prediction quality. Despite the simplicity, the proposed method achieves competitive performance to state-of-the-art approaches on standard video prediction benchmarks with fewer parameters, and enables high-resolution video prediction on complex and large-scale datasets. Videos are available at https://sites.google.com/view/harp-videos/home.
Masked World Models for Visual Control
Jun 28, 2022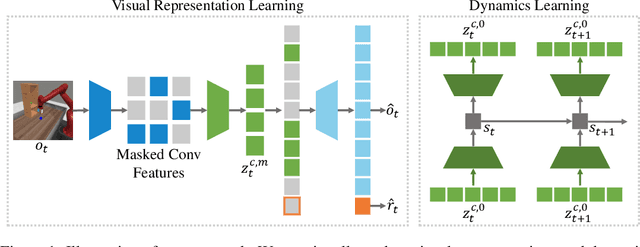
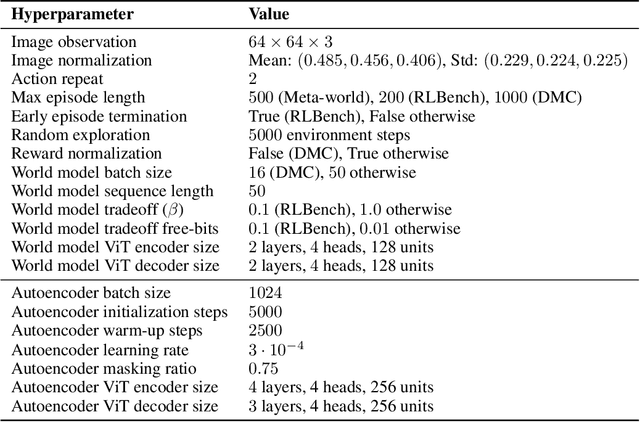

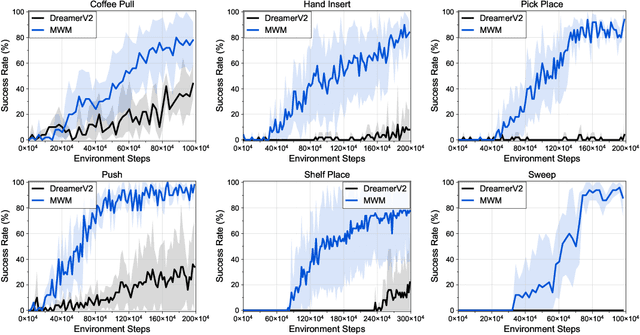
Visual model-based reinforcement learning (RL) has the potential to enable sample-efficient robot learning from visual observations. Yet the current approaches typically train a single model end-to-end for learning both visual representations and dynamics, making it difficult to accurately model the interaction between robots and small objects. In this work, we introduce a visual model-based RL framework that decouples visual representation learning and dynamics learning. Specifically, we train an autoencoder with convolutional layers and vision transformers (ViT) to reconstruct pixels given masked convolutional features, and learn a latent dynamics model that operates on the representations from the autoencoder. Moreover, to encode task-relevant information, we introduce an auxiliary reward prediction objective for the autoencoder. We continually update both autoencoder and dynamics model using online samples collected from environment interaction. We demonstrate that our decoupling approach achieves state-of-the-art performance on a variety of visual robotic tasks from Meta-world and RLBench, e.g., we achieve 81.7% success rate on 50 visual robotic manipulation tasks from Meta-world, while the baseline achieves 67.9%. Code is available on the project website: https://sites.google.com/view/mwm-rl.