 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Catastrophic Interference in Atari 2600 Games
Feb 28, 2020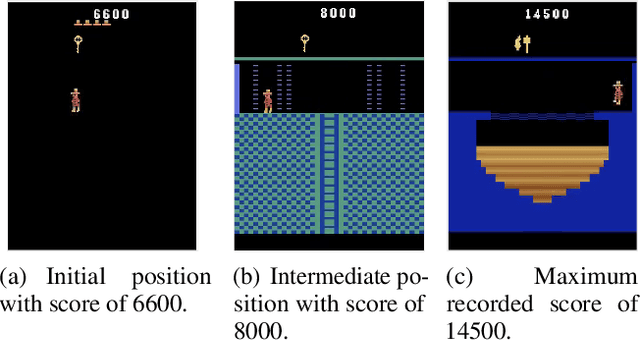
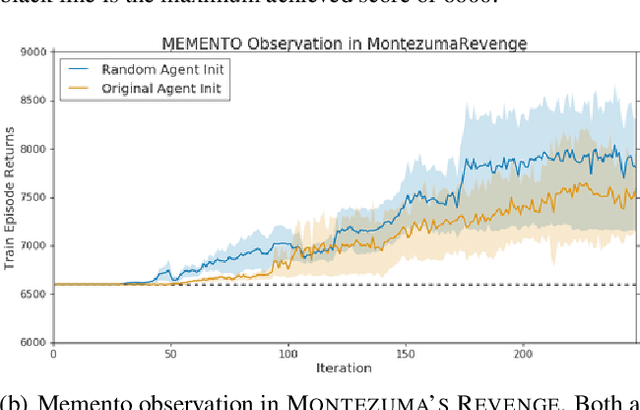
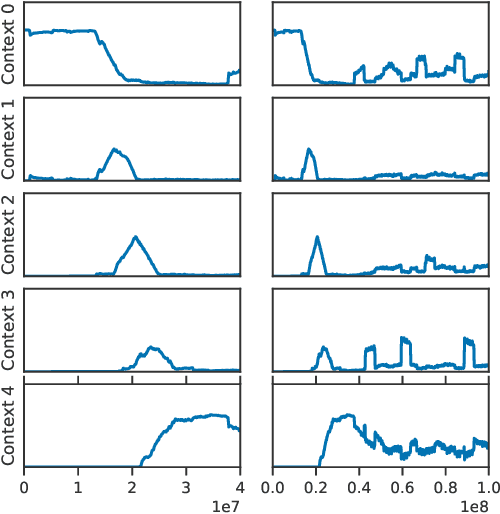
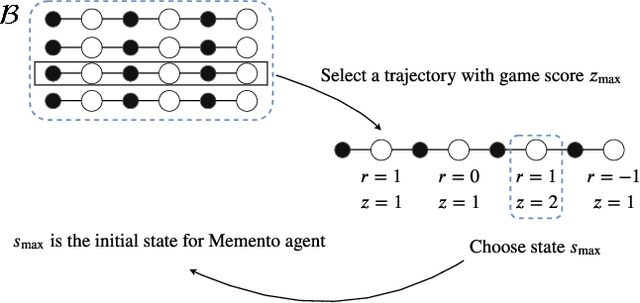
Model-free deep reinforcement learning algorithms are troubled with poor sample efficiency -- learning reliable policies generally requires a vast amount of interaction with the environment. One hypothesis is that catastrophic interference between various segments within the environment is an issue. In this paper, we perform a large-scale empirical study on the presence of catastrophic interference in the Arcade Learning Environment and find that learning particular game segments frequently degrades performance on previously learned segments. In what we term the Memento observation, we show that an identically parameterized agent spawned from a state where the original agent plateaued, reliably makes further progress. This phenomenon is general -- we find consistent performance boosts across architectures, learning algorithms and environments. Our results indicate that eliminating catastrophic interference can contribute towards improved performance and data efficiency of deep reinforcement learning algorithms.
Neural Bayes: A Generic Parameterization Method for Unsupervised Representation Learning
Feb 20, 2020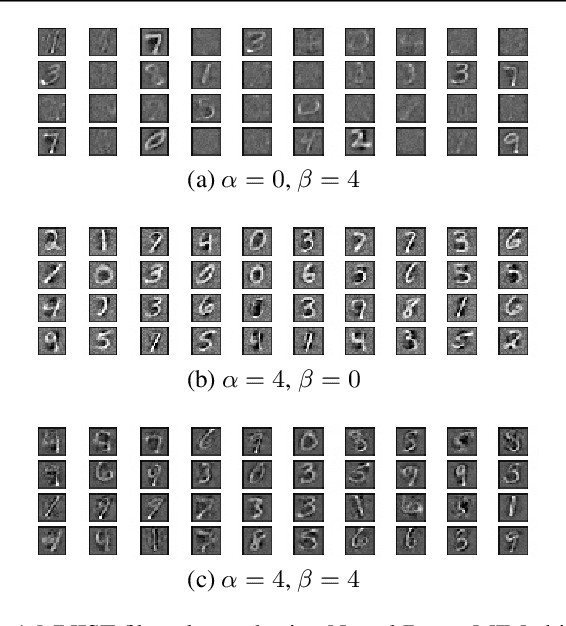
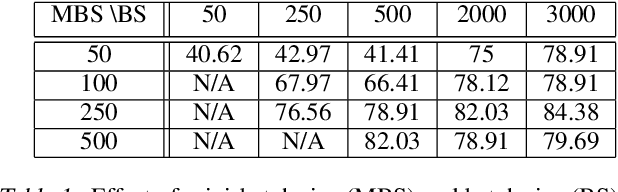
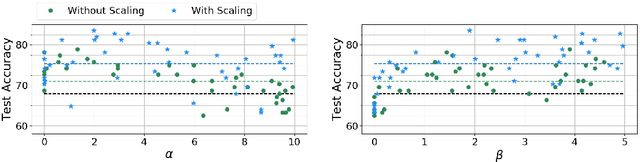
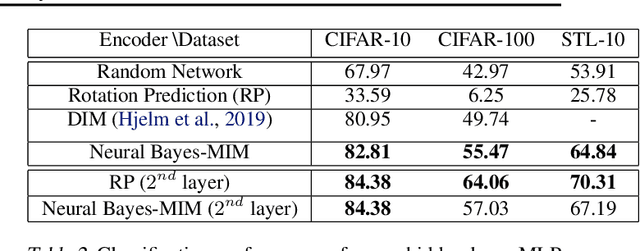
We introduce a parameterization method called Neural Bayes which allows computing statistical quantities that are in general difficult to compute and opens avenues for formulating new objectives for unsupervised representation learning. Specifically, given an observed random variable $\mathbf{x}$ and a latent discrete variable $z$, we can express $p(\mathbf{x}|z)$, $p(z|\mathbf{x})$ and $p(z)$ in closed form in terms of a sufficiently expressive function (Eg. neural network) using our parameterization without restricting the class of these distributions. To demonstrate its usefulness, we develop two independent use cases for this parameterization: 1. Mutual Information Maximization (MIM): MIM has become a popular means for self-supervised representation learning. Neural Bayes allows us to compute mutual information between observed random variables $\mathbf{x}$ and latent discrete random variables $z$ in closed form. We use this for learning image representations and show its usefulness on downstream classification tasks. 2. Disjoint Manifold Labeling: Neural Bayes allows us to formulate an objective which can optimally label samples from disjoint manifolds present in the support of a continuous distribution. This can be seen as a specific form of clustering where each disjoint manifold in the support is a separate cluster. We design clustering tasks that obey this formulation and empirically show that the model optimally labels the disjoint manifolds. Our code is available at \url{https://github.com/salesforce/NeuralBayes}
HighRes-net: Recursive Fusion for Multi-Frame Super-Resolution of Satellite Imagery
Feb 15, 2020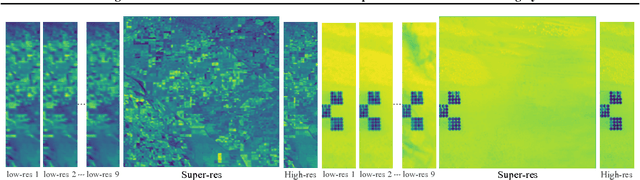
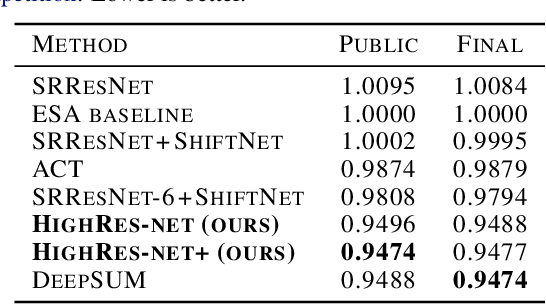
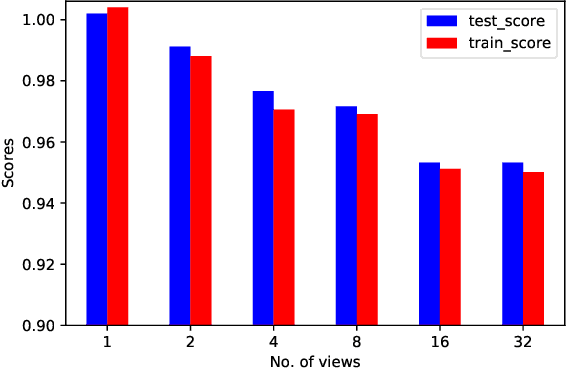
Generative deep learning has sparked a new wave of Super-Resolution (SR) algorithms that enhance single images with impressive aesthetic results, albeit with imaginary details. Multi-frame Super-Resolution (MFSR) offers a more grounded approach to the ill-posed problem, by conditioning on multiple low-resolution views. This is important for satellite monitoring of human impact on the planet -- from deforestation, to human rights violations -- that depend on reliable imagery. To this end, we present HighRes-net, the first deep learning approach to MFSR that learns its sub-tasks in an end-to-end fashion: (i) co-registration, (ii) fusion, (iii) up-sampling, and (iv) registration-at-the-loss. Co-registration of low-resolution views is learned implicitly through a reference-frame channel, with no explicit registration mechanism. We learn a global fusion operator that is applied recursively on an arbitrary number of low-resolution pairs. We introduce a registered loss, by learning to align the SR output to a ground-truth through ShiftNet. We show that by learning deep representations of multiple views, we can super-resolve low-resolution signals and enhance Earth Observation data at scale. Our approach recently topped the European Space Agency's MFSR competition on real-world satellite imagery.
Parameterizing Branch-and-Bound Search Trees to Learn Branching Policies
Feb 12, 2020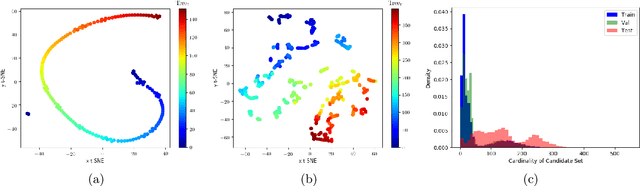

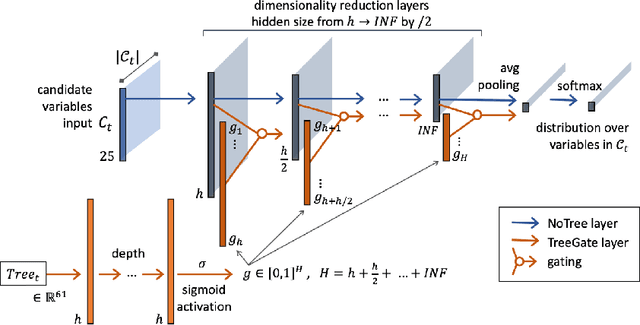

Branch and Bound (B&B) is the exact tree search method typically used to solve Mixed-Integer Linear Programming problems (MILPs). Learning branching policies for MILP has become an active research area, with most works proposing to imitate the strong branching rule and specialize it to distinct classes of problems. We aim instead at learning a policy that generalizes across heterogeneous MILPs: our main hypothesis is that parameterizing the state of the B&B search tree can significantly aid this type of generalization. We propose a novel imitation learning framework, and introduce new input features and architectures to represent branching. Experiments on MILP benchmark instances clearly show the advantages of incorporating to a baseline model an explicit parameterization of the state of the search tree to modulate the branching decisions. The resulting policy reaches higher accuracy than the baseline, and on average explores smaller B&B trees, while effectively allowing generalization to generic unseen instances.
BitPruning: Learning Bitlengths for Aggressive and Accurate Quantization
Feb 08, 2020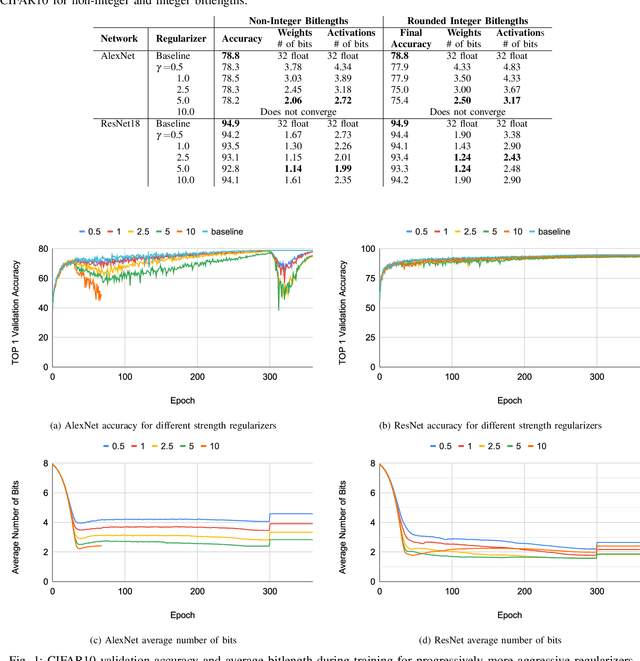

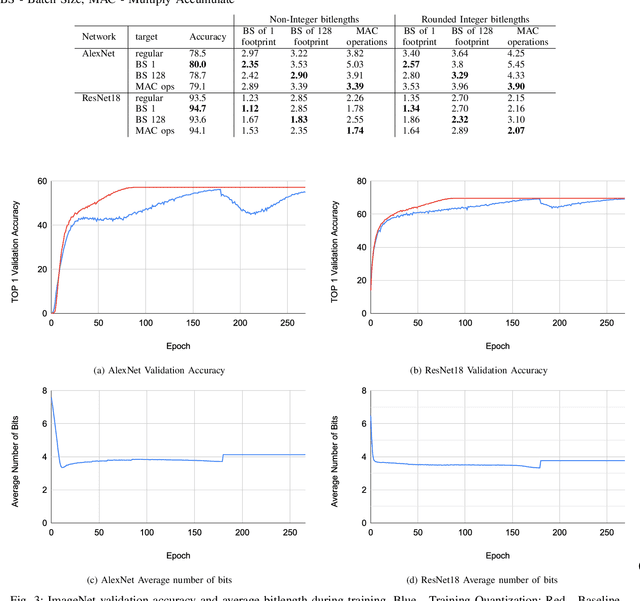
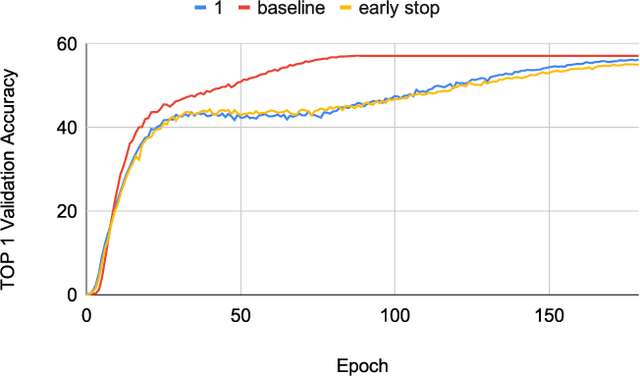
Neural networks have demonstrably achieved state-of-the art accuracy using low-bitlength integer quantization, yielding both execution time and energy benefits on existing hardware designs that support short bitlengths. However, the question of finding the minimum bitlength for a desired accuracy remains open. We introduce a training method for minimizing inference bitlength at any granularity while maintaining accuracy. Furthermore, we propose a regularizer that penalizes large bitlength representations throughout the architecture and show how it can be modified to minimize other quantifiable criteria, such as number of operations or memory footprint. We demonstrate that our method learns thrifty representations while maintaining accuracy. With ImageNet, the method produces an average per layer bitlength of 4.13 and 3.76 bits on AlexNet and ResNet18 respectively, remaining within 2.0% and 0.5% of the baseline TOP-1 accuracy.
Meta-learning framework with applications to zero-shot time-series forecasting
Feb 07, 2020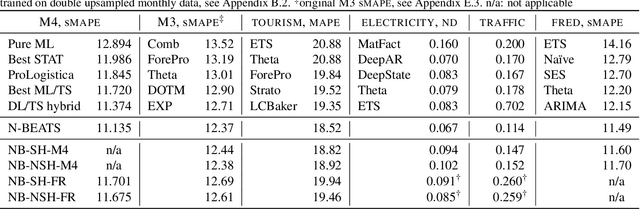
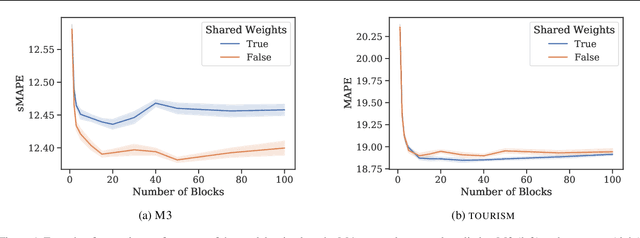
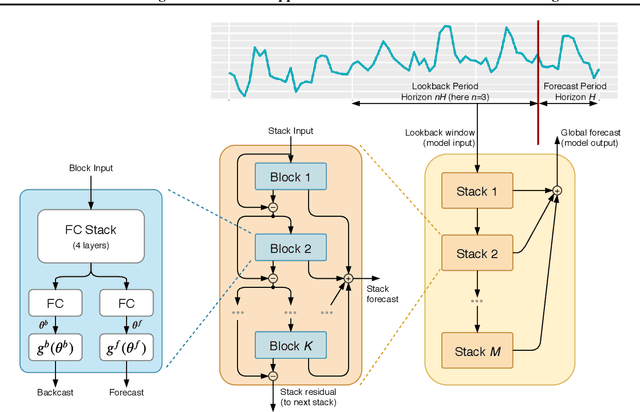
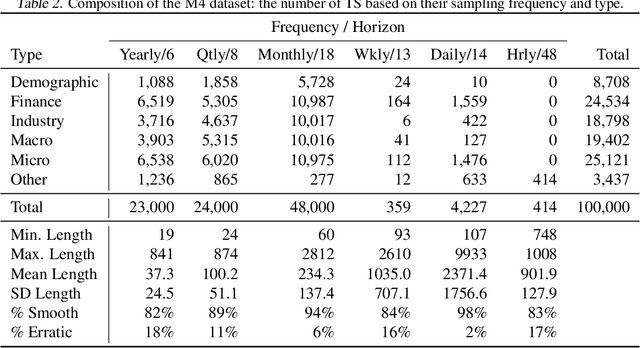
Can meta-learning discover generic ways of processing time-series (TS) from a diverse dataset so as to greatly improve generalization on new TS coming from different datasets? This work provides positive evidence to demonstrate this using a broad meta-learning framework which we show subsumes many existing meta-learning algorithms as specific cases. We further identify via theoretical analysis the meta-learning adaptation mechanisms within N-BEATS, a recent neural TS forecasting model. Our meta-learning theory predicts that N-BEATS iteratively generates a subset of its task-specific parameters based on a given TS input, thus gradually expanding the expressive power of the architecture on-the-fly. Our empirical results emphasize the importance of meta-learning for successful zero-shot forecasting to new sources of TS, supporting the claim that it is viable to train a neural network on a source TS dataset and deploy it on a different target TS dataset without retraining, resulting in performance that is at least as good as that of state-of-practice univariate forecasting models.
Combating False Negatives in Adversarial Imitation Learning
Feb 02, 2020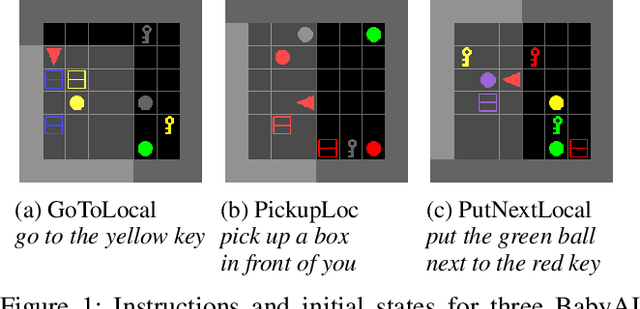

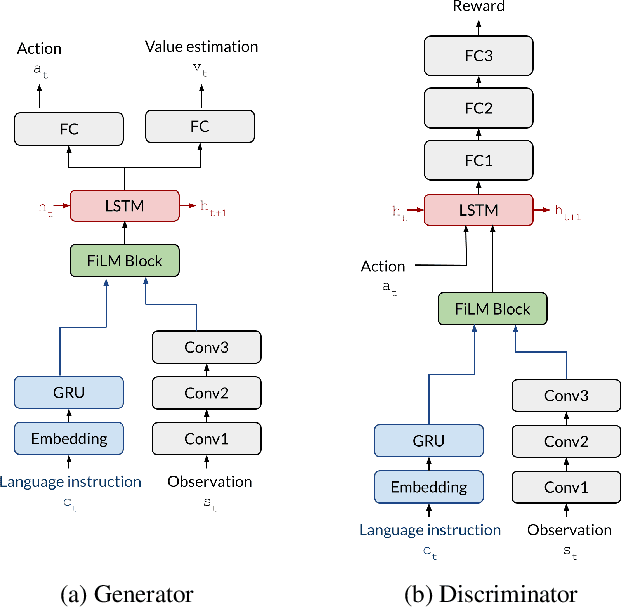
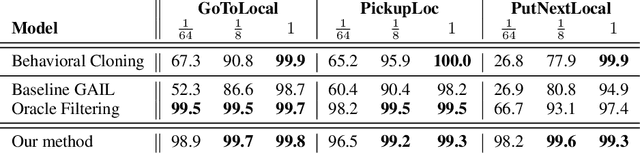
In adversarial imitation learning, a discriminator is trained to differentiate agent episodes from expert demonstrations representing the desired behavior. However, as the trained policy learns to be more successful, the negative examples (the ones produced by the agent) become increasingly similar to expert ones. Despite the fact that the task is successfully accomplished in some of the agent's trajectories, the discriminator is trained to output low values for them. We hypothesize that this inconsistent training signal for the discriminator can impede its learning, and consequently leads to worse overall performance of the agent. We show experimental evidence for this hypothesis and that the 'False Negatives' (i.e. successful agent episodes) significantly hinder adversarial imitation learning, which is the first contribution of this paper. Then, we propose a method to alleviate the impact of false negatives and test it on the BabyAI environment. This method consistently improves sample efficiency over the baselines by at least an order of magnitude.
Using Simulated Data to Generate Images of Climate Change
Jan 26, 2020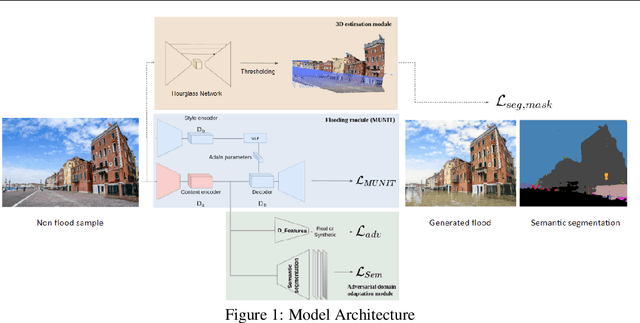



Generative adversarial networks (GANs) used in domain adaptation tasks have the ability to generate images that are both realistic and personalized, transforming an input image while maintaining its identifiable characteristics. However, they often require a large quantity of training data to produce high-quality images in a robust way, which limits their usability in cases when access to data is limited. In our paper, we explore the potential of using images from a simulated 3D environment to improve a domain adaptation task carried out by the MUNIT architecture, aiming to use the resulting images to raise awareness of the potential future impacts of climate change.
Multi-task self-supervised learning for Robust Speech Recognition
Jan 25, 2020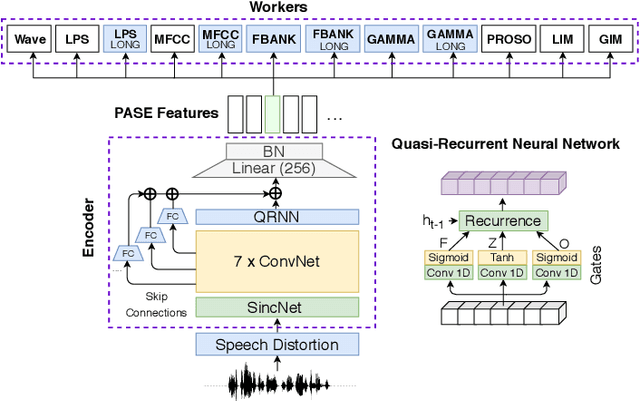
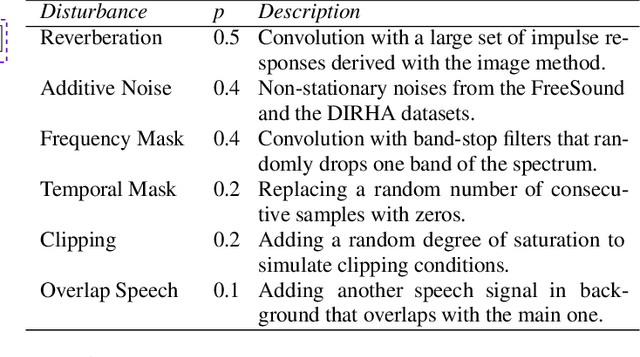
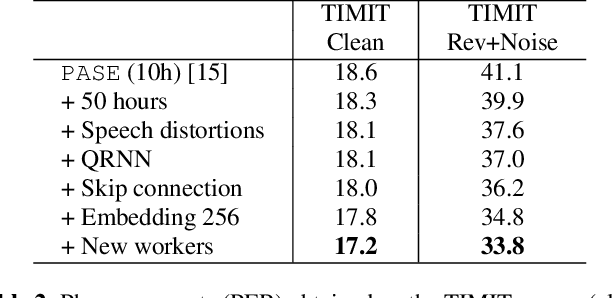
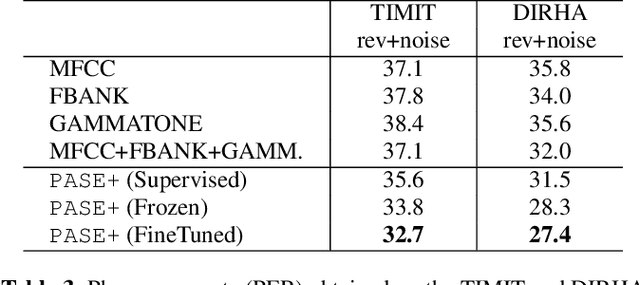
Despite the growing interest in unsupervised learning, extracting meaningful knowledge from unlabelled audio remains an open challenge. To take a step in this direction, we recently proposed a problem-agnostic speech encoder (PASE), that combines a convolutional encoder followed by multiple neural networks, called workers, tasked to solve self-supervised problems (i.e., ones that do not require manual annotations as ground truth). PASE was shown to capture relevant speech information, including speaker voice-print and phonemes. This paper proposes PASE+, an improved version of PASE for robust speech recognition in noisy and reverberant environments. To this end, we employ an online speech distortion module, that contaminates the input signals with a variety of random disturbances. We then propose a revised encoder that better learns short- and long-term speech dynamics with an efficient combination of recurrent and convolutional networks. Finally, we refine the set of workers used in self-supervision to encourage better cooperation. Results on TIMIT, DIRHA and CHiME-5 show that PASE+ significantly outperforms both the previous version of PASE as well as common acoustic features. Interestingly, PASE+ learns transferable representations suitable for highly mismatched acoustic conditions.
Universal Successor Features for Transfer Reinforcement Learning
Jan 05, 2020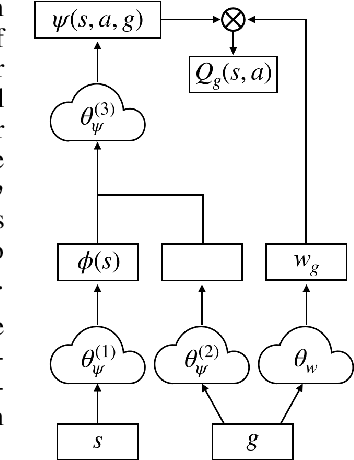
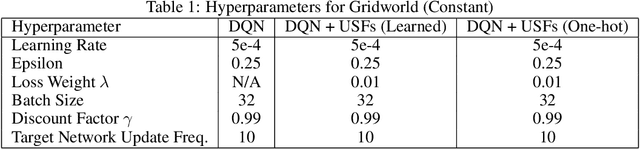
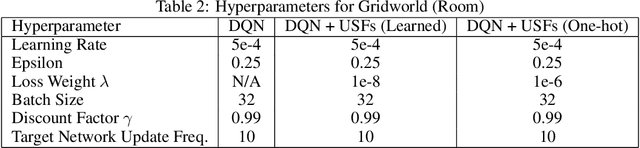
Transfer in Reinforcement Learning (RL) refers to the idea of applying knowledge gained from previous tasks to solving related tasks. Learning a universal value function (Schaul et al., 2015), which generalizes over goals and states, has previously been shown to be useful for transfer. However, successor features are believed to be more suitable than values for transfer (Dayan, 1993; Barreto et al.,2017), even though they cannot directly generalize to new goals. In this paper, we propose (1) Universal Successor Features (USFs) to capture the underlying dynamics of the environment while allowing generalization to unseen goals and (2) a flexible end-to-end model of USFs that can be trained by interacting with the environment. We show that learning USFs is compatible with any RL algorithm that learns state values using a temporal difference method. Our experiments in a simple gridworld and with two MuJoCo environments show that USFs can greatly accelerate training when learning multiple tasks and can effectively transfer knowledge to new tasks.