 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning framework with applications to zero-shot time-series forecasting
Feb 07, 2020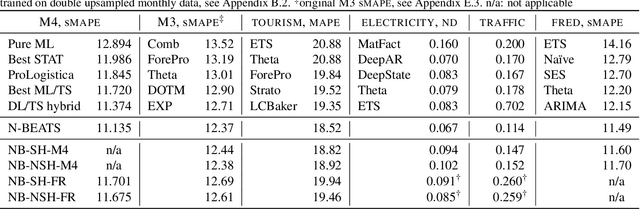
Can meta-learning discover generic ways of processing time-series (TS) from a diverse dataset so as to greatly improve generalization on new TS coming from different datasets? This work provides positive evidence to demonstrate this using a broad meta-learning framework which we show subsumes many existing meta-learning algorithms as specific cases. We further identify via theoretical analysis the meta-learning adaptation mechanisms within N-BEATS, a recent neural TS forecasting model. Our meta-learning theory predicts that N-BEATS iteratively generates a subset of its task-specific parameters based on a given TS input, thus gradually expanding the expressive power of the architecture on-the-fly. Our empirical results emphasize the importance of meta-learning for successful zero-shot forecasting to new sources of TS, supporting the claim that it is viable to train a neural network on a source TS dataset and deploy it on a different target TS dataset without retraining, resulting in performance that is at least as good as that of state-of-practice univariate forecasting models.
N-BEATS: Neural basis expansion analysis for interpretable time series forecasting
May 28, 2019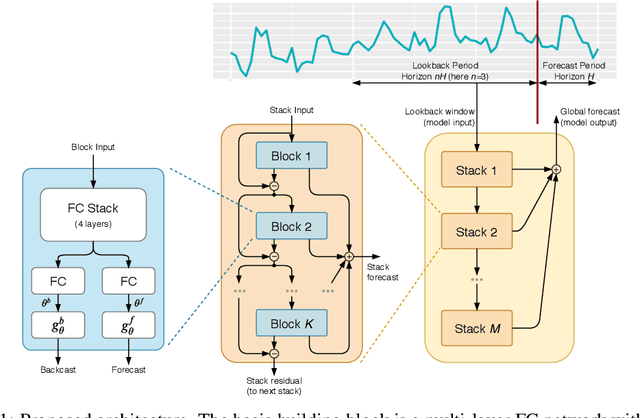
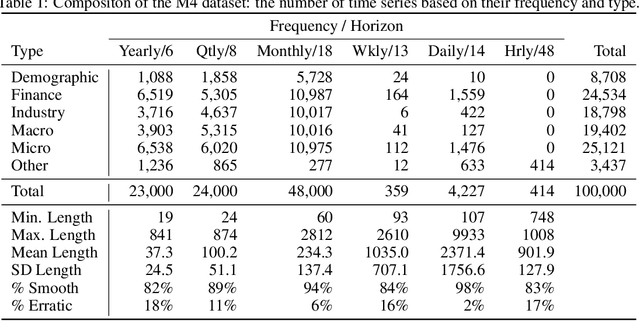
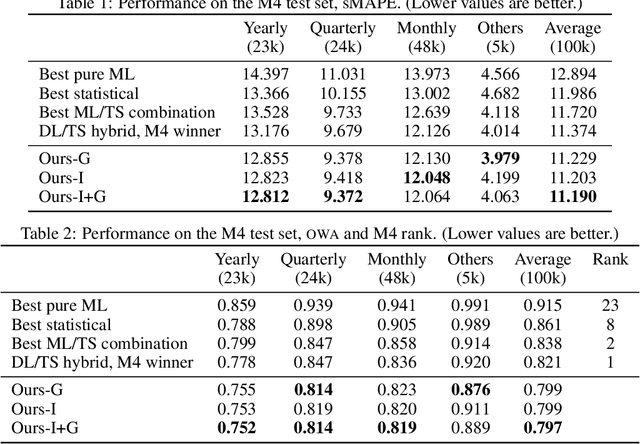
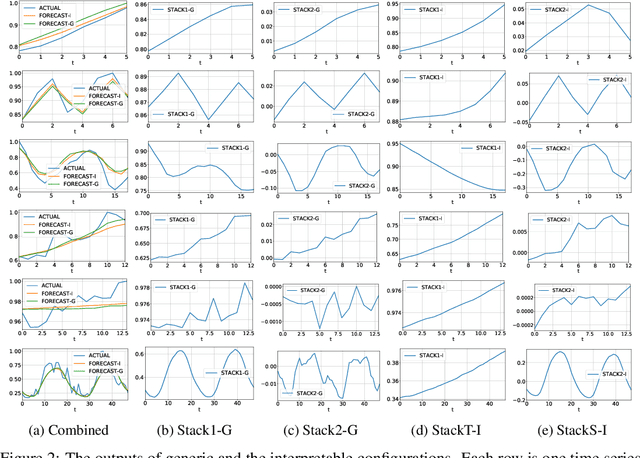
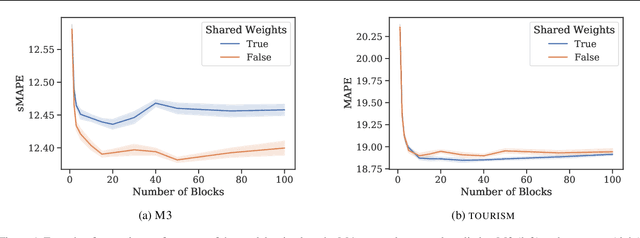
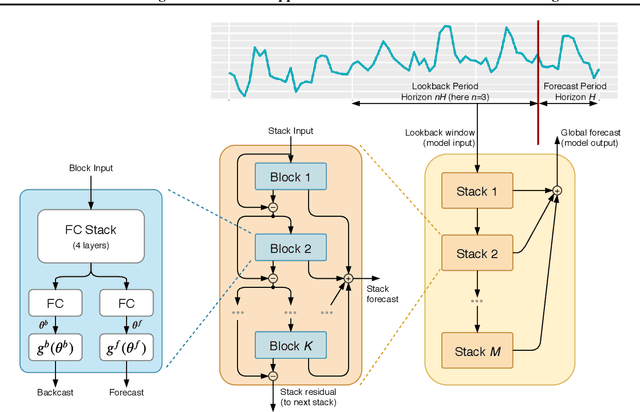
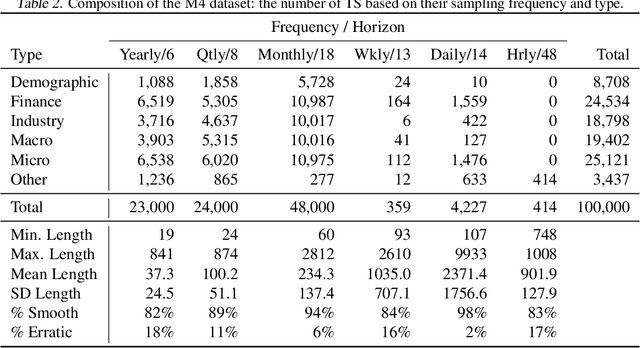
We focus on solving the univariate times series point forecasting problem using deep learning. We propose a deep neural architecture based on backward and forward residual links and a very deep stack of fully-connected layers. The architecture has a number of desirable properties, being interpretable, applicable without modification to a wide array of target domains, and fast to train. We test the proposed architecture on the well-known M4 competition dataset containing 100k time series from diverse domains. We demonstrate state-of-the-art performance for two configurations of N-BEATS, improving forecast accuracy by 11% over a statistical benchmark and by 3% over last year's winner of the M4 competition, a domain-adjusted hand-crafted hybrid between neural network and statistical time series models. The first configuration of our model does not employ any time-series-specific components and its performance on the M4 dataset strongly suggests that, contrarily to received wisdom, deep learning primitives such as residual blocks are by themselves sufficient to solve a wide range of forecasting problems. Finally, we demonstrate how the proposed architecture can be augmented to provide outputs that are interpretable without loss in accuracy.