 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale, Open-Domain, Mixed-Interface Dialogue-Based ITS for STEM
May 06, 2020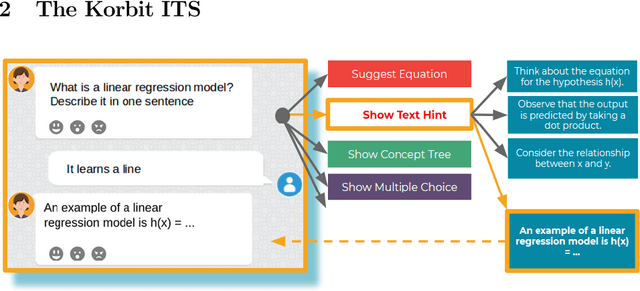
We present Korbit, a large-scale, open-domain, mixed-interface, dialogue-based intelligent tutoring system (ITS). Korbit uses machine learning, natural language processing and reinforcement learning to provide interactive, personalized learning online. Korbit has been designed to easily scale to thousands of subjects, by automating, standardizing and simplifying the content creation process. Unlike other ITS, a teacher can develop new learning modules for Korbit in a matter of hours. To facilitate learning across a widerange of STEM subjects, Korbit uses a mixed-interface, which includes videos, interactive dialogue-based exercises, question-answering, conceptual diagrams, mathematical exercises and gamification elements. Korbit has been built to scale to millions of students, by utilizing a state-of-the-art cloud-based micro-service architecture. Korbit launched its first course in 2019 on machine learning, and since then over 7,000 students have enrolled. Although Korbit was designed to be open-domain and highly scalable, A/B testing experiments with real-world students demonstrate that both student learning outcomes and student motivation are substantially improved compared to typical online courses.
Equilibrium Propagation with Continual Weight Updates
Apr 29, 2020
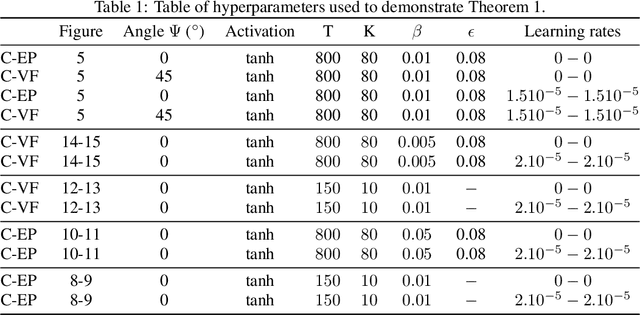
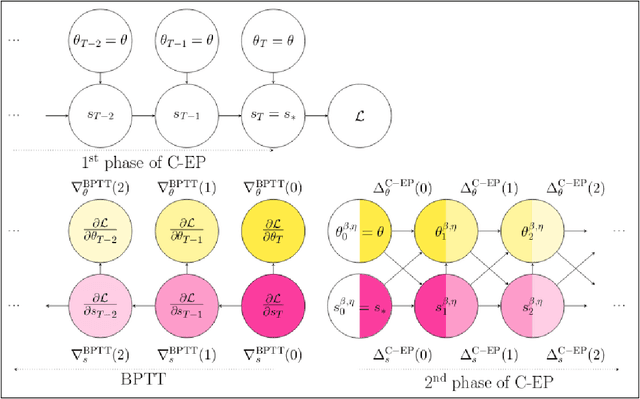
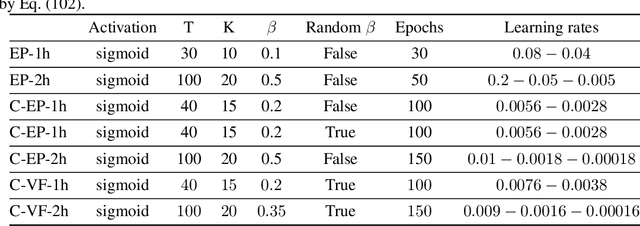
Equilibrium Propagation (EP) is a learning algorithm that bridges Machine Learning and Neuroscience, by computing gradients closely matching those of Backpropagation Through Time (BPTT), but with a learning rule local in space. Given an input $x$ and associated target $y$, EP proceeds in two phases: in the first phase neurons evolve freely towards a first steady state; in the second phase output neurons are nudged towards $y$ until they reach a second steady state. However, in existing implementations of EP, the learning rule is not local in time: the weight update is performed after the dynamics of the second phase have converged and requires information of the first phase that is no longer available physically. In this work, we propose a version of EP named Continual Equilibrium Propagation (C-EP) where neuron and synapse dynamics occur simultaneously throughout the second phase, so that the weight update becomes local in time. Such a learning rule local both in space and time opens the possibility of an extremely energy efficient hardware implementation of EP. We prove theoretically that, provided the learning rates are sufficiently small, at each time step of the second phase the dynamics of neurons and synapses follow the gradients of the loss given by BPTT (Theorem 1). We demonstrate training with C-EP on MNIST and generalize C-EP to neural networks where neurons are connected by asymmetric connections. We show through experiments that the more the network updates follows the gradients of BPTT, the best it performs in terms of training. These results bring EP a step closer to biology by better complying with hardware constraints while maintaining its intimate link with backpropagation.
Continual Weight Updates and Convolutional Architectures for Equilibrium Propagation
Apr 29, 2020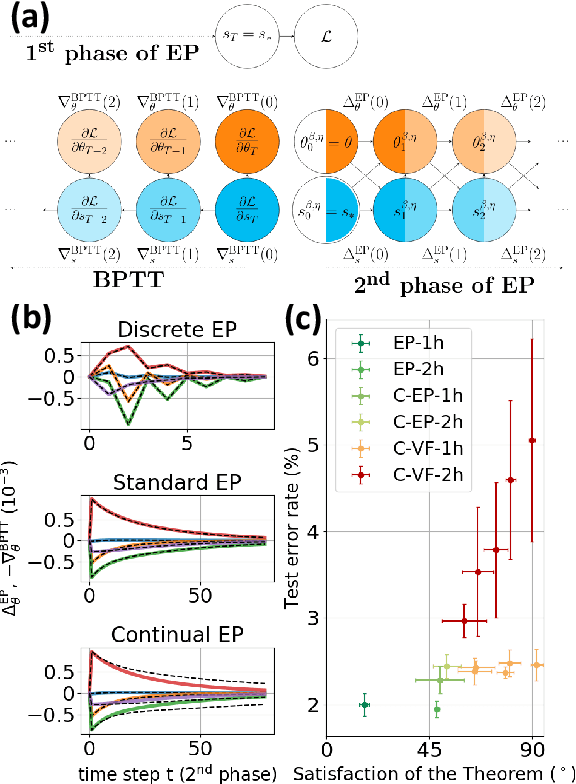
Equilibrium Propagation (EP) is a biologically inspired alternative algorithm to backpropagation (BP) for training neural networks. It applies to RNNs fed by a static input x that settle to a steady state, such as Hopfield networks. EP is similar to BP in that in the second phase of training, an error signal propagates backwards in the layers of the network, but contrary to BP, the learning rule of EP is spatially local. Nonetheless, EP suffers from two major limitations. On the one hand, due to its formulation in terms of real-time dynamics, EP entails long simulation times, which limits its applicability to practical tasks. On the other hand, the biological plausibility of EP is limited by the fact that its learning rule is not local in time: the synapse update is performed after the dynamics of the second phase have converged and requires information of the first phase that is no longer available physically. Our work addresses these two issues and aims at widening the spectrum of EP from standard machine learning models to more bio-realistic neural networks. First, we propose a discrete-time formulation of EP which enables to simplify equations, speed up training and extend EP to CNNs. Our CNN model achieves the best performance ever reported on MNIST with EP. Using the same discrete-time formulation, we introduce Continual Equilibrium Propagation (C-EP): the weights of the network are adjusted continually in the second phase of training using local information in space and time. We show that in the limit of slow changes of synaptic strengths and small nudging, C-EP is equivalent to BPTT (Theorem 1). We numerically demonstrate Theorem 1 and C-EP training on MNIST and generalize it to the bio-realistic situation of a neural network with asymmetric connections between neurons.
DiVA: Diverse Visual Feature Aggregation for Deep Metric Learning
Apr 29, 2020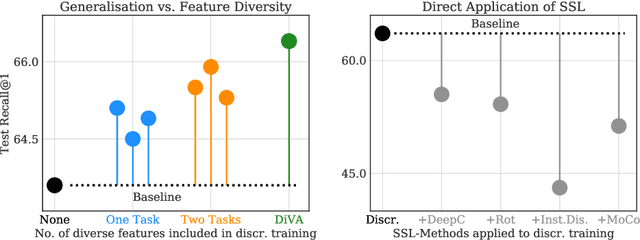
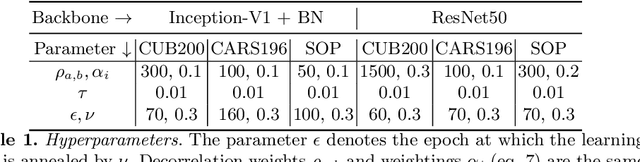
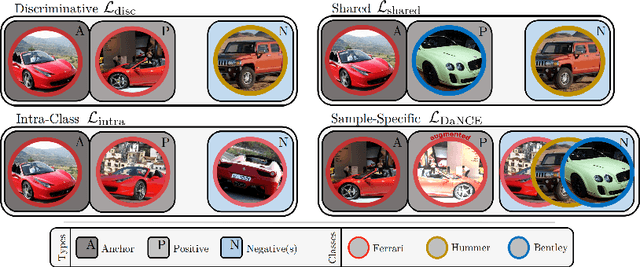
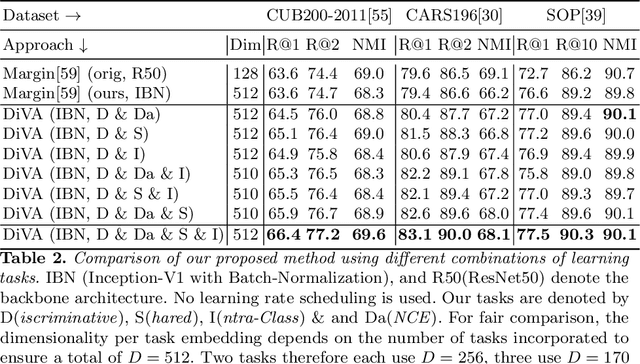
Visual Similarity plays an important role in many computer vision applications. Deep metric learning (DML) is a powerful framework for learning such similarities which not only generalize from training data to identically distributed test distributions, but in particular also translate to unknown test classes. However, its prevailing learning paradigm is class-discriminative supervised training, which typically results in representations specialized in separating training classes. For effective generalization, however, such an image representation needs to capture a diverse range of data characteristics. To this end, we propose and study multiple complementary learning tasks, targeting conceptually different data relationships by only resorting to the available training samples and labels of a standard DML setting. Through simultaneous optimization of our tasks we learn a single model to aggregate their training signals, resulting in strong generalization and state-of-the-art performance on multiple established DML benchmark datasets.
The Variational Bandwidth Bottleneck: Stochastic Evaluation on an Information Budget
Apr 24, 2020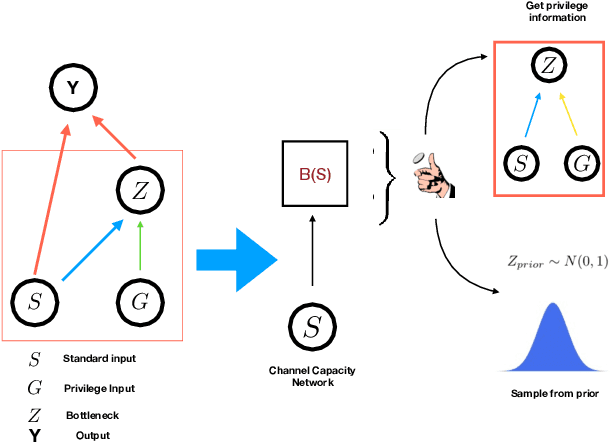

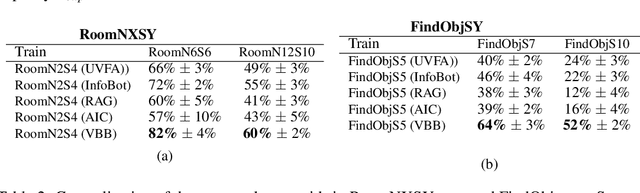
In many applications, it is desirable to extract only the relevant information from complex input data, which involves making a decision about which input features are relevant. The information bottleneck method formalizes this as an information-theoretic optimization problem by maintaining an optimal tradeoff between compression (throwing away irrelevant input information), and predicting the target. In many problem settings, including the reinforcement learning problems we consider in this work, we might prefer to compress only part of the input. This is typically the case when we have a standard conditioning input, such as a state observation, and a "privileged" input, which might correspond to the goal of a task, the output of a costly planning algorithm, or communication with another agent. In such cases, we might prefer to compress the privileged input, either to achieve better generalization (e.g., with respect to goals) or to minimize access to costly information (e.g., in the case of communication). Practical implementations of the information bottleneck based on variational inference require access to the privileged input in order to compute the bottleneck variable, so although they perform compression, this compression operation itself needs unrestricted, lossless access. In this work, we propose the variational bandwidth bottleneck, which decides for each example on the estimated value of the privileged information before seeing it, i.e., only based on the standard input, and then accordingly chooses stochastically, whether to access the privileged input or not. We formulate a tractable approximation to this framework and demonstrate in a series of reinforcement learning experiments that it can improve generalization and reduce access to computationally costly information.
Experience Grounds Language
Apr 21, 2020Successful linguistic communication relies on a shared experience of the world, and it is this shared experience that makes utterances meaningful. Despite the incredible effectiveness of language processing models trained on text alone, today's best systems still make mistakes that arise from a failure to relate language to the physical world it describes and to the social interactions it facilitates. Natural Language Processing is a diverse field, and progress throughout its development has come from new representational theories, modeling techniques, data collection paradigms, and tasks. We posit that the present success of representation learning approaches trained on large text corpora can be deeply enriched from the parallel tradition of research on the contextual and social nature of language. In this article, we consider work on the contextual foundations of language: grounding, embodiment, and social interaction. We describe a brief history and possible progression of how contextual information can factor into our representations, with an eye towards how this integration can move the field forward and where it is currently being pioneered. We believe this framing will serve as a roadmap for truly contextual language understanding.
Your GAN is Secretly an Energy-based Model and You Should use Discriminator Driven Latent Sampling
Mar 24, 2020
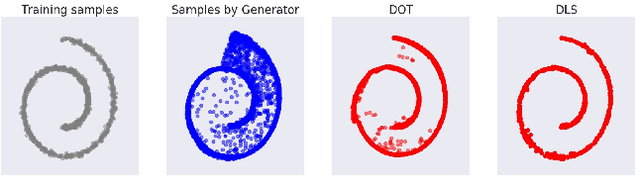
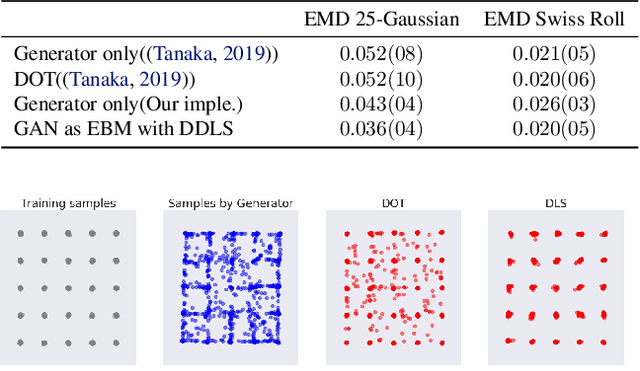

We show that the sum of the implicit generator log-density $\log p_g$ of a GAN with the logit score of the discriminator defines an energy function which yields the true data density when the generator is imperfect but the discriminator is optimal, thus making it possible to improve on the typical generator (with implicit density $p_g$). To make that practical, we show that sampling from this modified density can be achieved by sampling in latent space according to an energy-based model induced by the sum of the latent prior log-density and the discriminator output score. This can be achieved by running a Langevin MCMC in latent space and then applying the generator function, which we call Discriminator Driven Latent Sampling~(DDLS). We show that DDLS is highly efficient compared to previous methods which work in the high-dimensional pixel space and can be applied to improve on previously trained GANs of many types. We evaluate DDLS on both synthetic and real-world datasets qualitatively and quantitatively. On CIFAR-10, DDLS substantially improves the Inception Score of an off-the-shelf pre-trained SN-GAN~\citep{sngan} from $8.22$ to $9.09$ which is even comparable to the class-conditional BigGAN~\citep{biggan} model. This achieves a new state-of-the-art in unconditional image synthesis setting without introducing extra parameters or additional training.
Object-Centric Image Generation from Layouts
Mar 16, 2020


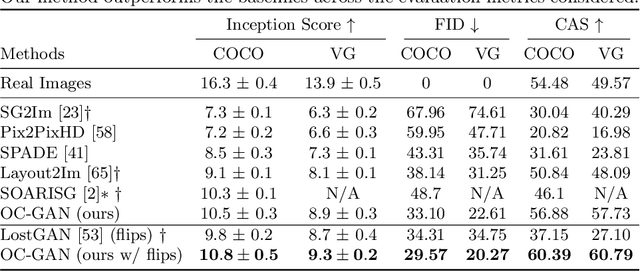
Despite recent impressive results on single-object and single-domain image generation, the generation of complex scenes with multiple objects remains challenging. In this paper, we start with the idea that a model must be able to understand individual objects and relationships between objects in order to generate complex scenes well. Our layout-to-image-generation method, which we call Object-Centric Generative Adversarial Network (or OC-GAN), relies on a novel Scene-Graph Similarity Module (SGSM). The SGSM learns representations of the spatial relationships between objects in the scene, which lead to our model's improved layout-fidelity. We also propose changes to the conditioning mechanism of the generator that enhance its object instance-awareness. Apart from improving image quality, our contributions mitigate two failure modes in previous approaches: (1) spurious objects being generated without corresponding bounding boxes in the layout, and (2) overlapping bounding boxes in the layout leading to merged objects in images. Extensive quantitative evaluation and ablation studies demonstrate the impact of our contributions, with our model outperforming previous state-of-the-art approaches on both the COCO-Stuff and Visual Genome datasets. Finally, we address an important limitation of evaluation metrics used in previous works by introducing SceneFID -- an object-centric adaptation of the popular Fr{\'e}chet Inception Distance metric, that is better suited for multi-object images.
Continuous Domain Adaptation with Variational Domain-Agnostic Feature Replay
Mar 09, 2020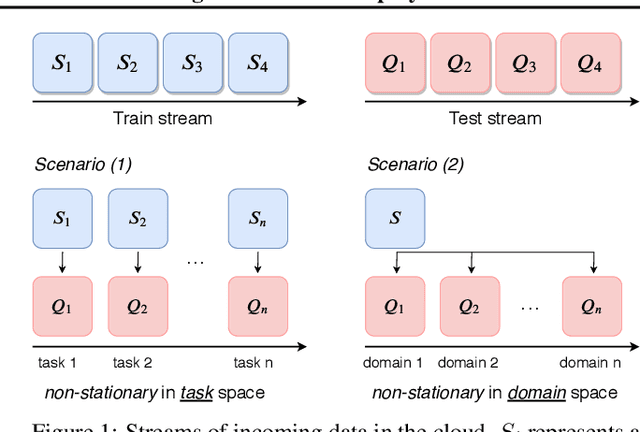
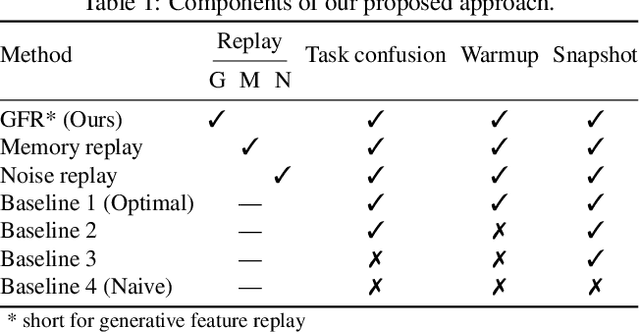
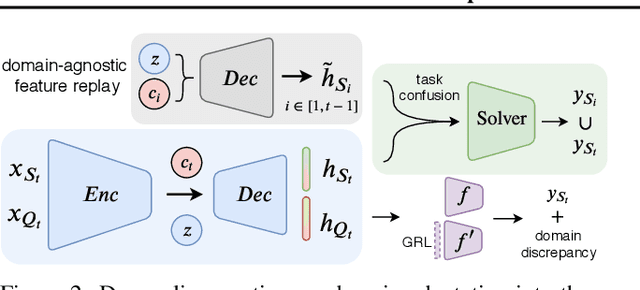
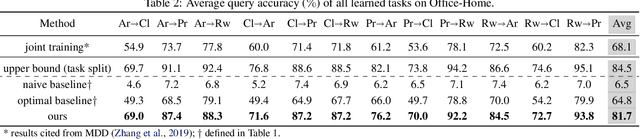
Learning in non-stationary environments is one of the biggest challenges in machine learning. Non-stationarity can be caused by either task drift, i.e., the drift in the conditional distribution of labels given the input data, or the domain drift, i.e., the drift in the marginal distribution of the input data. This paper aims to tackle this challenge in the context of continuous domain adaptation, where the model is required to learn new tasks adapted to new domains in a non-stationary environment while maintaining previously learned knowledge. To deal with both drifts, we propose variational domain-agnostic feature replay, an approach that is composed of three components: an inference module that filters the input data into domain-agnostic representations, a generative module that facilitates knowledge transfer, and a solver module that applies the filtered and transferable knowledge to solve the queries. We address the two fundamental scenarios in continuous domain adaptation, demonstrating the effectiveness of our proposed approach for practical usage.
Benchmarking Graph Neural Networks
Mar 02, 2020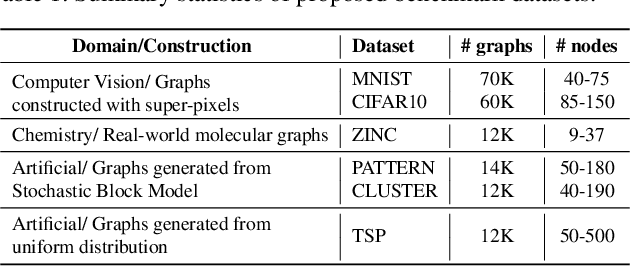
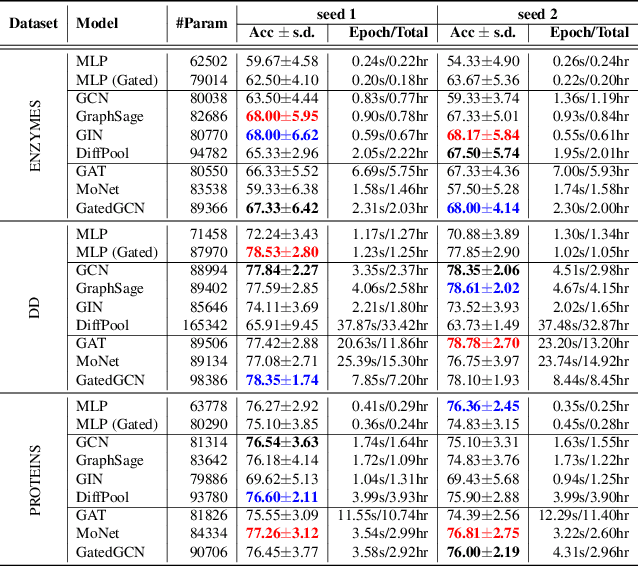
Graph neural networks (GNNs) have become the standard toolkit for analyzing and learning from data on graphs. They have been successfully applied to a myriad of domains including chemistry, physics, social sciences, knowledge graphs, recommendation, and neuroscience. As the field grows, it becomes critical to identify the architectures and key mechanisms which generalize across graphs sizes, enabling us to tackle larger, more complex datasets and domains. Unfortunately, it has been increasingly difficult to gauge the effectiveness of new GNNs and compare models in the absence of a standardized benchmark with consistent experimental settings and large datasets. In this paper, we propose a reproducible GNN benchmarking framework, with the facility for researchers to add new datasets and models conveniently. We apply this benchmarking framework to novel medium-scale graph datasets from mathematical modeling, computer vision, chemistry and combinatorial problems to establish key operations when designing effective GNNs. Precisely, graph convolutions, anisotropic diffusion, residual connections and normalization layers are universal building blocks for developing robust and scalable GNNs.