 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Object-Centric Embeddings for Cell Instance Segmentation in Microscopy Images
Oct 12, 2023



Segmentation of objects in microscopy images is required for many biomedical applications. We introduce object-centric embeddings (OCEs), which embed image patches such that the spatial offsets between patches cropped from the same object are preserved. Those learnt embeddings can be used to delineate individual objects and thus obtain instance segmentations. Here, we show theoretically that, under assumptions commonly found in microscopy images, OCEs can be learnt through a self-supervised task that predicts the spatial offset between image patches. Together, this forms an unsupervised cell instance segmentation method which we evaluate on nine diverse large-scale microscopy datasets. Segmentations obtained with our method lead to substantially improved results, compared to state-of-the-art baselines on six out of nine datasets, and perform on par on the remaining three datasets. If ground-truth annotations are available, our method serves as an excellent starting point for supervised training, reducing the required amount of ground-truth needed by one order of magnitude, thus substantially increasing the practical applicability of our method. Source code is available at https://github.com/funkelab/cellulus.
ALE: A Simulation-Based Active Learning Evaluation Framework for the Parameter-Driven Comparison of Query Strategies for NLP
Aug 01, 2023Supervised machine learning and deep learning require a large amount of labeled data, which data scientists obtain in a manual, and time-consuming annotation process. To mitigate this challenge, Active Learning (AL) proposes promising data points to annotators they annotate next instead of a subsequent or random sample. This method is supposed to save annotation effort while maintaining model performance. However, practitioners face many AL strategies for different tasks and need an empirical basis to choose between them. Surveys categorize AL strategies into taxonomies without performance indications. Presentations of novel AL strategies compare the performance to a small subset of strategies. Our contribution addresses the empirical basis by introducing a reproducible active learning evaluation (ALE) framework for the comparative evaluation of AL strategies in NLP. The framework allows the implementation of AL strategies with low effort and a fair data-driven comparison through defining and tracking experiment parameters (e.g., initial dataset size, number of data points per query step, and the budget). ALE helps practitioners to make more informed decisions, and researchers can focus on developing new, effective AL strategies and deriving best practices for specific use cases. With best practices, practitioners can lower their annotation costs. We present a case study to illustrate how to use the framework.
* The Version of Record of this contribution is published in Deep Learning Theory and Applications 4th International Conference, DeLTA 2023 Proceedings, and is available online at https://doi.org/10.1007/978-3-031-39059-3_16
Proposal-Free Volumetric Instance Segmentation from Latent Single-Instance Masks
Sep 10, 2020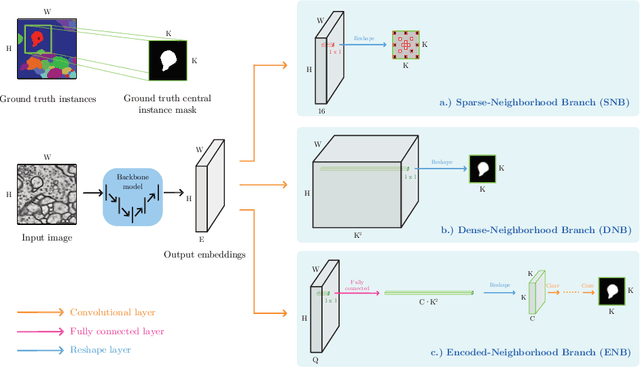
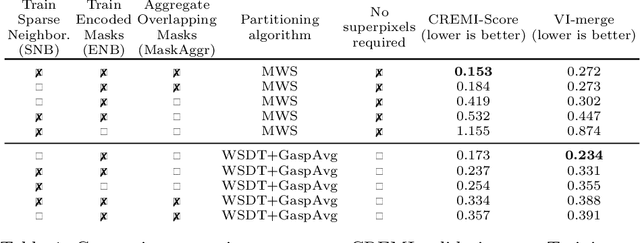

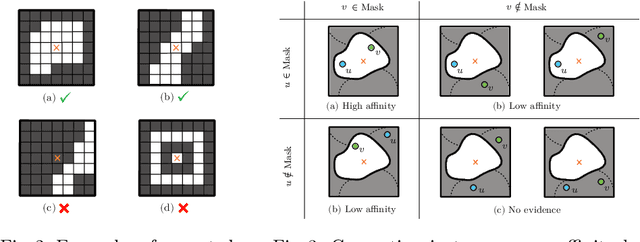
This work introduces a new proposal-free instance segmentation method that builds on single-instance segmentation masks predicted across the entire image in a sliding window style. In contrast to related approaches, our method concurrently predicts all masks, one for each pixel, and thus resolves any conflict jointly across the entire image. Specifically, predictions from overlapping masks are combined into edge weights of a signed graph that is subsequently partitioned to obtain all final instances concurrently. The result is a parameter-free method that is strongly robust to noise and prioritizes predictions with the highest consensus across overlapping masks. All masks are decoded from a low dimensional latent representation, which results in great memory savings strictly required for applications to large volumetric images. We test our method on the challenging CREMI 2016 neuron segmentation benchmark where it achieves competitive scores.
Instance Separation Emerges from Inpainting
Feb 28, 2020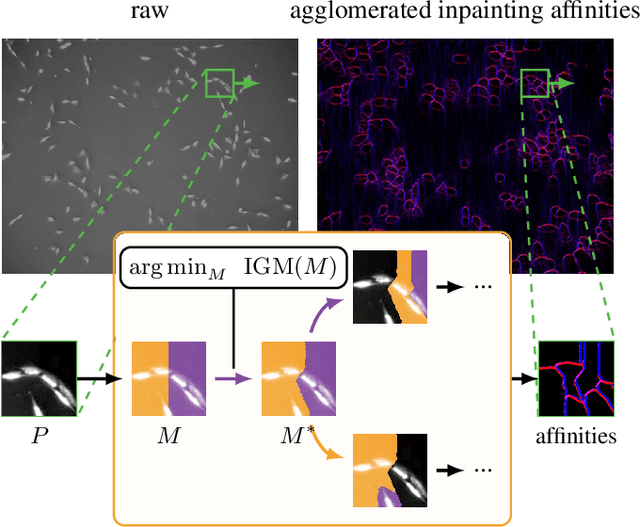

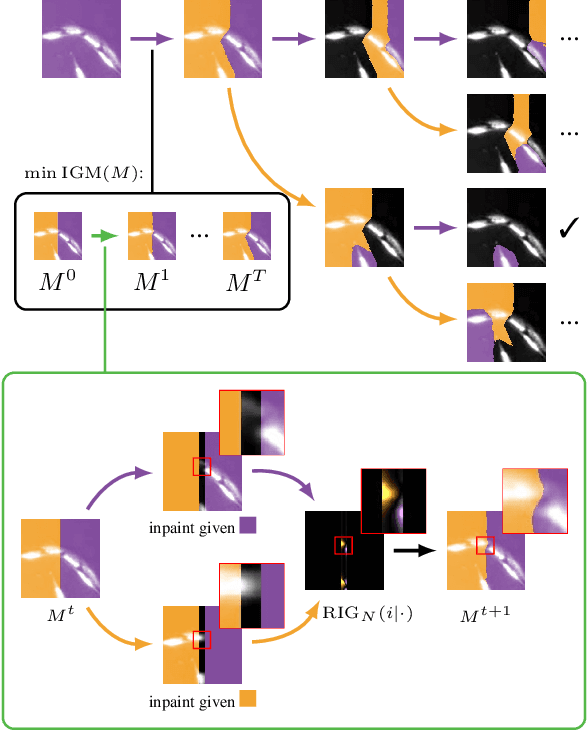

Deep neural networks trained to inpaint partially occluded images show a deep understanding of image composition and have even been shown to remove objects from images convincingly. In this work, we investigate how this implicit knowledge of image composition can be leveraged for fully self-supervised instance separation. We propose a measure for the independence of two image regions given a fully self-supervised inpainting network and separate objects by maximizing this independence. We evaluate our method on two microscopy image datasets and show that it reaches similar segmentation performance to fully supervised methods.
The Semantic Mutex Watershed for Efficient Bottom-Up Semantic Instance Segmentation
Dec 29, 2019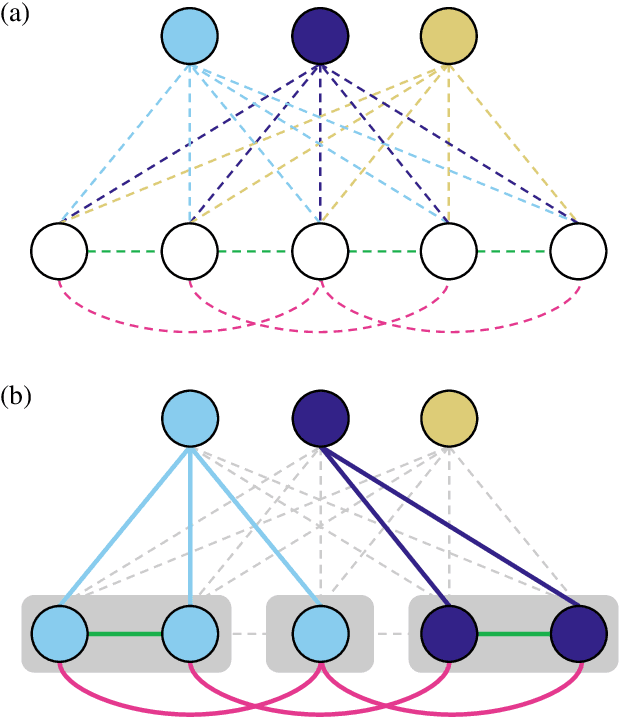


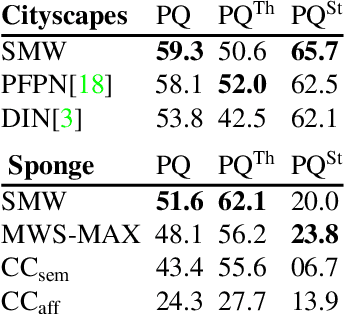
Semantic instance segmentation is the task of simultaneously partitioning an image into distinct segments while associating each pixel with a class label. In commonly used pipelines, segmentation and label assignment are solved separately since joint optimization is computationally expensive. We propose a greedy algorithm for joint graph partitioning and labeling derived from the efficient Mutex Watershed partitioning algorithm. It optimizes an objective function closely related to the Symmetric Multiway Cut objective and empirically shows efficient scaling behavior. Due to the algorithm's efficiency it can operate directly on pixels without prior over-segmentation of the image into superpixels. We evaluate the performance on the Cityscapes dataset (2D urban scenes) and on a 3D microscopy volume. In urban scenes, the proposed algorithm combined with current deep neural networks outperforms the strong baseline of `Panoptic Feature Pyramid Networks' by Kirillov et al. (2019). In the 3D electron microscopy images, we show explicitly that our joint formulation outperforms a separate optimization of the partitioning and labeling problems.
Learning the Arrow of Time
Jul 02, 2019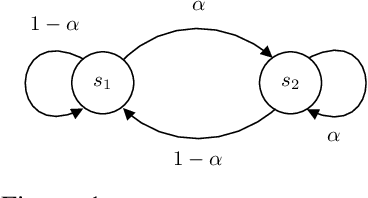
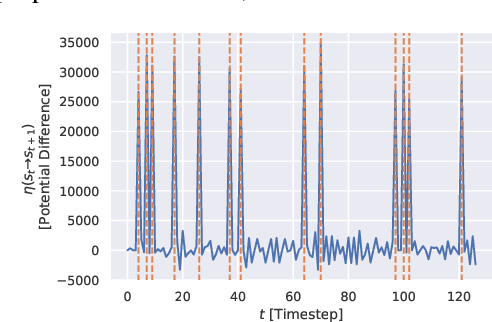
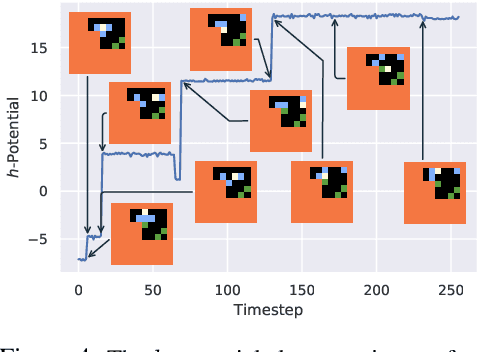
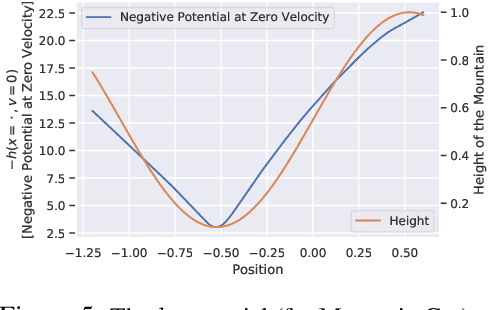
We humans seem to have an innate understanding of the asymmetric progression of time, which we use to efficiently and safely perceive and manipulate our environment. Drawing inspiration from that, we address the problem of learning an arrow of time in a Markov (Decision) Process. We illustrate how a learned arrow of time can capture meaningful information about the environment, which in turn can be used to measure reachability, detect side-effects and to obtain an intrinsic reward signal. We show empirical results on a selection of discrete and continuous environments, and demonstrate for a class of stochastic processes that the learned arrow of time agrees reasonably well with a known notion of an arrow of time given by the celebrated Jordan-Kinderlehrer-Otto result.
A Generalized Framework for Agglomerative Clustering of Signed Graphs applied to Instance Segmentation
Jun 27, 2019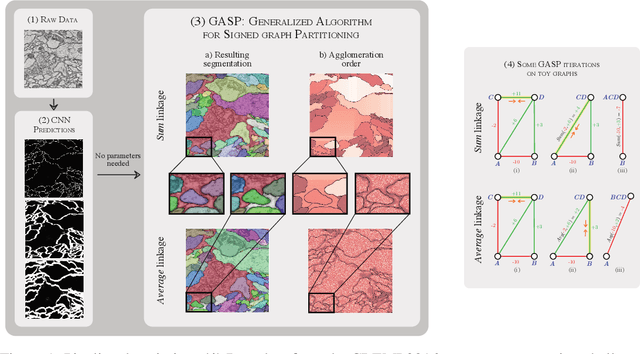
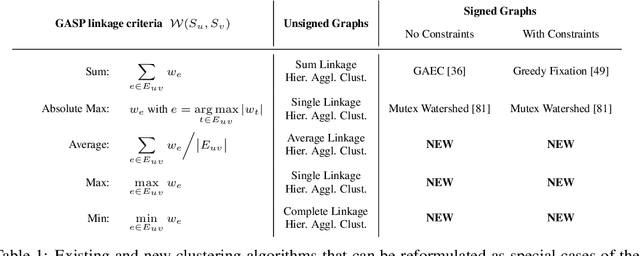
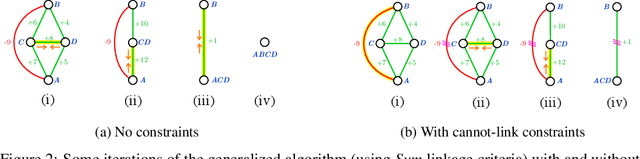
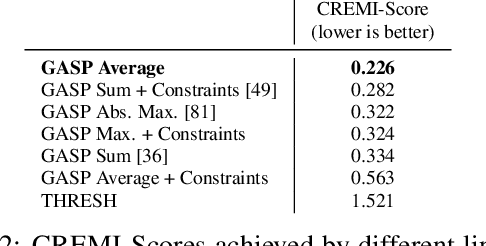
We propose a novel theoretical framework that generalizes algorithms for hierarchical agglomerative clustering to weighted graphs with both attractive and repulsive interactions between the nodes. This framework defines GASP, a Generalized Algorithm for Signed graph Partitioning, and allows us to explore many combinations of different linkage criteria and cannot-link constraints. We prove the equivalence of existing clustering methods to some of those combinations, and introduce new algorithms for combinations which have not been studied. An extensive comparison is performed to evaluate properties of the clustering algorithms in the context of instance segmentation in images, including robustness to noise and efficiency. We show how one of the new algorithms proposed in our framework outperforms all previously known agglomerative methods for signed graphs, both on the competitive CREMI 2016 EM segmentation benchmark and on the CityScapes dataset.
The Mutex Watershed and its Objective: Efficient, Parameter-Free Image Partitioning
Apr 25, 2019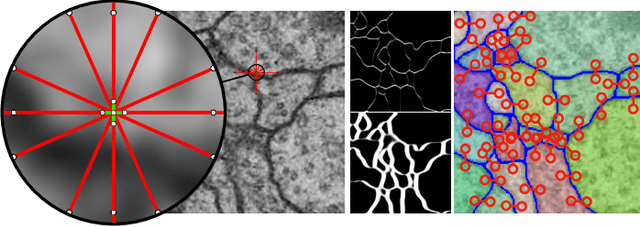
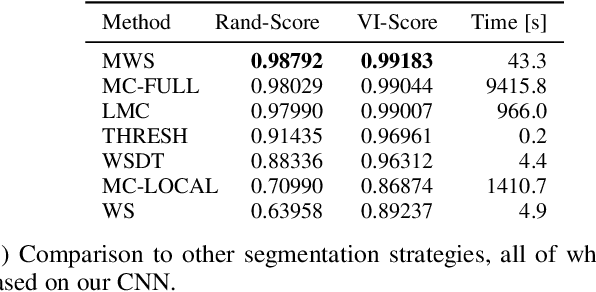
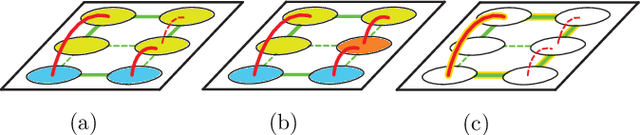
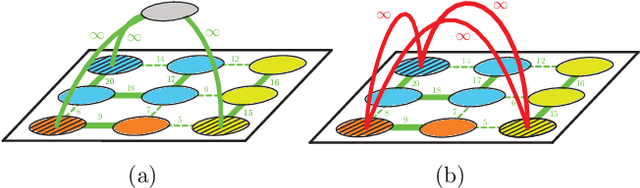
Image partitioning, or segmentation without semantics, is the task of decomposing an image into distinct segments, or equivalently to detect closed contours. Most prior work either requires seeds, one per segment; or a threshold; or formulates the task as multicut / correlation clustering, an NP-hard problem. Here, we propose a greedy algorithm for signed graph partitioning, the "Mutex Watershed". Unlike seeded watershed, the algorithm can accommodate not only attractive but also repulsive cues, allowing it to find a previously unspecified number of segments without the need for explicit seeds or a tunable threshold. We also prove that this simple algorithm solves to global optimality an objective function that is intimately related to the multicut / correlation clustering integer linear programming formulation. The algorithm is deterministic, very simple to implement, and has empirically linearithmic complexity. When presented with short-range attractive and long-range repulsive cues from a deep neural network, the Mutex Watershed gives the best results currently known for the competitive ISBI 2012 EM segmentation benchmark.
Learned Watershed: End-to-End Learning of Seeded Segmentation
Sep 04, 2017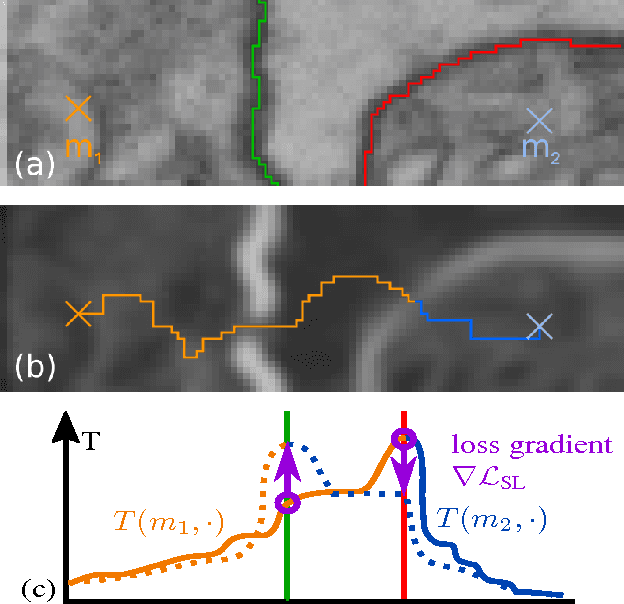
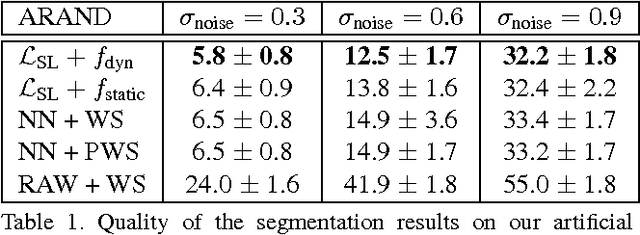
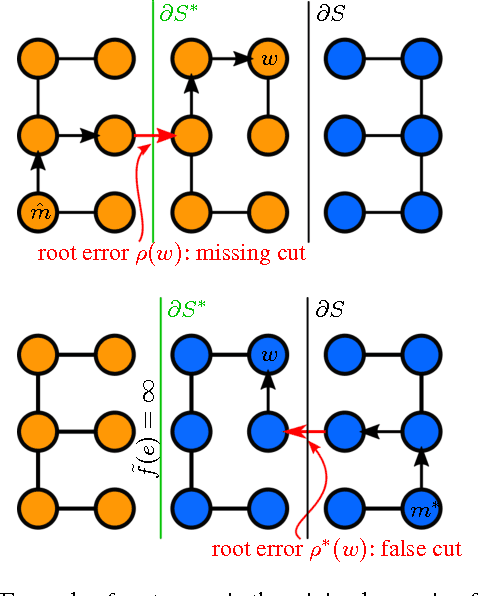

Learned boundary maps are known to outperform hand- crafted ones as a basis for the watershed algorithm. We show, for the first time, how to train watershed computation jointly with boundary map prediction. The estimator for the merging priorities is cast as a neural network that is con- volutional (over space) and recurrent (over iterations). The latter allows learning of complex shape priors. The method gives the best known seeded segmentation results on the CREMI segmentation challenge.
Tracking Objects with Higher Order Interactions using Delayed Column Generation
Aug 09, 2016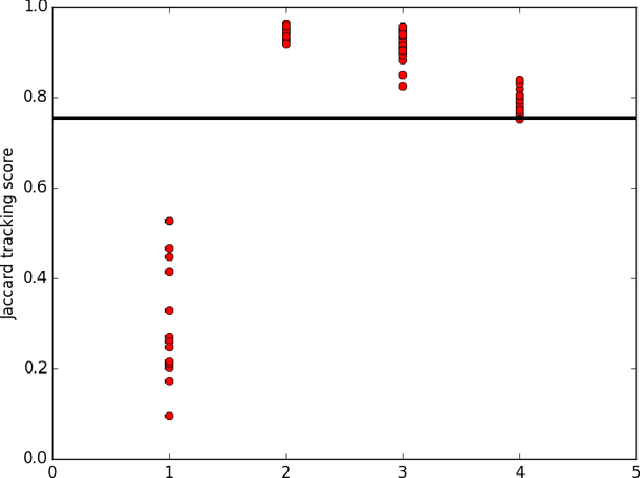
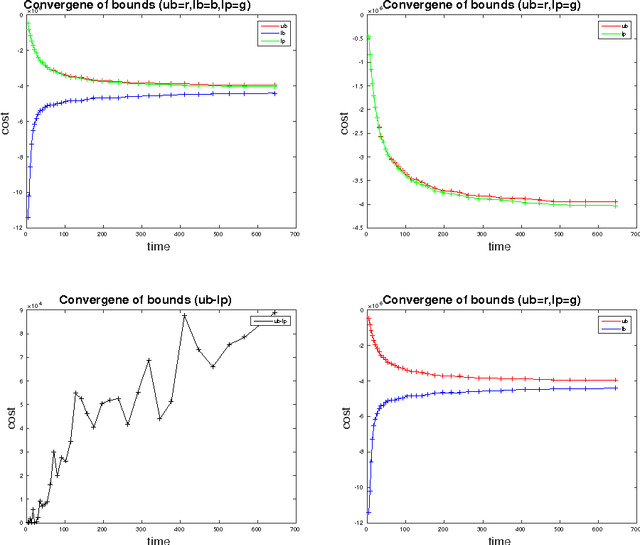
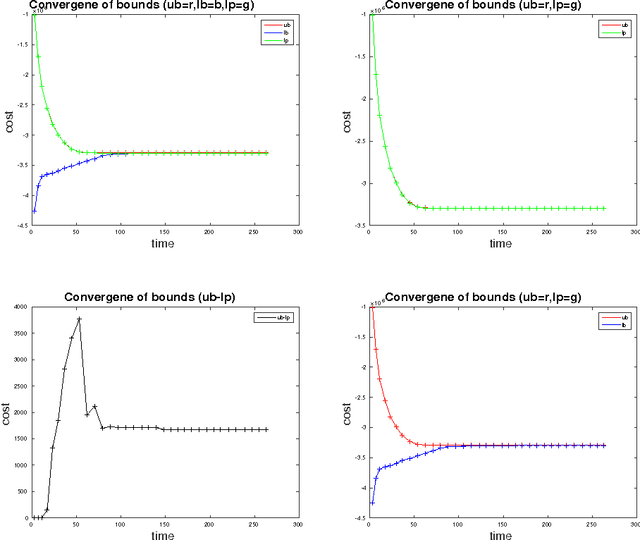
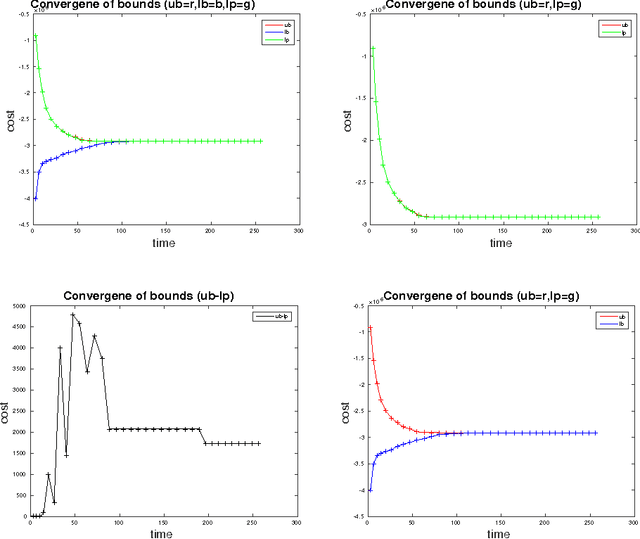
We study the problem of multi-target tracking and data association in video. We formulate this in terms of selecting a subset of high-quality tracks subject to the constraint that no pair of selected tracks is associated with a common detection (of an object). This objective is equivalent to the classic NP-hard problem of finding a maximum-weight set packing (MWSP) where tracks correspond to sets and is made further difficult since the number of candidate tracks grows exponentially in the number of detections. We present a relaxation of this combinatorial problem that uses a column generation formulation where the pricing problem is solved via dynamic programming to efficiently explore the space of tracks. We employ row generation to tighten the bound in such a way as to preserve efficient inference in the pricing problem. We show the practical utility of this algorithm for tracking problems in natural and biological video datasets.