 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-field Localization with Dynamic Metasurface Antennas
Oct 28, 2022



Sixth generation (6G) cellular communications are expected to support enhanced wireless localization capabilities. The widespread deployment of large arrays and high-frequency bandwidths give rise to new considerations for localization applications. First, emerging antenna architectures, such as dynamic metasurface antennas (DMAs), are expected to be frequently utilized thanks to the achievable high angular resolution and low hardware complexity. Further, wireless localization is likely to take place in the radiating near-field (Fresnel) region, which provides new degrees of freedom, because of the adoption of arrays with large apertures. While current studies mostly focus on the use of costly fully-digital antenna arrays, in this paper we investigate how DMAs can be applied for near-field localization of a single user. We use a direct positioning estimation method based on curvature-of-arrival of the impinging wavefront to obtain the user location, and characterize the effects of DMA tuning on the estimation accuracy. Next, we propose an algorithm for configuring the DMA to optimize near-field localization, by first tuning the adjustable DMA coefficients to minimize the estimation error using postulated knowledge of the actual user position. Finally, we propose a sub-optimal iterative algorithm that does not rely on such knowledge. Simulation results show that the DMA-based near-field localization accuracy could approach that of fully-digital arrays at lower cost.
Split-KalmanNet: A Robust Model-Based Deep Learning Approach for SLAM
Oct 18, 2022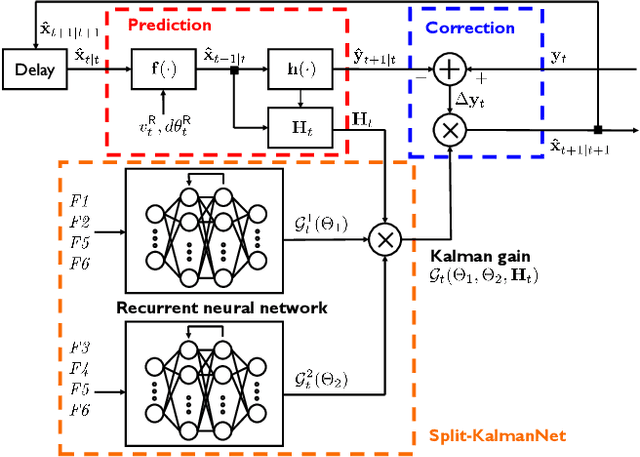
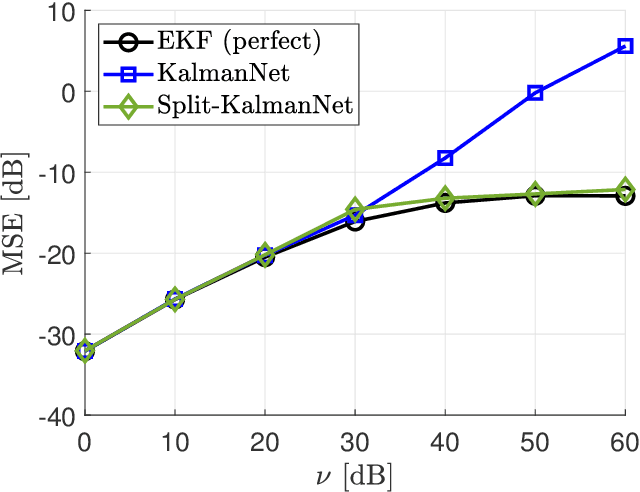
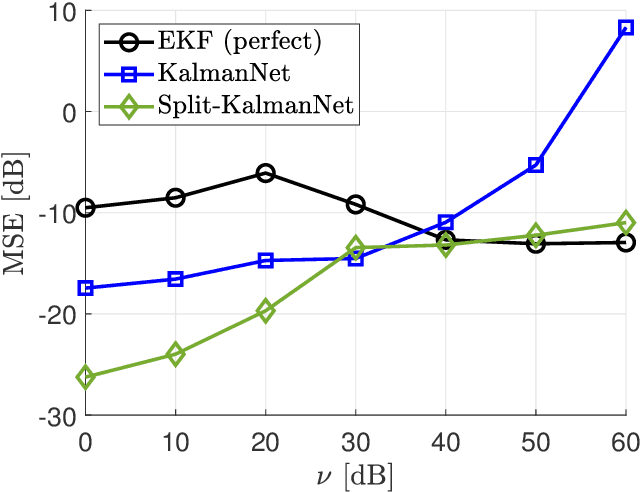
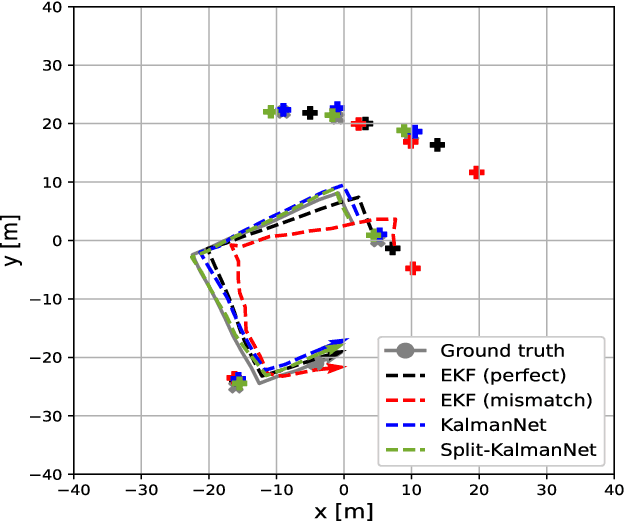
Simultaneous localization and mapping (SLAM) is a method that constructs a map of an unknown environment and localizes the position of a moving agent on the map simultaneously. Extended Kalman filter (EKF) has been widely adopted as a low complexity solution for online SLAM, which relies on a motion and measurement model of the moving agent. In practice, however, acquiring precise information about these models is very challenging, and the model mismatch effect causes severe performance loss in SLAM. In this paper, inspired by the recently proposed KalmanNet, we present a robust EKF algorithm using the power of deep learning for online SLAM, referred to as Split-KalmanNet. The key idea of Split-KalmanNet is to compute the Kalman gain using the Jacobian matrix of a measurement function and two recurrent neural networks (RNNs). The two RNNs independently learn the covariance matrices for a prior state estimate and the innovation from data. The proposed split structure in the computation of the Kalman gain allows to compensate for state and measurement model mismatch effects independently. Numerical simulation results verify that Split-KalmanNet outperforms the traditional EKF and the state-of-the-art KalmanNet algorithm in various model mismatch scenarios.
FedFM: Anchor-based Feature Matching for Data Heterogeneity in Federated Learning
Oct 14, 2022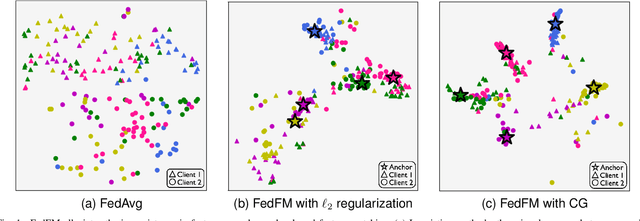
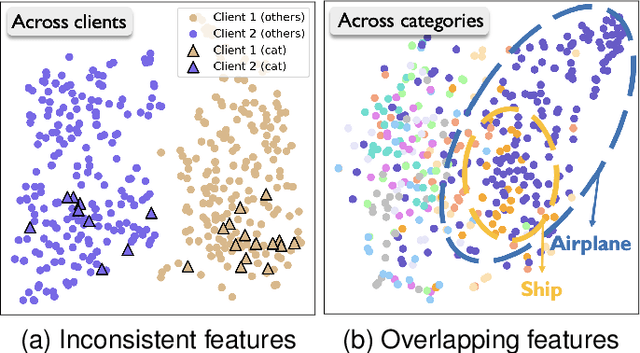
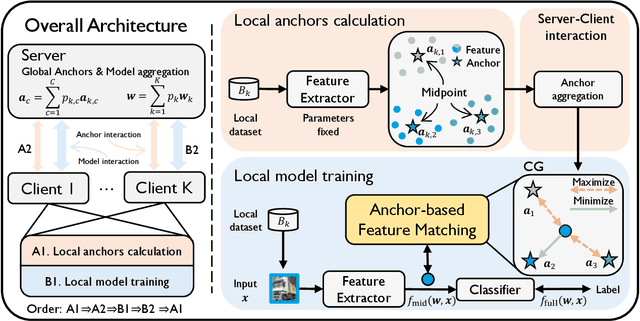
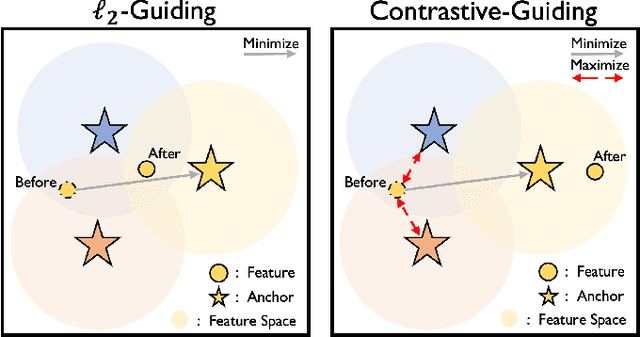
One of the key challenges in federated learning (FL) is local data distribution heterogeneity across clients, which may cause inconsistent feature spaces across clients. To address this issue, we propose a novel method FedFM, which guides each client's features to match shared category-wise anchors (landmarks in feature space). This method attempts to mitigate the negative effects of data heterogeneity in FL by aligning each client's feature space. Besides, we tackle the challenge of varying objective function and provide convergence guarantee for FedFM. In FedFM, to mitigate the phenomenon of overlapping feature spaces across categories and enhance the effectiveness of feature matching, we further propose a more precise and effective feature matching loss called contrastive-guiding (CG), which guides each local feature to match with the corresponding anchor while keeping away from non-corresponding anchors. Additionally, to achieve higher efficiency and flexibility, we propose a FedFM variant, called FedFM-Lite, where clients communicate with server with fewer synchronization times and communication bandwidth costs. Through extensive experiments, we demonstrate that FedFM with CG outperforms several works by quantitative and qualitative comparisons. FedFM-Lite can achieve better performance than state-of-the-art methods with five to ten times less communication costs.
Signal Detection in MIMO Systems with Hardware Imperfections: Message Passing on Neural Networks
Oct 08, 2022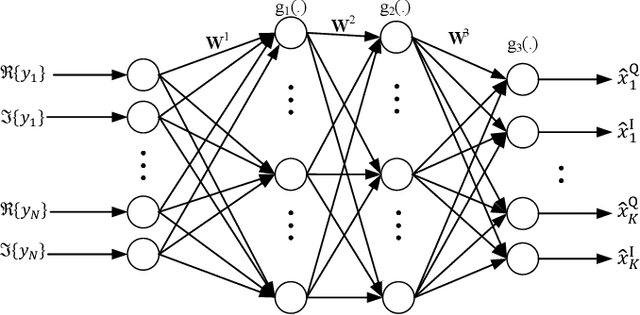
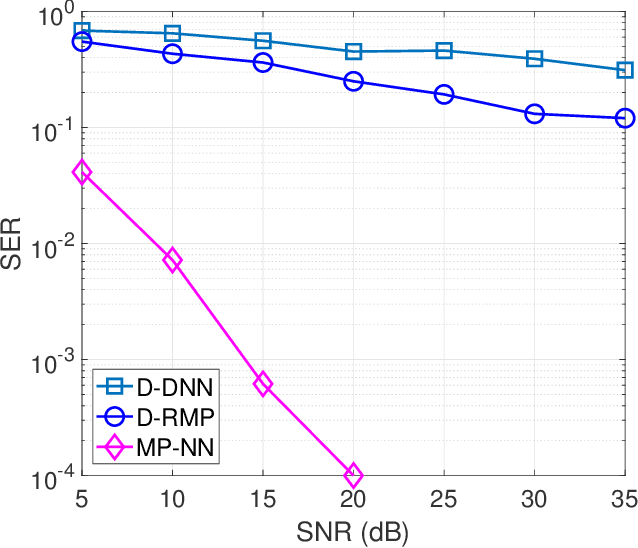
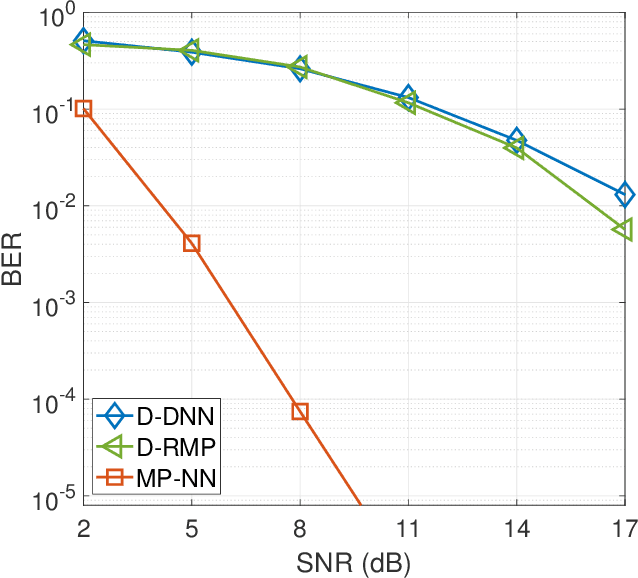
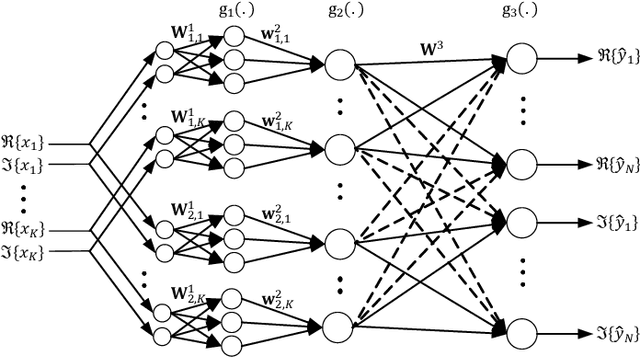
In this paper, we investigate signal detection in multiple-input-multiple-output (MIMO) communication systems with hardware impairments, such as power amplifier nonlinearity and in-phase/quadrature imbalance. To deal with the complex combined effects of hardware imperfections, neural network (NN) techniques, in particular deep neural networks (DNNs), have been studied to directly compensate for the impact of hardware impairments. However, it is difficult to train a DNN with limited pilot signals, hindering its practical applications. In this work, we investigate how to achieve efficient Bayesian signal detection in MIMO systems with hardware imperfections. Characterizing combined hardware imperfections often leads to complicated signal models, making Bayesian signal detection challenging. To address this issue, we first train an NN to "model" the MIMO system with hardware imperfections and then perform Bayesian inference based on the trained NN. Modelling the MIMO system with NN enables the design of NN architectures based on the signal flow of the MIMO system, minimizing the number of NN layers and parameters, which is crucial to achieving efficient training with limited pilot signals. We then represent the trained NN with a factor graph, and design an efficient message passing based Bayesian signal detector, leveraging the unitary approximate message passing (UAMP) algorithm. The implementation of a turbo receiver with the proposed Bayesian detector is also investigated. Extensive simulation results demonstrate that the proposed technique delivers remarkably better performance than state-of-the-art methods.
Seventy Years of Radar and Communications: The Road from Separation to Integration
Oct 02, 2022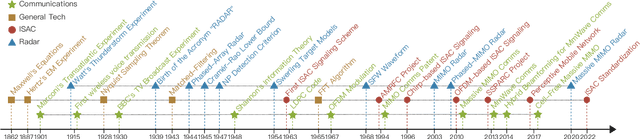
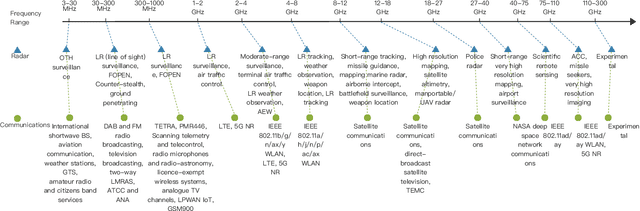
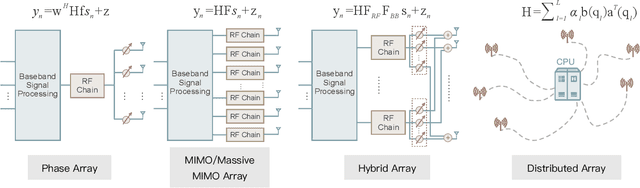
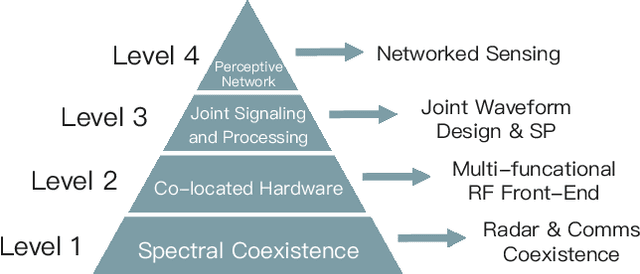
Radar and communications (R&C) as key utilities of electromagnetic (EM) waves have fundamentally shaped human society and triggered the modern information age. Although R&C have been historically progressing separately, in recent decades they have been moving from separation to integration, forming integrated sensing and communication (ISAC) systems, which find extensive applications in next-generation wireless networks and future radar systems. To better understand the essence of ISAC systems, this paper provides a systematic overview on the historical development of R&C from a signal processing (SP) perspective. We first interpret the duality between R&C as signals and systems, followed by an introduction of their fundamental principles. We then elaborate on the two main trends in their technological evolution, namely, the increase of frequencies and bandwidths, and the expansion of antenna arrays. Moreover, we show how the intertwined narratives of R\&C evolved into ISAC, and discuss the resultant SP framework. Finally, we overview future research directions in this field.
RDA: An Accelerated Collision-free Motion Planner for Autonomous Navigation in Cluttered Environments
Oct 01, 2022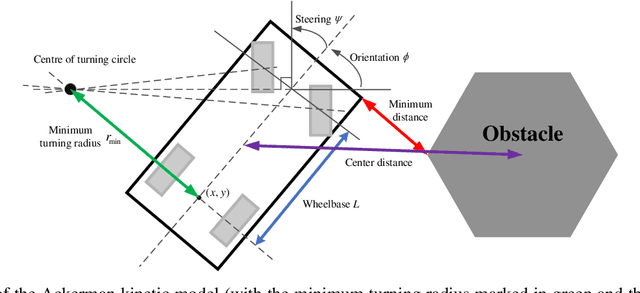
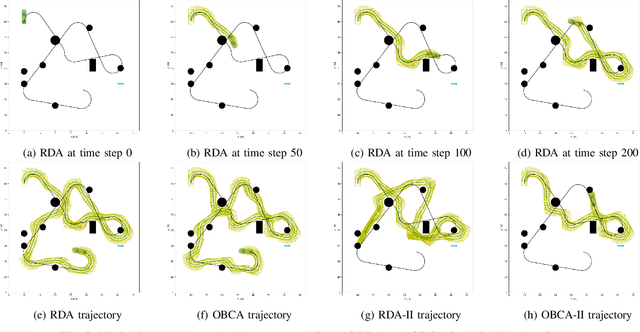
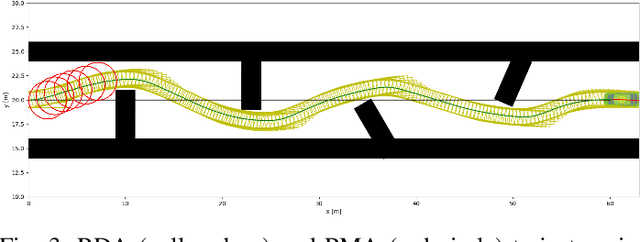
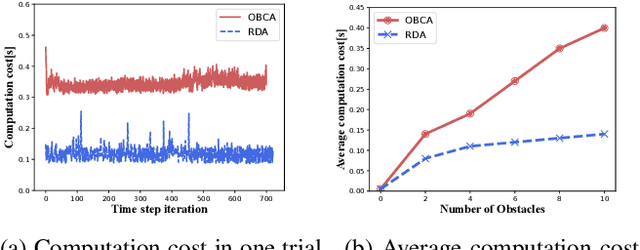
Motion planning is challenging for autonomous systems in multi-obstacle environments due to nonconvex collision avoidance constraints. Directly applying numerical solvers to these nonconvex formulations fails to exploit the constraint structures, resulting in excessive computation time. In this paper, we present an accelerated collision-free motion planner, namely regularized dual alternating direction method of multipliers (RDADMM or RDA for short), for the model predictive control (MPC) based motion planning problem. The proposed RDA addresses nonconvex motion planning via solving a smooth biconvex reformulation via duality and allows the collision avoidance constraints to be computed in parallel for each obstacle to reduce computation time significantly. We validate the performance of the RDA planner through path-tracking experiments with car-like robots in simulation and real world setting. Experimental results show that the proposed methods can generate smooth collision-free trajectories with less computation time compared with other benchmarks and perform robustly in cluttered environments.
Learning Filter-Based Compressed Blind-Deconvolution
Sep 28, 2022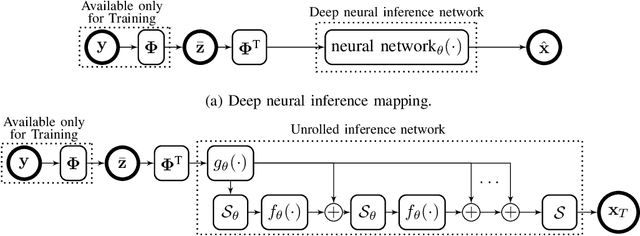
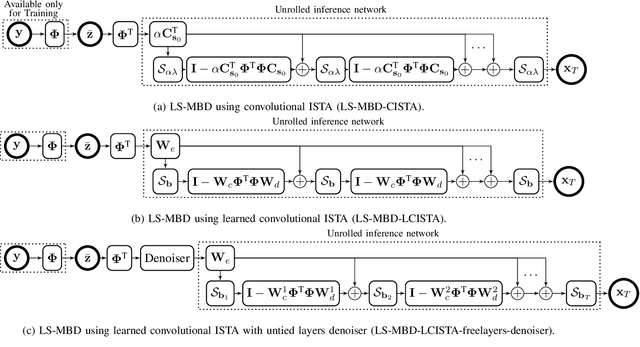
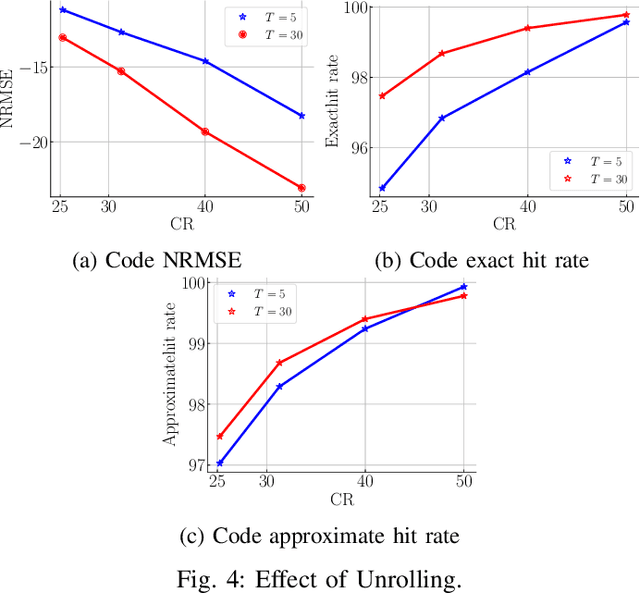
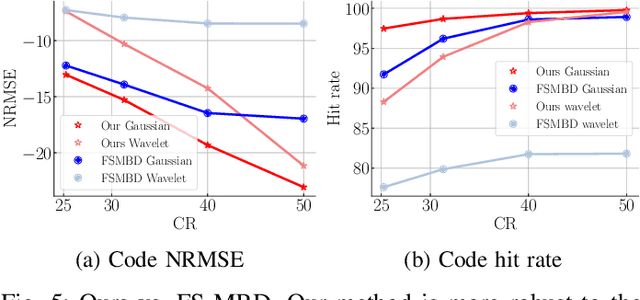
The problem of sparse multichannel blind deconvolution (S-MBD) arises frequently in many engineering applications such as radar/sonar/ultrasound imaging. To reduce its computational and implementation cost, we propose a compression method that enables blind recovery from much fewer measurements with respect to the full received signal in time. The proposed compression measures the signal through a filter followed by a subsampling, allowing for a significant reduction in implementation cost. We derive theoretical guarantees for the identifiability and recovery of a sparse filter from compressed measurements. Our results allow for the design of a wide class of compression filters. We, then, propose a data-driven unrolled learning framework to learn the compression filter and solve the S-MBD problem. The encoder is a recurrent inference network that maps compressed measurements into an estimate of sparse filters. We demonstrate that our unrolled learning method is more robust to choices of source shapes and has better recovery performance compared to optimization-based methods. Finally, in applications with limited data (fewshot learning), we highlight the superior generalization capability of unrolled learning compared to conventional deep learning.
Design and Analysis of Hardware-limited Non-uniform Task-based Quantizers
Aug 16, 2022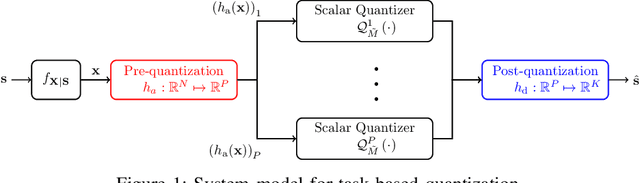
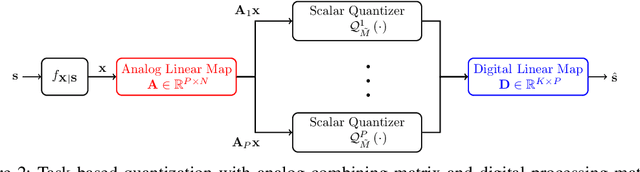
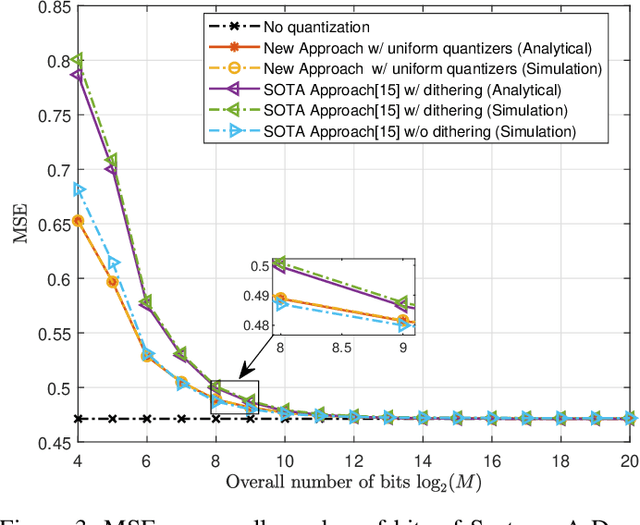
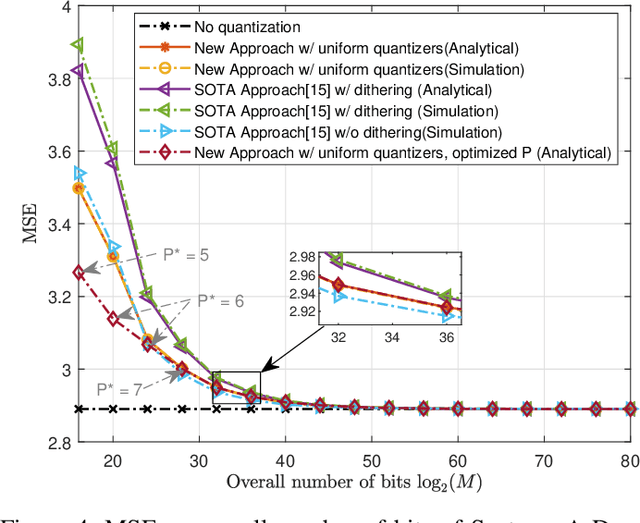
Hardware-limited task-based quantization is a new design paradigm for data acquisition systems equipped with serial scalar analog-to-digital converters using a small number of bits. By taking into account the underlying system task, task-based quantizers can efficiently recover the desired parameters from the low-bit quantized observation. Current design and analysis frameworks for hardware-limited task-based quantization are only applicable to inputs with bounded support and uniform quantizers with non-subtractive dithering. Here, we propose a new framework based on generalized Bussgang decomposition that enables the design and analysis of hardware-limited task-based quantizers that are equipped with non-uniform scalar quantizers or that have inputs with unbounded support. We first consider the scenario in which the task is linear. Under this scenario, we derive new pre-quantization and post-quantization linear mappings for task-based quantizers with mean squared error (MSE) that closely matches the theoretical MSE. Next, we extend the proposed analysis framework to quadratic tasks. We demonstrate that our derived analytical expression for the MSE accurately predicts the performance of task-based quantizers with quadratic tasks.
Unitary Approximate Message Passing for Matrix Factorization
Jul 31, 2022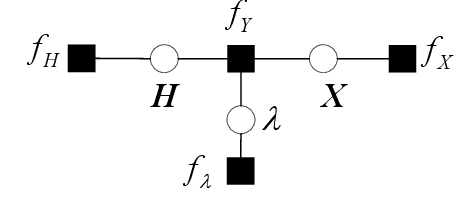
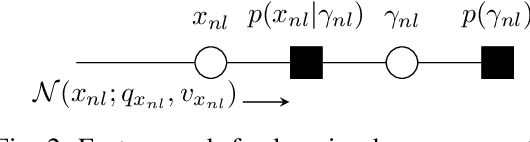
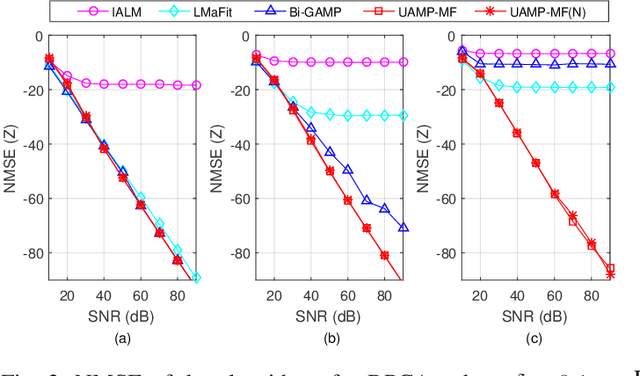
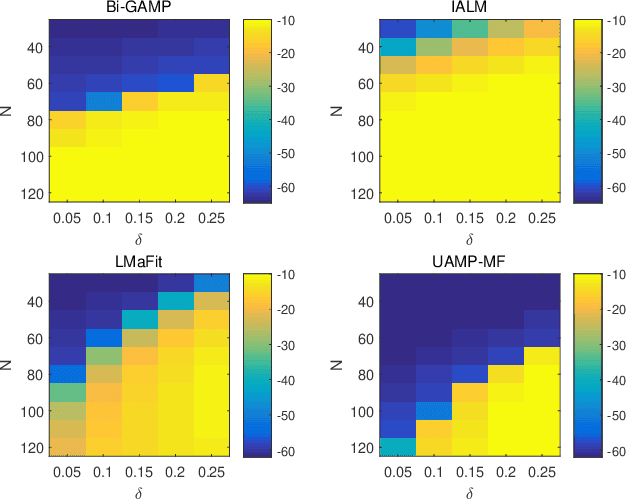
We consider matrix factorization (MF) with certain constraints, which finds wide applications in various areas. Leveraging variational inference (VI) and unitary approximate message passing (UAMP), we develop a Bayesian approach to MF with an efficient message passing implementation, called UAMPMF. With proper priors imposed on the factor matrices, UAMPMF can be used to solve many problems that can be formulated as MF, such as non negative matrix factorization, dictionary learning, compressive sensing with matrix uncertainty, robust principal component analysis, and sparse matrix factorization. Extensive numerical examples are provided to show that UAMPMF significantly outperforms state-of-the-art algorithms in terms of recovery accuracy, robustness and computational complexity.
Deep Learning Based Successive Interference Cancellation for the Non-Orthogonal Downlink
Jul 29, 2022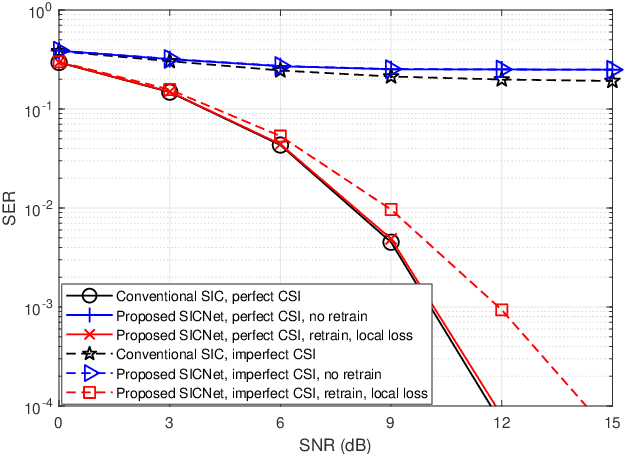
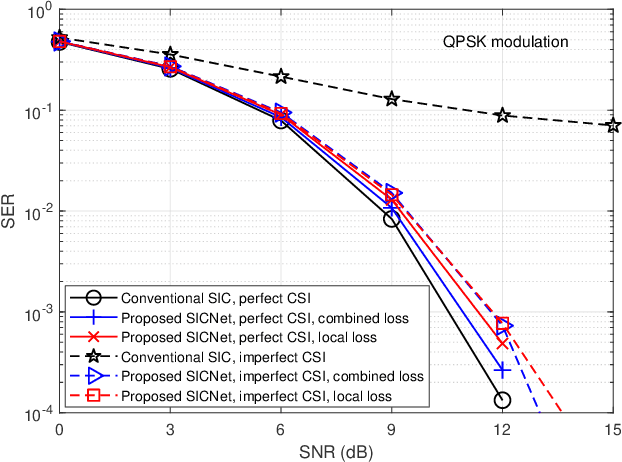
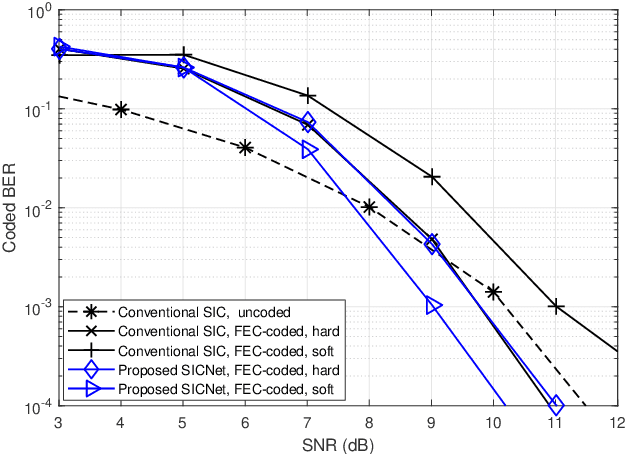
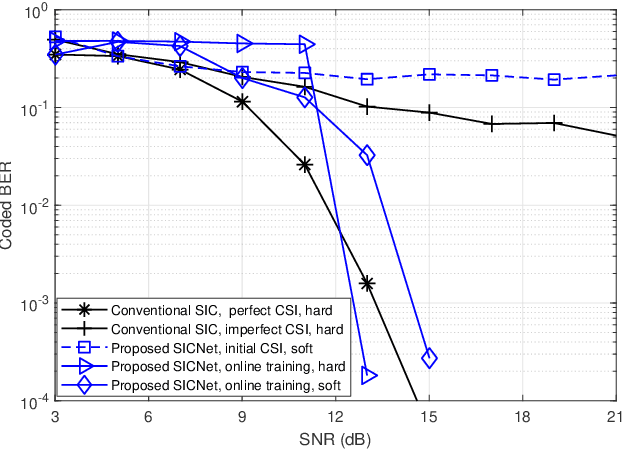
Non-orthogonal communications are expected to play a key role in future wireless systems. In downlink transmissions, the data symbols are broadcast from a base station to different users, which are superimposed with different power to facilitate high-integrity detection using successive interference cancellation (SIC). However, SIC requires accurate knowledge of both the channel model and channel state information (CSI), which may be difficult to acquire. We propose a deep learningaided SIC detector termed SICNet, which replaces the interference cancellation blocks of SIC by deep neural networks (DNNs). Explicitly, SICNet jointly trains its internal DNN-aided blocks for inferring the soft information representing the interfering symbols in a data-driven fashion, rather than using hard-decision decoders as in classical SIC. As a result, SICNet reliably detects the superimposed symbols in the downlink of non-orthogonal systems without requiring any prior knowledge of the channel model, while being less sensitive to CSI uncertainty than its model-based counterpart. SICNet is also robust to changes in the number of users and to their power allocation. Furthermore, SICNet learns to produce accurate soft outputs, which facilitates improved soft-input error correction decoding compared to model-based SIC. Finally, we propose an online training method for SICNet under block fading, which exploits the channel decoding for accurately recovering online data labels for retraining, hence, allowing it to smoothly track the fading envelope without requiring dedicated pilots. Our numerical results show that SICNet approaches the performance of classical SIC under perfect CSI, while outperforming it under realistic CSI uncertainty.