 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifference Feedback: Generating Multimodal Process-Level Supervision for VLM Reinforcement Learning
Mar 29, 2026Vision--language models (VLMs) are increasingly aligned via Group Relative Policy Optimization (GRPO)-style training. However, relying solely on terminal outcome rewards yields sparse credit assignment in multi-step reasoning, weakening the linkage between visual evidence and intermediate steps and often causing unstable optimization and visual hallucinations. We propose Differential Feedback, which automatically constructs token/step-level supervision masks by repairing erroneous reasoning trajectories, explicitly marking the key positions that require correction. Without costly large-scale step-by-step human annotations, our method enables process-level visual alignment and can be seamlessly integrated into existing GRPO-like frameworks. Experiments on multimodal reasoning benchmarks including MMMStar and MathVista show an average 3% improvement under matched compute budgets. Our approach offers an effective, low-cost solution for accurate vision--reasoning process alignment.
MetaWorld-X: Hierarchical World Modeling via VLM-Orchestrated Experts for Humanoid Loco-Manipulation
Mar 09, 2026Learning natural, stable, and compositionally generalizable whole-body control policies for humanoid robots performing simultaneous locomotion and manipulation (loco-manipulation) remains a fundamental challenge in robotics. Existing reinforcement learning approaches typically rely on a single monolithic policy to acquire multiple skills, which often leads to cross-skill gradient interference and motion pattern conflicts in high-degree-of-freedom systems. As a result, generated behaviors frequently exhibit unnatural movements, limited stability, and poor generalization to complex task compositions. To address these limitations, we propose MetaWorld-X, a hierarchical world model framework for humanoid control. Guided by a divide-and-conquer principle, our method decomposes complex control problems into a set of specialized expert policies (Specialized Expert Policies, SEP). Each expert is trained under human motion priors through imitation-constrained reinforcement learning, introducing biomechanically consistent inductive biases that ensure natural and physically plausible motion generation. Building upon this foundation, we further develop an Intelligent Routing Mechanism (IRM) supervised by a Vision-Language Model (VLM), enabling semantic-driven expert composition. The VLM-guided router dynamically integrates expert policies according to high-level task semantics, facilitating compositional generalization and adaptive execution in multi-stage loco-manipulation tasks.
Order Is Not Layout: Order-to-Space Bias in Image Generation
Mar 04, 2026We study a systematic bias in modern image generation models: the mention order of entities in text spuriously determines spatial layout and entity--role binding. We term this phenomenon Order-to-Space Bias (OTS) and show that it arises in both text-to-image and image-to-image generation, often overriding grounded cues and causing incorrect layouts or swapped assignments. To quantify OTS, we introduce OTS-Bench, which isolates order effects with paired prompts differing only in entity order and evaluates models along two dimensions: homogenization and correctness. Experiments show that Order-to-Space Bias (OTS) is widespread in modern image generation models, and provide evidence that it is primarily data-driven and manifests during the early stages of layout formation. Motivated by this insight, we show that both targeted fine-tuning and early-stage intervention strategies can substantially reduce OTS, while preserving generation quality.
Learning with Challenges: Adaptive Difficulty-Aware Data Generation for Mobile GUI Agent Training
Jan 30, 2026Large-scale, high-quality interaction trajectories are essential for advancing mobile Graphical User Interface (GUI) agents. While existing methods typically rely on labor-intensive human demonstrations or automated model exploration to generate GUI trajectories, they lack fine-grained control over task difficulty. This fundamentally restricts learning effectiveness due to the mismatch between the training difficulty and the agent's capabilities. Inspired by how humans acquire skills through progressively challenging tasks, we propose MobileGen, a novel data generation framework that adaptively aligns training difficulty with the GUI agent's capability frontier. Specifically, MobileGen explicitly decouples task difficulty into structural (e.g., trajectory length) and semantic (e.g., task goal) dimensions. It then iteratively evaluates the agent on a curated prior dataset to construct a systematic profile of its capability frontier across these two dimensions. With this profile, the probability distribution of task difficulty is adaptively computed, from which the target difficulty for the next round of training can be sampled. Guided by the sampled difficulty, a multi-agent controllable generator is finally used to synthesize high-quality interaction trajectories along with corresponding task instructions. Extensive experiments show that MobileGen consistently outperforms existing data generation methods by improving the average performance of GUI agents by 1.57 times across multiple challenging benchmarks. This highlights the importance of capability-aligned data generation for effective mobile GUI agent training.
MVSS: A Unified Framework for Multi-View Structured Survey Generation
Jan 14, 2026Scientific surveys require not only summarizing large bodies of literature, but also organizing them into clear and coherent conceptual structures. Existing automatic survey generation methods typically focus on linear text generation and struggle to explicitly model hierarchical relations among research topics and structured methodological comparisons, resulting in gaps in structural organization compared to expert-written surveys. We propose MVSS, a multi-view structured survey generation framework that jointly generates and aligns citation-grounded hierarchical trees, structured comparison tables, and survey text. MVSS follows a structure-first paradigm: it first constructs a conceptual tree of the research domain, then generates comparison tables constrained by the tree, and finally uses both as structural constraints for text generation. This enables complementary multi-view representations across structure, comparison, and narrative. We introduce an evaluation framework assessing structural quality, comparative completeness, and citation fidelity. Experiments on 76 computer science topics show MVSS outperforms existing methods in organization and evidence grounding, achieving performance comparable to expert surveys.
Temporal Transformer Networks with Self-Supervision for Action Recognition
Dec 17, 2021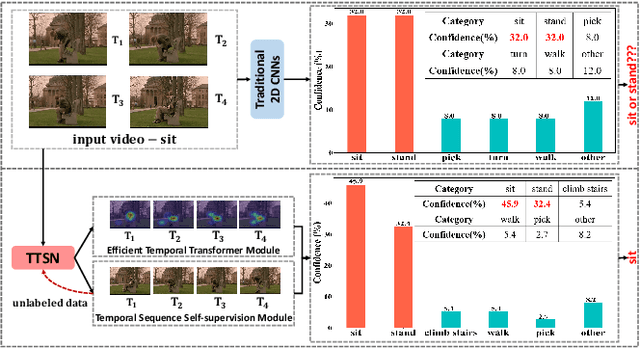
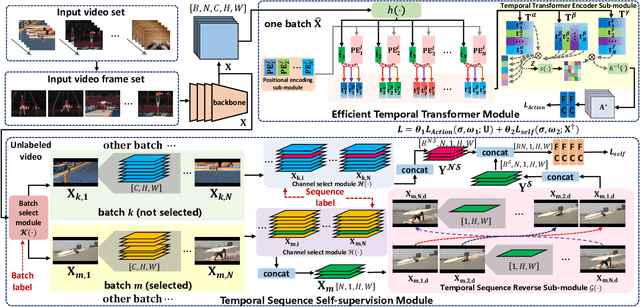
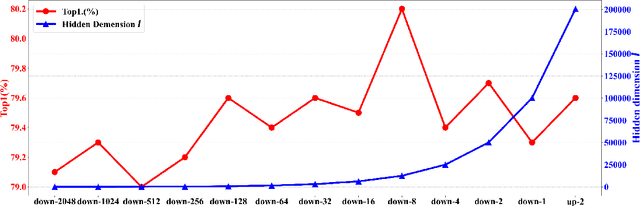
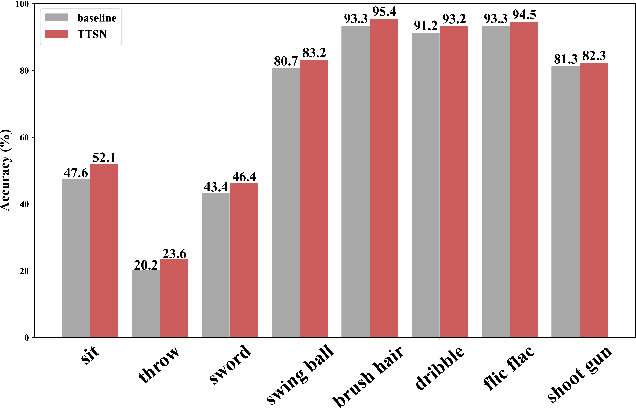
In recent years, 2D Convolutional Networks-based video action recognition has encouragingly gained wide popularity; However, constrained by the lack of long-range non-linear temporal relation modeling and reverse motion information modeling, the performance of existing models is, therefore, undercut seriously. To address this urgent problem, we introduce a startling Temporal Transformer Network with Self-supervision (TTSN). Our high-performance TTSN mainly consists of a temporal transformer module and a temporal sequence self-supervision module. Concisely speaking, we utilize the efficient temporal transformer module to model the non-linear temporal dependencies among non-local frames, which significantly enhances complex motion feature representations. The temporal sequence self-supervision module we employ unprecedentedly adopts the streamlined strategy of "random batch random channel" to reverse the sequence of video frames, allowing robust extractions of motion information representation from inversed temporal dimensions and improving the generalization capability of the model. Extensive experiments on three widely used datasets (HMDB51, UCF101, and Something-something V1) have conclusively demonstrated that our proposed TTSN is promising as it successfully achieves state-of-the-art performance for action recognition.