 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Critical LiDAR-Inertial Odometry with On-Manifold Deterministic Protection Level
May 10, 2026In safety-critical scenarios, the protection level of the autonomous navigation system is crucial for enabling mobile robots to perform safe tasks. However, existing studies on probabilistic navigation systems for robots usually perform offline accuracy evaluations using limited datasets and assume that the results can be applied to unknown real-world environments. As a result, current autonomous mobile robots often lack protection levels for online safety assessment. To fill this gap, we propose a safety-critical LiDAR-inertial odometry (LIO) that provides deterministic protection levels based on on-manifold deterministic state estimation. By adopting the unknown but bounded assumption, we derive a neat closed-form relationship between point cloud noise and the uncertainty of the estimation from the iterated closest point algorithm. Using this relationship, we design an on-manifold ellipsoidal set-membership filter and implement it within the LIO system. Leveraging the properties of the set-membership filter, our system offers the feasible sets of the estimated locations as the deterministic protection levels, serving as safety references for the robots' downstream autonomous operations. The experimental results show that our system can provide effective deterministic online safety references for diverse robots in various environments.
Silo-Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi-Agent LLM Systems
Mar 01, 2026Large language models are increasingly deployed in multi-agent systems to overcome context limitations by distributing information across agents. Yet whether agents can reliably compute with distributed information -- rather than merely exchange it -- remains an open question. We introduce Silo-Bench, a role-agnostic benchmark of 30 algorithmic tasks across three communication complexity levels, evaluating 54 configurations over 1,620 experiments. Our experiments expose a fundamental Communication-Reasoning Gap: agents spontaneously form task-appropriate coordination topologies and exchange information actively, yet systematically fail to synthesize distributed state into correct answers. The failure is localized to the reasoning-integration stage -- agents often acquire sufficient information but cannot integrate it. This coordination overhead compounds with scale, eventually eliminating parallelization gains entirely. These findings demonstrate that naively scaling agent count cannot circumvent context limitations, and Silo-Bench provides a foundation for tracking progress toward genuinely collaborative multi-agent systems.
MVSS: A Unified Framework for Multi-View Structured Survey Generation
Jan 14, 2026Scientific surveys require not only summarizing large bodies of literature, but also organizing them into clear and coherent conceptual structures. Existing automatic survey generation methods typically focus on linear text generation and struggle to explicitly model hierarchical relations among research topics and structured methodological comparisons, resulting in gaps in structural organization compared to expert-written surveys. We propose MVSS, a multi-view structured survey generation framework that jointly generates and aligns citation-grounded hierarchical trees, structured comparison tables, and survey text. MVSS follows a structure-first paradigm: it first constructs a conceptual tree of the research domain, then generates comparison tables constrained by the tree, and finally uses both as structural constraints for text generation. This enables complementary multi-view representations across structure, comparison, and narrative. We introduce an evaluation framework assessing structural quality, comparative completeness, and citation fidelity. Experiments on 76 computer science topics show MVSS outperforms existing methods in organization and evidence grounding, achieving performance comparable to expert surveys.
Working memory inspired hierarchical video decomposition with transformative representations
Apr 25, 2022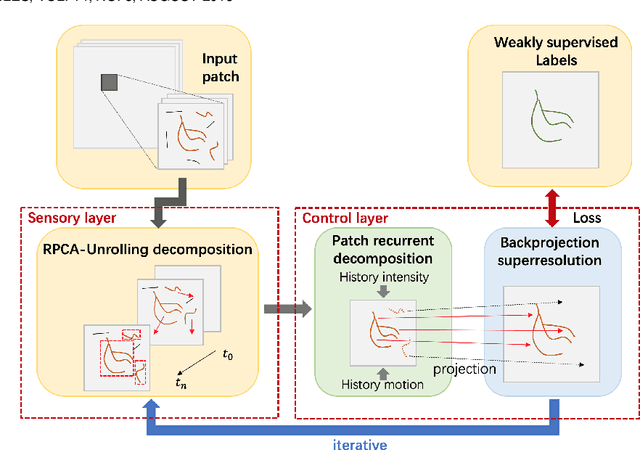
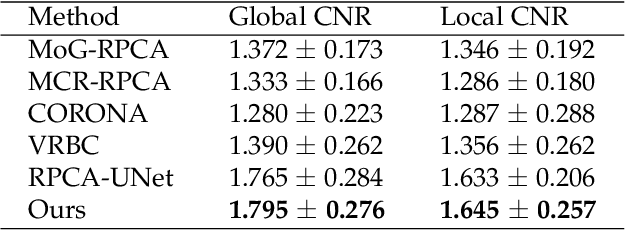
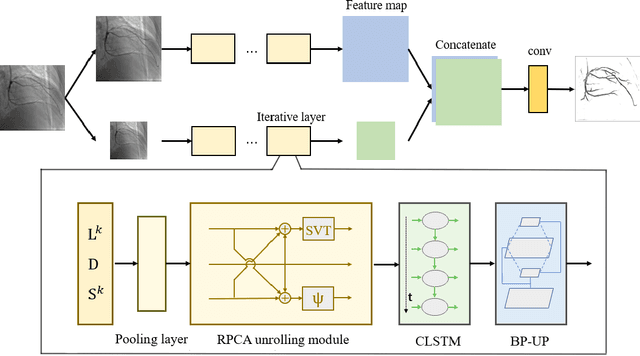
Video decomposition is very important to extract moving foreground objects from complex backgrounds in computer vision, machine learning, and medical imaging, e.g., extracting moving contrast-filled vessels from the complex and noisy backgrounds of X-ray coronary angiography (XCA). However, the challenges caused by dynamic backgrounds, overlapping heterogeneous environments and complex noises still exist in video decomposition. To solve these problems, this study is the first to introduce a flexible visual working memory model in video decomposition tasks to provide interpretable and high-performance hierarchical deep architecture, integrating the transformative representations between sensory and control layers from the perspective of visual and cognitive neuroscience. Specifically, robust PCA unrolling networks acting as a structure-regularized sensor layer decompose XCA into sparse/low-rank structured representations to separate moving contrast-filled vessels from noisy and complex backgrounds. Then, patch recurrent convolutional LSTM networks with a backprojection module embody unstructured random representations of the control layer in working memory, recurrently projecting spatiotemporally decomposed nonlocal patches into orthogonal subspaces for heterogeneous vessel retrieval and interference suppression. This video decomposition deep architecture effectively restores the heterogeneous profiles of intensity and the geometries of moving objects against the complex background interferences. Experiments show that the proposed method significantly outperforms state-of-the-art methods in accurate moving contrast-filled vessel extraction with excellent flexibility and computational efficiency.
Robust PCA Unrolling Network for Super-resolution Vessel Extraction in X-ray Coronary Angiography
Apr 24, 2022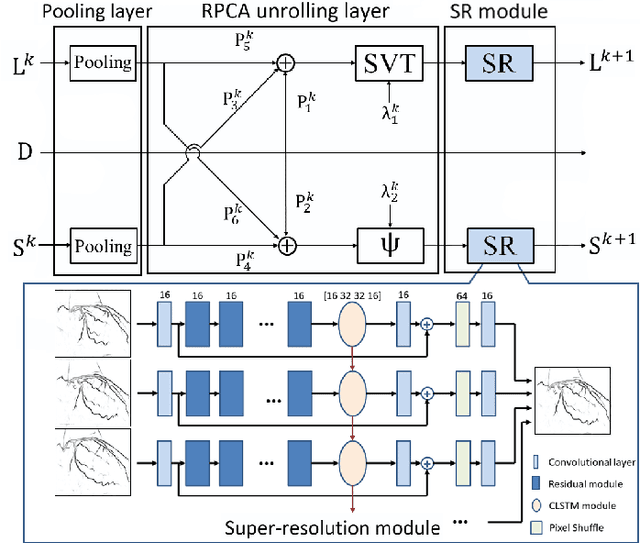
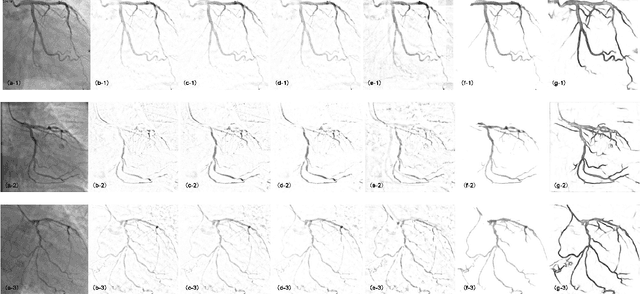

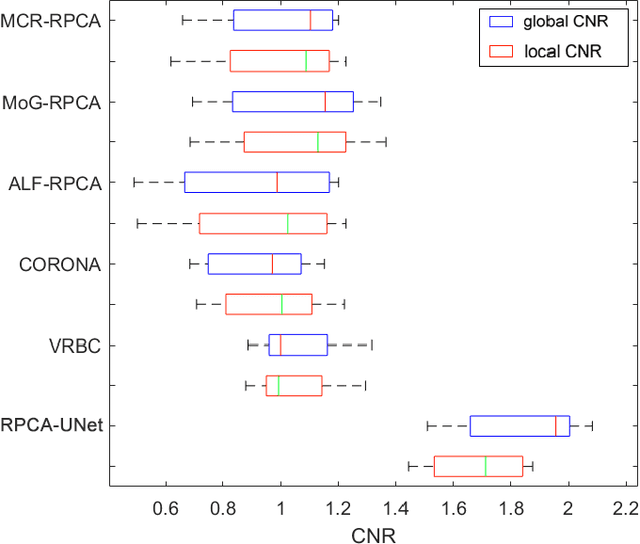
Although robust PCA has been increasingly adopted to extract vessels from X-ray coronary angiography (XCA) images, challenging problems such as inefficient vessel-sparsity modelling, noisy and dynamic background artefacts, and high computational cost still remain unsolved. Therefore, we propose a novel robust PCA unrolling network with sparse feature selection for super-resolution XCA vessel imaging. Being embedded within a patch-wise spatiotemporal super-resolution framework that is built upon a pooling layer and a convolutional long short-term memory network, the proposed network can not only gradually prune complex vessel-like artefacts and noisy backgrounds in XCA during network training but also iteratively learn and select the high-level spatiotemporal semantic information of moving contrast agents flowing in the XCA-imaged vessels. The experimental results show that the proposed method significantly outperforms state-of-the-art methods, especially in the imaging of the vessel network and its distal vessels, by restoring the intensity and geometry profiles of heterogeneous vessels against complex and dynamic backgrounds.
Sequential vessel segmentation via deep channel attention network
Feb 10, 2021
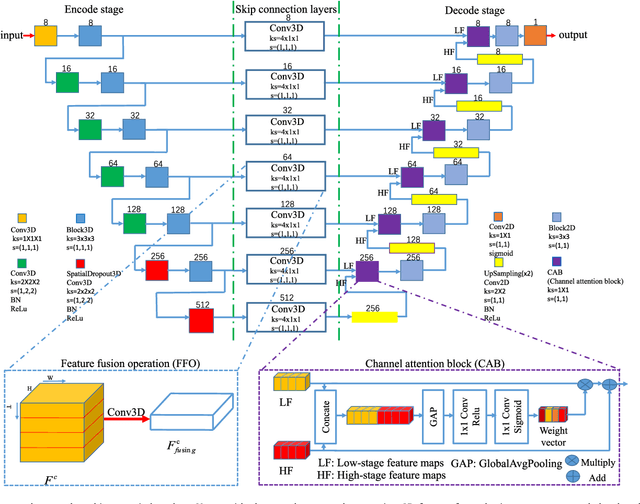
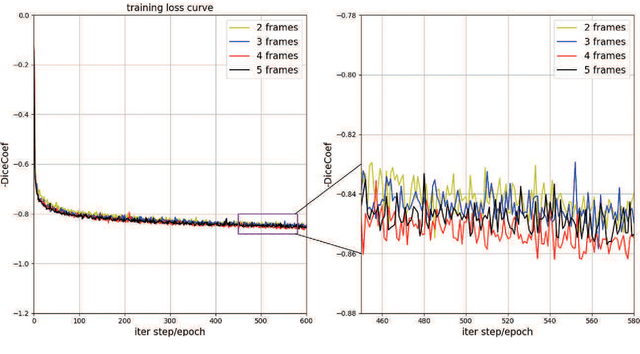
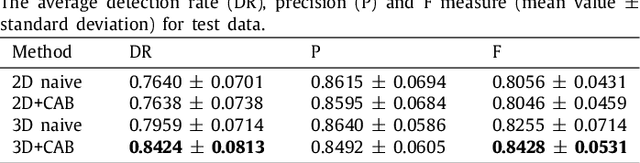
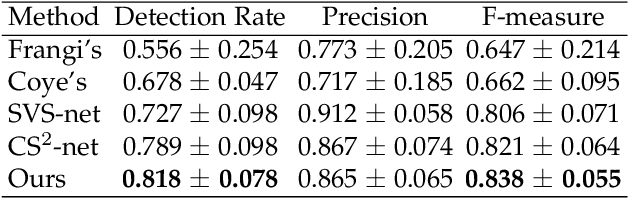
This paper develops a novel encoder-decoder deep network architecture which exploits the several contextual frames of 2D+t sequential images in a sliding window centered at current frame to segment 2D vessel masks from the current frame. The architecture is equipped with temporal-spatial feature extraction in encoder stage, feature fusion in skip connection layers and channel attention mechanism in decoder stage. In the encoder stage, a series of 3D convolutional layers are employed to hierarchically extract temporal-spatial features. Skip connection layers subsequently fuse the temporal-spatial feature maps and deliver them to the corresponding decoder stages. To efficiently discriminate vessel features from the complex and noisy backgrounds in the XCA images, the decoder stage effectively utilizes channel attention blocks to refine the intermediate feature maps from skip connection layers for subsequently decoding the refined features in 2D ways to produce the segmented vessel masks. Furthermore, Dice loss function is implemented to train the proposed deep network in order to tackle the class imbalance problem in the XCA data due to the wide distribution of complex background artifacts. Extensive experiments by comparing our method with other state-of-the-art algorithms demonstrate the proposed method's superior performance over other methods in terms of the quantitative metrics and visual validation. The source codes are at https://github.com/Binjie-Qin/SVS-net
* 14