 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-to-Sequence Ranking-based Concept-aware Learning Path Recommendation
Jun 07, 2023



With the development of the online education system, personalized education recommendation has played an essential role. In this paper, we focus on developing path recommendation systems that aim to generating and recommending an entire learning path to the given user in each session. Noticing that existing approaches fail to consider the correlations of concepts in the path, we propose a novel framework named Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation (SRC), which formulates the recommendation task under a set-to-sequence paradigm. Specifically, we first design a concept-aware encoder module which can capture the correlations among the input learning concepts. The outputs are then fed into a decoder module that sequentially generates a path through an attention mechanism that handles correlations between the learning and target concepts. Our recommendation policy is optimized by policy gradient. In addition, we also introduce an auxiliary module based on knowledge tracing to enhance the model's stability by evaluating students' learning effects on learning concepts. We conduct extensive experiments on two real-world public datasets and one industrial dataset, and the experimental results demonstrate the superiority and effectiveness of SRC. Code will be available at https://gitee.com/mindspore/models/tree/master/research/recommend/SRC.
MADiff: Offline Multi-agent Learning with Diffusion Models
May 27, 2023Diffusion model (DM), as a powerful generative model, recently achieved huge success in various scenarios including offline reinforcement learning, where the policy learns to conduct planning by generating trajectory in the online evaluation. However, despite the effectiveness shown for single-agent learning, it remains unclear how DMs can operate in multi-agent problems, where agents can hardly complete teamwork without good coordination by independently modeling each agent's trajectories. In this paper, we propose MADiff, a novel generative multi-agent learning framework to tackle this problem. MADiff is realized with an attention-based diffusion model to model the complex coordination among behaviors of multiple diffusion agents. To the best of our knowledge, MADiff is the first diffusion-based multi-agent offline RL framework, which behaves as both a decentralized policy and a centralized controller, which includes opponent modeling and can be used for multi-agent trajectory prediction. MADiff takes advantage of the powerful generative ability of diffusion while well-suited in modeling complex multi-agent interactions. Our experiments show the superior performance of MADiff compared to baseline algorithms in a range of multi-agent learning tasks.
Refined Edge Usage of Graph Neural Networks for Edge Prediction
Dec 25, 2022



Graph Neural Networks (GNNs), originally proposed for node classification, have also motivated many recent works on edge prediction (a.k.a., link prediction). However, existing methods lack elaborate design regarding the distinctions between two tasks that have been frequently overlooked: (i) edges only constitute the topology in the node classification task but can be used as both the topology and the supervisions (i.e., labels) in the edge prediction task; (ii) the node classification makes prediction over each individual node, while the edge prediction is determinated by each pair of nodes. To this end, we propose a novel edge prediction paradigm named Edge-aware Message PassIng neuRal nEtworks (EMPIRE). Concretely, we first introduce an edge splitting technique to specify use of each edge where each edge is solely used as either the topology or the supervision (named as topology edge or supervision edge). We then develop a new message passing mechanism that generates the messages to source nodes (through topology edges) being aware of target nodes (through supervision edges). In order to emphasize the differences between pairs connected by supervision edges and pairs unconnected, we further weight the messages to highlight the relative ones that can reflect the differences. In addition, we design a novel negative node-pair sampling trick that efficiently samples 'hard' negative instances in the supervision instances, and can significantly improve the performance. Experimental results verify that the proposed method can significantly outperform existing state-of-the-art models regarding the edge prediction task on multiple homogeneous and heterogeneous graph datasets.
Sim-to-Real Transfer for Quadrupedal Locomotion via Terrain Transformer
Dec 15, 2022Deep reinforcement learning has recently emerged as an appealing alternative for legged locomotion over multiple terrains by training a policy in physical simulation and then transferring it to the real world (i.e., sim-to-real transfer). Despite considerable progress, the capacity and scalability of traditional neural networks are still limited, which may hinder their applications in more complex environments. In contrast, the Transformer architecture has shown its superiority in a wide range of large-scale sequence modeling tasks, including natural language processing and decision-making problems. In this paper, we propose Terrain Transformer (TERT), a high-capacity Transformer model for quadrupedal locomotion control on various terrains. Furthermore, to better leverage Transformer in sim-to-real scenarios, we present a novel two-stage training framework consisting of an offline pretraining stage and an online correction stage, which can naturally integrate Transformer with privileged training. Extensive experiments in simulation demonstrate that TERT outperforms state-of-the-art baselines on different terrains in terms of return, energy consumption and control smoothness. In further real-world validation, TERT successfully traverses nine challenging terrains, including sand pit and stair down, which can not be accomplished by strong baselines.
A Bird's-eye View of Reranking: from List Level to Page Level
Nov 17, 2022Reranking, as the final stage of multi-stage recommender systems, refines the initial lists to maximize the total utility. With the development of multimedia and user interface design, the recommendation page has evolved to a multi-list style. Separately employing traditional list-level reranking methods for different lists overlooks the inter-list interactions and the effect of different page formats, thus yielding suboptimal reranking performance. Moreover, simply applying a shared network for all the lists fails to capture the commonalities and distinctions in user behaviors on different lists. To this end, we propose to draw a bird's-eye view of \textbf{page-level reranking} and design a novel Page-level Attentional Reranking (PAR) model. We introduce a hierarchical dual-side attention module to extract personalized intra- and inter-list interactions. A spatial-scaled attention network is devised to integrate the spatial relationship into pairwise item influences, which explicitly models the page format. The multi-gated mixture-of-experts module is further applied to capture the commonalities and differences of user behaviors between different lists. Extensive experiments on a public dataset and a proprietary dataset show that PAR significantly outperforms existing baseline models.
RITA: Boost Autonomous Driving Simulators with Realistic Interactive Traffic Flow
Nov 11, 2022



High-quality traffic flow generation is the core module in building simulators for autonomous driving. However, the majority of available simulators are incapable of replicating traffic patterns that accurately reflect the various features of real-world data while also simulating human-like reactive responses to the tested autopilot driving strategies. Taking one step forward to addressing such a problem, we propose Realistic Interactive TrAffic flow (RITA) as an integrated component of existing driving simulators to provide high-quality traffic flow for the evaluation and optimization of the tested driving strategies. RITA is developed with fidelity, diversity, and controllability in consideration, and consists of two core modules called RITABackend and RITAKit. RITABackend is built to support vehicle-wise control and provide traffic generation models from real-world datasets, while RITAKit is developed with easy-to-use interfaces for controllable traffic generation via RITABackend. We demonstrate RITA's capacity to create diversified and high-fidelity traffic simulations in several highly interactive highway scenarios. The experimental findings demonstrate that our produced RITA traffic flows meet all three design goals, hence enhancing the completeness of driving strategy evaluation. Moreover, we showcase the possibility for further improvement of baseline strategies through online fine-tuning with RITA traffic flows.
Understanding or Manipulation: Rethinking Online Performance Gains of Modern Recommender Systems
Oct 11, 2022

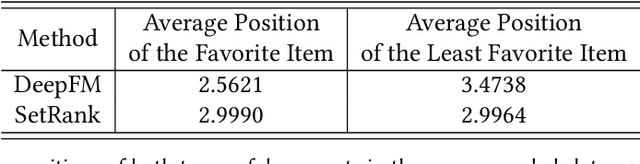
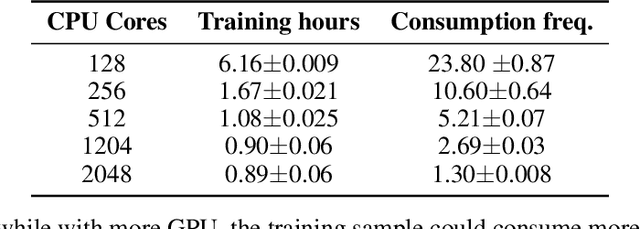
Recommender systems are expected to be assistants that help human users find relevant information in an automatic manner without explicit queries. As recommender systems evolve, increasingly sophisticated learning techniques are applied and have achieved better performance in terms of user engagement metrics such as clicks and browsing time. The increase of the measured performance, however, can have two possible attributions: a better understanding of user preferences, and a more proactive ability to utilize human bounded rationality to seduce user over-consumption. A natural following question is whether current recommendation algorithms are manipulating user preferences. If so, can we measure the manipulation level? In this paper, we present a general framework for benchmarking the degree of manipulations of recommendation algorithms, in both slate recommendation and sequential recommendation scenarios. The framework consists of three stages, initial preference calculation, algorithm training and interaction, and metrics calculation that involves two proposed metrics, Manipulation Score and Preference Shift. We benchmark some representative recommendation algorithms in both synthetic and real-world datasets under the proposed framework. We have observed that a high online click-through rate does not mean a better understanding of user initial preference, but ends in prompting users to choose more documents they initially did not favor. Moreover, we find that the properties of training data have notable impacts on the manipulation degrees, and algorithms with more powerful modeling abilities are more sensitive to such impacts. The experiments also verified the usefulness of the proposed metrics for measuring the degree of manipulations. We advocate that future recommendation algorithm studies should be treated as an optimization problem with constrained user preference manipulations.
Honor of Kings Arena: an Environment for Generalization in Competitive Reinforcement Learning
Oct 09, 2022

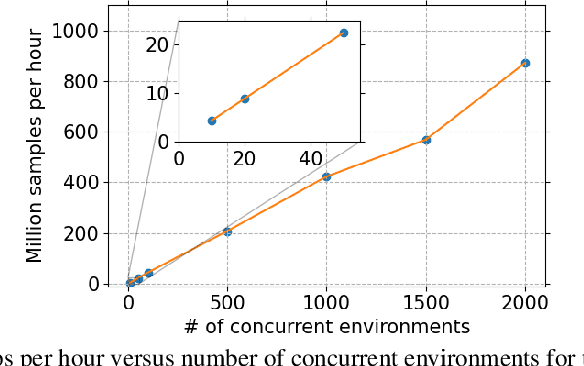
This paper introduces Honor of Kings Arena, a reinforcement learning (RL) environment based on Honor of Kings, one of the world's most popular games at present. Compared to other environments studied in most previous work, ours presents new generalization challenges for competitive reinforcement learning. It is a multi-agent problem with one agent competing against its opponent; and it requires the generalization ability as it has diverse targets to control and diverse opponents to compete with. We describe the observation, action, and reward specifications for the Honor of Kings domain and provide an open-source Python-based interface for communicating with the game engine. We provide twenty target heroes with a variety of tasks in Honor of Kings Arena and present initial baseline results for RL-based methods with feasible computing resources. Finally, we showcase the generalization challenges imposed by Honor of Kings Arena and possible remedies to the challenges. All of the software, including the environment-class, are publicly available at https://github.com/tencent-ailab/hok_env . The documentation is available at https://aiarena.tencent.com/hok/doc/ .
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 16, 2022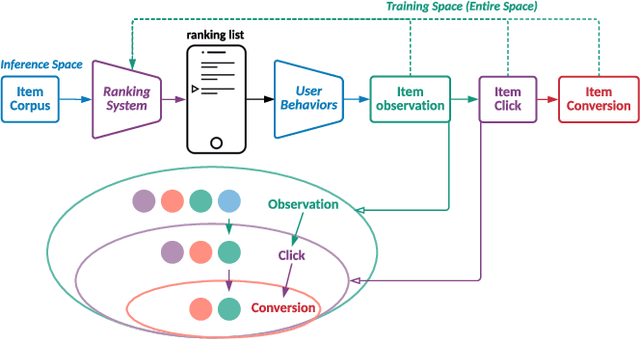

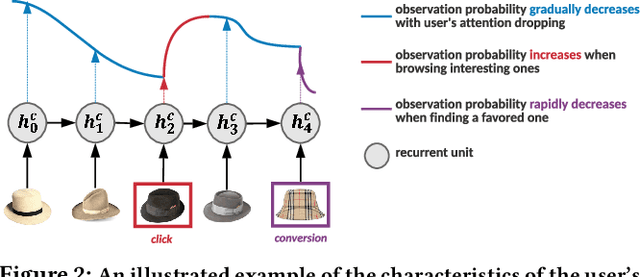
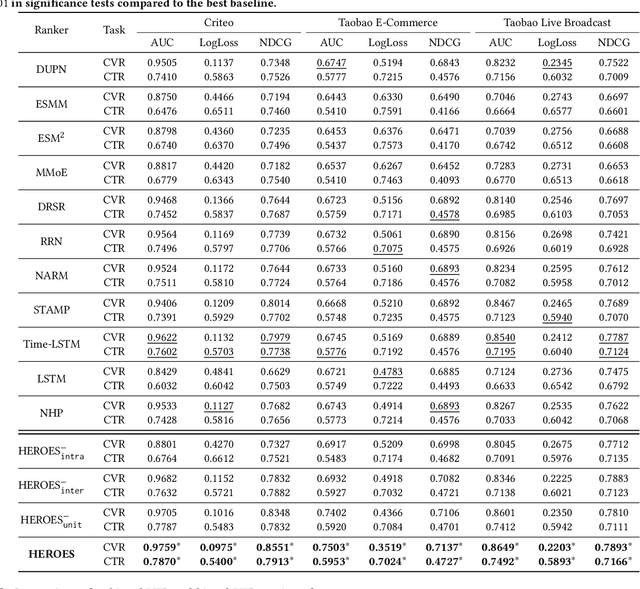
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.
Branch Ranking for Efficient Mixed-Integer Programming via Offline Ranking-based Policy Learning
Jul 26, 2022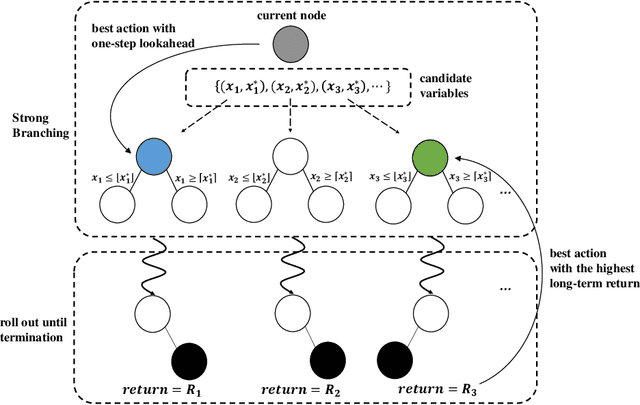
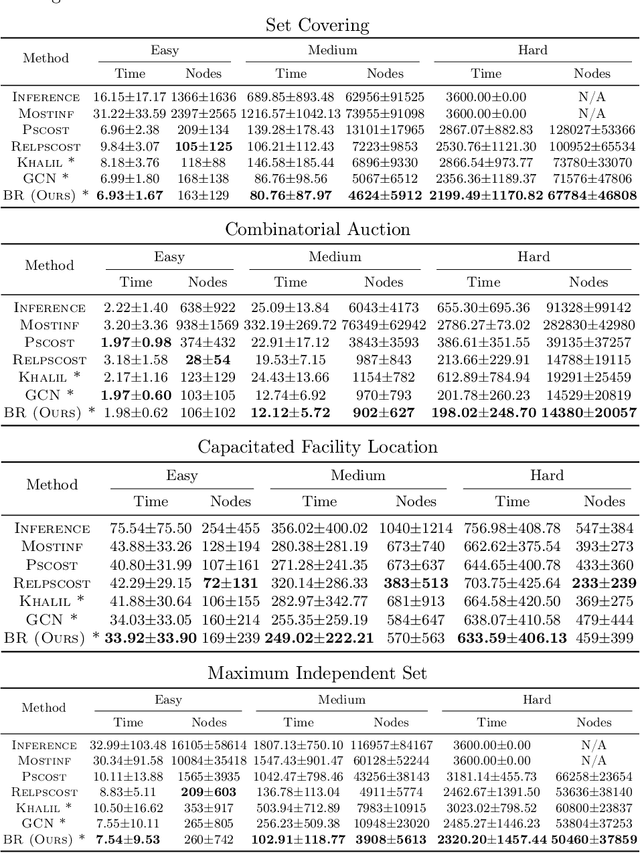
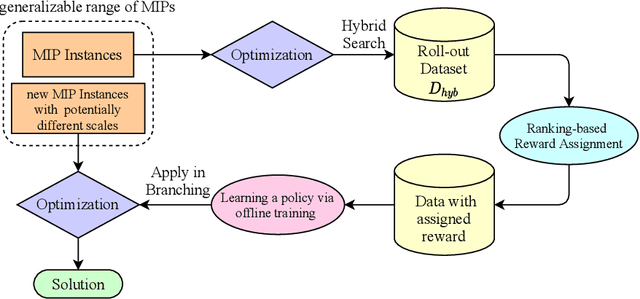

Deriving a good variable selection strategy in branch-and-bound is essential for the efficiency of modern mixed-integer programming (MIP) solvers. With MIP branching data collected during the previous solution process, learning to branch methods have recently become superior over heuristics. As branch-and-bound is naturally a sequential decision making task, one should learn to optimize the utility of the whole MIP solving process instead of being myopic on each step. In this work, we formulate learning to branch as an offline reinforcement learning (RL) problem, and propose a long-sighted hybrid search scheme to construct the offline MIP dataset, which values the long-term utilities of branching decisions. During the policy training phase, we deploy a ranking-based reward assignment scheme to distinguish the promising samples from the long-term or short-term view, and train the branching model named Branch Ranking via offline policy learning. Experiments on synthetic MIP benchmarks and real-world tasks demonstrate that Branch Rankink is more efficient and robust, and can better generalize to large scales of MIP instances compared to the widely used heuristics and state-of-the-art learning-based branching models.