 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Augmentation with SAM: Boosting Medical Image Segmentation with Segmentation Foundation Model
Apr 22, 2023



The Segment Anything Model (SAM) is a recently developed large model for general-purpose segmentation for computer vision tasks. SAM was trained using 11 million images with over 1 billion masks and can produce segmentation results for a wide range of objects in natural scene images. SAM can be viewed as a general perception model for segmentation (partitioning images into semantically meaningful regions). Thus, how to utilize such a large foundation model for medical image segmentation is an emerging research target. This paper shows that although SAM does not immediately give high-quality segmentation for medical images, its generated masks, features, and stability scores are useful for building and training better medical image segmentation models. In particular, we demonstrate how to use SAM to augment image inputs for a commonly-used medical image segmentation model (e.g., U-Net). Experiments on two datasets show the effectiveness of our proposed method.
Can SAM Segment Polyps?
Apr 15, 2023



Recently, Meta AI Research releases a general Segment Anything Model (SAM), which has demonstrated promising performance in several segmentation tasks. As we know, polyp segmentation is a fundamental task in the medical imaging field, which plays a critical role in the diagnosis and cure of colorectal cancer. In particular, applying SAM to the polyp segmentation task is interesting. In this report, we evaluate the performance of SAM in segmenting polyps, in which SAM is under unprompted settings. We hope this report will provide insights to advance this polyp segmentation field and promote more interesting works in the future. This project is publicly at https://github.com/taozh2017/SAMPolyp.
Interactive Text Generation
Mar 17, 2023



Users interact with text, image, code, or other editors on a daily basis. However, machine learning models are rarely trained in the settings that reflect the interactivity between users and their editor. This is understandable as training AI models with real users is not only slow and costly, but what these models learn may be specific to user interface design choices. Unfortunately, this means most of the research on text, code, and image generation has focused on non-interactive settings, whereby the model is expected to get everything right without accounting for any input from a user who may be willing to help. We introduce a new Interactive Text Generation task that allows training generation models interactively without the costs of involving real users, by using user simulators that provide edits that guide the model towards a given target text. We train our interactive models using Imitation Learning, and our experiments against competitive non-interactive generation models show that models trained interactively are superior to their non-interactive counterparts, even when all models are given the same budget of user inputs or edits.
Stabilizing Transformer Training by Preventing Attention Entropy Collapse
Mar 11, 2023Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we track the attention entropy for each attention head during the course of training, which is a proxy for model sharpness. We identify a common pattern across different architectures and tasks, where low attention entropy is accompanied by high training instability, which can take the form of oscillating loss or divergence. We denote the pathologically low attention entropy, corresponding to highly concentrated attention scores, as $\textit{entropy collapse}$. As a remedy, we propose $\sigma$Reparam, a simple and efficient solution where we reparametrize all linear layers with spectral normalization and an additional learned scalar. We demonstrate that the proposed reparameterization successfully prevents entropy collapse in the attention layers, promoting more stable training. Additionally, we prove a tight lower bound of the attention entropy, which decreases exponentially fast with the spectral norm of the attention logits, providing additional motivation for our approach. We conduct experiments with $\sigma$Reparam on image classification, image self-supervised learning, machine translation, automatic speech recognition, and language modeling tasks, across Transformer architectures. We show that $\sigma$Reparam provides stability and robustness with respect to the choice of hyperparameters, going so far as enabling training (a) a Vision Transformer to competitive performance without warmup, weight decay, layer normalization or adaptive optimizers; (b) deep architectures in machine translation and (c) speech recognition to competitive performance without warmup and adaptive optimizers.
GPT4MIA: Utilizing Geneative Pre-trained Transformer (GPT-3) as A Plug-and-Play Transductive Model for Medical Image Analysis
Feb 17, 2023In this paper, we propose a novel approach (called GPT4MIA) that utilizes Generative Pre-trained Transformer (GPT) as a plug-and-play transductive inference tool for medical image analysis (MIA). We provide theoretical analysis on why a large pre-trained language model such as GPT-3 can be used as a plug-and-play transductive inference model for MIA. At the methodological level, we develop several technical treatments to improve the efficiency and effectiveness of GPT4MIA, including better prompt structure design, sample selection, and prompt ordering of representative samples/features. We present two concrete use cases (with workflow) of GPT4MIA: (1) detecting prediction errors and (2) improving prediction accuracy, working in conjecture with well-established vision-based models for image classification (e.g., ResNet). Experiments validate that our proposed method is effective for these two tasks. We further discuss the opportunities and challenges in utilizing Transformer-based large language models for broader MIA applications.
EndoBoost: a plug-and-play module for false positive suppression during computer-aided polyp detection in real-world colonoscopy
Dec 23, 2022The advance of computer-aided detection systems using deep learning opened a new scope in endoscopic image analysis. However, the learning-based models developed on closed datasets are susceptible to unknown anomalies in complex clinical environments. In particular, the high false positive rate of polyp detection remains a major challenge in clinical practice. In this work, we release the FPPD-13 dataset, which provides a taxonomy and real-world cases of typical false positives during computer-aided polyp detection in real-world colonoscopy. We further propose a post-hoc module EndoBoost, which can be plugged into generic polyp detection models to filter out false positive predictions. This is realized by generative learning of the polyp manifold with normalizing flows and rejecting false positives through density estimation. Compared to supervised classification, this anomaly detection paradigm achieves better data efficiency and robustness in open-world settings. Extensive experiments demonstrate a promising false positive suppression in both retrospective and prospective validation. In addition, the released dataset can be used to perform 'stress' tests on established detection systems and encourages further research toward robust and reliable computer-aided endoscopic image analysis. The dataset and code will be publicly available at http://endoboost.miccai.cloud.
Bridging the Training-Inference Gap for Dense Phrase Retrieval
Oct 25, 2022Building dense retrievers requires a series of standard procedures, including training and validating neural models and creating indexes for efficient search. However, these procedures are often misaligned in that training objectives do not exactly reflect the retrieval scenario at inference time. In this paper, we explore how the gap between training and inference in dense retrieval can be reduced, focusing on dense phrase retrieval (Lee et al., 2021) where billions of representations are indexed at inference. Since validating every dense retriever with a large-scale index is practically infeasible, we propose an efficient way of validating dense retrievers using a small subset of the entire corpus. This allows us to validate various training strategies including unifying contrastive loss terms and using hard negatives for phrase retrieval, which largely reduces the training-inference discrepancy. As a result, we improve top-1 phrase retrieval accuracy by 2~3 points and top-20 passage retrieval accuracy by 2~4 points for open-domain question answering. Our work urges modeling dense retrievers with careful consideration of training and inference via efficient validation while advancing phrase retrieval as a general solution for dense retrieval.
f-DM: A Multi-stage Diffusion Model via Progressive Signal Transformation
Oct 10, 2022
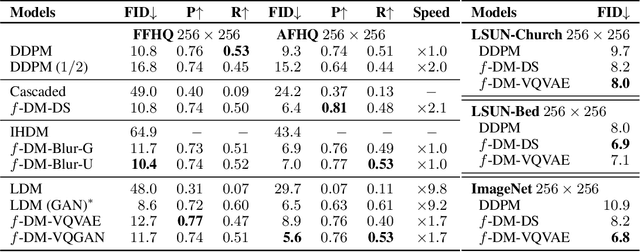
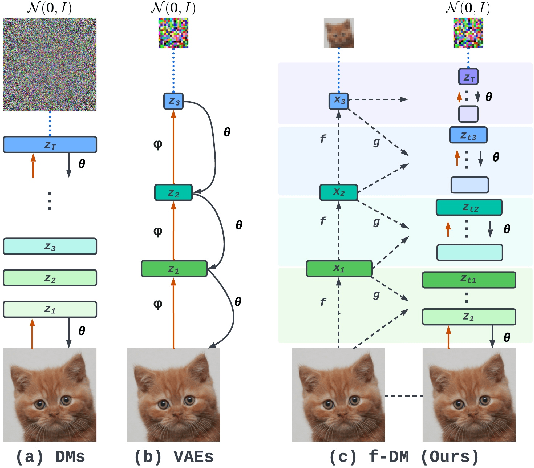
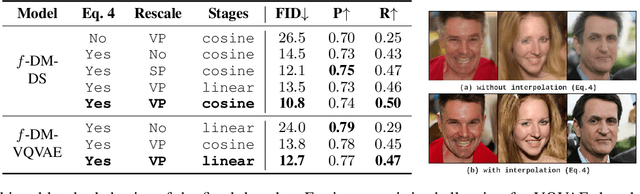
Diffusion models (DMs) have recently emerged as SoTA tools for generative modeling in various domains. Standard DMs can be viewed as an instantiation of hierarchical variational autoencoders (VAEs) where the latent variables are inferred from input-centered Gaussian distributions with fixed scales and variances. Unlike VAEs, this formulation limits DMs from changing the latent spaces and learning abstract representations. In this work, we propose f-DM, a generalized family of DMs which allows progressive signal transformation. More precisely, we extend DMs to incorporate a set of (hand-designed or learned) transformations, where the transformed input is the mean of each diffusion step. We propose a generalized formulation and derive the corresponding de-noising objective with a modified sampling algorithm. As a demonstration, we apply f-DM in image generation tasks with a range of functions, including down-sampling, blurring, and learned transformations based on the encoder of pretrained VAEs. In addition, we identify the importance of adjusting the noise levels whenever the signal is sub-sampled and propose a simple rescaling recipe. f-DM can produce high-quality samples on standard image generation benchmarks like FFHQ, AFHQ, LSUN, and ImageNet with better efficiency and semantic interpretation.
Data-Driven Deep Supervision for Skin Lesion Classification
Sep 04, 2022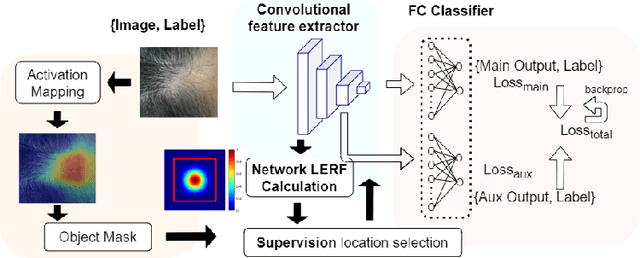
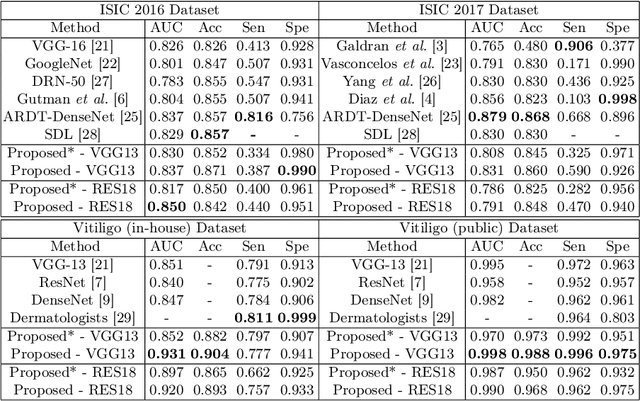

Automatic classification of pigmented, non-pigmented, and depigmented non-melanocytic skin lesions have garnered lots of attention in recent years. However, imaging variations in skin texture, lesion shape, depigmentation contrast, lighting condition, etc. hinder robust feature extraction, affecting classification accuracy. In this paper, we propose a new deep neural network that exploits input data for robust feature extraction. Specifically, we analyze the convolutional network's behavior (field-of-view) to find the location of deep supervision for improved feature extraction. To achieve this, first, we perform activation mapping to generate an object mask, highlighting the input regions most critical for classification output generation. Then the network layer whose layer-wise effective receptive field matches the approximated object shape in the object mask is selected as our focus for deep supervision. Utilizing different types of convolutional feature extractors and classifiers on three melanoma detection datasets and two vitiligo detection datasets, we verify the effectiveness of our new method.
Usable Region Estimate for Assessing Practical Usability of Medical Image Segmentation Models
Jul 01, 2022
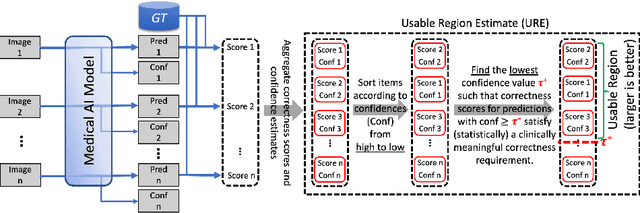
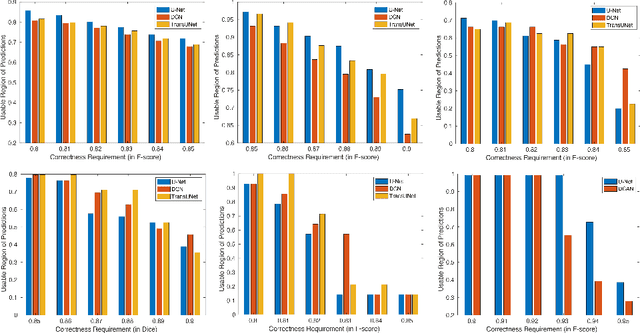
We aim to quantitatively measure the practical usability of medical image segmentation models: to what extent, how often, and on which samples a model's predictions can be used/trusted. We first propose a measure, Correctness-Confidence Rank Correlation (CCRC), to capture how predictions' confidence estimates correlate with their correctness scores in rank. A model with a high value of CCRC means its prediction confidences reliably suggest which samples' predictions are more likely to be correct. Since CCRC does not capture the actual prediction correctness, it alone is insufficient to indicate whether a prediction model is both accurate and reliable to use in practice. Therefore, we further propose another method, Usable Region Estimate (URE), which simultaneously quantifies predictions' correctness and reliability of confidence assessments in one estimate. URE provides concrete information on to what extent a model's predictions are usable. In addition, the sizes of usable regions (UR) can be utilized to compare models: A model with a larger UR can be taken as a more usable and hence better model. Experiments on six datasets validate that the proposed evaluation methods perform well, providing a concrete and concise measure for the practical usability of medical image segmentation models. Code is made available at https://github.com/yizhezhang2000/ure.