 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASRec: Weight Sharing Neural Architecture Search for Recommender Systems
Jul 14, 2022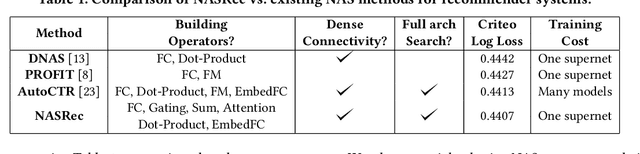
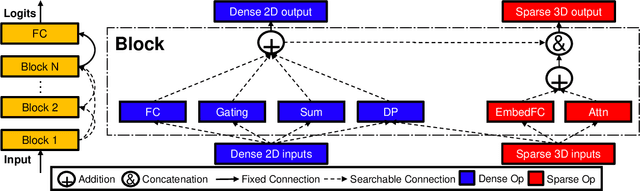
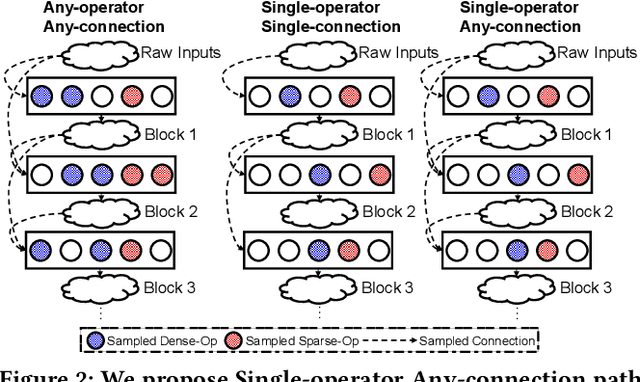

The rise of deep neural networks provides an important driver in optimizing recommender systems. However, the success of recommender systems lies in delicate architecture fabrication, and thus calls for Neural Architecture Search (NAS) to further improve its modeling. We propose NASRec, a paradigm that trains a single supernet and efficiently produces abundant models/sub-architectures by weight sharing. To overcome the data multi-modality and architecture heterogeneity challenges in recommendation domain, NASRec establishes a large supernet (i.e., search space) to search the full architectures, with the supernet incorporating versatile operator choices and dense connectivity minimizing human prior for flexibility. The scale and heterogeneity in NASRec impose challenges in search, such as training inefficiency, operator-imbalance, and degraded rank correlation. We tackle these challenges by proposing single-operator any-connection sampling, operator-balancing interaction modules, and post-training fine-tuning. Our results on three Click-Through Rates (CTR) prediction benchmarks show that NASRec can outperform both manually designed models and existing NAS methods, achieving state-of-the-art performance.
Towards Collaborative Intelligence: Routability Estimation based on Decentralized Private Data
Mar 30, 2022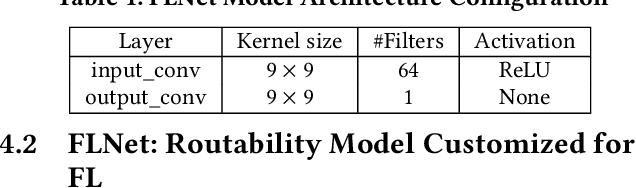
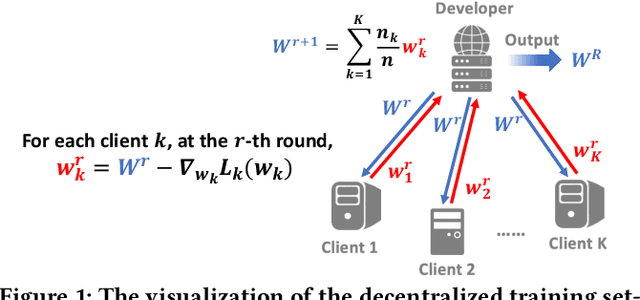
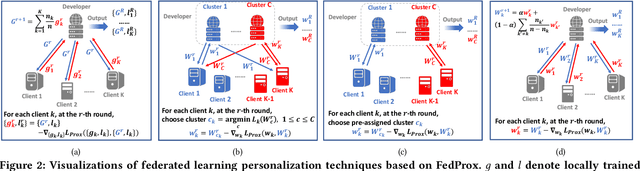
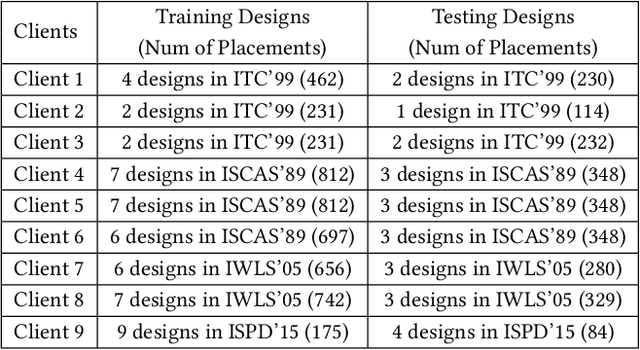
Applying machine learning (ML) in design flow is a popular trend in EDA with various applications from design quality predictions to optimizations. Despite its promise, which has been demonstrated in both academic researches and industrial tools, its effectiveness largely hinges on the availability of a large amount of high-quality training data. In reality, EDA developers have very limited access to the latest design data, which is owned by design companies and mostly confidential. Although one can commission ML model training to a design company, the data of a single company might be still inadequate or biased, especially for small companies. Such data availability problem is becoming the limiting constraint on future growth of ML for chip design. In this work, we propose an Federated-Learning based approach for well-studied ML applications in EDA. Our approach allows an ML model to be collaboratively trained with data from multiple clients but without explicit access to the data for respecting their data privacy. To further strengthen the results, we co-design a customized ML model FLNet and its personalization under the decentralized training scenario. Experiments on a comprehensive dataset show that collaborative training improves accuracy by 11% compared with individual local models, and our customized model FLNet significantly outperforms the best of previous routability estimators in this collaborative training flow.
The Dark Side: Security Concerns in Machine Learning for EDA
Mar 20, 2022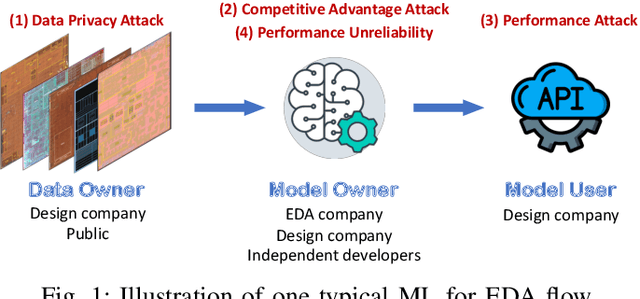
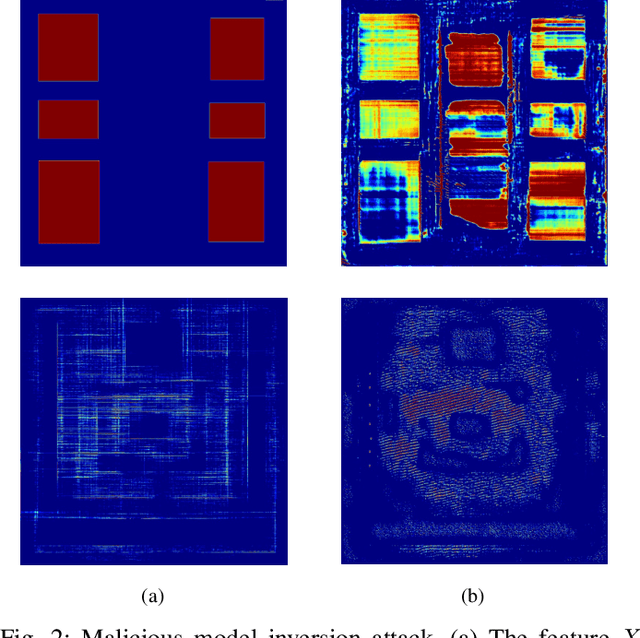

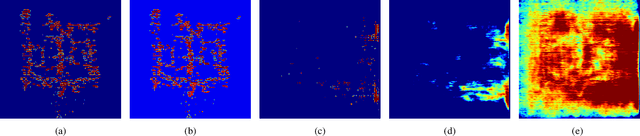
The growing IC complexity has led to a compelling need for design efficiency improvement through new electronic design automation (EDA) methodologies. In recent years, many unprecedented efficient EDA methods have been enabled by machine learning (ML) techniques. While ML demonstrates its great potential in circuit design, however, the dark side about security problems, is seldomly discussed. This paper gives a comprehensive and impartial summary of all security concerns we have observed in ML for EDA. Many of them are hidden or neglected by practitioners in this field. In this paper, we first provide our taxonomy to define four major types of security concerns, then we analyze different application scenarios and special properties in ML for EDA. After that, we present our detailed analysis of each security concern with experiments.
Privacy Leakage of Adversarial Training Models in Federated Learning Systems
Feb 21, 2022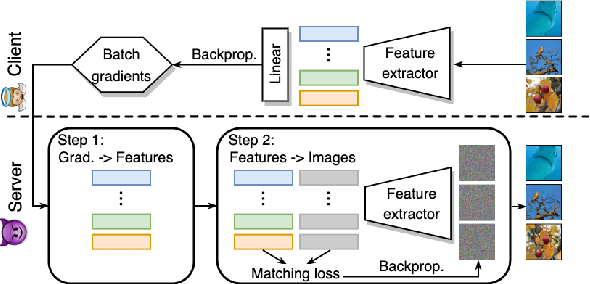
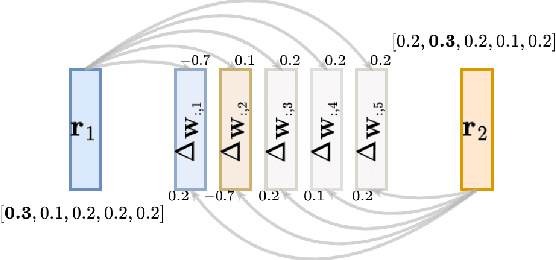
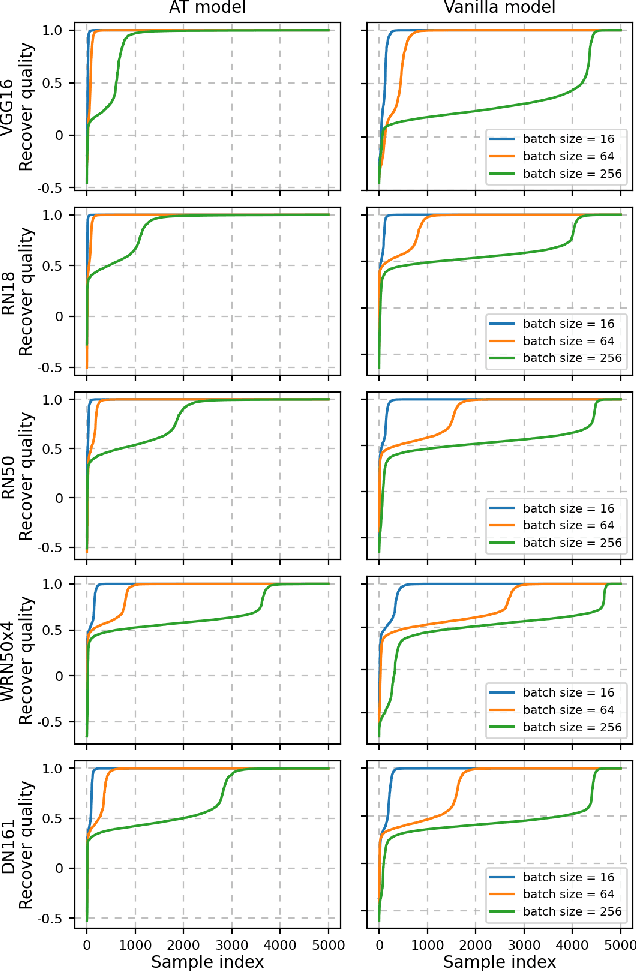
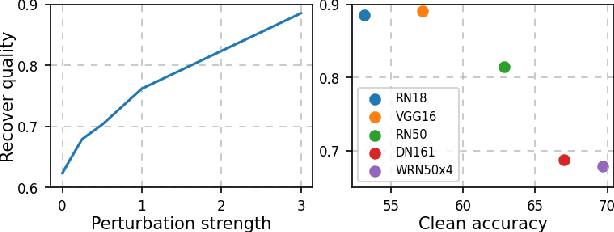
Adversarial Training (AT) is crucial for obtaining deep neural networks that are robust to adversarial attacks, yet recent works found that it could also make models more vulnerable to privacy attacks. In this work, we further reveal this unsettling property of AT by designing a novel privacy attack that is practically applicable to the privacy-sensitive Federated Learning (FL) systems. Using our method, the attacker can exploit AT models in the FL system to accurately reconstruct users' private training images even when the training batch size is large. Code is available at https://github.com/zjysteven/PrivayAttack_AT_FL.
HERO: Hessian-Enhanced Robust Optimization for Unifying and Improving Generalization and Quantization Performance
Nov 23, 2021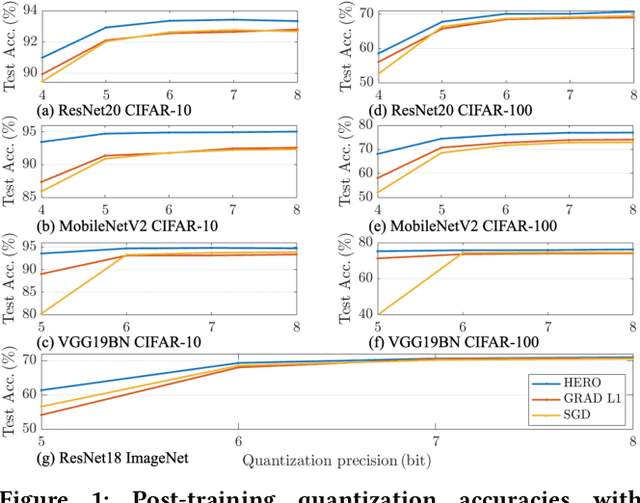
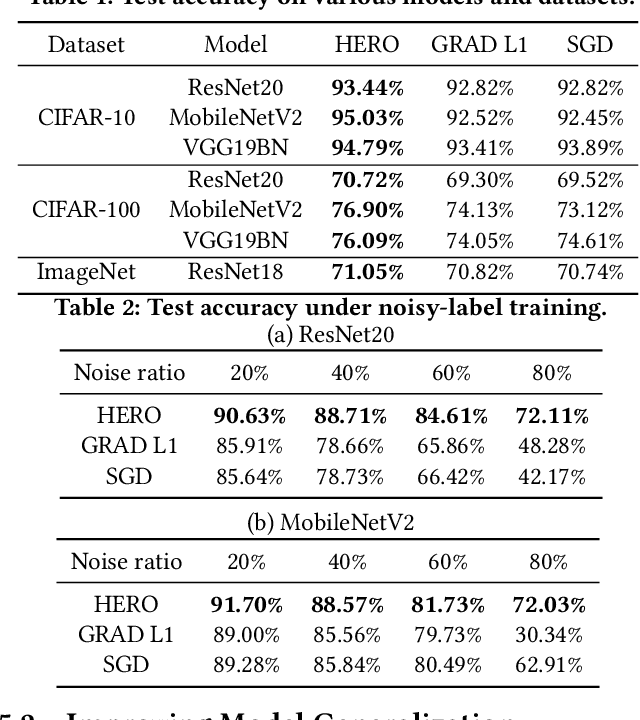
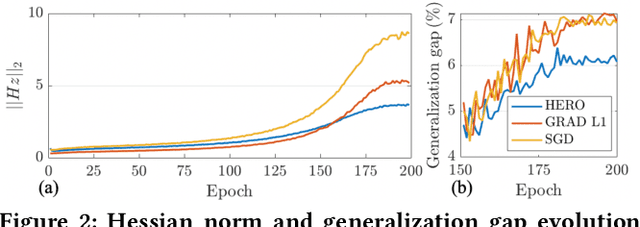
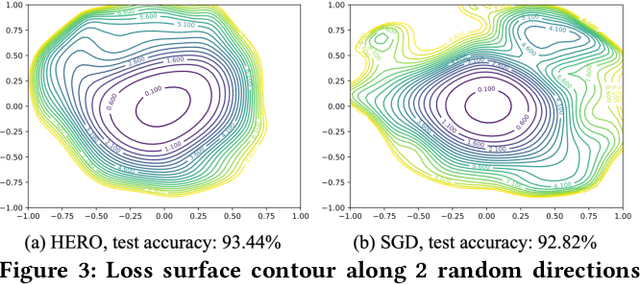
With the recent demand of deploying neural network models on mobile and edge devices, it is desired to improve the model's generalizability on unseen testing data, as well as enhance the model's robustness under fixed-point quantization for efficient deployment. Minimizing the training loss, however, provides few guarantees on the generalization and quantization performance. In this work, we fulfill the need of improving generalization and quantization performance simultaneously by theoretically unifying them under the framework of improving the model's robustness against bounded weight perturbation and minimizing the eigenvalues of the Hessian matrix with respect to model weights. We therefore propose HERO, a Hessian-enhanced robust optimization method, to minimize the Hessian eigenvalues through a gradient-based training process, simultaneously improving the generalization and quantization performance. HERO enables up to a 3.8% gain on test accuracy, up to 30% higher accuracy under 80% training label perturbation, and the best post-training quantization accuracy across a wide range of precision, including a >10% accuracy improvement over SGD-trained models for common model architectures on various datasets.
FL-WBC: Enhancing Robustness against Model Poisoning Attacks in Federated Learning from a Client Perspective
Oct 26, 2021
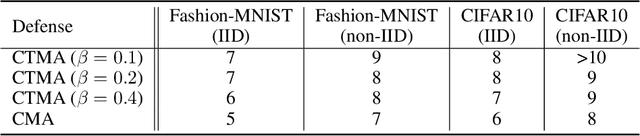
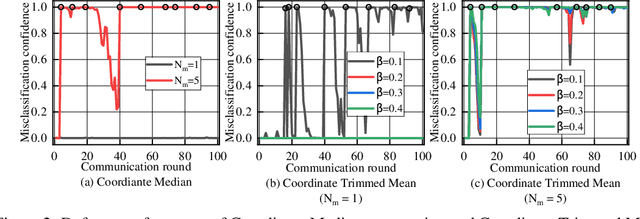
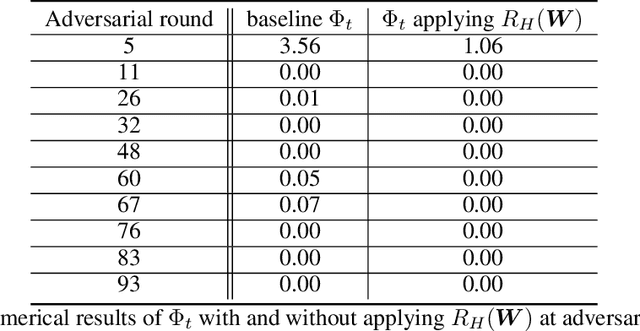
Federated learning (FL) is a popular distributed learning framework that trains a global model through iterative communications between a central server and edge devices. Recent works have demonstrated that FL is vulnerable to model poisoning attacks. Several server-based defense approaches (e.g. robust aggregation), have been proposed to mitigate such attacks. However, we empirically show that under extremely strong attacks, these defensive methods fail to guarantee the robustness of FL. More importantly, we observe that as long as the global model is polluted, the impact of attacks on the global model will remain in subsequent rounds even if there are no subsequent attacks. In this work, we propose a client-based defense, named White Blood Cell for Federated Learning (FL-WBC), which can mitigate model poisoning attacks that have already polluted the global model. The key idea of FL-WBC is to identify the parameter space where long-lasting attack effect on parameters resides and perturb that space during local training. Furthermore, we derive a certified robustness guarantee against model poisoning attacks and a convergence guarantee to FedAvg after applying our FL-WBC. We conduct experiments on FasionMNIST and CIFAR10 to evaluate the defense against state-of-the-art model poisoning attacks. The results demonstrate that our method can effectively mitigate model poisoning attack impact on the global model within 5 communication rounds with nearly no accuracy drop under both IID and Non-IID settings. Our defense is also complementary to existing server-based robust aggregation approaches and can further improve the robustness of FL under extremely strong attacks.
MTG: A Benchmarking Suite for Multilingual Text Generation
Aug 13, 2021

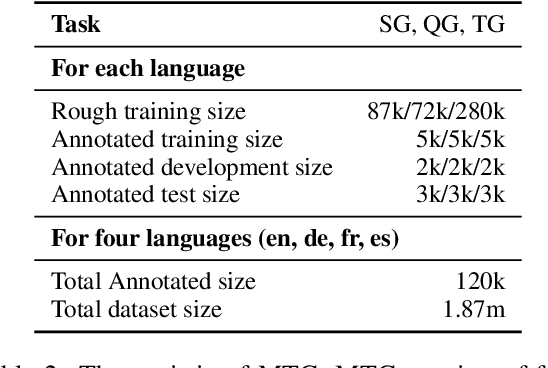
We introduce MTG, a new benchmark suite for training and evaluating multilingual text generation. It is the first and largest text generation benchmark with 120k human-annotated multi-way parallel data for three tasks (story generation, question generation, and title generation) across four languages (English, German, French, and Spanish). Based on it, we set various evaluation scenarios and make a deep analysis of several popular multilingual generation models from different aspects. Our benchmark suite will encourage the multilingualism for text generation community with more human-annotated parallel data and more diverse generation scenarios.
Lithography Hotspot Detection via Heterogeneous Federated Learning with Local Adaptation
Jul 30, 2021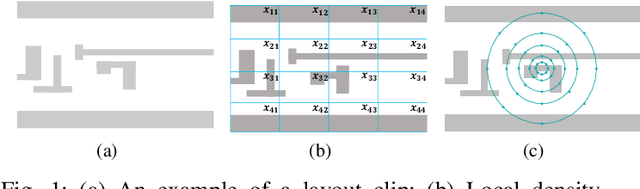
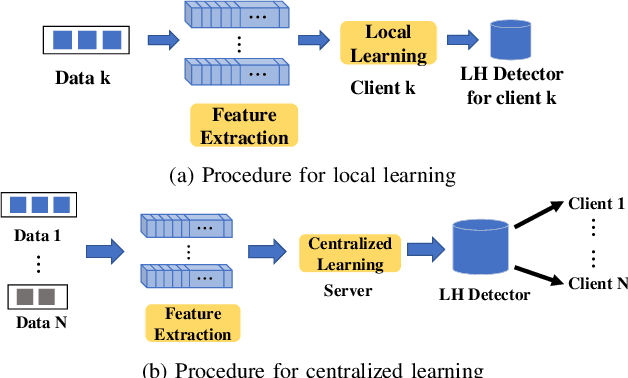
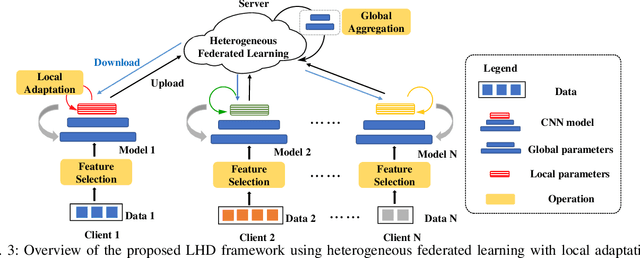
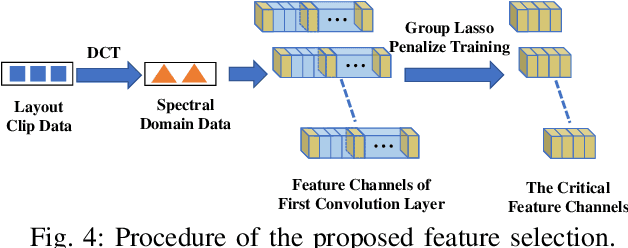
As technology scaling is approaching the physical limit, lithography hotspot detection has become an essential task in design for manufacturability. While the deployment of pattern matching or machine learning in hotspot detection can help save significant simulation time, such methods typically demand for non-trivial quality data to build the model, which most design houses are short of. Moreover, the design houses are also unwilling to directly share such data with the other houses to build a unified model, which can be ineffective for the design house with unique design patterns due to data insufficiency. On the other hand, with data homogeneity in each design house, the locally trained models can be easily over-fitted, losing generalization ability and robustness. In this paper, we propose a heterogeneous federated learning framework for lithography hotspot detection that can address the aforementioned issues. On one hand, the framework can build a more robust centralized global sub-model through heterogeneous knowledge sharing while keeping local data private. On the other hand, the global sub-model can be combined with a local sub-model to better adapt to local data heterogeneity. The experimental results show that the proposed framework can overcome the challenge of non-independent and identically distributed (non-IID) data and heterogeneous communication to achieve very high performance in comparison to other state-of-the-art methods while guaranteeing a good convergence rate in various scenarios.
Privacy-Preserving Representation Learning on Graphs: A Mutual Information Perspective
Jul 03, 2021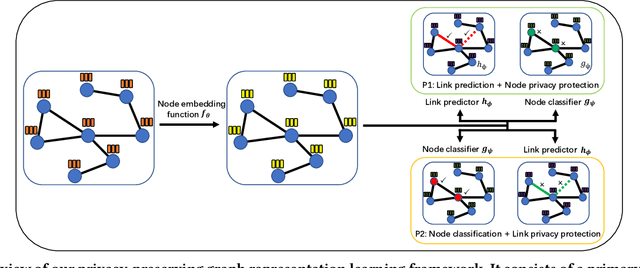
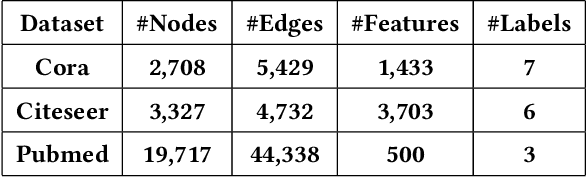
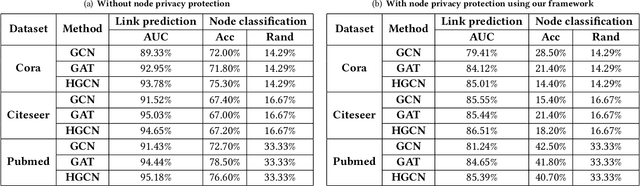
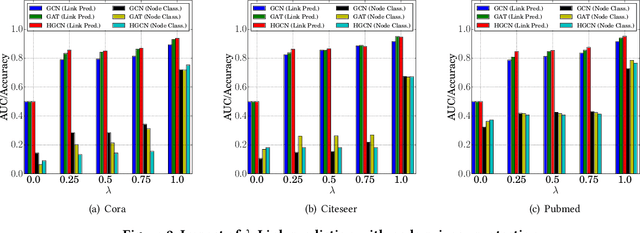
Learning with graphs has attracted significant attention recently. Existing representation learning methods on graphs have achieved state-of-the-art performance on various graph-related tasks such as node classification, link prediction, etc. However, we observe that these methods could leak serious private information. For instance, one can accurately infer the links (or node identity) in a graph from a node classifier (or link predictor) trained on the learnt node representations by existing methods. To address the issue, we propose a privacy-preserving representation learning framework on graphs from the \emph{mutual information} perspective. Specifically, our framework includes a primary learning task and a privacy protection task, and we consider node classification and link prediction as the two tasks of interest. Our goal is to learn node representations such that they can be used to achieve high performance for the primary learning task, while obtaining performance for the privacy protection task close to random guessing. We formally formulate our goal via mutual information objectives. However, it is intractable to compute mutual information in practice. Then, we derive tractable variational bounds for the mutual information terms, where each bound can be parameterized via a neural network. Next, we train these parameterized neural networks to approximate the true mutual information and learn privacy-preserving node representations. We finally evaluate our framework on various graph datasets.
Fine-grained Out-of-Distribution Detection with Mixup Outlier Exposure
Jun 07, 2021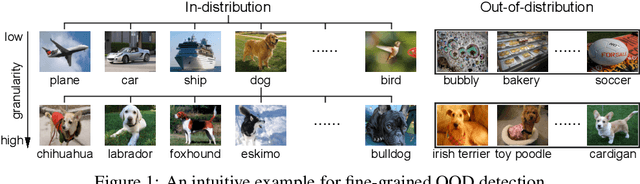
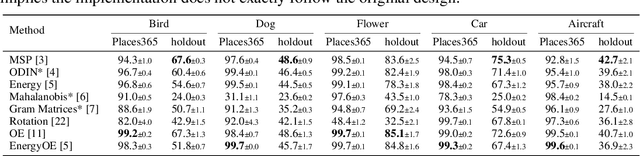
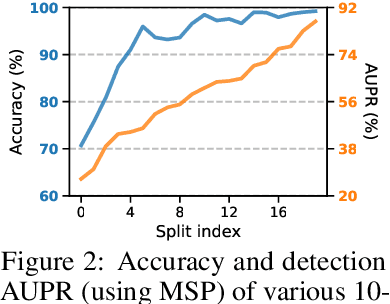

Enabling out-of-distribution (OOD) detection for DNNs is critical for their safe and reliable operation in the "open world". Unfortunately, current works in both methodology and evaluation focus on rather contrived detection problems, and only consider a coarse level of granularity w.r.t.: 1) the in-distribution (ID) classes, and 2) the OOD data's "closeness" to the ID data. We posit that such settings may be poor approximations of many real-world tasks that are naturally fine-grained (e.g., bird species classification), and thus the reported detection abilities may be over-estimates. Differently, in this work we make granularity a top priority and focus on fine-grained OOD detection. We start by carefully constructing five novel fine-grained test environments in which existing methods are shown to have difficulties. We then propose a new DNN training algorithm, Mixup Outlier Exposure (MixupOE), which leverages an outlier distribution and principles from vicinal risk minimization. Finally, we perform extensive experiments and analyses in our custom test environments and demonstrate that MixupOE can consistently improve fine-grained detection performance, establishing a strong baseline in these more realistic and challenging OOD detection settings.