 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerPruning: Selecting Weights and Activations for Power-Efficient Neural Network Acceleration
Mar 24, 2023



Deep neural networks (DNNs) have been successfully applied in various fields. A major challenge of deploying DNNs, especially on edge devices, is power consumption, due to the large number of multiply-and-accumulate (MAC) operations. To address this challenge, we propose PowerPruning, a novel method to reduce power consumption in digital neural network accelerators by selecting weights that lead to less power consumption in MAC operations. In addition, the timing characteristics of the selected weights together with all activation transitions are evaluated. The weights and activations that lead to small delays are further selected. Consequently, the maximum delay of the sensitized circuit paths in the MAC units is reduced even without modifying MAC units, which thus allows a flexible scaling of supply voltage to reduce power consumption further. Together with retraining, the proposed method can reduce power consumption of DNNs on hardware by up to 78.3% with only a slight accuracy loss.
Biologically Plausible Learning on Neuromorphic Hardware Architectures
Dec 29, 2022



With an ever-growing number of parameters defining increasingly complex networks, Deep Learning has led to several breakthroughs surpassing human performance. As a result, data movement for these millions of model parameters causes a growing imbalance known as the memory wall. Neuromorphic computing is an emerging paradigm that confronts this imbalance by performing computations directly in analog memories. On the software side, the sequential Backpropagation algorithm prevents efficient parallelization and thus fast convergence. A novel method, Direct Feedback Alignment, resolves inherent layer dependencies by directly passing the error from the output to each layer. At the intersection of hardware/software co-design, there is a demand for developing algorithms that are tolerable to hardware nonidealities. Therefore, this work explores the interrelationship of implementing bio-plausible learning in-situ on neuromorphic hardware, emphasizing energy, area, and latency constraints. Using the benchmarking framework DNN+NeuroSim, we investigate the impact of hardware nonidealities and quantization on algorithm performance, as well as how network topologies and algorithm-level design choices can scale latency, energy and area consumption of a chip. To the best of our knowledge, this work is the first to compare the impact of different learning algorithms on Compute-In-Memory-based hardware and vice versa. The best results achieved for accuracy remain Backpropagation-based, notably when facing hardware imperfections. Direct Feedback Alignment, on the other hand, allows for significant speedup due to parallelization, reducing training time by a factor approaching N for N-layered networks.
PIDS: Joint Point Interaction-Dimension Search for 3D Point Cloud
Nov 28, 2022The interaction and dimension of points are two important axes in designing point operators to serve hierarchical 3D models. Yet, these two axes are heterogeneous and challenging to fully explore. Existing works craft point operator under a single axis and reuse the crafted operator in all parts of 3D models. This overlooks the opportunity to better combine point interactions and dimensions by exploiting varying geometry/density of 3D point clouds. In this work, we establish PIDS, a novel paradigm to jointly explore point interactions and point dimensions to serve semantic segmentation on point cloud data. We establish a large search space to jointly consider versatile point interactions and point dimensions. This supports point operators with various geometry/density considerations. The enlarged search space with heterogeneous search components calls for a better ranking of candidate models. To achieve this, we improve the search space exploration by leveraging predictor-based Neural Architecture Search (NAS), and enhance the quality of prediction by assigning unique encoding to heterogeneous search components based on their priors. We thoroughly evaluate the networks crafted by PIDS on two semantic segmentation benchmarks, showing ~1% mIOU improvement on SemanticKITTI and S3DIS over state-of-the-art 3D models.
More Generalized and Personalized Unsupervised Representation Learning In A Distributed System
Nov 11, 2022Discriminative unsupervised learning methods such as contrastive learning have demonstrated the ability to learn generalized visual representations on centralized data. It is nonetheless challenging to adapt such methods to a distributed system with unlabeled, private, and heterogeneous client data due to user styles and preferences. Federated learning enables multiple clients to collectively learn a global model without provoking any privacy breach between local clients. On the other hand, another direction of federated learning studies personalized methods to address the local heterogeneity. However, work on solving both generalization and personalization without labels in a decentralized setting remains unfamiliar. In this work, we propose a novel method, FedStyle, to learn a more generalized global model by infusing local style information with local content information for contrastive learning, and to learn more personalized local models by inducing local style information for downstream tasks. The style information is extracted by contrasting original local data with strongly augmented local data (Sobel filtered images). Through extensive experiments with linear evaluations in both IID and non-IID settings, we demonstrate that FedStyle outperforms both the generalization baseline methods and personalization baseline methods in a stylized decentralized setting. Through comprehensive ablations, we demonstrate our design of style infusion and stylized personalization improve performance significantly.
Rethinking Normalization Methods in Federated Learning
Oct 07, 2022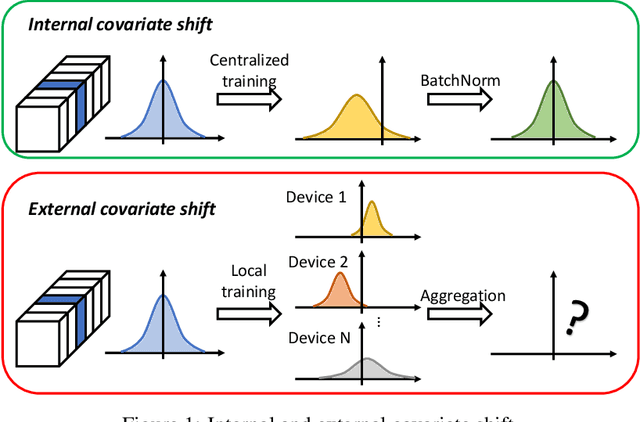

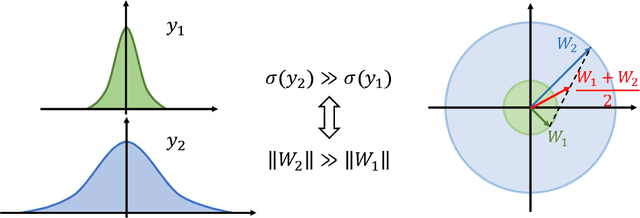
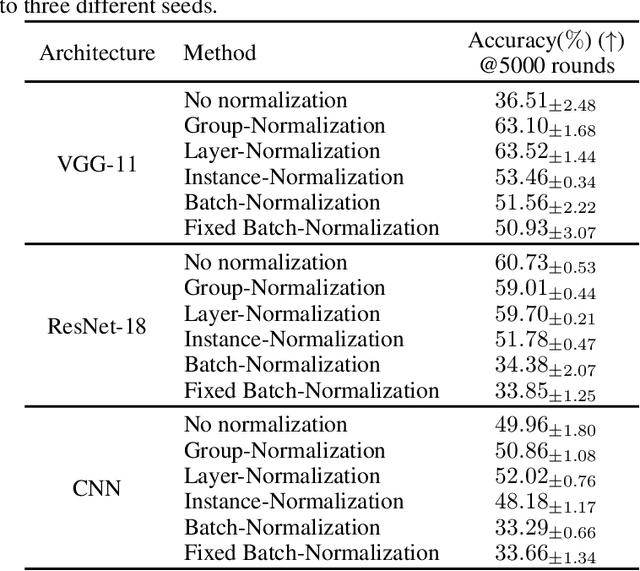
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. In this work, we explicitly uncover external covariate shift problem in FL, which is caused by the independent local training processes on different devices. We demonstrate that external covariate shifts will lead to the obliteration of some devices' contributions to the global model. Further, we show that normalization layers are indispensable in FL since their inherited properties can alleviate the problem of obliterating some devices' contributions. However, recent works have shown that batch normalization, which is one of the standard components in many deep neural networks, will incur accuracy drop of the global model in FL. The essential reason for the failure of batch normalization in FL is poorly studied. We unveil that external covariate shift is the key reason why batch normalization is ineffective in FL. We also show that layer normalization is a better choice in FL which can mitigate the external covariate shift and improve the performance of the global model. We conduct experiments on CIFAR10 under non-IID settings. The results demonstrate that models with layer normalization converge fastest and achieve the best or comparable accuracy for three different model architectures.
Join-Chain Network: A Logical Reasoning View of the Multi-head Attention in Transformer
Oct 07, 2022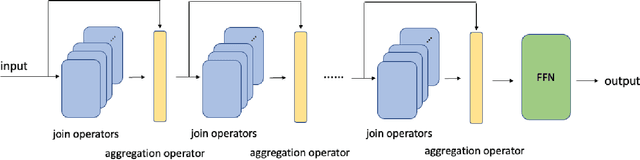
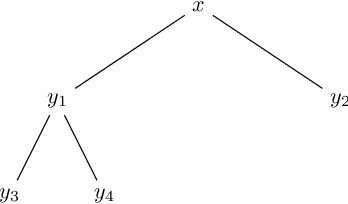
Developing neural architectures that are capable of logical reasoning has become increasingly important for a wide range of applications (e.g., natural language processing). Towards this grand objective, we propose a symbolic reasoning architecture that chains many join operators together to model output logical expressions. In particular, we demonstrate that such an ensemble of join-chains can express a broad subset of ''tree-structured'' first-order logical expressions, named FOET, which is particularly useful for modeling natural languages. To endow it with differentiable learning capability, we closely examine various neural operators for approximating the symbolic join-chains. Interestingly, we find that the widely used multi-head self-attention module in transformer can be understood as a special neural operator that implements the union bound of the join operator in probabilistic predicate space. Our analysis not only provides a new perspective on the mechanism of the pretrained models such as BERT for natural language understanding but also suggests several important future improvement directions.
Fed-CBS: A Heterogeneity-Aware Client Sampling Mechanism for Federated Learning via Class-Imbalance Reduction
Sep 30, 2022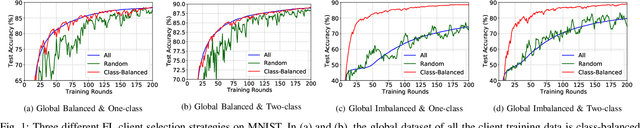
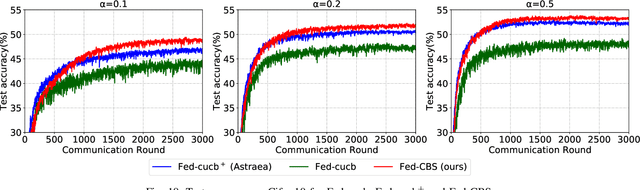
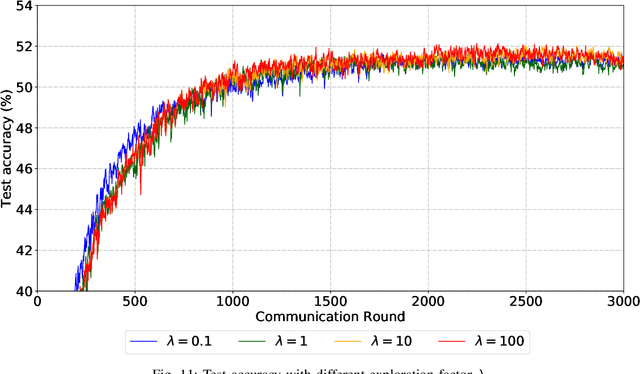
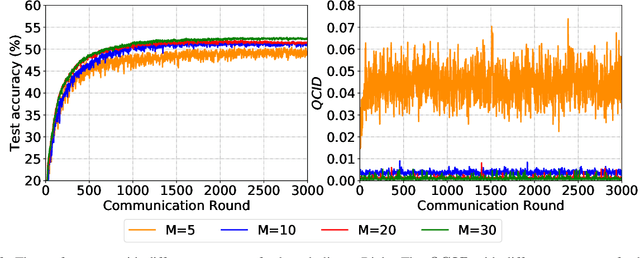
Due to limited communication capacities of edge devices, most existing federated learning (FL) methods randomly select only a subset of devices to participate in training for each communication round. Compared with engaging all the available clients, the random-selection mechanism can lead to significant performance degradation on non-IID (independent and identically distributed) data. In this paper, we show our key observation that the essential reason resulting in such performance degradation is the class-imbalance of the grouped data from randomly selected clients. Based on our key observation, we design an efficient heterogeneity-aware client sampling mechanism, i.e., Federated Class-balanced Sampling (Fed-CBS), which can effectively reduce class-imbalance of the group dataset from the intentionally selected clients. In particular, we propose a measure of class-imbalance and then employ homomorphic encryption to derive this measure in a privacy-preserving way. Based on this measure, we also design a computation-efficient client sampling strategy, such that the actively selected clients will generate a more class-balanced grouped dataset with theoretical guarantees. Extensive experimental results demonstrate Fed-CBS outperforms the status quo approaches. Furthermore, it achieves comparable or even better performance than the ideal setting where all the available clients participate in the FL training.
Fine-grain Inference on Out-of-Distribution Data with Hierarchical Classification
Sep 09, 2022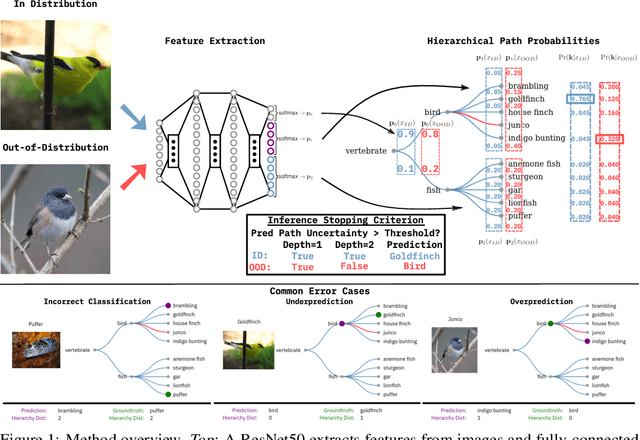
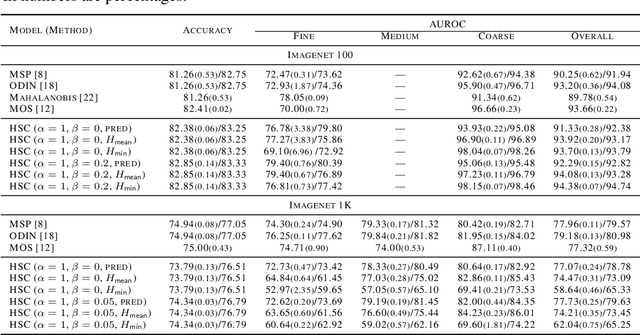
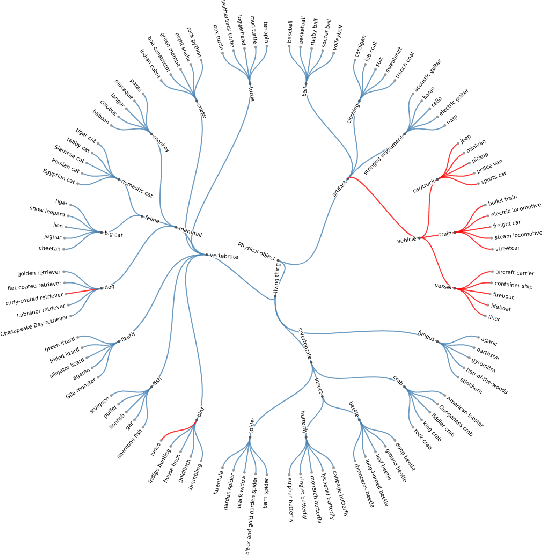
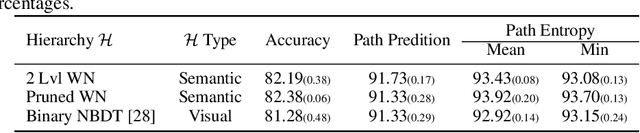
Machine learning methods must be trusted to make appropriate decisions in real-world environments, even when faced with out-of-distribution (OOD) samples. Many current approaches simply aim to detect OOD examples and alert the user when an unrecognized input is given. However, when the OOD sample significantly overlaps with the training data, a binary anomaly detection is not interpretable or explainable, and provides little information to the user. We propose a new model for OOD detection that makes predictions at varying levels of granularity as the inputs become more ambiguous, the model predictions become coarser and more conservative. Consider an animal classifier that encounters an unknown bird species and a car. Both cases are OOD, but the user gains more information if the classifier recognizes that its uncertainty over the particular species is too large and predicts bird instead of detecting it as OOD. Furthermore, we diagnose the classifiers performance at each level of the hierarchy improving the explainability and interpretability of the models predictions. We demonstrate the effectiveness of hierarchical classifiers for both fine- and coarse-grained OOD tasks.
FADE: Enabling Large-Scale Federated Adversarial Training on Resource-Constrained Edge Devices
Sep 08, 2022
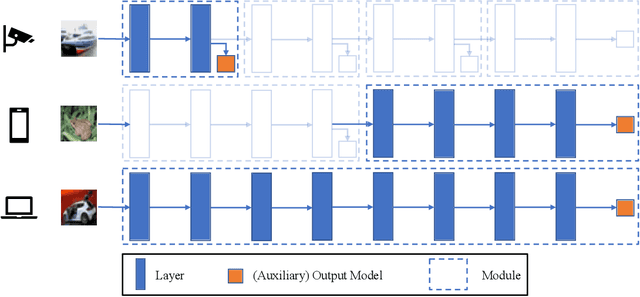
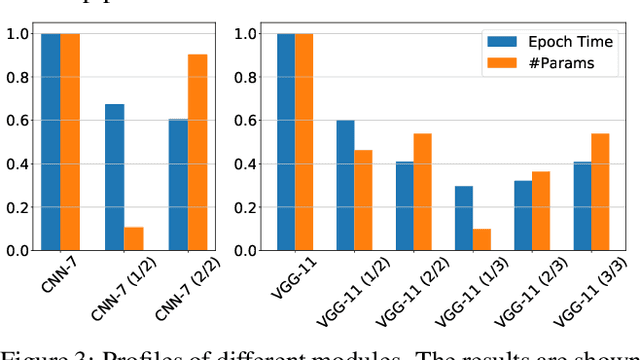
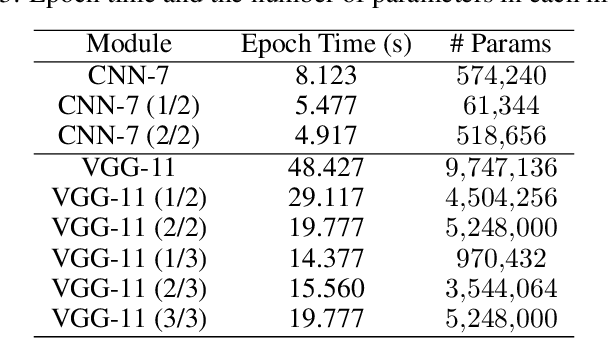
Adversarial Training (AT) has been proven to be an effective method of introducing strong adversarial robustness into deep neural networks. However, the high computational cost of AT prohibits the deployment of large-scale AT on resource-constrained edge devices, e.g., with limited computing power and small memory footprint, in Federated Learning (FL) applications. Very few previous studies have tried to tackle these constraints in FL at the same time. In this paper, we propose a new framework named Federated Adversarial Decoupled Learning (FADE) to enable AT on resource-constrained edge devices in FL. FADE reduces the computation and memory usage by applying Decoupled Greedy Learning (DGL) to federated adversarial training such that each client only needs to perform AT on a small module of the entire model in each communication round. In addition, we improve vanilla DGL by adding an auxiliary weight decay to alleviate objective inconsistency and achieve better performance. FADE offers a theoretical guarantee for the adversarial robustness and convergence. The experimental results also show that FADE can significantly reduce the computing resources consumed by AT while maintaining almost the same accuracy and robustness as fully joint training.
Self-Trained Proposal Networks for the Open World
Aug 23, 2022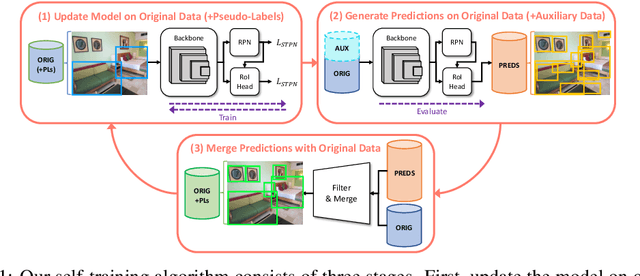
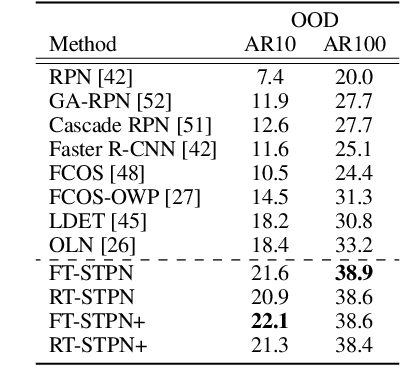
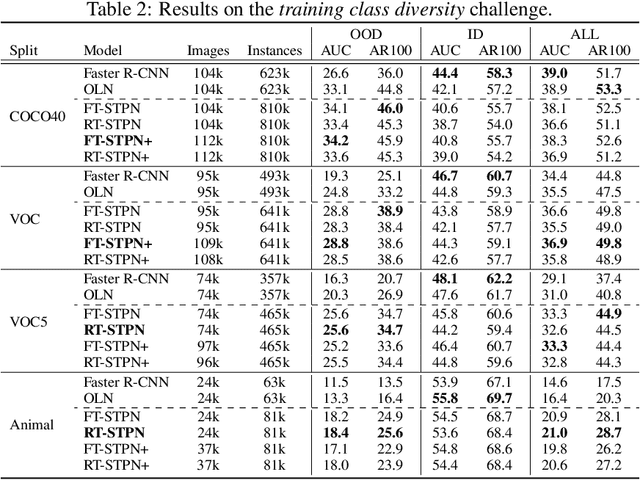
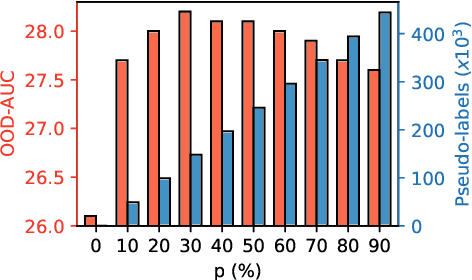
Deep learning-based object proposal methods have enabled significant advances in many computer vision pipelines. However, current state-of-the-art proposal networks use a closed-world assumption, meaning they are only trained to detect instances of the training classes while treating every other region as background. This style of solution fails to provide high recall on out-of-distribution objects, rendering it inadequate for use in realistic open-world applications where novel object categories of interest may be observed. To better detect all objects, we propose a classification-free Self-Trained Proposal Network (STPN) that leverages a novel self-training optimization strategy combined with dynamically weighted loss functions that account for challenges such as class imbalance and pseudo-label uncertainty. Not only is our model designed to excel in existing optimistic open-world benchmarks, but also in challenging operating environments where there is significant label bias. To showcase this, we devise two challenges to test the generalization of proposal models when the training data contains (1) less diversity within the labeled classes, and (2) fewer labeled instances. Our results show that STPN achieves state-of-the-art novel object generalization on all tasks.