 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen No Answer Is Correct: Diagnosing Absent Answer Detection for MLLMs in Video Understanding
Jun 06, 2026Multimodal large language models (MLLMs) have made substantial advancements in video understanding, yet the reliability of their responses remains underexplored. This work presents a diagnostic study of absent answer detection for MLLMs in video understanding, where the correct answer is deliberately excluded from the candidate set and a reliable model is expected to recognize that no valid option exists. We evaluate the absent answer detection behavior under three settings: multiple-choice questions augmented with an ``None of the Above'' option, open-ended generation with a detection instruction, and standard evaluation without any guidance. Across a diverse set of models and benchmarks, we find that MLLMs overwhelmingly select plausible distractors rather than detecting the absent answer. This failure is more pronounced in temporal reasoning tasks and worsens with denser frame sampling. We further explore chain-of-thought prompting as a mitigation strategy and find that while it substantially improves detection rates, performance remains unsatisfactory, suggesting that prompting-based strategies alone are insufficient to fully address this limitation. These findings expose a systematic failure in absent answer detection and highlight the need for explicit detection mechanisms in multimodal systems.
Query-Conditioned Evidential Keyframe Sampling for MLLM-Based Long-Form Video Understanding
Apr 01, 2026Multimodal Large Language Models (MLLMs) have shown strong performance on video question answering, but their application to long-form videos is constrained by limited context length and computational cost, making keyframe sampling essential. Existing approaches typically rely on semantic relevance or reinforcement learning, which either fail to capture evidential clues or suffer from inefficient combinatorial optimization. In this work, we propose an evidence-driven keyframe sampling framework grounded in information bottleneck theory. We formulate keyframe selection as maximizing the conditional mutual information between selected frames and the query, providing a principled objective that reflects each frame's contribution to answering the question. To make this objective tractable, we exploit its structure to derive a decomposed optimization that reduces subset selection to independent frame-level scoring. We further introduce a query-conditioned evidence scoring network trained with a contrastive objective to estimate evidential importance efficiently. Experiments on long-form video understanding benchmarks show that our method consistently outperforms prior sampling strategies under strict token budgets, while significantly improving training efficiency.
Skilled AI Agents for Embedded and IoT Systems Development
Mar 20, 2026Large language models (LLMs) and agentic systems have shown promise for automated software development, but applying them to hardware-in-the-loop (HIL) embedded and Internet-of-Things (IoT) systems remains challenging due to the tight coupling between software logic and physical hardware behavior. Code that compiles successfully may still fail when deployed on real devices because of timing constraints, peripheral initialization requirements, or hardware-specific behaviors. To address this challenge, we introduce a skills-based agentic framework for HIL embedded development together with IoT-SkillsBench, a benchmark designed to systematically evaluate AI agents in real embedded programming environments. IoT-SkillsBench spans three representative embedded platforms, 23 peripherals, and 42 tasks across three difficulty levels, where each task is evaluated under three agent configurations (no-skills, LLM-generated skills, and human-expert skills) and validated through real hardware execution. Across 378 hardware validated experiments, we show that concise human-expert skills with structured expert knowledge enable near-perfect success rates across platforms.
Phi: Leveraging Pattern-based Hierarchical Sparsity for High-Efficiency Spiking Neural Networks
May 16, 2025Spiking Neural Networks (SNNs) are gaining attention for their energy efficiency and biological plausibility, utilizing 0-1 activation sparsity through spike-driven computation. While existing SNN accelerators exploit this sparsity to skip zero computations, they often overlook the unique distribution patterns inherent in binary activations. In this work, we observe that particular patterns exist in spike activations, which we can utilize to reduce the substantial computation of SNN models. Based on these findings, we propose a novel \textbf{pattern-based hierarchical sparsity} framework, termed \textbf{\textit{Phi}}, to optimize computation. \textit{Phi} introduces a two-level sparsity hierarchy: Level 1 exhibits vector-wise sparsity by representing activations with pre-defined patterns, allowing for offline pre-computation with weights and significantly reducing most runtime computation. Level 2 features element-wise sparsity by complementing the Level 1 matrix, using a highly sparse matrix to further reduce computation while maintaining accuracy. We present an algorithm-hardware co-design approach. Algorithmically, we employ a k-means-based pattern selection method to identify representative patterns and introduce a pattern-aware fine-tuning technique to enhance Level 2 sparsity. Architecturally, we design \textbf{\textit{Phi}}, a dedicated hardware architecture that efficiently processes the two levels of \textit{Phi} sparsity on the fly. Extensive experiments demonstrate that \textit{Phi} achieves a $3.45\times$ speedup and a $4.93\times$ improvement in energy efficiency compared to state-of-the-art SNN accelerators, showcasing the effectiveness of our framework in optimizing SNN computation.
HippoMM: Hippocampal-inspired Multimodal Memory for Long Audiovisual Event Understanding
Apr 14, 2025Comprehending extended audiovisual experiences remains a fundamental challenge for computational systems. Current approaches struggle with temporal integration and cross-modal associations that humans accomplish effortlessly through hippocampal-cortical networks. We introduce HippoMM, a biologically-inspired architecture that transforms hippocampal mechanisms into computational advantages for multimodal understanding. HippoMM implements three key innovations: (i) hippocampus-inspired pattern separation and completion specifically designed for continuous audiovisual streams, (ii) short-to-long term memory consolidation that transforms perceptual details into semantic abstractions, and (iii) cross-modal associative retrieval pathways enabling modality-crossing queries. Unlike existing retrieval systems with static indexing schemes, HippoMM dynamically forms integrated episodic representations through adaptive temporal segmentation and dual-process memory encoding. Evaluations on our challenging HippoVlog benchmark demonstrate that HippoMM significantly outperforms state-of-the-art approaches (78.2% vs. 64.2% accuracy) while providing substantially faster response times (20.4s vs. 112.5s). Our results demonstrate that translating neuroscientific memory principles into computational architectures provides a promising foundation for next-generation multimodal understanding systems. The code and benchmark dataset are publicly available at https://github.com/linyueqian/HippoMM.
SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval
Dec 16, 2024We introduce Speech Information Retrieval (SIR), a new long-context task for Speech Large Language Models (Speech LLMs), and present SPIRAL, a 1,012-sample benchmark testing models' ability to extract critical details from approximately 90-second spoken inputs. While current Speech LLMs excel at short-form tasks, they struggle with the computational and representational demands of longer audio sequences. To address this limitation, we propose SpeechPrune, a training-free token pruning strategy that uses speech-text similarity and approximated attention scores to efficiently discard irrelevant tokens. In SPIRAL, SpeechPrune achieves accuracy improvements of 29% and up to 47% over the original model and the random pruning model at a pruning rate of 20%, respectively. SpeechPrune can maintain network performance even at a pruning level of 80%. This approach highlights the potential of token-level pruning for efficient and scalable long-form speech understanding.
FedProphet: Memory-Efficient Federated Adversarial Training via Theoretic-Robustness and Low-Inconsistency Cascade Learning
Sep 12, 2024



Federated Learning (FL) provides a strong privacy guarantee by enabling local training across edge devices without training data sharing, and Federated Adversarial Training (FAT) further enhances the robustness against adversarial examples, promoting a step toward trustworthy artificial intelligence. However, FAT requires a large model to preserve high accuracy while achieving strong robustness, and it is impractically slow when directly training with memory-constrained edge devices due to the memory-swapping latency. Moreover, existing memory-efficient FL methods suffer from poor accuracy and weak robustness in FAT because of inconsistent local and global models, i.e., objective inconsistency. In this paper, we propose FedProphet, a novel FAT framework that can achieve memory efficiency, adversarial robustness, and objective consistency simultaneously. FedProphet partitions the large model into small cascaded modules such that the memory-constrained devices can conduct adversarial training module-by-module. A strong convexity regularization is derived to theoretically guarantee the robustness of the whole model, and we show that the strong robustness implies low objective inconsistency in FedProphet. We also develop a training coordinator on the server of FL, with Adaptive Perturbation Adjustment for utility-robustness balance and Differentiated Module Assignment for objective inconsistency mitigation. FedProphet empirically shows a significant improvement in both accuracy and robustness compared to previous memory-efficient methods, achieving almost the same performance of end-to-end FAT with 80% memory reduction and up to 10.8x speedup in training time.
SiDA: Sparsity-Inspired Data-Aware Serving for Efficient and Scalable Large Mixture-of-Experts Models
Oct 29, 2023



Mixture-of-Experts (MoE) has emerged as a favorable architecture in the era of large models due to its inherent advantage, i.e., enlarging model capacity without incurring notable computational overhead. Yet, the realization of such benefits often results in ineffective GPU memory utilization, as large portions of the model parameters remain dormant during inference. Moreover, the memory demands of large models consistently outpace the memory capacity of contemporary GPUs. Addressing this, we introduce SiDA (Sparsity-inspired Data-Aware), an efficient inference approach tailored for large MoE models. SiDA judiciously exploits both the system's main memory, which is now abundant and readily scalable, and GPU memory by capitalizing on the inherent sparsity on expert activation in MoE models. By adopting a data-aware perspective, SiDA achieves enhanced model efficiency with a neglectable performance drop. Specifically, SiDA attains a remarkable speedup in MoE inference with up to 3.93X throughput increasing, up to 75% latency reduction, and up to 80% GPU memory saving with down to 1% performance drop. This work paves the way for scalable and efficient deployment of large MoE models, even in memory-constrained systems.
Rethinking Normalization Methods in Federated Learning
Oct 07, 2022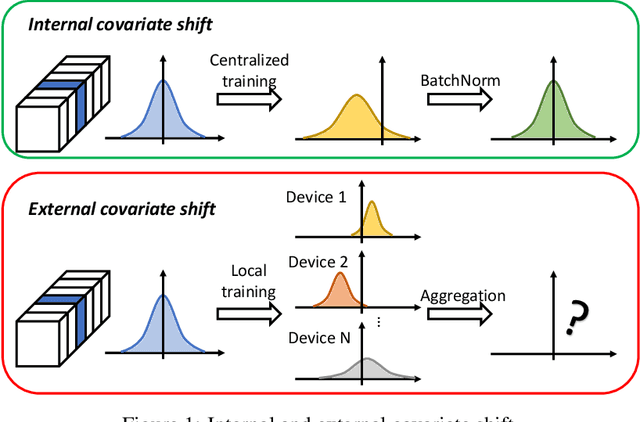

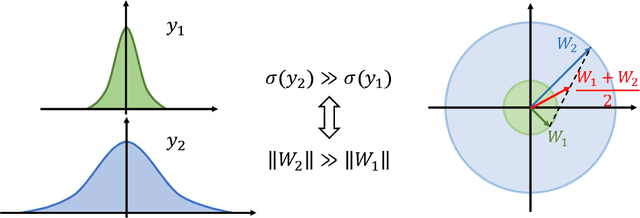
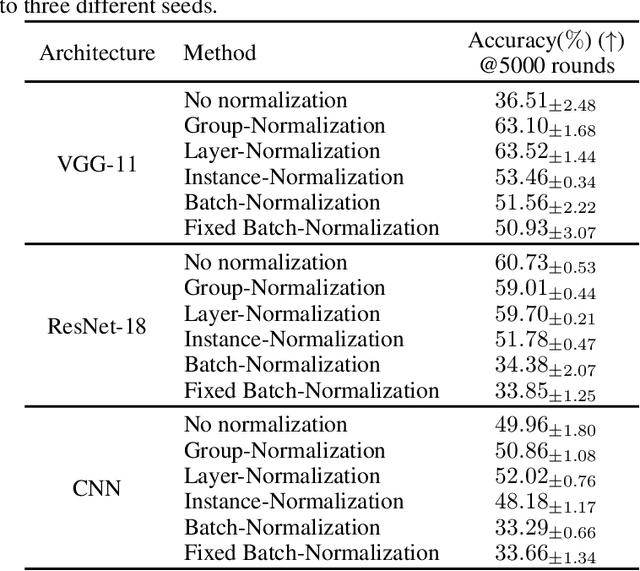
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. In this work, we explicitly uncover external covariate shift problem in FL, which is caused by the independent local training processes on different devices. We demonstrate that external covariate shifts will lead to the obliteration of some devices' contributions to the global model. Further, we show that normalization layers are indispensable in FL since their inherited properties can alleviate the problem of obliterating some devices' contributions. However, recent works have shown that batch normalization, which is one of the standard components in many deep neural networks, will incur accuracy drop of the global model in FL. The essential reason for the failure of batch normalization in FL is poorly studied. We unveil that external covariate shift is the key reason why batch normalization is ineffective in FL. We also show that layer normalization is a better choice in FL which can mitigate the external covariate shift and improve the performance of the global model. We conduct experiments on CIFAR10 under non-IID settings. The results demonstrate that models with layer normalization converge fastest and achieve the best or comparable accuracy for three different model architectures.