 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV Packet: Recomputation-Free Context-Independent KV Caching for LLMs
Apr 14, 2026Large Language Models (LLMs) rely heavily on Key-Value (KV) caching to minimize inference latency. However, standard KV caches are context-dependent: reusing a cached document in a new context requires recomputing KV states to account for shifts in attention distribution. Existing solutions such as CacheBlend, EPIC, and SAM-KV mitigate this issue by selectively recomputing a subset of tokens; however, they still incur non-negligible computational overhead (FLOPs) and increased Time-to-First-Token (TTFT) latency. In this paper, we propose KV Packet, a recomputation-free cache reuse framework that treats cached documents as immutable ``packets'' wrapped in light-weight trainable soft-token adapters, which are trained via self-supervised distillation to bridge context discontinuities. Experiments on Llama-3.1 and Qwen2.5 demonstrate that the proposed KV Packet method achieves near-zero FLOPs and lower TTFT than recomputation-based baselines, while retaining F1 scores comparable to those of the full recomputation baseline.
OptINC: Optical In-Network-Computing for Scalable Distributed Learning
Mar 30, 2026Distributed learning is widely used for training large models on large datasets by distributing parts of the model or dataset across multiple devices and aggregating the computed results for subsequent computations or parameter updates. Existing communication algorithms for distributed learning such as ring all-reduce result in heavy communication overhead between servers. Since communication in large-scale systems uses optical fibers, we propose an Optical In-Network-Computing (OptINC) architecture to offload the computation in servers onto the optical interconnects. To execute gradient averaging and quantization in the optical domain, we incorporate optical devices such as Mach-Zehnder-Interferometers (MZIs) into the interconnects. Such a de facto optical neural network (ONN) can effectively reduce the communication overhead in existing distributed training solutions. To reduce dataset complexity for training this neural network, a preprocessing algorithm implemented in the optical domain is also proposed. Hardware cost is lowered by approximating the weight matrices of the optical neural network with unitary and diagonal matrices, while the accuracy is maintained by a proposed hardware-aware training algorithm. The proposed solution was evaluated on real distributed learning tasks, including ResNet50 on CIFAR-100, and a LLaMA-based network on Wikipedia-1B. In both cases, the proposed framework can achieve comparable training accuracy to the ring all-reduce baseline, while eliminating communication overhead.
Large Language Models (LLMs) for Electronic Design Automation (EDA)
Aug 27, 2025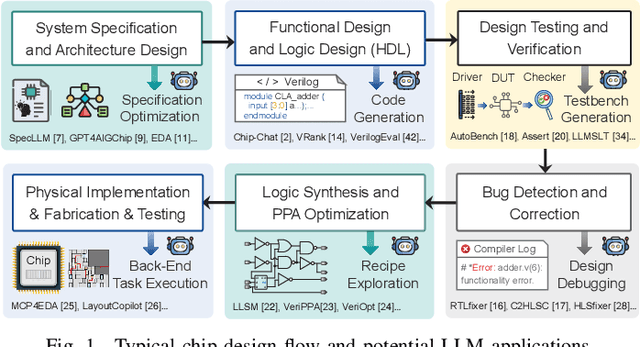

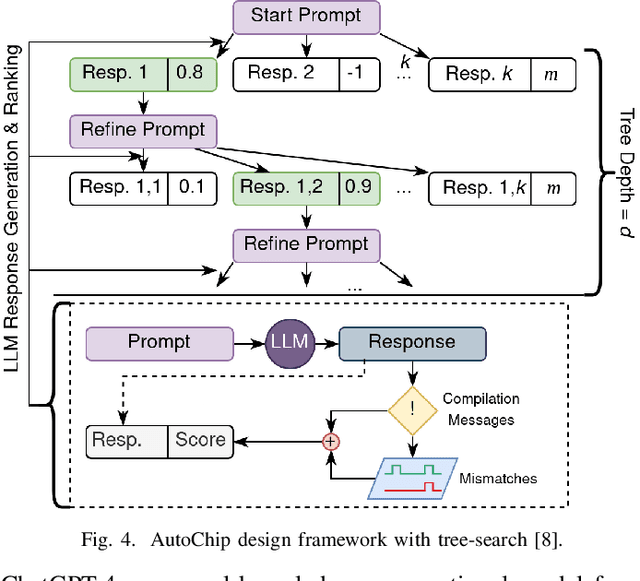
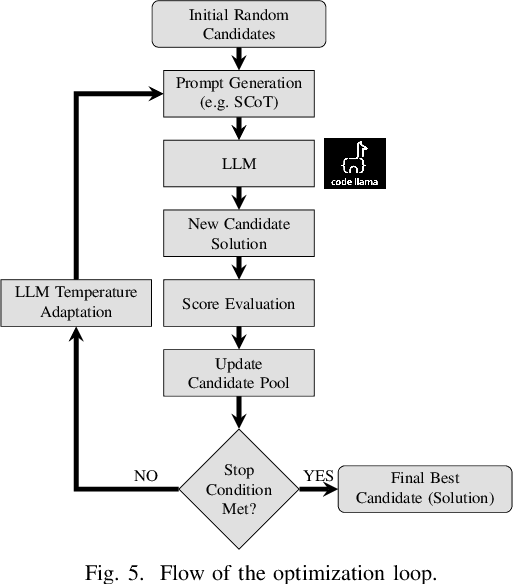
With the growing complexity of modern integrated circuits, hardware engineers are required to devote more effort to the full design-to-manufacturing workflow. This workflow involves numerous iterations, making it both labor-intensive and error-prone. Therefore, there is an urgent demand for more efficient Electronic Design Automation (EDA) solutions to accelerate hardware development. Recently, large language models (LLMs) have shown remarkable advancements in contextual comprehension, logical reasoning, and generative capabilities. Since hardware designs and intermediate scripts can be represented as text, integrating LLM for EDA offers a promising opportunity to simplify and even automate the entire workflow. Accordingly, this paper provides a comprehensive overview of incorporating LLMs into EDA, with emphasis on their capabilities, limitations, and future opportunities. Three case studies, along with their outlook, are introduced to demonstrate the capabilities of LLMs in hardware design, testing, and optimization. Finally, future directions and challenges are highlighted to further explore the potential of LLMs in shaping the next-generation EDA, providing valuable insights for researchers interested in leveraging advanced AI technologies for EDA.
GENIE-ASI: Generative Instruction and Executable Code for Analog Subcircuit Identification
Aug 26, 2025Analog subcircuit identification is a core task in analog design, essential for simulation, sizing, and layout. Traditional methods often require extensive human expertise, rule-based encoding, or large labeled datasets. To address these challenges, we propose GENIE-ASI, the first training-free, large language model (LLM)-based methodology for analog subcircuit identification. GENIE-ASI operates in two phases: it first uses in-context learning to derive natural language instructions from a few demonstration examples, then translates these into executable Python code to identify subcircuits in unseen SPICE netlists. In addition, to evaluate LLM-based approaches systematically, we introduce a new benchmark composed of operational amplifier netlists (op-amps) that cover a wide range of subcircuit variants. Experimental results on the proposed benchmark show that GENIE-ASI matches rule-based performance on simple structures (F1-score = 1.0), remains competitive on moderate abstractions (F1-score = 0.81), and shows potential even on complex subcircuits (F1-score = 0.31). These findings demonstrate that LLMs can serve as adaptable, general-purpose tools in analog design automation, opening new research directions for foundation model applications in analog design automation.
BasisN: Reprogramming-Free RRAM-Based In-Memory-Computing by Basis Combination for Deep Neural Networks
Jul 04, 2024Deep neural networks (DNNs) have made breakthroughs in various fields including image recognition and language processing. DNNs execute hundreds of millions of multiply-and-accumulate (MAC) operations. To efficiently accelerate such computations, analog in-memory-computing platforms have emerged leveraging emerging devices such as resistive RAM (RRAM). However, such accelerators face the hurdle of being required to have sufficient on-chip crossbars to hold all the weights of a DNN. Otherwise, RRAM cells in the crossbars need to be reprogramed to process further layers, which causes huge time/energy overhead due to the extremely slow writing and verification of the RRAM cells. As a result, it is still not possible to deploy such accelerators to process large-scale DNNs in industry. To address this problem, we propose the BasisN framework to accelerate DNNs on any number of available crossbars without reprogramming. BasisN introduces a novel representation of the kernels in DNN layers as combinations of global basis vectors shared between all layers with quantized coefficients. These basis vectors are written to crossbars only once and used for the computations of all layers with marginal hardware modification. BasisN also provides a novel training approach to enhance computation parallelization with the global basis vectors and optimize the coefficients to construct the kernels. Experimental results demonstrate that cycles per inference and energy-delay product were reduced to below 1% compared with applying reprogramming on crossbars in processing large-scale DNNs such as DenseNet and ResNet on ImageNet and CIFAR100 datasets, while the training and hardware costs are negligible.
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Jun 20, 2024



In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference
Jun 12, 2024



Large language models (LLMs) have recently transformed natural language processing, enabling machines to generate human-like text and engage in meaningful conversations. This development necessitates speed, efficiency, and accessibility in LLM inference as the computational and memory requirements of these systems grow exponentially. Meanwhile, advancements in computing and memory capabilities are lagging behind, exacerbated by the discontinuation of Moore's law. With LLMs exceeding the capacity of single GPUs, they require complex, expert-level configurations for parallel processing. Memory accesses become significantly more expensive than computation, posing a challenge for efficient scaling, known as the memory wall. Here, compute-in-memory (CIM) technologies offer a promising solution for accelerating AI inference by directly performing analog computations in memory, potentially reducing latency and power consumption. By closely integrating memory and compute elements, CIM eliminates the von Neumann bottleneck, reducing data movement and improving energy efficiency. This survey paper provides an overview and analysis of transformer-based models, reviewing various CIM architectures and exploring how they can address the imminent challenges of modern AI computing systems. We discuss transformer-related operators and their hardware acceleration schemes and highlight challenges, trends, and insights in corresponding CIM designs.
EncodingNet: A Novel Encoding-based MAC Design for Efficient Neural Network Acceleration
Feb 25, 2024Deep neural networks (DNNs) have achieved great breakthroughs in many fields such as image classification and natural language processing. However, the execution of DNNs needs to conduct massive numbers of multiply-accumulate (MAC) operations on hardware and thus incurs a large power consumption. To address this challenge, we propose a novel digital MAC design based on encoding. In this new design, the multipliers are replaced by simple logic gates to project the results onto a wide bit representation. These bits carry individual position weights, which can be trained for specific neural networks to enhance inference accuracy. The outputs of the new multipliers are added by bit-wise weighted accumulation and the accumulation results are compatible with existing computing platforms accelerating neural networks with either uniform or non-uniform quantization. Since the multiplication function is replaced by simple logic projection, the critical paths in the resulting circuits become much shorter. Correspondingly, pipelining stages in the MAC array can be reduced, leading to a significantly smaller area as well as a better power efficiency. The proposed design has been synthesized and verified by ResNet18-Cifar10, ResNet20-Cifar100 and ResNet50-ImageNet. The experimental results confirmed the reduction of circuit area by up to 79.63% and the reduction of power consumption of executing DNNs by up to 70.18%, while the accuracy of the neural networks can still be well maintained.
Logic Design of Neural Networks for High-Throughput and Low-Power Applications
Sep 19, 2023



Neural networks (NNs) have been successfully deployed in various fields. In NNs, a large number of multiplyaccumulate (MAC) operations need to be performed. Most existing digital hardware platforms rely on parallel MAC units to accelerate these MAC operations. However, under a given area constraint, the number of MAC units in such platforms is limited, so MAC units have to be reused to perform MAC operations in a neural network. Accordingly, the throughput in generating classification results is not high, which prevents the application of traditional hardware platforms in extreme-throughput scenarios. Besides, the power consumption of such platforms is also high, mainly due to data movement. To overcome this challenge, in this paper, we propose to flatten and implement all the operations at neurons, e.g., MAC and ReLU, in a neural network with their corresponding logic circuits. To improve the throughput and reduce the power consumption of such logic designs, the weight values are embedded into the MAC units to simplify the logic, which can reduce the delay of the MAC units and the power consumption incurred by weight movement. The retiming technique is further used to improve the throughput of the logic circuits for neural networks. In addition, we propose a hardware-aware training method to reduce the area of logic designs of neural networks. Experimental results demonstrate that the proposed logic designs can achieve high throughput and low power consumption for several high-throughput applications.
MLonMCU: TinyML Benchmarking with Fast Retargeting
Jun 15, 2023



While there exist many ways to deploy machine learning models on microcontrollers, it is non-trivial to choose the optimal combination of frameworks and targets for a given application. Thus, automating the end-to-end benchmarking flow is of high relevance nowadays. A tool called MLonMCU is proposed in this paper and demonstrated by benchmarking the state-of-the-art TinyML frameworks TFLite for Microcontrollers and TVM effortlessly with a large number of configurations in a low amount of time.