 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphPPD: Posterior Predictive Modelling for Graph-Level Inference
Aug 23, 2025Accurate modelling and quantification of predictive uncertainty is crucial in deep learning since it allows a model to make safer decisions when the data is ambiguous and facilitates the users' understanding of the model's confidence in its predictions. Along with the tremendously increasing research focus on \emph{graph neural networks} (GNNs) in recent years, there have been numerous techniques which strive to capture the uncertainty in their predictions. However, most of these approaches are specifically designed for node or link-level tasks and cannot be directly applied to graph-level learning problems. In this paper, we propose a novel variational modelling framework for the \emph{posterior predictive distribution}~(PPD) to obtain uncertainty-aware prediction in graph-level learning tasks. Based on a graph-level embedding derived from one of the existing GNNs, our framework can learn the PPD in a data-adaptive fashion. Experimental results on several benchmark datasets exhibit the effectiveness of our approach.
An Entity Linking Agent for Question Answering
Aug 05, 2025Some Question Answering (QA) systems rely on knowledge bases (KBs) to provide accurate answers. Entity Linking (EL) plays a critical role in linking natural language mentions to KB entries. However, most existing EL methods are designed for long contexts and do not perform well on short, ambiguous user questions in QA tasks. We propose an entity linking agent for QA, based on a Large Language Model that simulates human cognitive workflows. The agent actively identifies entity mentions, retrieves candidate entities, and makes decision. To verify the effectiveness of our agent, we conduct two experiments: tool-based entity linking and QA task evaluation. The results confirm the robustness and effectiveness of our agent.
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
One Demo Is All It Takes: Planning Domain Derivation with LLMs from A Single Demonstration
May 23, 2025Pre-trained Large Language Models (LLMs) have shown promise in solving planning problems but often struggle to ensure plan correctness, especially for long-horizon tasks. Meanwhile, traditional robotic task and motion planning (TAMP) frameworks address these challenges more reliably by combining high-level symbolic search with low-level motion planning. At the core of TAMP is the planning domain, an abstract world representation defined through symbolic predicates and actions. However, creating these domains typically involves substantial manual effort and domain expertise, limiting generalizability. We introduce Planning Domain Derivation with LLMs (PDDLLM), a novel approach that combines simulated physical interaction with LLM reasoning to improve planning performance. The method reduces reliance on humans by inferring planning domains from a single annotated task-execution demonstration. Unlike prior domain-inference methods that rely on partially predefined or language descriptions of planning domains, PDDLLM constructs domains entirely from scratch and automatically integrates them with low-level motion planning skills, enabling fully automated long-horizon planning. PDDLLM is evaluated on over 1,200 diverse tasks spanning nine environments and benchmarked against six LLM-based planning baselines, demonstrating superior long-horizon planning performance, lower token costs, and successful deployment on multiple physical robot platforms.
Reinforcing Question Answering Agents with Minimalist Policy Gradient Optimization
May 20, 2025Large Language Models (LLMs) have demonstrated remarkable versatility, due to the lack of factual knowledge, their application to Question Answering (QA) tasks remains hindered by hallucination. While Retrieval-Augmented Generation mitigates these issues by integrating external knowledge, existing approaches rely heavily on in-context learning, whose performance is constrained by the fundamental reasoning capabilities of LLMs. In this paper, we propose Mujica, a Multi-hop Joint Intelligence for Complex Question Answering, comprising a planner that decomposes questions into a directed acyclic graph of subquestions and a worker that resolves questions via retrieval and reasoning. Additionally, we introduce MyGO (Minimalist policy Gradient Optimization), a novel reinforcement learning method that replaces traditional policy gradient updates with Maximum Likelihood Estimation (MLE) by sampling trajectories from an asymptotically optimal policy. MyGO eliminates the need for gradient rescaling and reference models, ensuring stable and efficient training. Empirical results across multiple datasets demonstrate the effectiveness of Mujica-MyGO in enhancing multi-hop QA performance for various LLMs, offering a scalable and resource-efficient solution for complex QA tasks.
UrbanMind: Urban Dynamics Prediction with Multifaceted Spatial-Temporal Large Language Models
May 16, 2025Understanding and predicting urban dynamics is crucial for managing transportation systems, optimizing urban planning, and enhancing public services. While neural network-based approaches have achieved success, they often rely on task-specific architectures and large volumes of data, limiting their ability to generalize across diverse urban scenarios. Meanwhile, Large Language Models (LLMs) offer strong reasoning and generalization capabilities, yet their application to spatial-temporal urban dynamics remains underexplored. Existing LLM-based methods struggle to effectively integrate multifaceted spatial-temporal data and fail to address distributional shifts between training and testing data, limiting their predictive reliability in real-world applications. To bridge this gap, we propose UrbanMind, a novel spatial-temporal LLM framework for multifaceted urban dynamics prediction that ensures both accurate forecasting and robust generalization. At its core, UrbanMind introduces Muffin-MAE, a multifaceted fusion masked autoencoder with specialized masking strategies that capture intricate spatial-temporal dependencies and intercorrelations among multifaceted urban dynamics. Additionally, we design a semantic-aware prompting and fine-tuning strategy that encodes spatial-temporal contextual details into prompts, enhancing LLMs' ability to reason over spatial-temporal patterns. To further improve generalization, we introduce a test time adaptation mechanism with a test data reconstructor, enabling UrbanMind to dynamically adjust to unseen test data by reconstructing LLM-generated embeddings. Extensive experiments on real-world urban datasets across multiple cities demonstrate that UrbanMind consistently outperforms state-of-the-art baselines, achieving high accuracy and robust generalization, even in zero-shot settings.
Simplifying Graph Transformers
Apr 17, 2025



Transformers have attained outstanding performance across various modalities, employing scaled-dot-product (SDP) attention mechanisms. Researchers have attempted to migrate Transformers to graph learning, but most advanced Graph Transformers are designed with major architectural differences, either integrating message-passing or incorporating sophisticated attention mechanisms. These complexities prevent the easy adoption of Transformer training advances. We propose three simple modifications to the plain Transformer to render it applicable to graphs without introducing major architectural distortions. Specifically, we advocate for the use of (1) simplified $L_2$ attention to measure the magnitude closeness of tokens; (2) adaptive root-mean-square normalization to preserve token magnitude information; and (3) a relative positional encoding bias with a shared encoder. Significant performance gains across a variety of graph datasets justify the effectiveness of our proposed modifications. Furthermore, empirical evaluation on the expressiveness benchmark reveals noteworthy realized expressiveness in the graph isomorphism.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025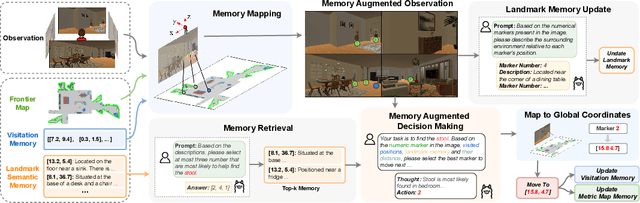
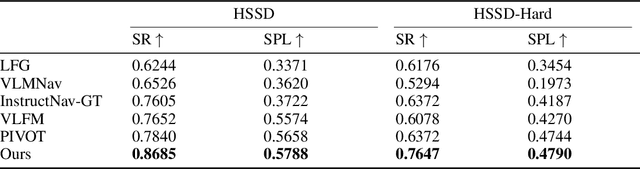
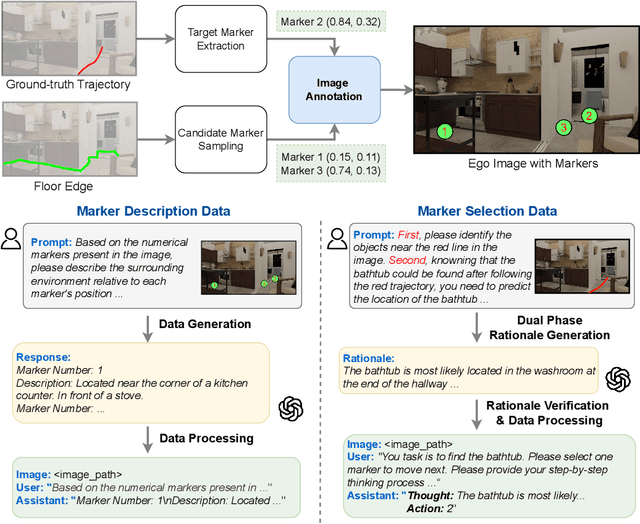

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
Remote Sensing Semantic Segmentation Quality Assessment based on Vision Language Model
Feb 19, 2025The complexity of scenes and variations in image quality result in significant variability in the performance of semantic segmentation methods of remote sensing imagery (RSI) in supervised real-world scenarios. This makes the evaluation of semantic segmentation quality in such scenarios an issue to be resolved. However, most of the existing evaluation metrics are developed based on expert-labeled object-level annotations, which are not applicable in such scenarios. To address this issue, we propose RS-SQA, an unsupervised quality assessment model for RSI semantic segmentation based on vision language model (VLM). This framework leverages a pre-trained RS VLM for semantic understanding and utilizes intermediate features from segmentation methods to extract implicit information about segmentation quality. Specifically, we introduce CLIP-RS, a large-scale pre-trained VLM trained with purified text to reduce textual noise and capture robust semantic information in the RS domain. Feature visualizations confirm that CLIP-RS can effectively differentiate between various levels of segmentation quality. Semantic features and low-level segmentation features are effectively integrated through a semantic-guided approach to enhance evaluation accuracy. To further support the development of RS semantic segmentation quality assessment, we present RS-SQED, a dedicated dataset sampled from four major RS semantic segmentation datasets and annotated with segmentation accuracy derived from the inference results of 8 representative segmentation methods. Experimental results on the established dataset demonstrate that RS-SQA significantly outperforms state-of-the-art quality assessment models. This provides essential support for predicting segmentation accuracy and high-quality semantic segmentation interpretation, offering substantial practical value.
InnerThoughts: Disentangling Representations and Predictions in Large Language Models
Jan 29, 2025



Large language models (LLMs) contain substantial factual knowledge which is commonly elicited by multiple-choice question-answering prompts. Internally, such models process the prompt through multiple transformer layers, building varying representations of the problem within its hidden states. Ultimately, however, only the hidden state corresponding to the final layer and token position are used to predict the answer label. In this work, we propose instead to learn a small separate neural network predictor module on a collection of training questions, that take the hidden states from all the layers at the last temporal position as input and outputs predictions. In effect, such a framework disentangles the representational abilities of LLMs from their predictive abilities. On a collection of hard benchmarks, our method achieves considerable improvements in performance, sometimes comparable to supervised fine-tuning procedures, but at a fraction of the computational cost.