 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DCity-LLM: Empowering Multi-modality Large Language Models for 3D City-scale Perception and Understanding
Mar 24, 2026While multi-modality large language models excel in object-centric or indoor scenarios, scaling them to 3D city-scale environments remains a formidable challenge. To bridge this gap, we propose 3DCity-LLM, a unified framework designed for 3D city-scale vision-language perception and understanding. 3DCity-LLM employs a coarse-to-fine feature encoding strategy comprising three parallel branches for target object, inter-object relationship, and global scene. To facilitate large-scale training, we introduce 3DCity-LLM-1.2M dataset that comprises approximately 1.2 million high-quality samples across seven representative task categories, ranging from fine-grained object analysis to multi-faceted scene planning. This strictly quality-controlled dataset integrates explicit 3D numerical information and diverse user-oriented simulations, enriching the question-answering diversity and realism of urban scenarios. Furthermore, we apply a multi-dimensional protocol based on text-similarity metrics and LLM-based semantic assessment to ensure faithful and comprehensive evaluations for all methods. Extensive experiments on two benchmarks demonstrate that 3DCity-LLM significantly outperforms existing state-of-the-art methods, offering a promising and meaningful direction for advancing spatial reasoning and urban intelligence. The source code and dataset are available at https://github.com/SYSU-3DSTAILab/3D-City-LLM.
Multispectral airborne laser scanning for tree species classification: a benchmark of machine learning and deep learning algorithms
Apr 19, 2025



Climate-smart and biodiversity-preserving forestry demands precise information on forest resources, extending to the individual tree level. Multispectral airborne laser scanning (ALS) has shown promise in automated point cloud processing and tree segmentation, but challenges remain in identifying rare tree species and leveraging deep learning techniques. This study addresses these gaps by conducting a comprehensive benchmark of machine learning and deep learning methods for tree species classification. For the study, we collected high-density multispectral ALS data (>1000 pts/m$^2$) at three wavelengths using the FGI-developed HeliALS system, complemented by existing Optech Titan data (35 pts/m$^2$), to evaluate the species classification accuracy of various algorithms in a test site located in Southern Finland. Based on 5261 test segments, our findings demonstrate that point-based deep learning methods, particularly a point transformer model, outperformed traditional machine learning and image-based deep learning approaches on high-density multispectral point clouds. For the high-density ALS dataset, a point transformer model provided the best performance reaching an overall (macro-average) accuracy of 87.9% (74.5%) with a training set of 1065 segments and 92.0% (85.1%) with 5000 training segments. The best image-based deep learning method, DetailView, reached an overall (macro-average) accuracy of 84.3% (63.9%), whereas a random forest (RF) classifier achieved an overall (macro-average) accuracy of 83.2% (61.3%). Importantly, the overall classification accuracy of the point transformer model on the HeliALS data increased from 73.0% with no spectral information to 84.7% with single-channel reflectance, and to 87.9% with spectral information of all the three channels.
OSMLoc: Single Image-Based Visual Localization in OpenStreetMap with Geometric and Semantic Guidances
Nov 13, 2024



OpenStreetMap (OSM), an online and versatile source of volunteered geographic information (VGI), is widely used for human self-localization by matching nearby visual observations with vectorized map data. However, due to the divergence in modalities and views, image-to-OSM (I2O) matching and localization remain challenging for robots, preventing the full utilization of VGI data in the unmanned ground vehicles and logistic industry. Inspired by the fact that the human brain relies on geometric and semantic understanding of sensory information for spatial localization tasks, we propose the OSMLoc in this paper. OSMLoc is a brain-inspired single-image visual localization method with semantic and geometric guidance to improve accuracy, robustness, and generalization ability. First, we equip the OSMLoc with the visual foundational model to extract powerful image features. Second, a geometry-guided depth distribution adapter is proposed to bridge the monocular depth estimation and camera-to-BEV transform. Thirdly, the semantic embeddings from the OSM data are utilized as auxiliary guidance for image-to-OSM feature matching. To validate the proposed OSMLoc, we collect a worldwide cross-area and cross-condition (CC) benchmark for extensive evaluation. Experiments on the MGL dataset, CC validation benchmark, and KITTI dataset have demonstrated the superiority of our method. Code, pre-trained models, CC validation benchmark, and additional results are available on: https://github.com/WHU-USI3DV/OSMLoc
Integrating 3D City Data through Knowledge Graphs
Oct 17, 2023CityGML is a widely adopted standard by the Open Geospatial Consortium (OGC) for representing and exchanging 3D city models. The representation of semantic and topological properties in CityGML makes it possible to query such 3D city data to perform analysis in various applications, e.g., security management and emergency response, energy consumption and estimation, and occupancy measurement. However, the potential of querying CityGML data has not been fully exploited. The official GML/XML encoding of CityGML is only intended as an exchange format but is not suitable for query answering. The most common way of dealing with CityGML data is to store them in the 3DCityDB system as relational tables and then query them with the standard SQL query language. Nevertheless, for end users, it remains a challenging task to formulate queries over 3DCityDB directly for their ad-hoc analytical tasks, because there is a gap between the conceptual semantics of CityGML and the relational schema adopted in 3DCityDB. In fact, the semantics of CityGML itself can be modeled as a suitable ontology. The technology of Knowledge Graphs (KGs), where an ontology is at the core, is a good solution to bridge such a gap. Moreover, embracing KGs makes it easier to integrate with other spatial data sources, e.g., OpenStreetMap and existing (Geo)KGs (e.g., Wikidata, DBPedia, and GeoNames), and to perform queries combining information from multiple data sources. In this work, we describe a CityGML KG framework to populate the concepts in the CityGML ontology using declarative mappings to 3DCityDB, thus exposing the CityGML data therein as a KG. To demonstrate the feasibility of our approach, we use CityGML data from the city of Munich as test data and integrate OpenStreeMap data in the same area.
Semi-supervised Learning from Street-View Images and OpenStreetMap for Automatic Building Height Estimation
Jul 05, 2023



Accurate building height estimation is key to the automatic derivation of 3D city models from emerging big geospatial data, including Volunteered Geographical Information (VGI). However, an automatic solution for large-scale building height estimation based on low-cost VGI data is currently missing. The fast development of VGI data platforms, especially OpenStreetMap (OSM) and crowdsourced street-view images (SVI), offers a stimulating opportunity to fill this research gap. In this work, we propose a semi-supervised learning (SSL) method of automatically estimating building height from Mapillary SVI and OSM data to generate low-cost and open-source 3D city modeling in LoD1. The proposed method consists of three parts: first, we propose an SSL schema with the option of setting a different ratio of "pseudo label" during the supervised regression; second, we extract multi-level morphometric features from OSM data (i.e., buildings and streets) for the purposed of inferring building height; last, we design a building floor estimation workflow with a pre-trained facade object detection network to generate "pseudo label" from SVI and assign it to the corresponding OSM building footprint. In a case study, we validate the proposed SSL method in the city of Heidelberg, Germany and evaluate the model performance against the reference data of building heights. Based on three different regression models, namely Random Forest (RF), Support Vector Machine (SVM), and Convolutional Neural Network (CNN), the SSL method leads to a clear performance boosting in estimating building heights with a Mean Absolute Error (MAE) around 2.1 meters, which is competitive to state-of-the-art approaches. The preliminary result is promising and motivates our future work in scaling up the proposed method based on low-cost VGI data, with possibilities in even regions and areas with diverse data quality and availability.
How can voting mechanisms improve the robustness and generalizability of toponym disambiguation?
Sep 17, 2022
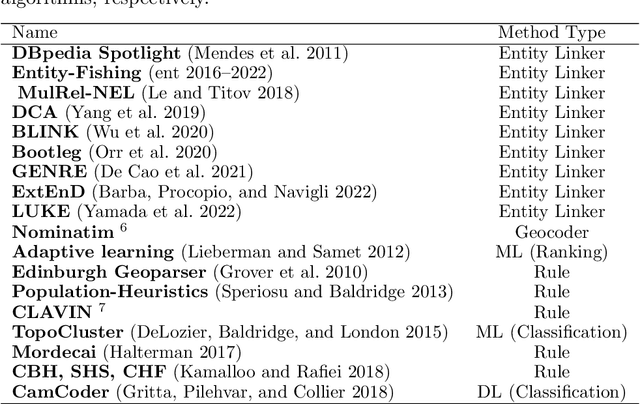
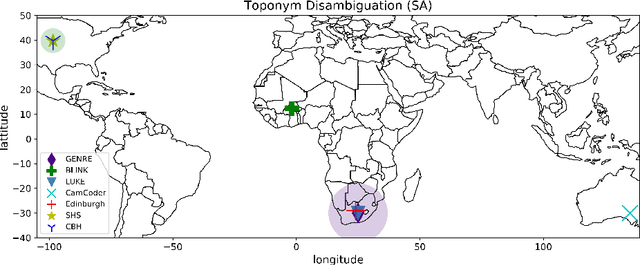
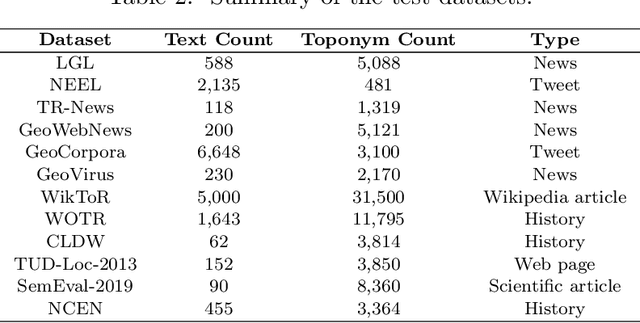
A vast amount of geographic information exists in natural language texts, such as tweets and news. Extracting geographic information from texts is called Geoparsing, which includes two subtasks: toponym recognition and toponym disambiguation, i.e., to identify the geospatial representations of toponyms. This paper focuses on toponym disambiguation, which is usually approached by toponym resolution and entity linking. Recently, many novel approaches have been proposed, especially deep learning-based approaches, such as CamCoder, GENRE, and BLINK. In this paper, a spatial clustering-based voting approach that combines several individual approaches is proposed to improve SOTA performance in terms of robustness and generalizability. Experiments are conducted to compare a voting ensemble with 20 latest and commonly-used approaches based on 12 public datasets, including several highly ambiguous and challenging datasets (e.g., WikToR and CLDW). The datasets are of six types: tweets, historical documents, news, web pages, scientific articles, and Wikipedia articles, containing in total 98,300 places across the world. The results show that the voting ensemble performs the best on all the datasets, achieving an average Accuracy@161km of 0.86, proving the generalizability and robustness of the voting approach. Also, the voting ensemble drastically improves the performance of resolving fine-grained places, i.e., POIs, natural features, and traffic ways.
Location reference recognition from texts: A survey and comparison
Jul 04, 2022
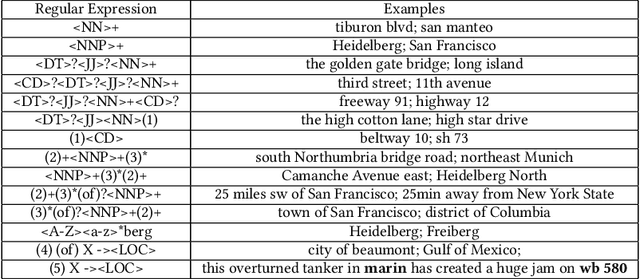
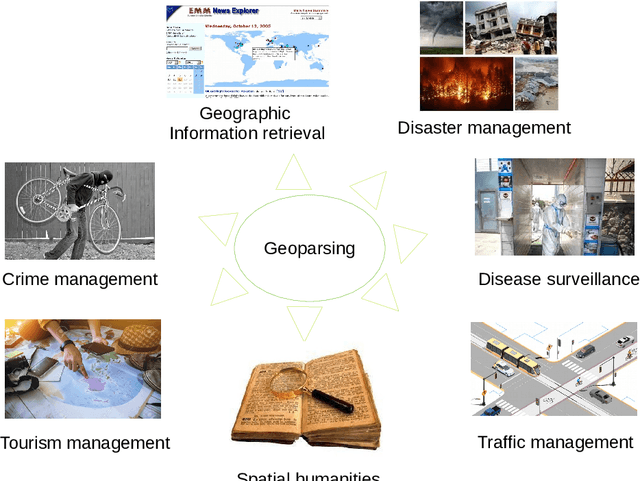
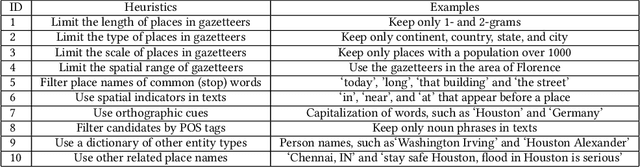
A vast amount of location information exists in unstructured texts, such as social media posts, news stories, scientific articles, web pages, travel blogs, and historical archives. Geoparsing refers to the process of recognizing location references from texts and identifying their geospatial representations. While geoparsing can benefit many domains, a summary of the specific applications is still missing. Further, there lacks a comprehensive review and comparison of existing approaches for location reference recognition, which is the first and a core step of geoparsing. To fill these research gaps, this review first summarizes seven typical application domains of geoparsing: geographic information retrieval, disaster management, disease surveillance, traffic management, spatial humanities, tourism management, and crime management. We then review existing approaches for location reference recognition by categorizing these approaches into four groups based on their underlying functional principle: rule-based, gazetteer matching-based, statistical learning-based, and hybrid approaches. Next, we thoroughly evaluate the correctness and computational efficiency of the 27 most widely used approaches for location reference recognition based on 26 public datasets with different types of texts (e.g., social media posts and news stories) containing 39,736 location references across the world. Results from this thorough evaluation can help inform future methodological developments for location reference recognition, and can help guide the selection of proper approaches based on application needs.
Automated Detecting and Placing Road Objects from Street-level Images
Sep 17, 2019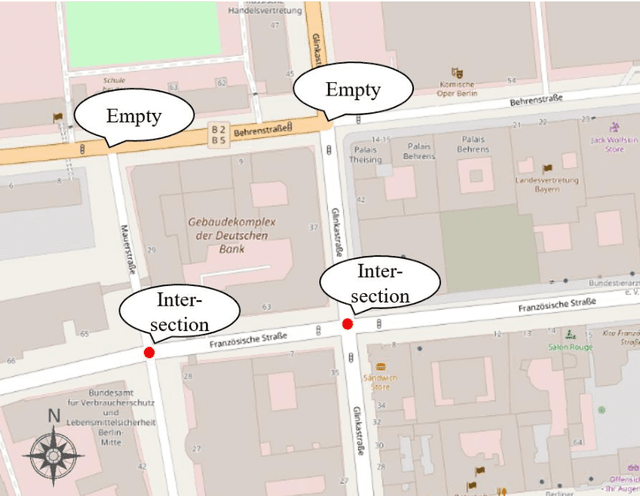

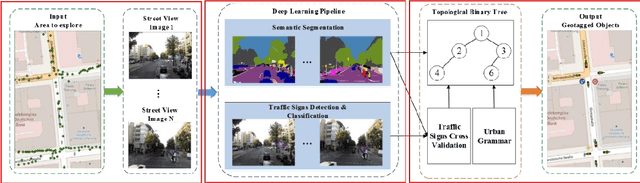

Navigation services utilized by autonomous vehicles or ordinary users require the availability of detailed information about road-related objects and their geolocations, especially at road intersections. However, these road intersections are mainly represented as point elements without detailed information, or are even not available in current versions of crowdsourced mapping databases including OpenStreetMap(OSM). This study develops an approach to automatically detect road objects and place them to right location from street-level images. Our processing pipeline relies on two convolutional neural networks: the first segments the images, while the second detects and classifies the specific objects. Moreover, to locate the detected objects, we establish an attributed topological binary tree(ATBT) based on urban grammar for each image to depict the coherent relations of topologies, attributes and semantics of the road objects. Then the ATBT is further matched with map features on OSM to determine the right placed location. The proposed method has been applied to a case study in Berlin, Germany. We validate the effectiveness of our method on two object classes: traffic signs and traffic lights. Experimental results demonstrate that the proposed approach provides near-precise localization results in terms of completeness and positional accuracy. Among many potential applications, the output may be combined with other sources of data to guide autonomous vehicles