 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow can voting mechanisms improve the robustness and generalizability of toponym disambiguation?
Sep 17, 2022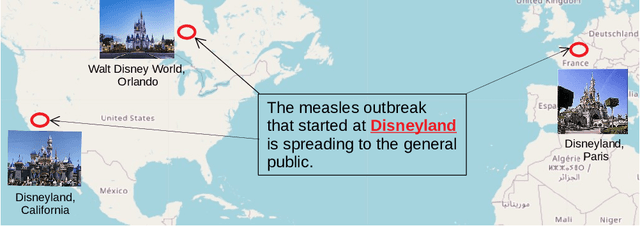
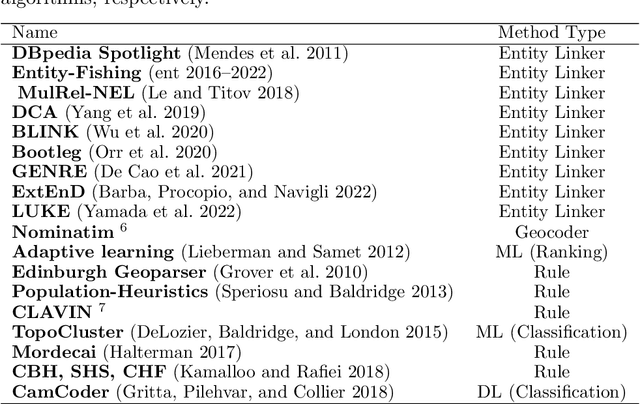
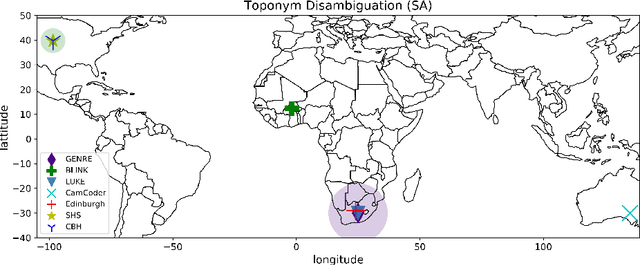
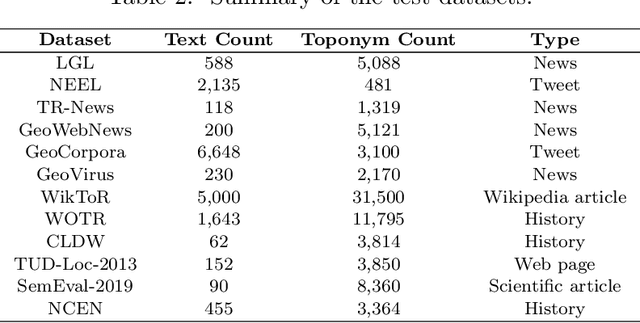
A vast amount of geographic information exists in natural language texts, such as tweets and news. Extracting geographic information from texts is called Geoparsing, which includes two subtasks: toponym recognition and toponym disambiguation, i.e., to identify the geospatial representations of toponyms. This paper focuses on toponym disambiguation, which is usually approached by toponym resolution and entity linking. Recently, many novel approaches have been proposed, especially deep learning-based approaches, such as CamCoder, GENRE, and BLINK. In this paper, a spatial clustering-based voting approach that combines several individual approaches is proposed to improve SOTA performance in terms of robustness and generalizability. Experiments are conducted to compare a voting ensemble with 20 latest and commonly-used approaches based on 12 public datasets, including several highly ambiguous and challenging datasets (e.g., WikToR and CLDW). The datasets are of six types: tweets, historical documents, news, web pages, scientific articles, and Wikipedia articles, containing in total 98,300 places across the world. The results show that the voting ensemble performs the best on all the datasets, achieving an average Accuracy@161km of 0.86, proving the generalizability and robustness of the voting approach. Also, the voting ensemble drastically improves the performance of resolving fine-grained places, i.e., POIs, natural features, and traffic ways.
Location reference recognition from texts: A survey and comparison
Jul 04, 2022
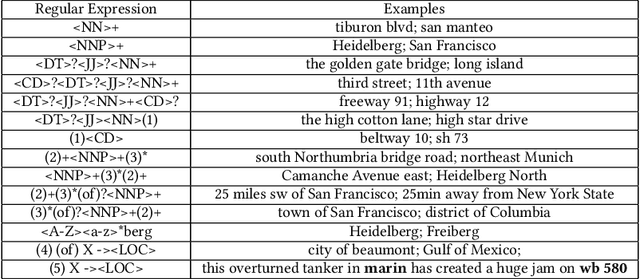
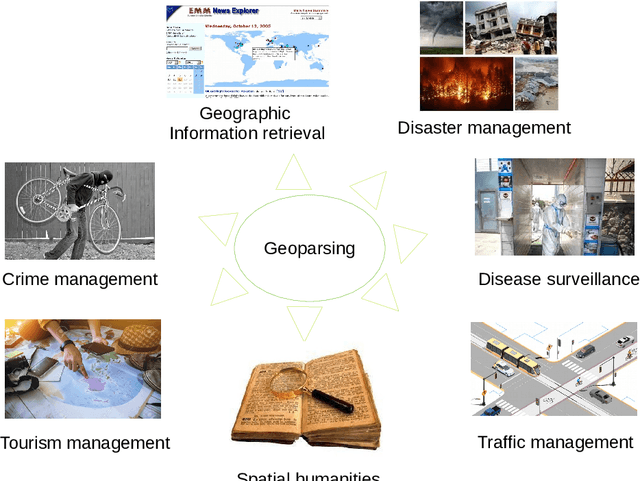
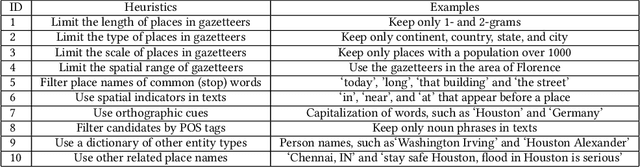
A vast amount of location information exists in unstructured texts, such as social media posts, news stories, scientific articles, web pages, travel blogs, and historical archives. Geoparsing refers to the process of recognizing location references from texts and identifying their geospatial representations. While geoparsing can benefit many domains, a summary of the specific applications is still missing. Further, there lacks a comprehensive review and comparison of existing approaches for location reference recognition, which is the first and a core step of geoparsing. To fill these research gaps, this review first summarizes seven typical application domains of geoparsing: geographic information retrieval, disaster management, disease surveillance, traffic management, spatial humanities, tourism management, and crime management. We then review existing approaches for location reference recognition by categorizing these approaches into four groups based on their underlying functional principle: rule-based, gazetteer matching-based, statistical learning-based, and hybrid approaches. Next, we thoroughly evaluate the correctness and computational efficiency of the 27 most widely used approaches for location reference recognition based on 26 public datasets with different types of texts (e.g., social media posts and news stories) containing 39,736 location references across the world. Results from this thorough evaluation can help inform future methodological developments for location reference recognition, and can help guide the selection of proper approaches based on application needs.
Deep Learning-based Segmentation of Cerebral Aneurysms in 3D TOF-MRA using Coarse-to-Fine Framework
Oct 26, 2021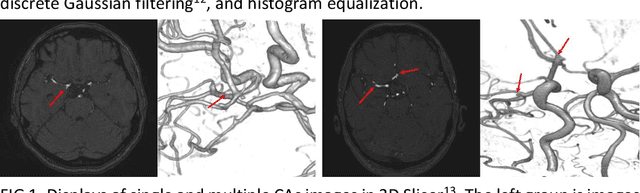
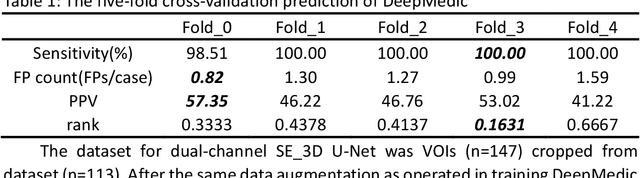
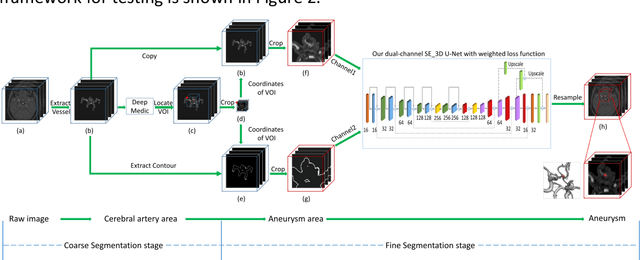
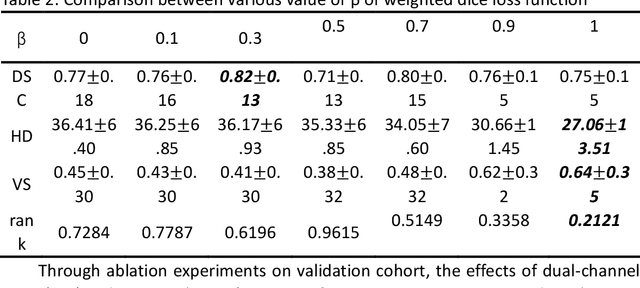
BACKGROUND AND PURPOSE: Cerebral aneurysm is one of the most common cerebrovascular diseases, and SAH caused by its rupture has a very high mortality and disability rate. Existing automatic segmentation methods based on DLMs with TOF-MRA modality could not segment edge voxels very well, so that our goal is to realize more accurate segmentation of cerebral aneurysms in 3D TOF-MRA with the help of DLMs. MATERIALS AND METHODS: In this research, we proposed an automatic segmentation framework of cerebral aneurysm in 3D TOF-MRA. The framework was composed of two segmentation networks ranging from coarse to fine. The coarse segmentation network, namely DeepMedic, completed the coarse segmentation of cerebral aneurysms, and the processed results were fed into the fine segmentation network, namely dual-channel SE_3D U-Net trained with weighted loss function, for fine segmentation. Images from ADAM2020 (n=113) were used for training and validation and images from another center (n=45) were used for testing. The segmentation metrics we used include DSC, HD, and VS. RESULTS: The trained cerebral aneurysm segmentation model achieved DSC of 0.75, HD of 1.52, and VS of 0.91 on validation cohort. On the totally independent test cohort, our method achieved the highest DSC of 0.12, the lowest HD of 11.61, and the highest VS of 0.16 in comparison with state-of-the-art segmentation networks. CONCLUSIONS: The coarse-to-fine framework, which composed of DeepMedic and dual-channel SE_3D U-Net can segment cerebral aneurysms in 3D TOF-MRA with a superior accuracy.
A Unified Framework for Constructing Nonconvex Regularizations
Jun 11, 2021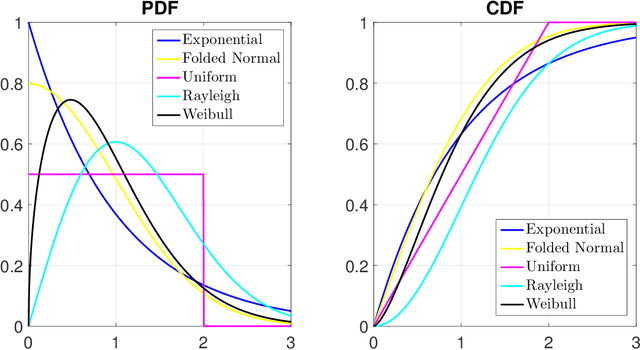
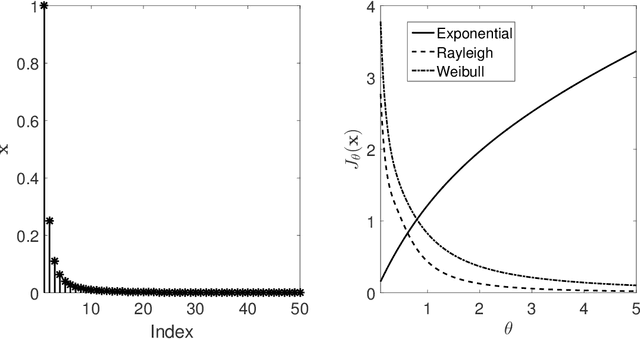
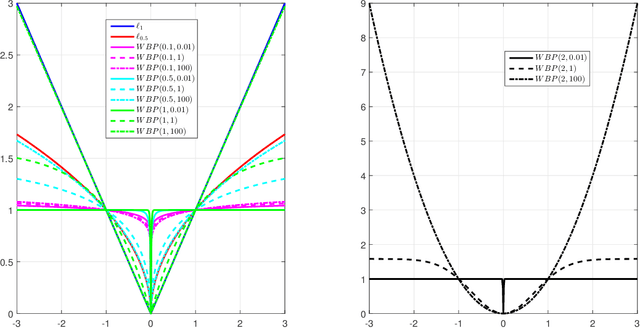
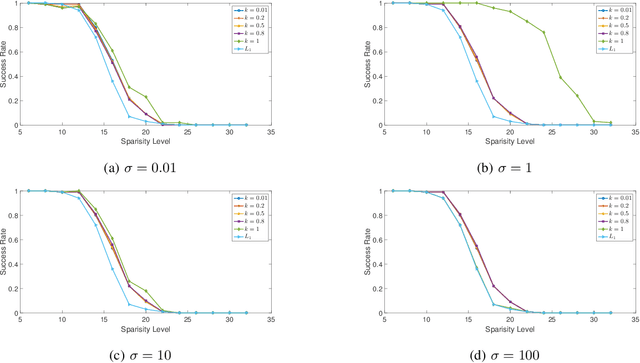
Over the past decades, many individual nonconvex methods have been proposed to achieve better sparse recovery performance in various scenarios. However, how to construct a valid nonconvex regularization function remains open in practice. In this paper, we fill in this gap by presenting a unified framework for constructing the nonconvex regularization based on the probability density function. Meanwhile, a new nonconvex sparse recovery method constructed via the Weibull distribution is studied.
Sparse recovery based on the generalized error function
Jun 03, 2021
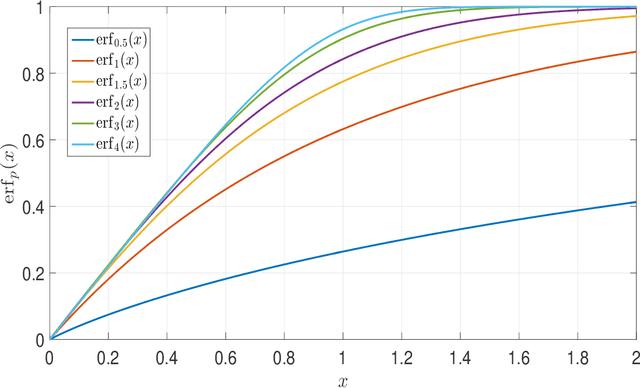
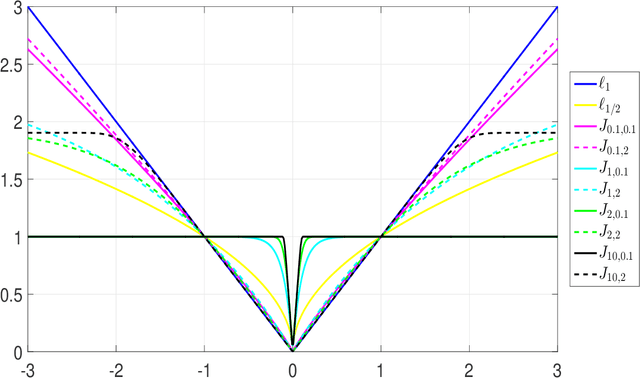

In this paper, we propose a novel sparse recovery method based on the generalized error function. The penalty function introduced involves both the shape and the scale parameters, making it very flexible. The theoretical analysis results in terms of the null space property, the spherical section property and the restricted invertibility factor are established for both constrained and unconstrained models. The practical algorithms via both the iteratively reweighted $\ell_1$ and the difference of convex functions algorithms are presented. Numerical experiments are conducted to illustrate the improvement provided by the proposed approach in various scenarios. Its practical application in magnetic resonance imaging (MRI) reconstruction is studied as well.