 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-Based Clustering with Kernel Diffusion
Oct 14, 2021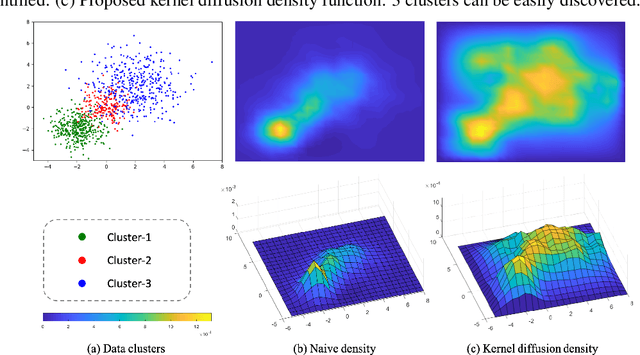
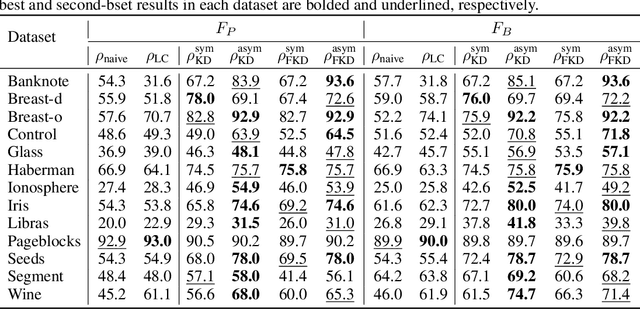
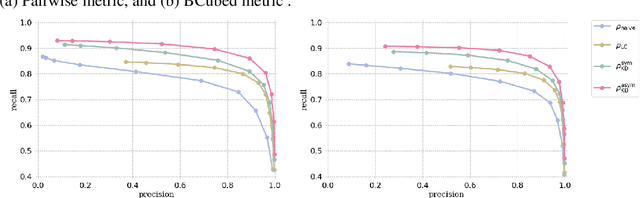
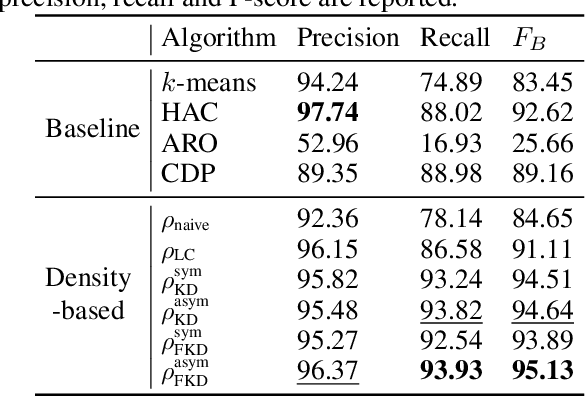
Finding a suitable density function is essential for density-based clustering algorithms such as DBSCAN and DPC. A naive density corresponding to the indicator function of a unit $d$-dimensional Euclidean ball is commonly used in these algorithms. Such density suffers from capturing local features in complex datasets. To tackle this issue, we propose a new kernel diffusion density function, which is adaptive to data of varying local distributional characteristics and smoothness. Furthermore, we develop a surrogate that can be efficiently computed in linear time and space and prove that it is asymptotically equivalent to the kernel diffusion density function. Extensive empirical experiments on benchmark and large-scale face image datasets show that the proposed approach not only achieves a significant improvement over classic density-based clustering algorithms but also outperforms the state-of-the-art face clustering methods by a large margin.
Zero-bias Deep Neural Network for Quickest RF Signal Surveillance
Oct 12, 2021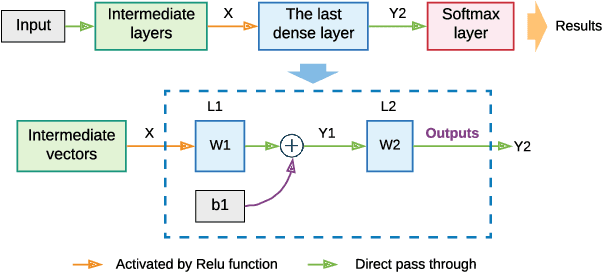
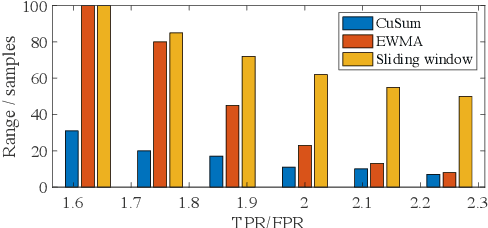
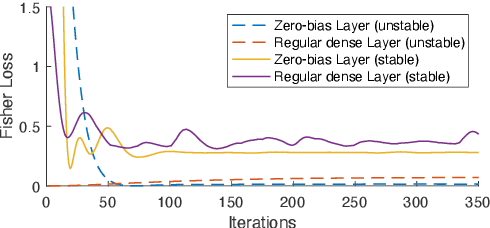
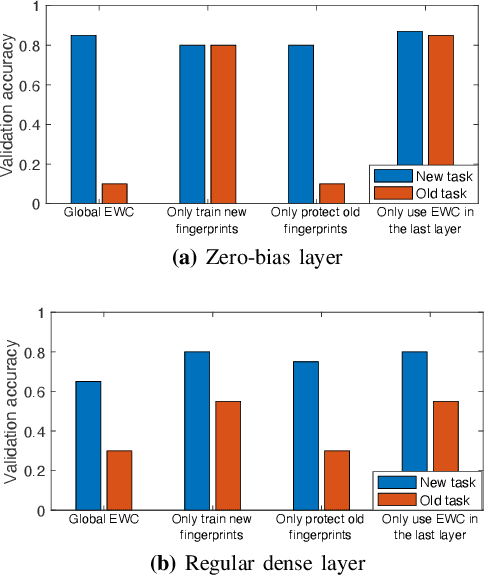
The Internet of Things (IoT) is reshaping modern society by allowing a decent number of RF devices to connect and share information through RF channels. However, such an open nature also brings obstacles to surveillance. For alleviation, a surveillance oracle, or a cognitive communication entity needs to identify and confirm the appearance of known or unknown signal sources in real-time. In this paper, we provide a deep learning framework for RF signal surveillance. Specifically, we jointly integrate the Deep Neural Networks (DNNs) and Quickest Detection (QD) to form a sequential signal surveillance scheme. We first analyze the latent space characteristic of neural network classification models, and then we leverage the response characteristics of DNN classifiers and propose a novel method to transform existing DNN classifiers into performance-assured binary abnormality detectors. In this way, we seamlessly integrate the DNNs with the parametric quickest detection. Finally, we propose an enhanced Elastic Weight Consolidation (EWC) algorithm with better numerical stability for DNNs in signal surveillance systems to evolve incrementally, we demonstrate that the zero-bias DNN is superior to regular DNN models considering incremental learning and decision fairness. We evaluated the proposed framework using real signal datasets and we believe this framework is helpful in developing a trustworthy IoT ecosystem.
SG-Net: Spatial Granularity Network for One-Stage Video Instance Segmentation
Apr 05, 2021
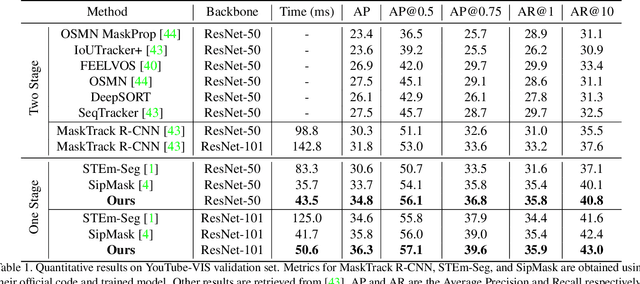
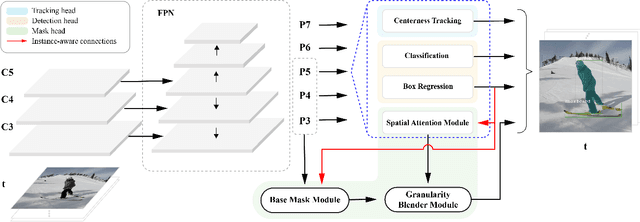
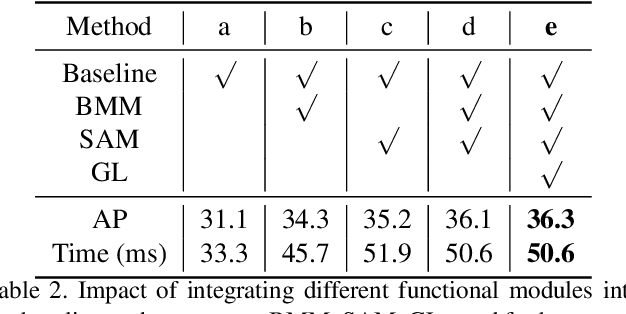
Video instance segmentation (VIS) is a new and critical task in computer vision. To date, top-performing VIS methods extend the two-stage Mask R-CNN by adding a tracking branch, leaving plenty of room for improvement. In contrast, we approach the VIS task from a new perspective and propose a one-stage spatial granularity network (SG-Net). Compared to the conventional two-stage methods, SG-Net demonstrates four advantages: 1) Our method has a one-stage compact architecture and each task head (detection, segmentation, and tracking) is crafted interdependently so they can effectively share features and enjoy the joint optimization; 2) Our mask prediction is dynamically performed on the sub-regions of each detected instance, leading to high-quality masks of fine granularity; 3) Each of our task predictions avoids using expensive proposal-based RoI features, resulting in much reduced runtime complexity per instance; 4) Our tracking head models objects centerness movements for tracking, which effectively enhances the tracking robustness to different object appearances. In evaluation, we present state-of-the-art comparisons on the YouTube-VIS dataset. Extensive experiments demonstrate that our compact one-stage method can achieve improved performance in both accuracy and inference speed. We hope our SG-Net could serve as a strong and flexible baseline for the VIS task. Our code will be available.
Hierarchical Attention Fusion for Geo-Localization
Feb 18, 2021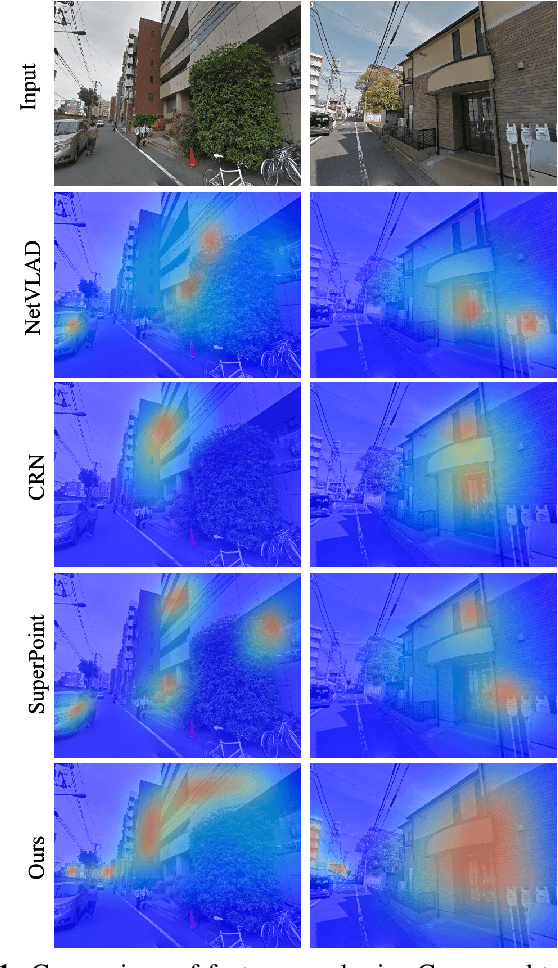
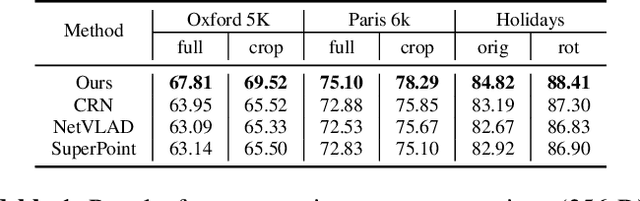
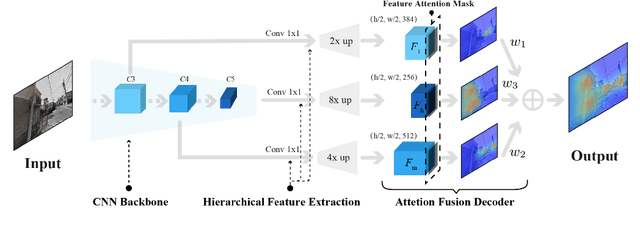

Geo-localization is a critical task in computer vision. In this work, we cast the geo-localization as a 2D image retrieval task. Current state-of-the-art methods for 2D geo-localization are not robust to locate a scene with drastic scale variations because they only exploit features from one semantic level for image representations. To address this limitation, we introduce a hierarchical attention fusion network using multi-scale features for geo-localization. We extract the hierarchical feature maps from a convolutional neural network (CNN) and organically fuse the extracted features for image representations. Our training is self-supervised using adaptive weights to control the attention of feature emphasis from each hierarchical level. Evaluation results on the image retrieval and the large-scale geo-localization benchmarks indicate that our method outperforms the existing state-of-the-art methods. Code is available here: \url{https://github.com/YanLiqi/HAF}.
DenserNet: Weakly Supervised Visual Localization Using Multi-scale Feature Aggregation
Dec 31, 2020

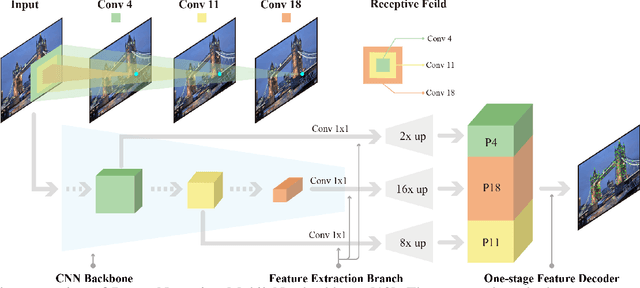
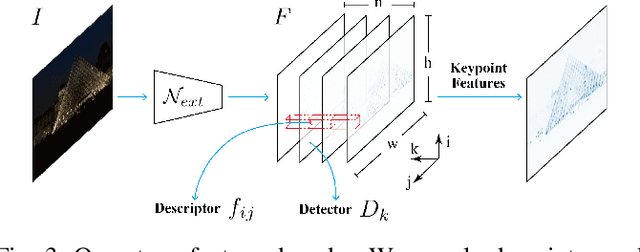
In this work, we introduce a Denser Feature Network (DenserNet) for visual localization. Our work provides three principal contributions. First, we develop a convolutional neural network (CNN) architecture which aggregates feature maps at different semantic levels for image representations. Using denser feature maps, our method can produce more keypoint features and increase image retrieval accuracy. Second, our model is trained end-to-end without pixel-level annotation other than positive and negative GPS-tagged image pairs. We use a weakly supervised triplet ranking loss to learn discriminative features and encourage keypoint feature repeatability for image representation. Finally, our method is computationally efficient as our architecture has shared features and parameters during computation. Our method can perform accurate large-scale localization under challenging conditions while remaining the computational constraint. Extensive experiment results indicate that our method sets a new state-of-the-art on four challenging large-scale localization benchmarks and three image retrieval benchmarks.
A Vector-based Representation to Enhance Head Pose Estimation
Oct 14, 2020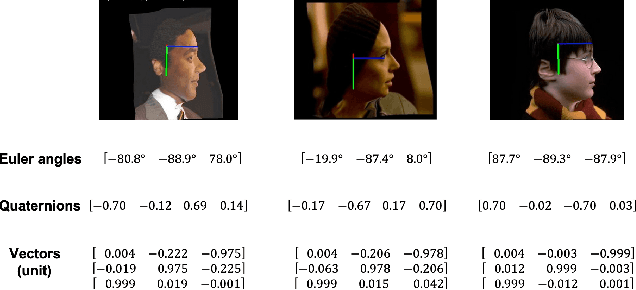
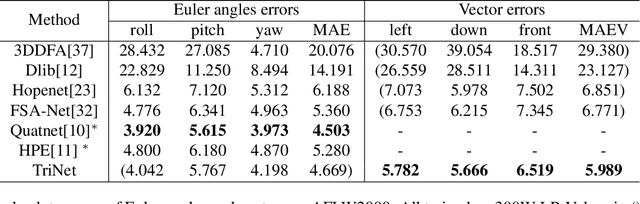
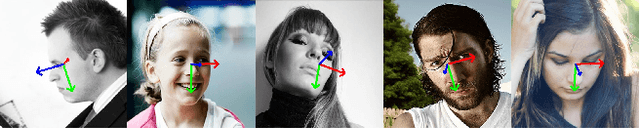
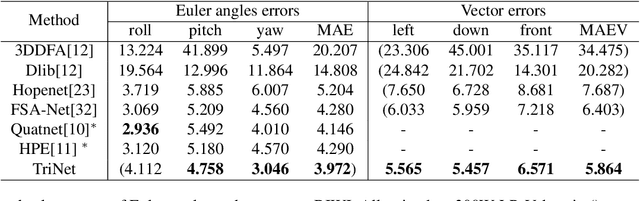
This paper proposes to use the three vectors in a rotation matrix as the representation in head pose estimation and develops a new neural network based on the characteristic of such representation. We address two potential issues existed in current head pose estimation works: 1. Public datasets for head pose estimation use either Euler angles or quaternions to annotate data samples. However, both of these annotations have the issue of discontinuity and thus could result in some performance issues in neural network training. 2. Most research works report Mean Absolute Error (MAE) of Euler angles as the measurement of performance. We show that MAE may not reflect the actual behavior especially for the cases of profile views. To solve these two problems, we propose a new annotation method which uses three vectors to describe head poses and a new measurement Mean Absolute Error of Vectors (MAEV) to assess the performance. We also train a new neural network to predict the three vectors with the constraints of orthogonality. Our proposed method achieves state-of-the-art results on both AFLW2000 and BIWI datasets. Experiments show our vector-based annotation method can effectively reduce prediction errors for large pose angles.
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Aug 13, 2020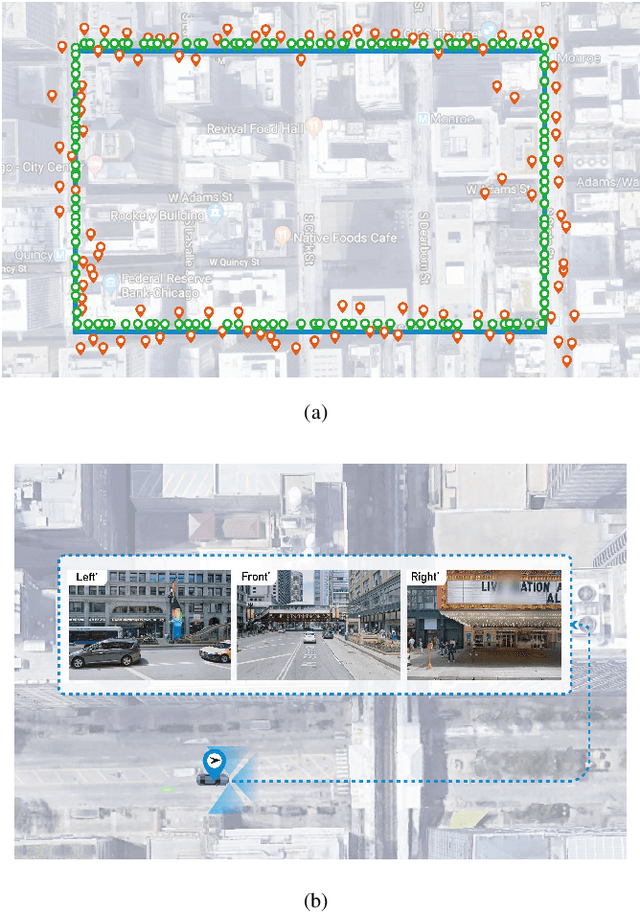
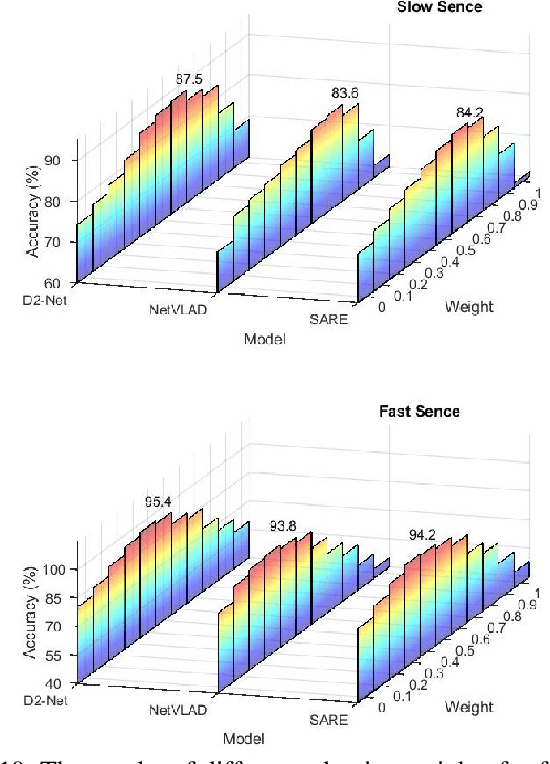
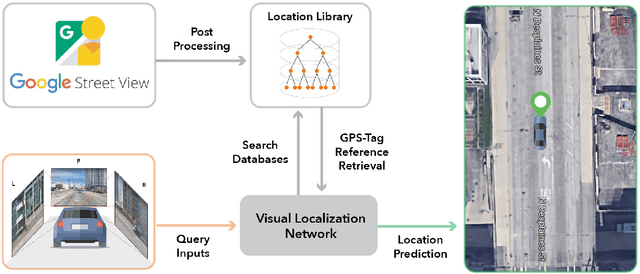
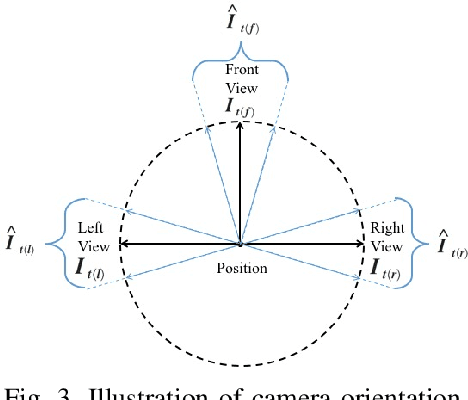
Accurate localization is a foundational capacity, required for autonomous vehicles to accomplish other tasks such as navigation or path planning. It is a common practice for vehicles to use GPS to acquire location information. However, the application of GPS can result in severe challenges when vehicles run within the inner city where different kinds of structures may shadow the GPS signal and lead to inaccurate location results. To address the localization challenges of urban settings, we propose a novel feature voting technique for visual localization. Different from the conventional front-view-based method, our approach employs views from three directions (front, left, and right) and thus significantly improves the robustness of location prediction. In our work, we craft the proposed feature voting method into three state-of-the-art visual localization networks and modify their architectures properly so that they can be applied for vehicular operation. Extensive field test results indicate that our approach can predict location robustly even in challenging inner-city settings. Our research sheds light on using the visual localization approach to help autonomous vehicles to find accurate location information in a city maze, within a desirable time constraint.
ICFVR 2017: 3rd International Competition on Finger Vein Recognition
Jan 04, 2018
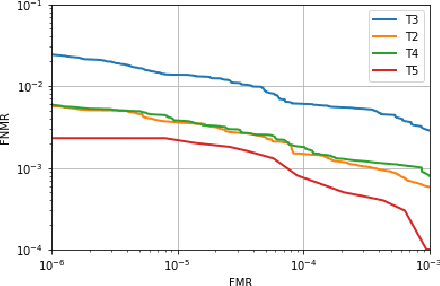
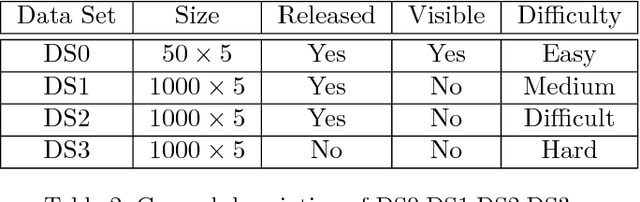
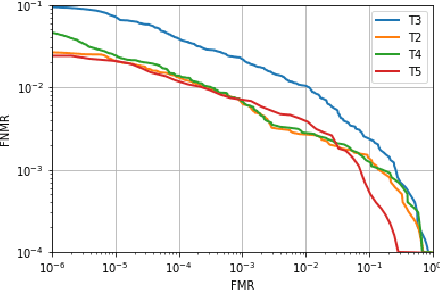
In recent years, finger vein recognition has become an important sub-field in biometrics and been applied to real-world applications. The development of finger vein recognition algorithms heavily depends on large-scale real-world data sets. In order to motivate research on finger vein recognition, we released the largest finger vein data set up to now and hold finger vein recognition competitions based on our data set every year. In 2017, International Competition on Finger Vein Recognition(ICFVR) is held jointly with IJCB 2017. 11 teams registered and 10 of them joined the final evaluation. The winner of this year dramatically improved the EER from 2.64% to 0.483% compared to the winner of last year. In this paper, we introduce the process and results of ICFVR 2017 and give insights on development of state-of-art finger vein recognition algorithms.