 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions
Oct 11, 2023Web-crawled datasets are pivotal to the success of pre-training vision-language models, exemplified by CLIP. However, web-crawled AltTexts can be noisy and potentially irrelevant to images, thereby undermining the crucial image-text alignment. Existing methods for rewriting captions using large language models (LLMs) have shown promise on small, curated datasets like CC3M and CC12M. Nevertheless, their efficacy on massive web-captured captions is constrained by the inherent noise and randomness in such data. In this study, we address this limitation by focusing on two key aspects: data quality and data variety. Unlike recent LLM rewriting techniques, we emphasize exploiting visual concepts and their integration into the captions to improve data quality. For data variety, we propose a novel mixed training scheme that optimally leverages AltTexts alongside newly generated Visual-enriched Captions (VeC). We use CLIP as one example and adapt the method for CLIP training on large-scale web-crawled datasets, named VeCLIP. We conduct a comprehensive evaluation of VeCLIP across small, medium, and large scales of raw data. Our results show significant advantages in image-text alignment and overall model performance, underscoring the effectiveness of VeCLIP in improving CLIP training. For example, VeCLIP achieves a remarkable over 20% improvement in COCO and Flickr30k retrieval tasks under the 12M setting. For data efficiency, we also achieve a notable over 3% improvement while using only 14% of the data employed in the vanilla CLIP and 11% in ALIGN.
Compressing LLMs: The Truth is Rarely Pure and Never Simple
Oct 02, 2023Despite their remarkable achievements, modern Large Language Models (LLMs) encounter exorbitant computational and memory footprints. Recently, several works have shown significant success in training-free and data-free compression (pruning and quantization) of LLMs achieving 50-60% sparsity and reducing the bit-width down to 3 or 4 bits per weight, with negligible perplexity degradation over the uncompressed baseline. As recent research efforts are focused on developing increasingly sophisticated compression methods, our work takes a step back, and re-evaluates the effectiveness of existing SoTA compression methods, which rely on a fairly simple and widely questioned metric, perplexity (even for dense LLMs). We introduce Knowledge-Intensive Compressed LLM BenchmarK (LLM-KICK), a collection of carefully-curated tasks to re-define the evaluation protocol for compressed LLMs, which have significant alignment with their dense counterparts, and perplexity fail to capture subtle change in their true capabilities. LLM-KICK unveils many favorable merits and unfortunate plights of current SoTA compression methods: all pruning methods suffer significant performance degradation, sometimes at trivial sparsity ratios (e.g., 25-30%), and fail for N:M sparsity on knowledge-intensive tasks; current quantization methods are more successful than pruning; yet, pruned LLMs even at $\geq 50$% sparsity are robust in-context retrieval and summarization systems; among others. LLM-KICK is designed to holistically access compressed LLMs' ability for language understanding, reasoning, generation, in-context retrieval, in-context summarization, etc. We hope our study can foster the development of better LLM compression methods. All our related codes are planed to be open-sourced.
Guiding Instruction-based Image Editing via Multimodal Large Language Models
Sep 29, 2023Instruction-based image editing improves the controllability and flexibility of image manipulation via natural commands without elaborate descriptions or regional masks. However, human instructions are sometimes too brief for current methods to capture and follow. Multimodal large language models (MLLMs) show promising capabilities in cross-modal understanding and visual-aware response generation via LMs. We investigate how MLLMs facilitate edit instructions and present MLLM-Guided Image Editing (MGIE). MGIE learns to derive expressive instructions and provides explicit guidance. The editing model jointly captures this visual imagination and performs manipulation through end-to-end training. We evaluate various aspects of Photoshop-style modification, global photo optimization, and local editing. Extensive experimental results demonstrate that expressive instructions are crucial to instruction-based image editing, and our MGIE can lead to a notable improvement in automatic metrics and human evaluation while maintaining competitive inference efficiency.
Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
Sep 08, 2023



Sparse Mixture-of-Experts models (MoEs) have recently gained popularity due to their ability to decouple model size from inference efficiency by only activating a small subset of the model parameters for any given input token. As such, sparse MoEs have enabled unprecedented scalability, resulting in tremendous successes across domains such as natural language processing and computer vision. In this work, we instead explore the use of sparse MoEs to scale-down Vision Transformers (ViTs) to make them more attractive for resource-constrained vision applications. To this end, we propose a simplified and mobile-friendly MoE design where entire images rather than individual patches are routed to the experts. We also propose a stable MoE training procedure that uses super-class information to guide the router. We empirically show that our sparse Mobile Vision MoEs (V-MoEs) can achieve a better trade-off between performance and efficiency than the corresponding dense ViTs. For example, for the ViT-Tiny model, our Mobile V-MoE outperforms its dense counterpart by 3.39% on ImageNet-1k. For an even smaller ViT variant with only 54M FLOPs inference cost, our MoE achieves an improvement of 4.66%.
MOFI: Learning Image Representations from Noisy Entity Annotated Images
Jun 24, 2023We present MOFI, a new vision foundation model designed to learn image representations from noisy entity annotated images. MOFI differs from previous work in two key aspects: ($i$) pre-training data, and ($ii$) training recipe. Regarding data, we introduce a new approach to automatically assign entity labels to images from noisy image-text pairs. Our approach involves employing a named entity recognition model to extract entities from the alt-text, and then using a CLIP model to select the correct entities as labels of the paired image. The approach is simple, does not require costly human annotation, and can be readily scaled up to billions of image-text pairs mined from the web. Through this method, we have created Image-to-Entities (I2E), a new large-scale dataset with 1 billion images and 2 million distinct entities, covering rich visual concepts in the wild. Building upon the I2E dataset, we study different training recipes, including supervised pre-training, contrastive pre-training, and multi-task learning. For constrastive pre-training, we treat entity names as free-form text, and further enrich them with entity descriptions. Experiments show that supervised pre-training with large-scale fine-grained entity labels is highly effective for image retrieval tasks, and multi-task training further improves the performance. The final MOFI model achieves 86.66% mAP on the challenging GPR1200 dataset, surpassing the previous state-of-the-art performance of 72.19% from OpenAI's CLIP model. Further experiments on zero-shot and linear probe image classification also show that MOFI outperforms a CLIP model trained on the original image-text data, demonstrating the effectiveness of the I2E dataset in learning strong image representations.
Less is More: Removing Text-regions Improves CLIP Training Efficiency and Robustness
May 08, 2023The CLIP (Contrastive Language-Image Pre-training) model and its variants are becoming the de facto backbone in many applications. However, training a CLIP model from hundreds of millions of image-text pairs can be prohibitively expensive. Furthermore, the conventional CLIP model doesn't differentiate between the visual semantics and meaning of text regions embedded in images. This can lead to non-robustness when the text in the embedded region doesn't match the image's visual appearance. In this paper, we discuss two effective approaches to improve the efficiency and robustness of CLIP training: (1) augmenting the training dataset while maintaining the same number of optimization steps, and (2) filtering out samples that contain text regions in the image. By doing so, we significantly improve the classification and retrieval accuracy on public benchmarks like ImageNet and CoCo. Filtering out images with text regions also protects the model from typographic attacks. To verify this, we build a new dataset named ImageNet with Adversarial Text Regions (ImageNet-Attr). Our filter-based CLIP model demonstrates a top-1 accuracy of 68.78\%, outperforming previous models whose accuracy was all below 50\%.
On Robustness in Multimodal Learning
Apr 11, 2023Multimodal learning is defined as learning over multiple heterogeneous input modalities such as video, audio, and text. In this work, we are concerned with understanding how models behave as the type of modalities differ between training and deployment, a situation that naturally arises in many applications of multimodal learning to hardware platforms. We present a multimodal robustness framework to provide a systematic analysis of common multimodal representation learning methods. Further, we identify robustness short-comings of these approaches and propose two intervention techniques leading to $1.5\times$-$4\times$ robustness improvements on three datasets, AudioSet, Kinetics-400 and ImageNet-Captions. Finally, we demonstrate that these interventions better utilize additional modalities, if present, to achieve competitive results of $44.2$ mAP on AudioSet 20K.
STAIR: Learning Sparse Text and Image Representation in Grounded Tokens
Feb 08, 2023Image and text retrieval is one of the foundational tasks in the vision and language domain with multiple real-world applications. State-of-the-art approaches, e.g. CLIP, ALIGN, represent images and texts as dense embeddings and calculate the similarity in the dense embedding space as the matching score. On the other hand, sparse semantic features like bag-of-words models are more interpretable, but believed to suffer from inferior accuracy than dense representations. In this work, we show that it is possible to build a sparse semantic representation that is as powerful as, or even better than, dense presentations. We extend the CLIP model and build a sparse text and image representation (STAIR), where the image and text are mapped to a sparse token space. Each token in the space is a (sub-)word in the vocabulary, which is not only interpretable but also easy to integrate with existing information retrieval systems. STAIR model significantly outperforms a CLIP model with +$4.9\%$ and +$4.3\%$ absolute Recall@1 improvement on COCO-5k text$\rightarrow$image and image$\rightarrow$text retrieval respectively. It also achieved better performance on both of ImageNet zero-shot and linear probing compared to CLIP.
Self Supervision Does Not Help Natural Language Supervision at Scale
Jan 20, 2023



Self supervision and natural language supervision have emerged as two exciting ways to train general purpose image encoders which excel at a variety of downstream tasks. Recent works such as M3AE and SLIP have suggested that these approaches can be effectively combined, but most notably their results use small pre-training datasets (<50M samples) and don't effectively reflect the large-scale regime (>100M examples) that is commonly used for these approaches. Here we investigate whether a similar approach can be effective when trained with a much larger amount of data. We find that a combination of two state of the art approaches: masked auto-encoders, MAE and contrastive language image pre-training, CLIP provides a benefit over CLIP when trained on a corpus of 11.3M image-text pairs, but little to no benefit (as evaluated on a suite of common vision tasks) over CLIP when trained on a large corpus of 1.4B images. Our work provides some much needed clarity into the effectiveness (or lack thereof) of self supervision for large-scale image-text training.
Perceptual Grouping in Vision-Language Models
Oct 18, 2022
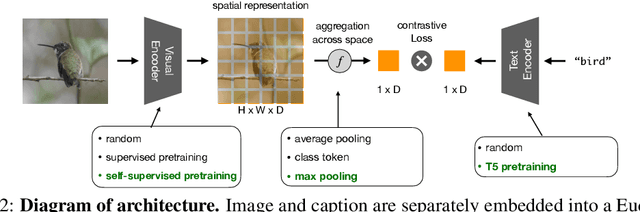
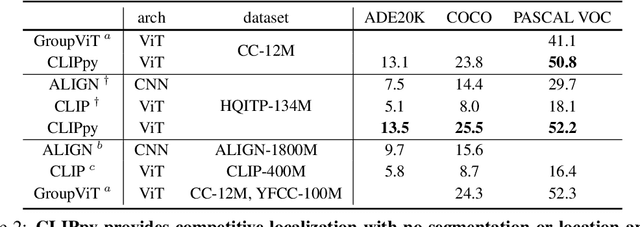
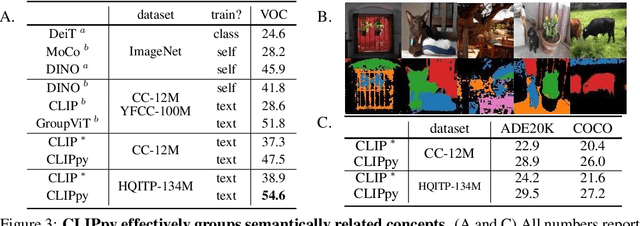
Recent advances in zero-shot image recognition suggest that vision-language models learn generic visual representations with a high degree of semantic information that may be arbitrarily probed with natural language phrases. Understanding an image, however, is not just about understanding what content resides within an image, but importantly, where that content resides. In this work we examine how well vision-language models are able to understand where objects reside within an image and group together visually related parts of the imagery. We demonstrate how contemporary vision and language representation learning models based on contrastive losses and large web-based data capture limited object localization information. We propose a minimal set of modifications that results in models that uniquely learn both semantic and spatial information. We measure this performance in terms of zero-shot image recognition, unsupervised bottom-up and top-down semantic segmentations, as well as robustness analyses. We find that the resulting model achieves state-of-the-art results in terms of unsupervised segmentation, and demonstrate that the learned representations are uniquely robust to spurious correlations in datasets designed to probe the causal behavior of vision models.