 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Gap Minimization Improves Sharpness-Aware Training
Mar 19, 2022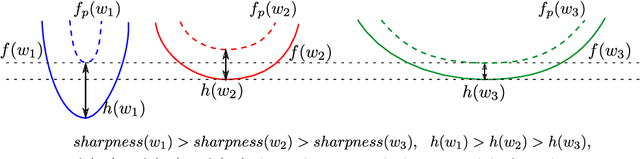
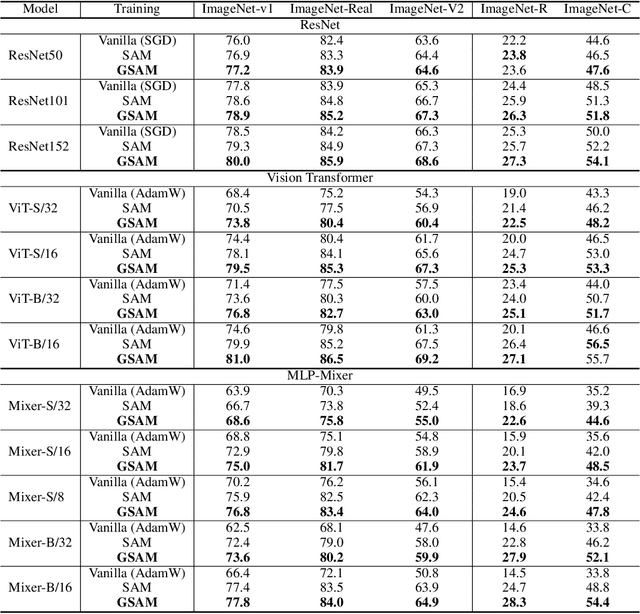


The recently proposed Sharpness-Aware Minimization (SAM) improves generalization by minimizing a \textit{perturbed loss} defined as the maximum loss within a neighborhood in the parameter space. However, we show that both sharp and flat minima can have a low perturbed loss, implying that SAM does not always prefer flat minima. Instead, we define a \textit{surrogate gap}, a measure equivalent to the dominant eigenvalue of Hessian at a local minimum when the radius of the neighborhood (to derive the perturbed loss) is small. The surrogate gap is easy to compute and feasible for direct minimization during training. Based on the above observations, we propose Surrogate \textbf{G}ap Guided \textbf{S}harpness-\textbf{A}ware \textbf{M}inimization (GSAM), a novel improvement over SAM with negligible computation overhead. Conceptually, GSAM consists of two steps: 1) a gradient descent like SAM to minimize the perturbed loss, and 2) an \textit{ascent} step in the \textit{orthogonal} direction (after gradient decomposition) to minimize the surrogate gap and yet not affect the perturbed loss. GSAM seeks a region with both small loss (by step 1) and low sharpness (by step 2), giving rise to a model with high generalization capabilities. Theoretically, we show the convergence of GSAM and provably better generalization than SAM. Empirically, GSAM consistently improves generalization (e.g., +3.2\% over SAM and +5.4\% over AdamW on ImageNet top-1 accuracy for ViT-B/32). Code is released at \url{ https://sites.google.com/view/gsam-iclr22/home}.
Open-Vocabulary Image Segmentation
Dec 22, 2021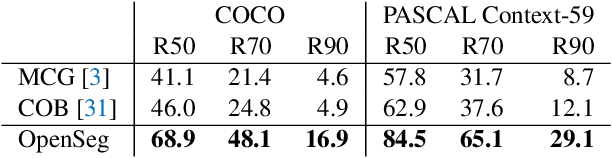

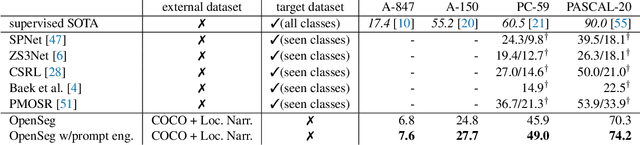
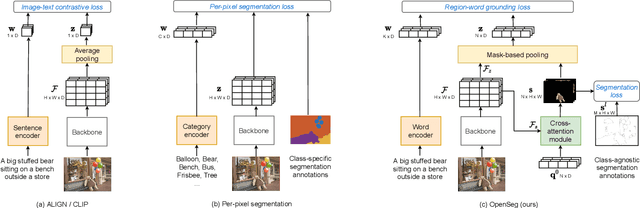
We design an open-vocabulary image segmentation model to organize an image into meaningful regions indicated by arbitrary texts. We identify that recent open-vocabulary models can not localize visual concepts well despite recognizing what are in an image. We argue that these models miss an important step of visual grouping, which organizes pixels into groups before learning visual-semantic alignments. We propose OpenSeg to address the above issue. First, it learns to propose segmentation masks for possible organizations. Then it learns visual-semantic alignments by aligning each word in a caption to one or a few predicted masks. We find the mask representations are the key to support learning from captions, making it possible to scale up the dataset and vocabulary sizes. Our work is the first to perform zero-shot transfer on holdout segmentation datasets. We set up two strong baselines by applying class activation maps or fine-tuning with pixel-wise labels on a pre-trained ALIGN model. OpenSeg outperforms these baselines by 3.4 mIoU on PASCAL-Context (459 classes) and 2.7 mIoU on ADE-20k (847 classes).
Towards a Unified Foundation Model: Jointly Pre-Training Transformers on Unpaired Images and Text
Dec 14, 2021



In this paper, we explore the possibility of building a unified foundation model that can be adapted to both vision-only and text-only tasks. Starting from BERT and ViT, we design a unified transformer consisting of modality-specific tokenizers, a shared transformer encoder, and task-specific output heads. To efficiently pre-train the proposed model jointly on unpaired images and text, we propose two novel techniques: (i) We employ the separately-trained BERT and ViT models as teachers and apply knowledge distillation to provide additional, accurate supervision signals for the joint training; (ii) We propose a novel gradient masking strategy to balance the parameter updates from the image and text pre-training losses. We evaluate the jointly pre-trained transformer by fine-tuning it on image classification tasks and natural language understanding tasks, respectively. The experiments show that the resultant unified foundation transformer works surprisingly well on both the vision-only and text-only tasks, and the proposed knowledge distillation and gradient masking strategy can effectively lift the performance to approach the level of separately-trained models.
Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision
Dec 09, 2021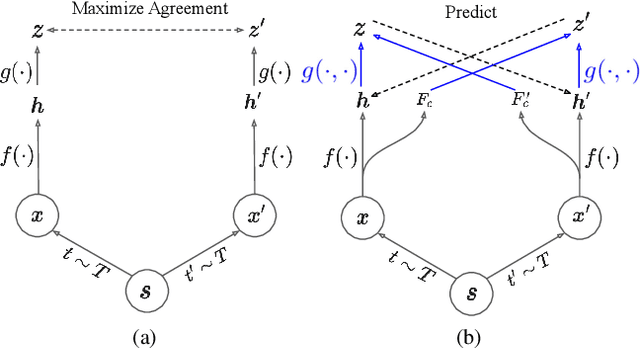
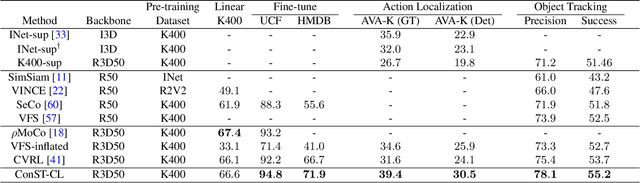
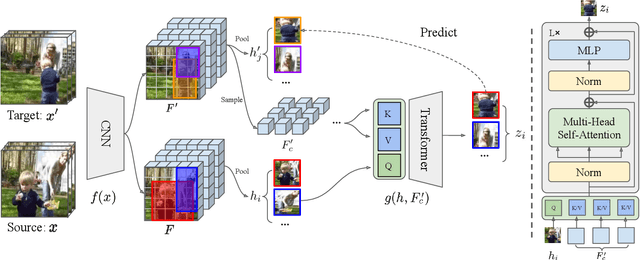
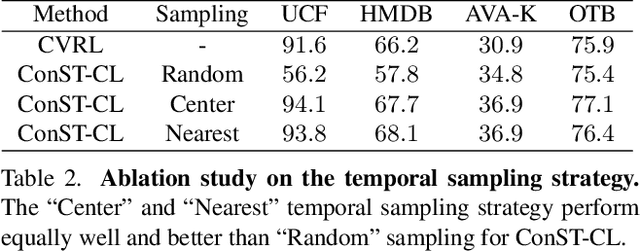
A modern self-supervised learning algorithm typically enforces persistency of the representations of an instance across views. While being very effective on learning holistic image and video representations, such an approach becomes sub-optimal for learning spatio-temporally fine-grained features in videos, where scenes and instances evolve through space and time. In this paper, we present the Contextualized Spatio-Temporal Contrastive Learning (ConST-CL) framework to effectively learn spatio-temporally fine-grained representations using self-supervision. We first design a region-based self-supervised pretext task which requires the model to learn to transform instance representations from one view to another guided by context features. Further, we introduce a simple network design that effectively reconciles the simultaneous learning process of both holistic and local representations. We evaluate our learned representations on a variety of downstream tasks and ConST-CL achieves state-of-the-art results on four datasets. For spatio-temporal action localization, ConST-CL achieves 39.4% mAP with ground-truth boxes and 30.5% mAP with detected boxes on the AVA-Kinetics validation set. For object tracking, ConST-CL achieves 78.1% precision and 55.2% success scores on OTB2015. Furthermore, ConST-CL achieves 94.8% and 71.9% top-1 fine-tuning accuracy on video action recognition datasets, UCF101 and HMDB51 respectively. We plan to release our code and models to the public.
Exploring Temporal Granularity in Self-Supervised Video Representation Learning
Dec 08, 2021



This work presents a self-supervised learning framework named TeG to explore Temporal Granularity in learning video representations. In TeG, we sample a long clip from a video and a short clip that lies inside the long clip. We then extract their dense temporal embeddings. The training objective consists of two parts: a fine-grained temporal learning objective to maximize the similarity between corresponding temporal embeddings in the short clip and the long clip, and a persistent temporal learning objective to pull together global embeddings of the two clips. Our study reveals the impact of temporal granularity with three major findings. 1) Different video tasks may require features of different temporal granularities. 2) Intriguingly, some tasks that are widely considered to require temporal awareness can actually be well addressed by temporally persistent features. 3) The flexibility of TeG gives rise to state-of-the-art results on 8 video benchmarks, outperforming supervised pre-training in most cases.
Revisiting 3D ResNets for Video Recognition
Sep 03, 2021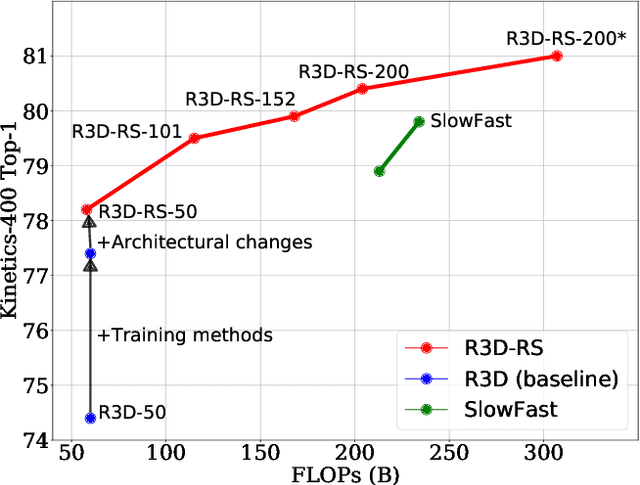
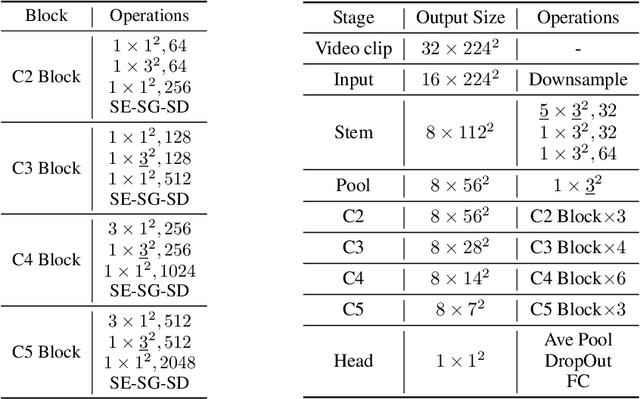
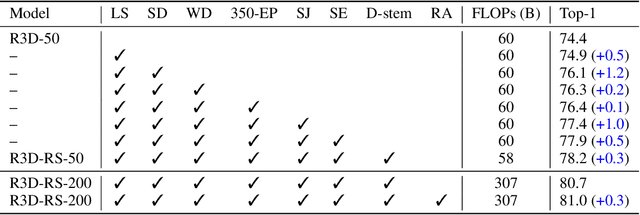
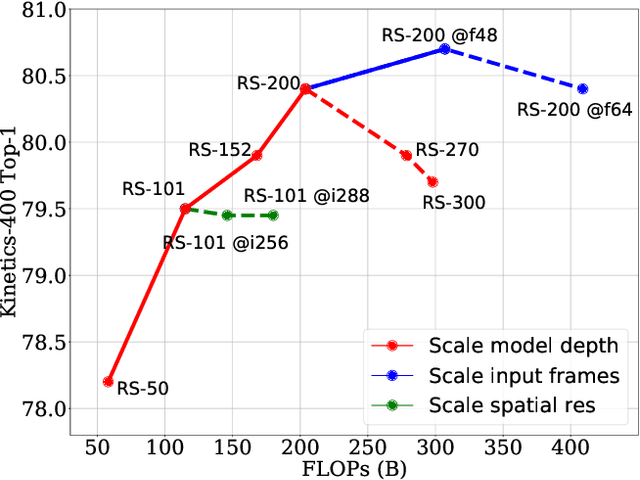
A recent work from Bello shows that training and scaling strategies may be more significant than model architectures for visual recognition. This short note studies effective training and scaling strategies for video recognition models. We propose a simple scaling strategy for 3D ResNets, in combination with improved training strategies and minor architectural changes. The resulting models, termed 3D ResNet-RS, attain competitive performance of 81.0 on Kinetics-400 and 83.8 on Kinetics-600 without pre-training. When pre-trained on a large Web Video Text dataset, our best model achieves 83.5 and 84.3 on Kinetics-400 and Kinetics-600. The proposed scaling rule is further evaluated in a self-supervised setup using contrastive learning, demonstrating improved performance. Code is available at: https://github.com/tensorflow/models/tree/master/official.
Federated Multi-Target Domain Adaptation
Aug 17, 2021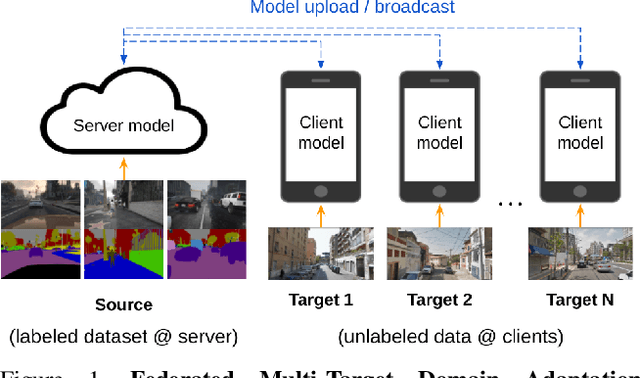
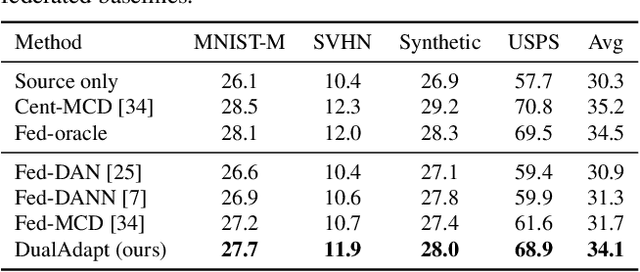
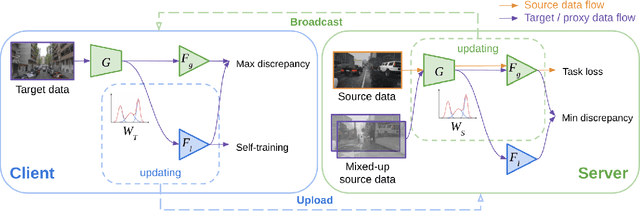
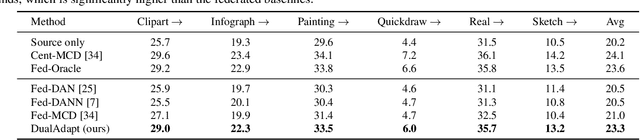
Federated learning methods enable us to train machine learning models on distributed user data while preserving its privacy. However, it is not always feasible to obtain high-quality supervisory signals from users, especially for vision tasks. Unlike typical federated settings with labeled client data, we consider a more practical scenario where the distributed client data is unlabeled, and a centralized labeled dataset is available on the server. We further take the server-client and inter-client domain shifts into account and pose a domain adaptation problem with one source (centralized server data) and multiple targets (distributed client data). Within this new Federated Multi-Target Domain Adaptation (FMTDA) task, we analyze the model performance of exiting domain adaptation methods and propose an effective DualAdapt method to address the new challenges. Extensive experimental results on image classification and semantic segmentation tasks demonstrate that our method achieves high accuracy, incurs minimal communication cost, and requires low computational resources on client devices.
Single Image Texture Translation for Data Augmentation
Jun 25, 2021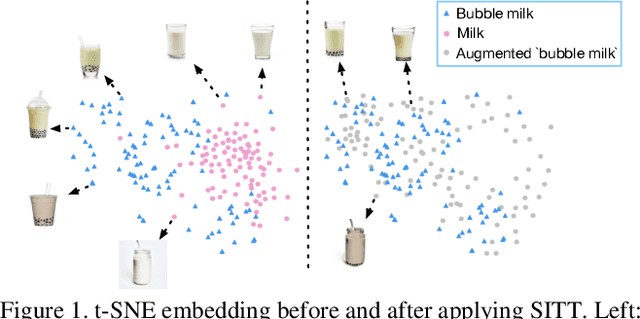
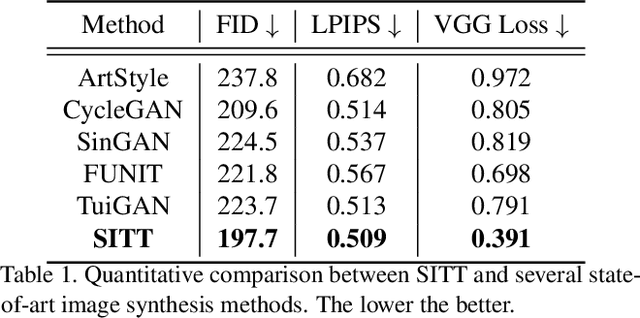
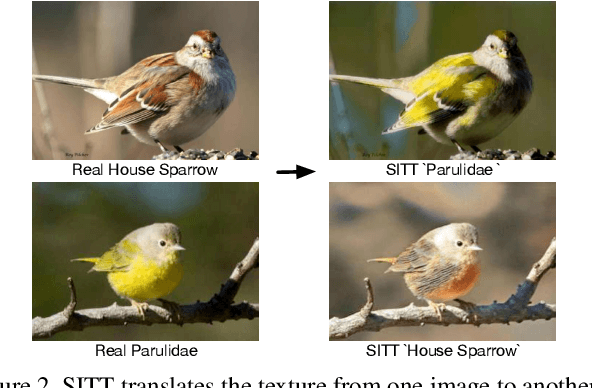
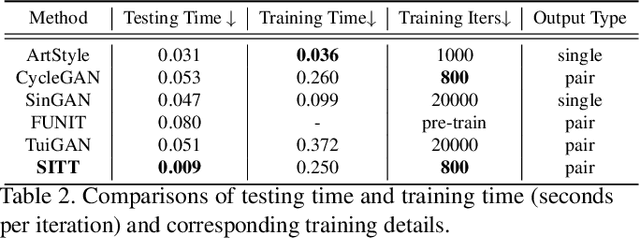
Recent advances in image synthesis enables one to translate images by learning the mapping between a source domain and a target domain. Existing methods tend to learn the distributions by training a model on a variety of datasets, with results evaluated largely in a subjective manner. Relatively few works in this area, however, study the potential use of semantic image translation methods for image recognition tasks. In this paper, we explore the use of Single Image Texture Translation (SITT) for data augmentation. We first propose a lightweight model for translating texture to images based on a single input of source texture, allowing for fast training and testing. Based on SITT, we then explore the use of augmented data in long-tailed and few-shot image classification tasks. We find the proposed method is capable of translating input data into a target domain, leading to consistent improved image recognition performance. Finally, we examine how SITT and related image translation methods can provide a basis for a data-efficient, augmentation engineering approach to model training.
Bridging the Gap Between Object Detection and User Intent via Query-Modulation
Jun 18, 2021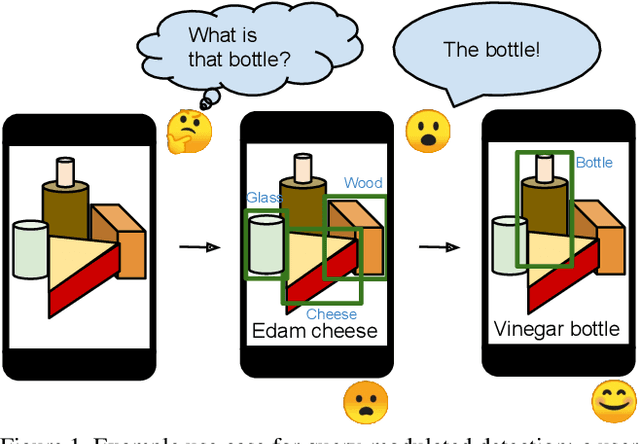

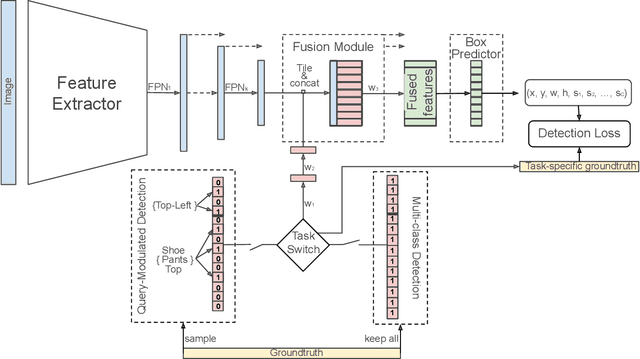
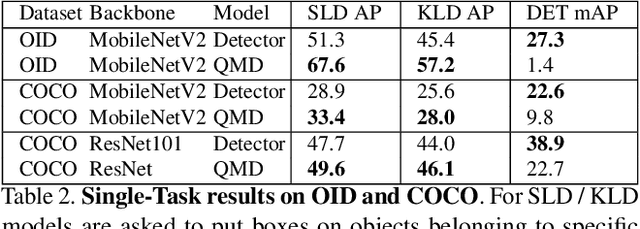
When interacting with objects through cameras, or pictures, users often have a specific intent. For example, they may want to perform a visual search. However, most object detection models ignore the user intent, relying on image pixels as their only input. This often leads to incorrect results, such as lack of a high-confidence detection on the object of interest, or detection with a wrong class label. In this paper we investigate techniques to modulate standard object detectors to explicitly account for the user intent, expressed as an embedding of a simple query. Compared to standard object detectors, query-modulated detectors show superior performance at detecting objects for a given label of interest. Thanks to large-scale training data synthesized from standard object detection annotations, query-modulated detectors can also outperform specialized referring expression recognition systems. Furthermore, they can be simultaneously trained to solve for both query-modulated detection and standard object detection.
Zero-Shot Detection via Vision and Language Knowledge Distillation
Apr 28, 2021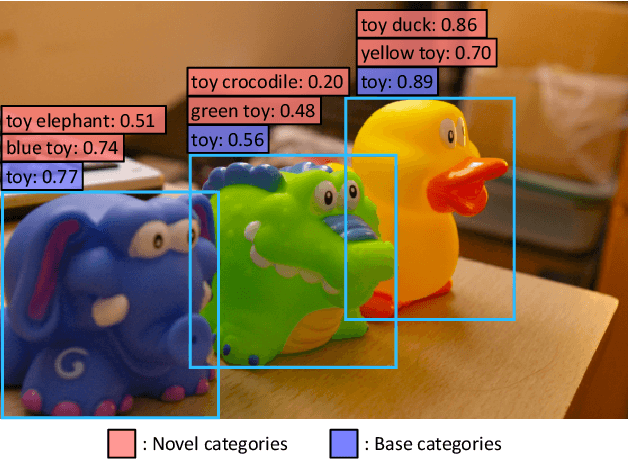

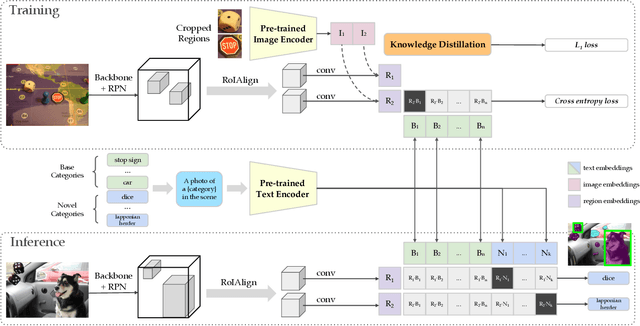
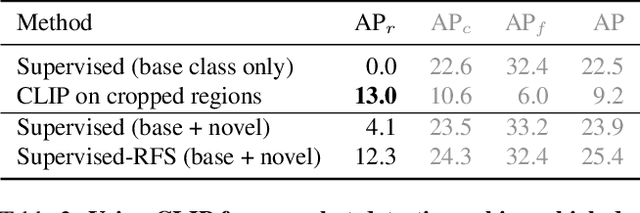
Zero-shot image classification has made promising progress by training the aligned image and text encoders. The goal of this work is to advance zero-shot object detection, which aims to detect novel objects without bounding box nor mask annotations. We propose ViLD, a training method via Vision and Language knowledge Distillation. We distill the knowledge from a pre-trained zero-shot image classification model (e.g., CLIP) into a two-stage detector (e.g., Mask R-CNN). Our method aligns the region embeddings in the detector to the text and image embeddings inferred by the pre-trained model. We use the text embeddings as the detection classifier, obtained by feeding category names into the pre-trained text encoder. We then minimize the distance between the region embeddings and image embeddings, obtained by feeding region proposals into the pre-trained image encoder. During inference, we include text embeddings of novel categories into the detection classifier for zero-shot detection. We benchmark the performance on LVIS dataset by holding out all rare categories as novel categories. ViLD obtains 16.1 mask AP$_r$ with a Mask R-CNN (ResNet-50 FPN) for zero-shot detection, outperforming the supervised counterpart by 3.8. The model can directly transfer to other datasets, achieving 72.2 AP$_{50}$, 36.6 AP and 11.8 AP on PASCAL VOC, COCO and Objects365, respectively.