 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircuitSense: A Hierarchical Circuit System Benchmark Bridging Visual Comprehension and Symbolic Reasoning in Engineering Design Process
Sep 26, 2025Engineering design operates through hierarchical abstraction from system specifications to component implementations, requiring visual understanding coupled with mathematical reasoning at each level. While Multi-modal Large Language Models (MLLMs) excel at natural image tasks, their ability to extract mathematical models from technical diagrams remains unexplored. We present \textbf{CircuitSense}, a comprehensive benchmark evaluating circuit understanding across this hierarchy through 8,006+ problems spanning component-level schematics to system-level block diagrams. Our benchmark uniquely examines the complete engineering workflow: Perception, Analysis, and Design, with a particular emphasis on the critical but underexplored capability of deriving symbolic equations from visual inputs. We introduce a hierarchical synthetic generation pipeline consisting of a grid-based schematic generator and a block diagram generator with auto-derived symbolic equation labels. Comprehensive evaluation of six state-of-the-art MLLMs, including both closed-source and open-source models, reveals fundamental limitations in visual-to-mathematical reasoning. Closed-source models achieve over 85\% accuracy on perception tasks involving component recognition and topology identification, yet their performance on symbolic derivation and analytical reasoning falls below 19\%, exposing a critical gap between visual parsing and symbolic reasoning. Models with stronger symbolic reasoning capabilities consistently achieve higher design task accuracy, confirming the fundamental role of mathematical understanding in circuit synthesis and establishing symbolic reasoning as the key metric for engineering competence.
Amplified Vulnerabilities: Structured Jailbreak Attacks on LLM-based Multi-Agent Debate
Apr 23, 2025



Multi-Agent Debate (MAD), leveraging collaborative interactions among Large Language Models (LLMs), aim to enhance reasoning capabilities in complex tasks. However, the security implications of their iterative dialogues and role-playing characteristics, particularly susceptibility to jailbreak attacks eliciting harmful content, remain critically underexplored. This paper systematically investigates the jailbreak vulnerabilities of four prominent MAD frameworks built upon leading commercial LLMs (GPT-4o, GPT-4, GPT-3.5-turbo, and DeepSeek) without compromising internal agents. We introduce a novel structured prompt-rewriting framework specifically designed to exploit MAD dynamics via narrative encapsulation, role-driven escalation, iterative refinement, and rhetorical obfuscation. Our extensive experiments demonstrate that MAD systems are inherently more vulnerable than single-agent setups. Crucially, our proposed attack methodology significantly amplifies this fragility, increasing average harmfulness from 28.14% to 80.34% and achieving attack success rates as high as 80% in certain scenarios. These findings reveal intrinsic vulnerabilities in MAD architectures and underscore the urgent need for robust, specialized defenses prior to real-world deployment.
Unity is Power: Semi-Asynchronous Collaborative Training of Large-Scale Models with Structured Pruning in Resource-Limited Clients
Oct 11, 2024



In this work, we study to release the potential of massive heterogeneous weak computing power to collaboratively train large-scale models on dispersed datasets. In order to improve both efficiency and accuracy in resource-adaptive collaborative learning, we take the first step to consider the \textit{unstructured pruning}, \textit{varying submodel architectures}, \textit{knowledge loss}, and \textit{straggler} challenges simultaneously. We propose a novel semi-asynchronous collaborative training framework, namely ${Co\text{-}S}^2{P}$, with data distribution-aware structured pruning and cross-block knowledge transfer mechanism to address the above concerns. Furthermore, we provide theoretical proof that ${Co\text{-}S}^2{P}$ can achieve asymptotic optimal convergence rate of $O(1/\sqrt{N^*EQ})$. Finally, we conduct extensive experiments on a real-world hardware testbed, in which 16 heterogeneous Jetson devices can be united to train large-scale models with parameters up to 0.11 billion. The experimental results demonstrate that $Co\text{-}S^2P$ improves accuracy by up to 8.8\% and resource utilization by up to 1.2$\times$ compared to state-of-the-art methods, while reducing memory consumption by approximately 22\% and training time by about 24\% on all resource-limited devices.
Federating to Grow Transformers with Constrained Resources without Model Sharing
Jun 19, 2024



The high resource consumption of large-scale models discourages resource-constrained users from developing their customized transformers. To this end, this paper considers a federated framework named Fed-Grow for multiple participants to cooperatively scale a transformer from their pre-trained small models. Under the Fed-Grow, a Dual-LiGO (Dual Linear Growth Operator) architecture is designed to help participants expand their pre-trained small models to a transformer. In Dual-LiGO, the Local-LiGO part is used to address the heterogeneity problem caused by the various pre-trained models, and the Global-LiGO part is shared to exchange the implicit knowledge from the pre-trained models, local data, and training process of participants. Instead of model sharing, only sharing the Global-LiGO strengthens the privacy of our approach. Compared with several state-of-the-art methods in simulation, our approach has higher accuracy, better precision, and lower resource consumption on computations and communications. To the best of our knowledge, most of the previous model-scaling works are centralized, and our work is the first one that cooperatively grows a transformer from multiple pre-trained heterogeneous models with the user privacy protected in terms of local data and models. We hope that our approach can extend the transformers to the broadly distributed scenarios and encourage more resource-constrained users to enjoy the bonus taken by the large-scale transformers.
A Resource-Adaptive Approach for Federated Learning under Resource-Constrained Environments
Jun 19, 2024



The paper studies a fundamental federated learning (FL) problem involving multiple clients with heterogeneous constrained resources. Compared with the numerous training parameters, the computing and communication resources of clients are insufficient for fast local training and real-time knowledge sharing. Besides, training on clients with heterogeneous resources may result in the straggler problem. To address these issues, we propose Fed-RAA: a Resource-Adaptive Asynchronous Federated learning algorithm. Different from vanilla FL methods, where all parameters are trained by each participating client regardless of resource diversity, Fed-RAA adaptively allocates fragments of the global model to clients based on their computing and communication capabilities. Each client then individually trains its assigned model fragment and asynchronously uploads the updated result. Theoretical analysis confirms the convergence of our approach. Additionally, we design an online greedy-based algorithm for fragment allocation in Fed-RAA, achieving fairness comparable to an offline strategy. We present numerical results on MNIST, CIFAR-10, and CIFAR-100, along with necessary comparisons and ablation studies, demonstrating the advantages of our work. To the best of our knowledge, this paper represents the first resource-adaptive asynchronous method for fragment-based FL with guaranteed theoretical convergence.
Leveraging Unknown Objects to Construct Labeled-Unlabeled Meta-Relationships for Zero-Shot Object Navigation
May 27, 2024Zero-shot object navigation (ZSON) addresses situation where an agent navigates to an unseen object that does not present in the training set. Previous works mainly train agent using seen objects with known labels, and ignore the seen objects without labels. In this paper, we introduce seen objects without labels, herein termed as ``unknown objects'', into training procedure to enrich the agent's knowledge base with distinguishable but previously overlooked information. Furthermore, we propose the label-wise meta-correlation module (LWMCM) to harness relationships among objects with and without labels, and obtain enhanced objects information. Specially, we propose target feature generator (TFG) to generate the features representation of the unlabeled target objects. Subsequently, the unlabeled object identifier (UOI) module assesses whether the unlabeled target object appears in the current observation frame captured by the camera and produces an adapted target features representation specific to the observed context. In meta contrastive feature modifier (MCFM), the target features is modified via approaching the features of objects within the observation frame while distancing itself from features of unobserved objects. Finally, the meta object-graph learner (MOGL) module is utilized to calculate the relationships among objects based on the features. Experiments conducted on AI2THOR and RoboTHOR platforms demonstrate the effectiveness of our proposed method.
Cooperative Backdoor Attack in Decentralized Reinforcement Learning with Theoretical Guarantee
May 24, 2024


The safety of decentralized reinforcement learning (RL) is a challenging problem since malicious agents can share their poisoned policies with benign agents. The paper investigates a cooperative backdoor attack in a decentralized reinforcement learning scenario. Differing from the existing methods that hide a whole backdoor attack behind their shared policies, our method decomposes the backdoor behavior into multiple components according to the state space of RL. Each malicious agent hides one component in its policy and shares its policy with the benign agents. When a benign agent learns all the poisoned policies, the backdoor attack is assembled in its policy. The theoretical proof is given to show that our cooperative method can successfully inject the backdoor into the RL policies of benign agents. Compared with the existing backdoor attacks, our cooperative method is more covert since the policy from each attacker only contains a component of the backdoor attack and is harder to detect. Extensive simulations are conducted based on Atari environments to demonstrate the efficiency and covertness of our method. To the best of our knowledge, this is the first paper presenting a provable cooperative backdoor attack in decentralized reinforcement learning.
Temporal-Spatial Object Relations Modeling for Vision-and-Language Navigation
Mar 23, 2024Vision-and-Language Navigation (VLN) is a challenging task where an agent is required to navigate to a natural language described location via vision observations. The navigation abilities of the agent can be enhanced by the relations between objects, which are usually learned using internal objects or external datasets. The relationships between internal objects are modeled employing graph convolutional network (GCN) in traditional studies. However, GCN tends to be shallow, limiting its modeling ability. To address this issue, we utilize a cross attention mechanism to learn the connections between objects over a trajectory, which takes temporal continuity into account, termed as Temporal Object Relations (TOR). The external datasets have a gap with the navigation environment, leading to inaccurate modeling of relations. To avoid this problem, we construct object connections based on observations from all viewpoints in the navigational environment, which ensures complete spatial coverage and eliminates the gap, called Spatial Object Relations (SOR). Additionally, we observe that agents may repeatedly visit the same location during navigation, significantly hindering their performance. For resolving this matter, we introduce the Turning Back Penalty (TBP) loss function, which penalizes the agent's repetitive visiting behavior, substantially reducing the navigational distance. Experimental results on the REVERIE, SOON, and R2R datasets demonstrate the effectiveness of the proposed method.
Too Much Information Kills Information: A Clustering Perspective
Sep 16, 2020
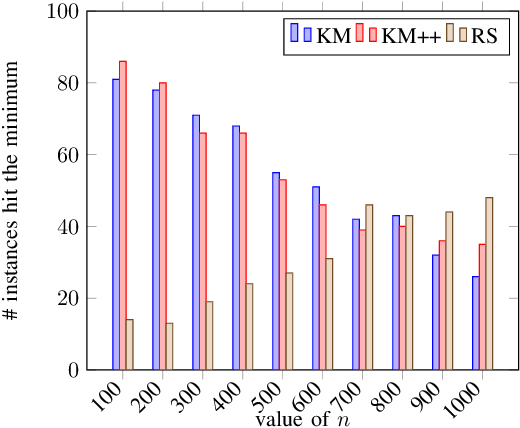
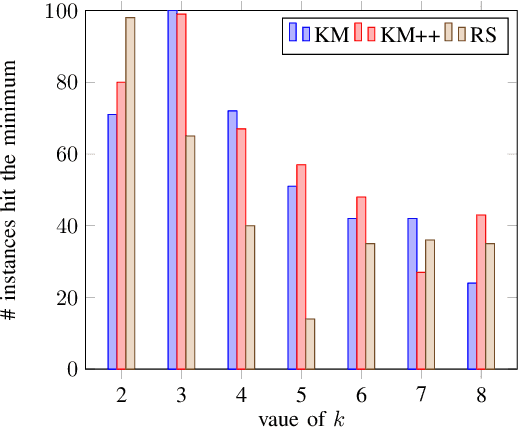
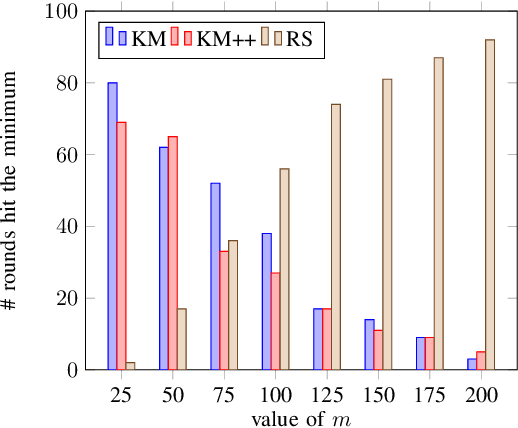
Clustering is one of the most fundamental tools in the artificial intelligence area, particularly in the pattern recognition and learning theory. In this paper, we propose a simple, but novel approach for variance-based k-clustering tasks, included in which is the widely known k-means clustering. The proposed approach picks a sampling subset from the given dataset and makes decisions based on the data information in the subset only. With certain assumptions, the resulting clustering is provably good to estimate the optimum of the variance-based objective with high probability. Extensive experiments on synthetic datasets and real-world datasets show that to obtain competitive results compared with k-means method (Llyod 1982) and k-means++ method (Arthur and Vassilvitskii 2007), we only need 7% information of the dataset. If we have up to 15% information of the dataset, then our algorithm outperforms both the k-means method and k-means++ method in at least 80% of the clustering tasks, in terms of the quality of clustering. Also, an extended algorithm based on the same idea guarantees a balanced k-clustering result.