 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-Inspired Capture: Evidence-Driven Neuromimetic Perceptual Simulation for Visual Decoding
Apr 20, 2026Visual decoding of neurophysiological signals is a critical challenge for brain-computer interfaces (BCIs) and computational neuroscience. However, current approaches are often constrained by the systematic and stochastic gaps between neural and visual modalities, largely neglecting the intrinsic computational mechanisms of the Human Visual System (HVS). To address this, we propose Brain-Inspired Capture (BI-Cap), a neuromimetic perceptual simulation paradigm that aligns these modalities by emulating HVS processing. Specifically, we construct a neuromimetic pipeline comprising four biologically plausible dynamic and static transformations, coupled with Mutual Information (MI)-guided dynamic blur regulation to simulate adaptive visual processing. Furthermore, to mitigate the inherent non-stationarity of neural activity, we introduce an evidence-driven latent space representation. This formulation explicitly models uncertainty, thereby ensuring robust neural embeddings. Extensive evaluations on zero-shot brain-to-image retrieval across two public benchmarks demonstrate that BI-Cap substantially outperforms state-of-the-art methods, achieving relative gains of 9.2\% and 8.0\%, respectively. We have released the source code on GitHub through the link https://github.com/flysnow1024/BI-Cap.
DMMRL: Disentangled Multi-Modal Representation Learning via Variational Autoencoders for Molecular Property Prediction
Mar 22, 2026Molecular property prediction constitutes a cornerstone of drug discovery and materials science, necessitating models capable of disentangling complex structure-property relationships across diverse molecular modalities. Existing approaches frequently exhibit entangled representations--conflating structural, chemical, and functional factors--thereby limiting interpretability and transferability. Furthermore, conventional methods inadequately exploit complementary information from graphs, sequences, and geometries, often relying on naive concatenation that neglects inter-modal dependencies. In this work, we propose DMMRL, which employs variational autoencoders to disentangle molecular representations into shared (structure-relevant) and private (modality-specific) latent spaces, enhancing both interpretability and predictive performance. The proposed variational disentanglement mechanism effectively isolates the most informative features for property prediction, while orthogonality and alignment regularizations promote statistical independence and cross-modal consistency. Additionally, a gated attention fusion module adaptively integrates shared representations, capturing complex inter-modal relationships. Experimental validation across seven benchmark datasets demonstrates DMMRL's superior performance relative to state-of-the-art approaches. The code and data underlying this article are freely available at https://github.com/xulong0826/DMMRL.
D4PM: A Dual-branch Driven Denoising Diffusion Probabilistic Model with Joint Posterior Diffusion Sampling for EEG Artifacts Removal
Sep 17, 2025



Artifact removal is critical for accurate analysis and interpretation of Electroencephalogram (EEG) signals. Traditional methods perform poorly with strong artifact-EEG correlations or single-channel data. Recent advances in diffusion-based generative models have demonstrated strong potential for EEG denoising, notably improving fine-grained noise suppression and reducing over-smoothing. However, existing methods face two main limitations: lack of temporal modeling limits interpretability and the use of single-artifact training paradigms ignore inter-artifact differences. To address these issues, we propose D4PM, a dual-branch driven denoising diffusion probabilistic model that unifies multi-type artifact removal. We introduce a dual-branch conditional diffusion architecture to implicitly model the data distribution of clean EEG and artifacts. A joint posterior sampling strategy is further designed to collaboratively integrate complementary priors for high-fidelity EEG reconstruction. Extensive experiments on two public datasets show that D4PM delivers superior denoising. It achieves new state-of-the-art performance in EOG artifact removal, outperforming all publicly available baselines. The code is available at https://github.com/flysnow1024/D4PM.
Unity is Power: Semi-Asynchronous Collaborative Training of Large-Scale Models with Structured Pruning in Resource-Limited Clients
Oct 11, 2024



In this work, we study to release the potential of massive heterogeneous weak computing power to collaboratively train large-scale models on dispersed datasets. In order to improve both efficiency and accuracy in resource-adaptive collaborative learning, we take the first step to consider the \textit{unstructured pruning}, \textit{varying submodel architectures}, \textit{knowledge loss}, and \textit{straggler} challenges simultaneously. We propose a novel semi-asynchronous collaborative training framework, namely ${Co\text{-}S}^2{P}$, with data distribution-aware structured pruning and cross-block knowledge transfer mechanism to address the above concerns. Furthermore, we provide theoretical proof that ${Co\text{-}S}^2{P}$ can achieve asymptotic optimal convergence rate of $O(1/\sqrt{N^*EQ})$. Finally, we conduct extensive experiments on a real-world hardware testbed, in which 16 heterogeneous Jetson devices can be united to train large-scale models with parameters up to 0.11 billion. The experimental results demonstrate that $Co\text{-}S^2P$ improves accuracy by up to 8.8\% and resource utilization by up to 1.2$\times$ compared to state-of-the-art methods, while reducing memory consumption by approximately 22\% and training time by about 24\% on all resource-limited devices.
Salient Bundle Adjustment for Visual SLAM
Dec 22, 2020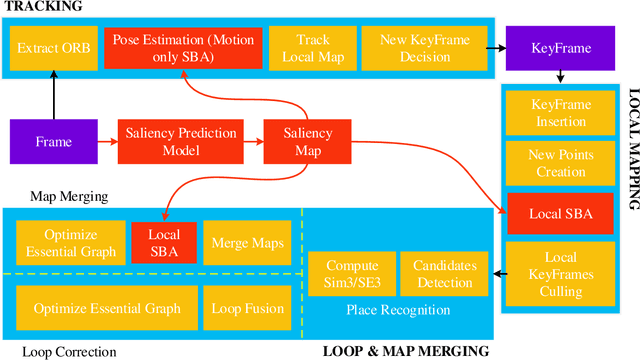

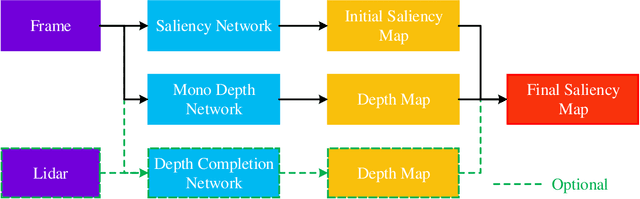

Recently, the philosophy of visual saliency and attention has started to gain popularity in the robotics community. Therefore, this paper aims to mimic this mechanism in SLAM framework by using saliency prediction model. Comparing with traditional SLAM that treated all feature points as equal important in optimization process, we think that the salient feature points should play more important role in optimization process. Therefore, we proposed a saliency model to predict the saliency map, which can capture both scene semantic and geometric information. Then, we proposed Salient Bundle Adjustment by using the value of saliency map as the weight of the feature points in traditional Bundle Adjustment approach. Exhaustive experiments conducted with the state-of-the-art algorithm in KITTI and EuRoc datasets show that our proposed algorithm outperforms existing algorithms in both indoor and outdoor environments. Finally, we will make our saliency dataset and relevant source code open-source for enabling future research.