 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Chebyshev Polynomial Neural Operator for Parametric Partial Differential Equations
Feb 02, 2026Neural operators have emerged as powerful deep learning frameworks for approximating solution operators of parameterized partial differential equations (PDE). However, current methods predominantly rely on multilayer perceptrons (MLPs) for mapping inputs to solutions, which impairs training robustness in physics-informed settings due to inherent spectral biases and fixed activation functions. To overcome the architectural limitations, we introduce the Physics-Informed Chebyshev Polynomial Neural Operator (CPNO), a novel mesh-free framework that leverages a basis transformation to replace unstable monomial expansions with the numerically stable Chebyshev spectral basis. By integrating parameter dependent modulation mechanism to main net, CPNO constructs PDE solutions in a near-optimal functional space, decoupling the model from MLP-specific constraints and enhancing multi-scale representation. Theoretical analysis demonstrates the Chebyshev basis's near-minimax uniform approximation properties and superior conditioning, with Lebesgue constants growing logarithmically with degree, thereby mitigating spectral bias and ensuring stable gradient flow during optimization. Numerical experiments on benchmark parameterized PDEs show that CPNO achieves superior accuracy, faster convergence, and enhanced robustness to hyperparameters. The experiment of transonic airfoil flow has demonstrated the capability of CPNO in characterizing complex geometric problems.
LLM Jailbreak Detection for (Almost) Free!
Sep 18, 2025



Large language models (LLMs) enhance security through alignment when widely used, but remain susceptible to jailbreak attacks capable of producing inappropriate content. Jailbreak detection methods show promise in mitigating jailbreak attacks through the assistance of other models or multiple model inferences. However, existing methods entail significant computational costs. In this paper, we first present a finding that the difference in output distributions between jailbreak and benign prompts can be employed for detecting jailbreak prompts. Based on this finding, we propose a Free Jailbreak Detection (FJD) which prepends an affirmative instruction to the input and scales the logits by temperature to further distinguish between jailbreak and benign prompts through the confidence of the first token. Furthermore, we enhance the detection performance of FJD through the integration of virtual instruction learning. Extensive experiments on aligned LLMs show that our FJD can effectively detect jailbreak prompts with almost no additional computational costs during LLM inference.
CCFExp: Facial Image Synthesis with Cycle Cross-Fusion Diffusion Model for Facial Paralysis Individuals
Sep 11, 2024



Facial paralysis is a debilitating condition that affects the movement of facial muscles, leading to a significant loss of facial expressions. Currently, the diagnosis of facial paralysis remains a challenging task, often relying heavily on the subjective judgment and experience of clinicians, which can introduce variability and uncertainty in the assessment process. One promising application in real-life situations is the automatic estimation of facial paralysis. However, the scarcity of facial paralysis datasets limits the development of robust machine learning models for automated diagnosis and therapeutic interventions. To this end, this study aims to synthesize a high-quality facial paralysis dataset to address this gap, enabling more accurate and efficient algorithm training. Specifically, a novel Cycle Cross-Fusion Expression Generative Model (CCFExp) based on the diffusion model is proposed to combine different features of facial information and enhance the visual details of facial appearance and texture in facial regions, thus creating synthetic facial images that accurately represent various degrees and types of facial paralysis. We have qualitatively and quantitatively evaluated the proposed method on the commonly used public clinical datasets of facial paralysis to demonstrate its effectiveness. Experimental results indicate that the proposed method surpasses state-of-the-art methods, generating more realistic facial images and maintaining identity consistency.
A Neural Column Generation Approach to the Vehicle Routing Problem with Two-Dimensional Loading and Last-In-First-Out Constraints
Jun 18, 2024



The vehicle routing problem with two-dimensional loading constraints (2L-CVRP) and the last-in-first-out (LIFO) rule presents significant practical and algorithmic challenges. While numerous heuristic approaches have been proposed to address its complexity, stemming from two NP-hard problems: the vehicle routing problem (VRP) and the two-dimensional bin packing problem (2D-BPP), less attention has been paid to developing exact algorithms. Bridging this gap, this article presents an exact algorithm that integrates advanced machine learning techniques, specifically a novel combination of attention and recurrence mechanisms. This integration accelerates the state-of-the-art exact algorithm by a median of 29.79% across various problem instances. Moreover, the proposed algorithm successfully resolves an open instance in the standard test-bed, demonstrating significant improvements brought about by the incorporation of machine learning models. Code is available at https://github.com/xyfffff/NCG-for-2L-CVRP.
Position: Rethinking Post-Hoc Search-Based Neural Approaches for Solving Large-Scale Traveling Salesman Problems
Jun 02, 2024



Recent advancements in solving large-scale traveling salesman problems (TSP) utilize the heatmap-guided Monte Carlo tree search (MCTS) paradigm, where machine learning (ML) models generate heatmaps, indicating the probability distribution of each edge being part of the optimal solution, to guide MCTS in solution finding. However, our theoretical and experimental analysis raises doubts about the effectiveness of ML-based heatmap generation. In support of this, we demonstrate that a simple baseline method can outperform complex ML approaches in heatmap generation. Furthermore, we question the practical value of the heatmap-guided MCTS paradigm. To substantiate this, our findings show its inferiority to the LKH-3 heuristic despite the paradigm's reliance on problem-specific, hand-crafted strategies. For the future, we suggest research directions focused on developing more theoretically sound heatmap generation methods and exploring autonomous, generalizable ML approaches for combinatorial problems. The code is available for review: https://github.com/xyfffff/rethink_mcts_for_tsp.
How ChatGPT is Solving Vulnerability Management Problem
Nov 11, 2023



Recently, ChatGPT has attracted great attention from the code analysis domain. Prior works show that ChatGPT has the capabilities of processing foundational code analysis tasks, such as abstract syntax tree generation, which indicates the potential of using ChatGPT to comprehend code syntax and static behaviors. However, it is unclear whether ChatGPT can complete more complicated real-world vulnerability management tasks, such as the prediction of security relevance and patch correctness, which require an all-encompassing understanding of various aspects, including code syntax, program semantics, and related manual comments. In this paper, we explore ChatGPT's capabilities on 6 tasks involving the complete vulnerability management process with a large-scale dataset containing 78,445 samples. For each task, we compare ChatGPT against SOTA approaches, investigate the impact of different prompts, and explore the difficulties. The results suggest promising potential in leveraging ChatGPT to assist vulnerability management. One notable example is ChatGPT's proficiency in tasks like generating titles for software bug reports. Furthermore, our findings reveal the difficulties encountered by ChatGPT and shed light on promising future directions. For instance, directly providing random demonstration examples in the prompt cannot consistently guarantee good performance in vulnerability management. By contrast, leveraging ChatGPT in a self-heuristic way -- extracting expertise from demonstration examples itself and integrating the extracted expertise in the prompt is a promising research direction. Besides, ChatGPT may misunderstand and misuse the information in the prompt. Consequently, effectively guiding ChatGPT to focus on helpful information rather than the irrelevant content is still an open problem.
Efficient Query-Based Attack against ML-Based Android Malware Detection under Zero Knowledge Setting
Sep 06, 2023The widespread adoption of the Android operating system has made malicious Android applications an appealing target for attackers. Machine learning-based (ML-based) Android malware detection (AMD) methods are crucial in addressing this problem; however, their vulnerability to adversarial examples raises concerns. Current attacks against ML-based AMD methods demonstrate remarkable performance but rely on strong assumptions that may not be realistic in real-world scenarios, e.g., the knowledge requirements about feature space, model parameters, and training dataset. To address this limitation, we introduce AdvDroidZero, an efficient query-based attack framework against ML-based AMD methods that operates under the zero knowledge setting. Our extensive evaluation shows that AdvDroidZero is effective against various mainstream ML-based AMD methods, in particular, state-of-the-art such methods and real-world antivirus solutions.
Correct-and-Memorize: Learning to Translate from Interactive Revisions
Aug 13, 2019
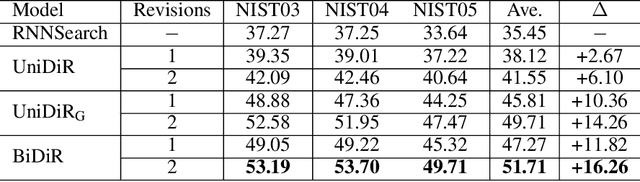
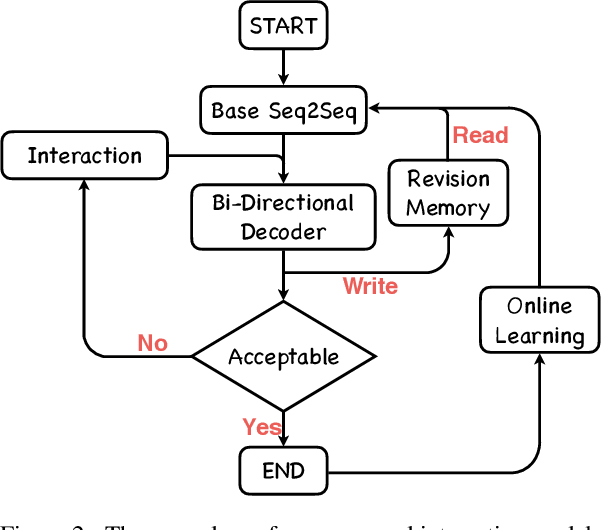
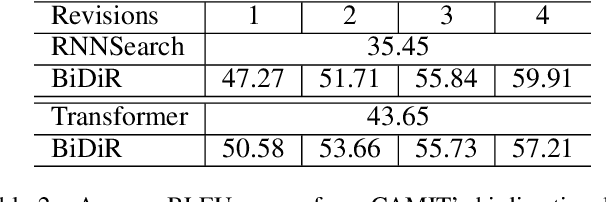
State-of-the-art machine translation models are still not on par with human translators. Previous work takes human interactions into the neural machine translation process to obtain improved results in target languages. However, not all model-translation errors are equal -- some are critical while others are minor. In the meanwhile, the same translation mistakes occur repeatedly in a similar context. To solve both issues, we propose CAMIT, a novel method for translating in an interactive environment. Our proposed method works with critical revision instructions, therefore allows human to correct arbitrary words in model-translated sentences. In addition, CAMIT learns from and softly memorizes revision actions based on the context, alleviating the issue of repeating mistakes. Experiments in both ideal and real interactive translation settings demonstrate that our proposed \method enhances machine translation results significantly while requires fewer revision instructions from human compared to previous methods.