 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-Aware Self-Training for Unsupervised Domain Adaptation on Regressing 6D Object Pose
May 18, 2023



Domain gap between synthetic and real data in visual regression (\eg 6D pose estimation) is bridged in this paper via global feature alignment and local refinement on the coarse classification of discretized anchor classes in target space, which imposes a piece-wise target manifold regularization into domain-invariant representation learning. Specifically, our method incorporates an explicit self-supervised manifold regularization, revealing consistent cumulative target dependency across domains, to a self-training scheme (\eg the popular Self-Paced Self-Training) to encourage more discriminative transferable representations of regression tasks. Moreover, learning unified implicit neural functions to estimate relative direction and distance of targets to their nearest class bins aims to refine target classification predictions, which can gain robust performance against inconsistent feature scaling sensitive to UDA regressors. Experiment results on three public benchmarks of the challenging 6D pose estimation task can verify the effectiveness of our method, consistently achieving superior performance to the state-of-the-art for UDA on 6D pose estimation.
Online Statistical Inference for Contextual Bandits via Stochastic Gradient Descent
Dec 30, 2022



With the fast development of big data, it has been easier than before to learn the optimal decision rule by updating the decision rule recursively and making online decisions. We study the online statistical inference of model parameters in a contextual bandit framework of sequential decision-making. We propose a general framework for online and adaptive data collection environment that can update decision rules via weighted stochastic gradient descent. We allow different weighting schemes of the stochastic gradient and establish the asymptotic normality of the parameter estimator. Our proposed estimator significantly improves the asymptotic efficiency over the previous averaged SGD approach via inverse probability weights. We also conduct an optimality analysis on the weights in a linear regression setting. We provide a Bahadur representation of the proposed estimator and show that the remainder term in the Bahadur representation entails a slower convergence rate compared to classical SGD due to the adaptive data collection.
Online Statistical Inference for Matrix Contextual Bandit
Dec 21, 2022Contextual bandit has been widely used for sequential decision-making based on the current contextual information and historical feedback data. In modern applications, such context format can be rich and can often be formulated as a matrix. Moreover, while existing bandit algorithms mainly focused on reward-maximization, less attention has been paid to the statistical inference. To fill in these gaps, in this work we consider a matrix contextual bandit framework where the true model parameter is a low-rank matrix, and propose a fully online procedure to simultaneously make sequential decision-making and conduct statistical inference. The low-rank structure of the model parameter and the adaptivity nature of the data collection process makes this difficult: standard low-rank estimators are not fully online and are biased, while existing inference approaches in bandit algorithms fail to account for the low-rankness and are also biased. To address these, we introduce a new online doubly-debiasing inference procedure to simultaneously handle both sources of bias. In theory, we establish the asymptotic normality of the proposed online doubly-debiased estimator and prove the validity of the constructed confidence interval. Our inference results are built upon a newly developed low-rank stochastic gradient descent estimator and its non-asymptotic convergence result, which is also of independent interest.
Distributed Estimation and Inference for Semi-parametric Binary Response Models
Oct 15, 2022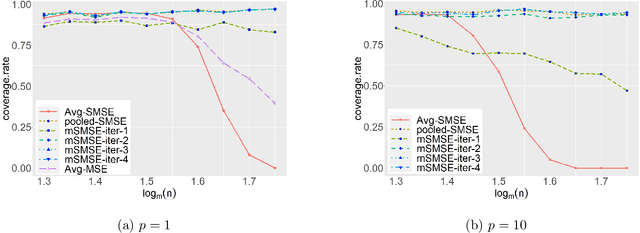
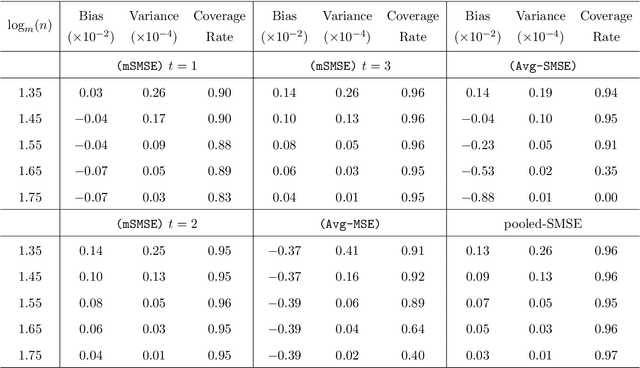
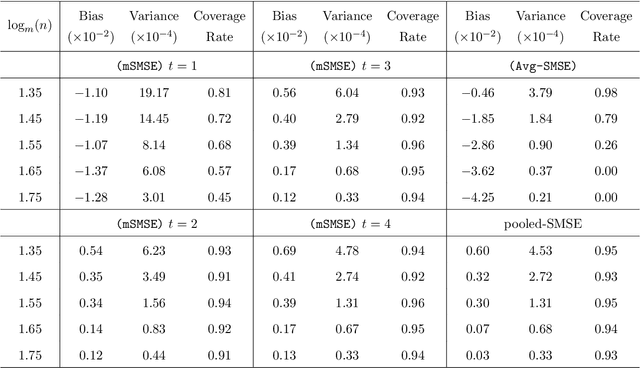
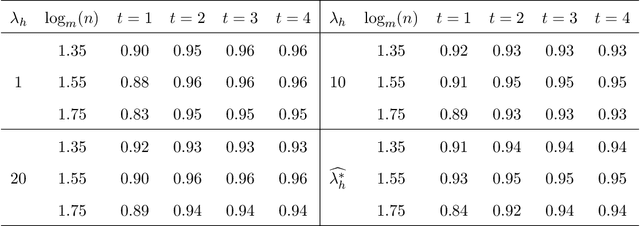
The development of modern technology has enabled data collection of unprecedented size, which poses new challenges to many statistical estimation and inference problems. This paper studies the maximum score estimator of a semi-parametric binary choice model under a distributed computing environment without pre-specifying the noise distribution. An intuitive divide-and-conquer estimator is computationally expensive and restricted by a non-regular constraint on the number of machines, due to the highly non-smooth nature of the objective function. We propose (1) a one-shot divide-and-conquer estimator after smoothing the objective to relax the constraint, and (2) a multi-round estimator to completely remove the constraint via iterative smoothing. We specify an adaptive choice of kernel smoother with a sequentially shrinking bandwidth to achieve the superlinear improvement of the optimization error over the multiple iterations. The improved statistical accuracy per iteration is derived, and a quadratic convergence up to the optimal statistical error rate is established. We further provide two generalizations to handle the heterogeneity of datasets with covariate shift and high-dimensional problems where the parameter of interest is sparse.
Fast 3D Sparse Topological Skeleton Graph Generation for Mobile Robot Global Planning
Aug 08, 2022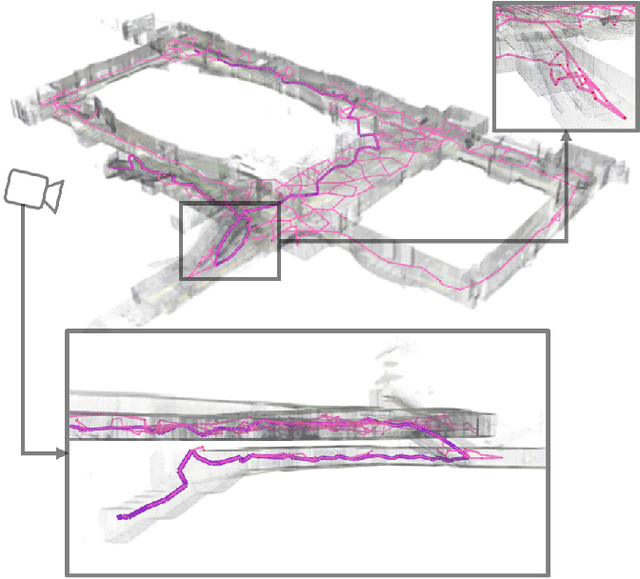
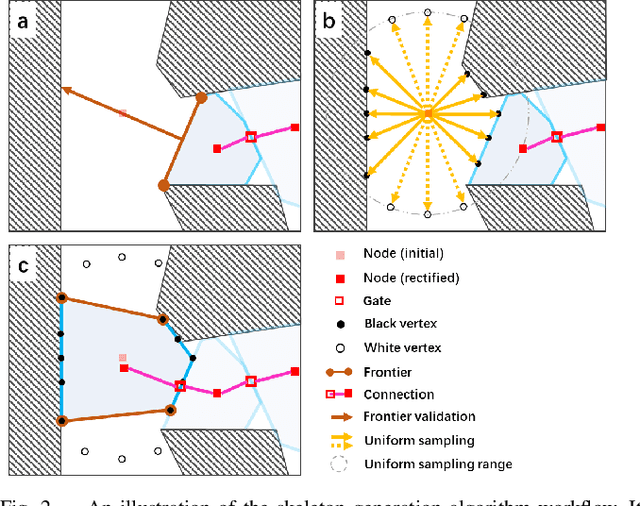
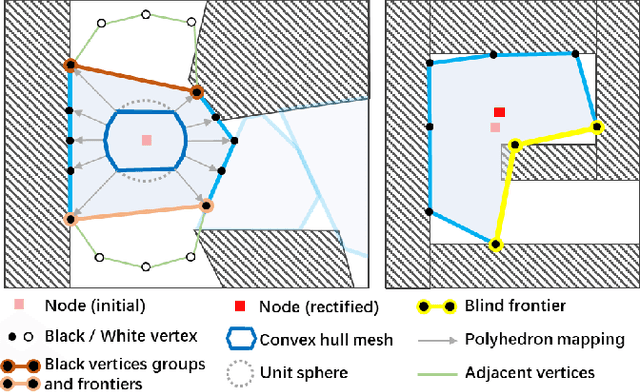
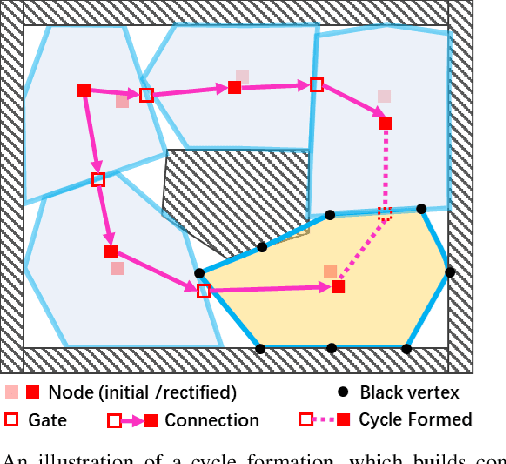
In recent years, mobile robots are becoming ambitious and deployed in large-scale scenarios. Serving as a high-level understanding of environments, a sparse skeleton graph is beneficial for more efficient global planning. Currently, existing solutions for skeleton graph generation suffer from several major limitations, including poor adaptiveness to different map representations, dependency on robot inspection trajectories and high computational overhead. In this paper, we propose an efficient and flexible algorithm generating a trajectory-independent 3D sparse topological skeleton graph capturing the spatial structure of the free space. In our method, an efficient ray sampling and validating mechanism are adopted to find distinctive free space regions, which contributes to skeleton graph vertices, with traversability between adjacent vertices as edges. A cycle formation scheme is also utilized to maintain skeleton graph compactness. Benchmark comparison with state-of-the-art works demonstrates that our approach generates sparse graphs in a substantially shorter time, giving high-quality global planning paths. Experiments conducted in real-world maps further validate the capability of our method in real-world scenarios. Our method will be made open source to benefit the community.
BiCo-Net: Regress Globally, Match Locally for Robust 6D Pose Estimation
May 07, 2022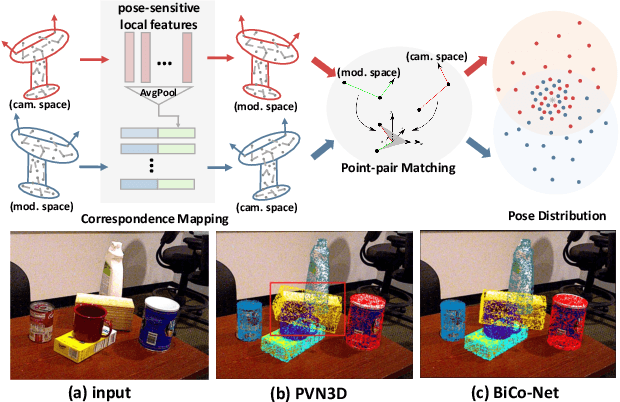
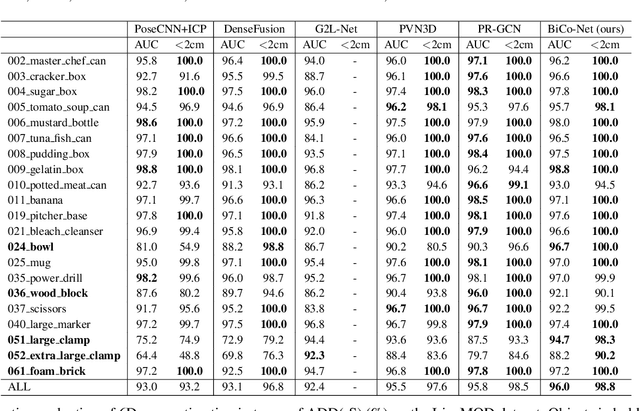
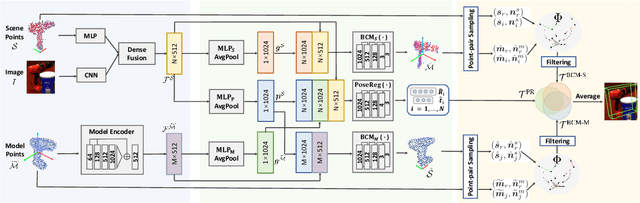

The challenges of learning a robust 6D pose function lie in 1) severe occlusion and 2) systematic noises in depth images. Inspired by the success of point-pair features, the goal of this paper is to recover the 6D pose of an object instance segmented from RGB-D images by locally matching pairs of oriented points between the model and camera space. To this end, we propose a novel Bi-directional Correspondence Mapping Network (BiCo-Net) to first generate point clouds guided by a typical pose regression, which can thus incorporate pose-sensitive information to optimize generation of local coordinates and their normal vectors. As pose predictions via geometric computation only rely on one single pair of local oriented points, our BiCo-Net can achieve robustness against sparse and occluded point clouds. An ensemble of redundant pose predictions from locally matching and direct pose regression further refines final pose output against noisy observations. Experimental results on three popularly benchmarking datasets can verify that our method can achieve state-of-the-art performance, especially for the more challenging severe occluded scenes. Source codes are available at https://github.com/Gorilla-Lab-SCUT/BiCo-Net.
Exploration with Global Consistency Using Real-Time Re-integration and Active Loop Closure
Apr 06, 2022
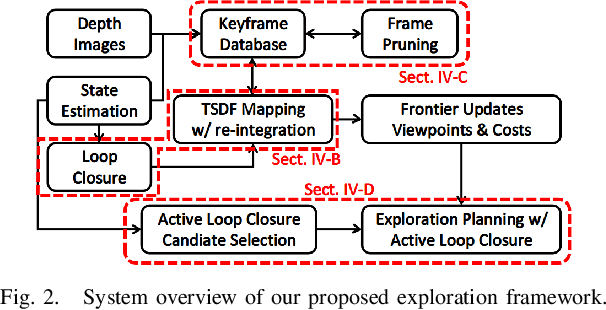
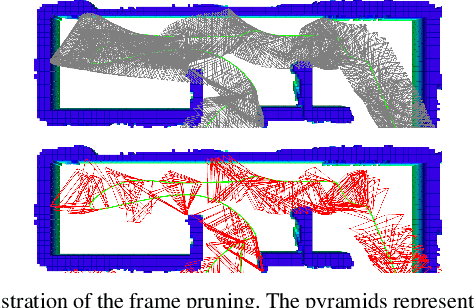

Despite recent progress of robotic exploration, most methods assume that drift-free localization is available, which is problematic in reality and causes severe distortion of the reconstructed map. In this work, we present a systematic exploration mapping and planning framework that deals with drifted localization, allowing efficient and globally consistent reconstruction. A real-time re-integration-based mapping approach along with a frame pruning mechanism is proposed, which rectifies map distortion effectively when drifted localization is corrected upon detecting loop-closure. Besides, an exploration planning method considering historical viewpoints is presented to enable active loop closing, which promotes a higher opportunity to correct localization errors and further improves the mapping quality. We evaluate both the mapping and planning methods as well as the entire system comprehensively in simulation and real-world experiments, showing their effectiveness in practice. The implementation of the proposed method will be made open-source for the benefit of the robotics community.
Mix-up Self-Supervised Learning for Contrast-agnostic Applications
Apr 02, 2022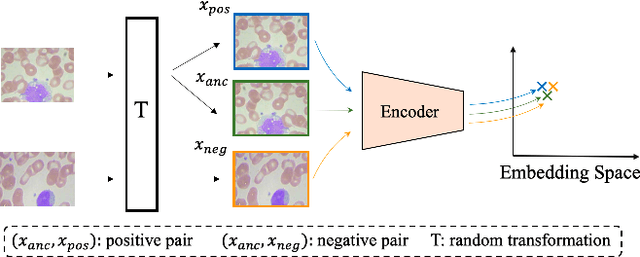
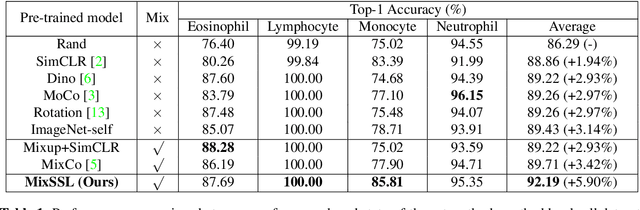
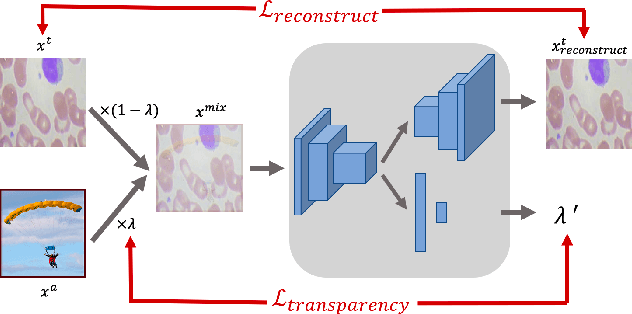
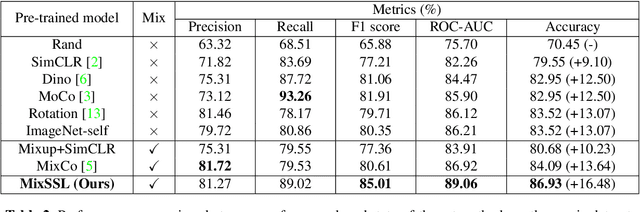
Contrastive self-supervised learning has attracted significant research attention recently. It learns effective visual representations from unlabeled data by embedding augmented views of the same image close to each other while pushing away embeddings of different images. Despite its great success on ImageNet classification, COCO object detection, etc., its performance degrades on contrast-agnostic applications, e.g., medical image classification, where all images are visually similar to each other. This creates difficulties in optimizing the embedding space as the distance between images is rather small. To solve this issue, we present the first mix-up self-supervised learning framework for contrast-agnostic applications. We address the low variance across images based on cross-domain mix-up and build the pretext task based on two synergistic objectives: image reconstruction and transparency prediction. Experimental results on two benchmark datasets validate the effectiveness of our method, where an improvement of 2.5% ~ 7.4% in top-1 accuracy was obtained compared to existing self-supervised learning methods.
Neither Fast Nor Slow: How to Fly Through Narrow Tunnels
Jan 10, 2022
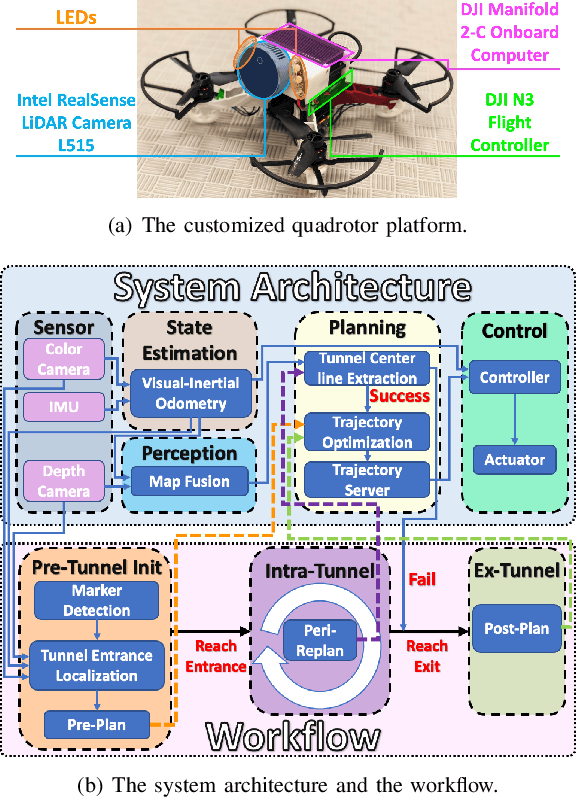

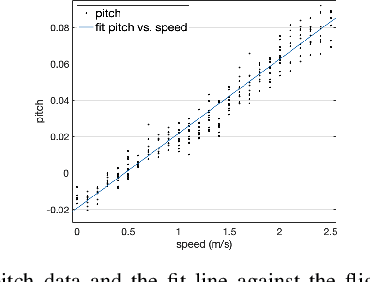
Nowadays, multirotors are playing important roles in abundant types of missions. During these missions, entering confined and narrow tunnels that are barely accessible to humans is desirable yet extremely challenging for multirotors. The restricted space and significant ego airflow disturbances induce control issues at both fast and slow flight speeds, meanwhile bringing about problems in state estimation and perception. Thus, a smooth trajectory at a proper speed is necessary for safe tunnel flights. To address these challenges, in this letter, a complete autonomous aerial system that can fly smoothly through tunnels with dimensions narrow to 0.6 m is presented. The system contains a motion planner that generates smooth mini-jerk trajectories along the tunnel center lines, which are extracted according to the map and Euclidean Distance Field (EDF), and its practical speed range is obtained through computational fluid dynamics (CFD) and flight data analyses. Extensive flight experiments on the quadrotor are conducted inside multiple narrow tunnels to validate the planning framework as well as the robustness of the whole system.
Unsupervised data augmentation for object detection
Apr 30, 2021
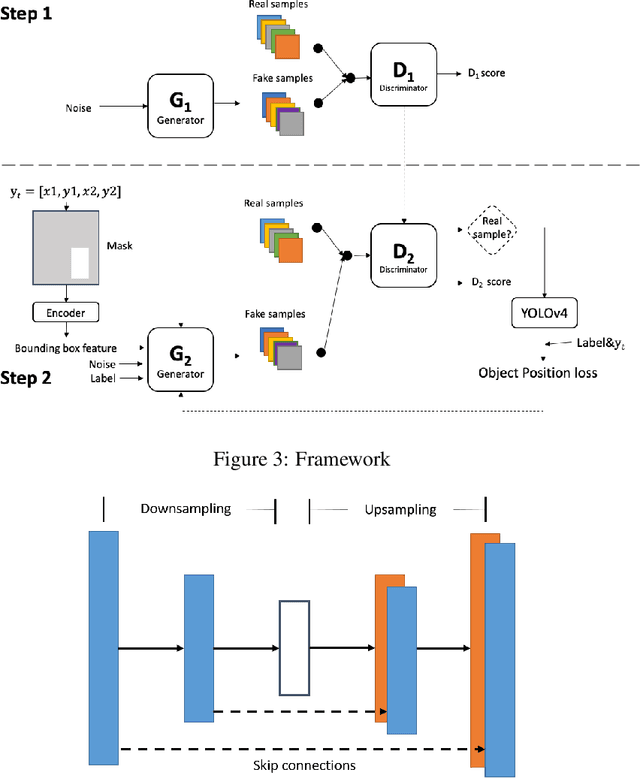


Data augmentation has always been an effective way to overcome overfitting issue when the dataset is small. There are already lots of augmentation operations such as horizontal flip, random crop or even Mixup. However, unlike image classification task, we cannot simply perform these operations for object detection task because of the lack of labeled bounding boxes information for corresponding generated images. To address this challenge, we propose a framework making use of Generative Adversarial Networks(GAN) to perform unsupervised data augmentation. To be specific, based on the recently supreme performance of YOLOv4, we propose a two-step pipeline that enables us to generate an image where the object lies in a certain position. In this way, we can accomplish the goal that generating an image with bounding box label.