 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta reinforcement learning as task inference
May 15, 2019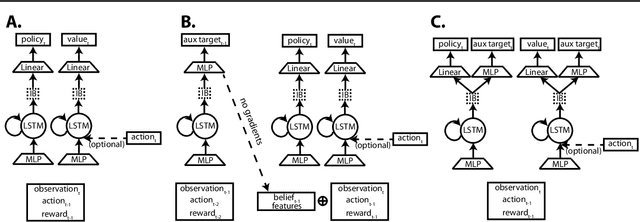
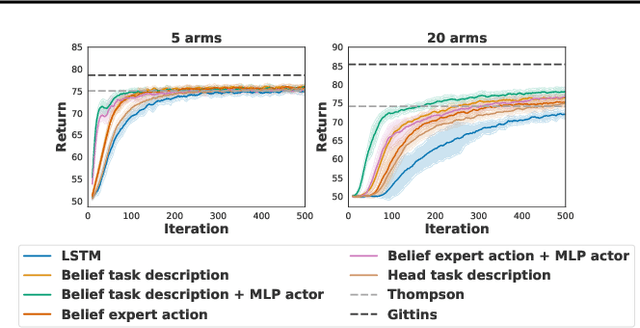
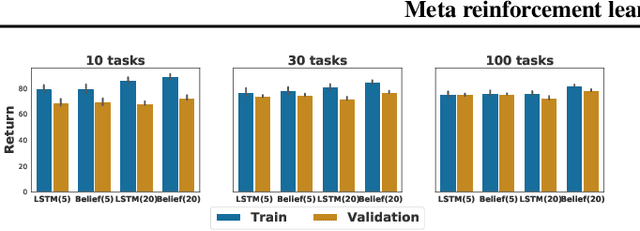

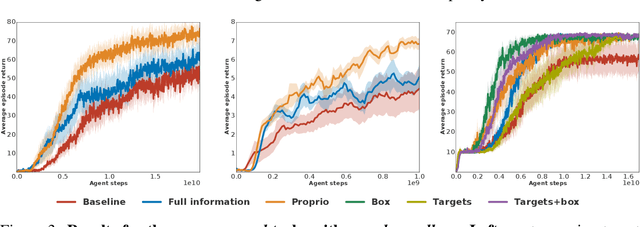
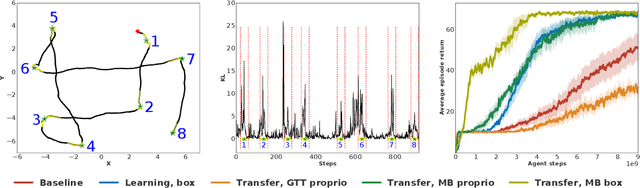
Humans achieve efficient learning by relying on prior knowledge about the structure of naturally occurring tasks. There has been considerable interest in designing reinforcement learning algorithms with similar properties. This includes several proposals to learn the learning algorithm itself, an idea also referred to as meta learning. One formal interpretation of this idea is in terms of a partially observable multi-task reinforcement learning problem in which information about the task is hidden from the agent. Although agents that solve partially observable environments can be trained from rewards alone, shaping an agent's memory with additional supervision has been shown to boost learning efficiency. It is thus natural to ask what kind of supervision, if any, facilitates meta-learning. Here we explore several choices and develop an architecture that separates learning of the belief about the unknown task from learning of the policy, and that can be used effectively with privileged information about the task during training. We show that this approach can be very effective at solving standard meta-RL environments, as well as a complex continuous control environment in which a simulated robot has to execute various movement sequences.
Meta-learning of Sequential Strategies
May 08, 2019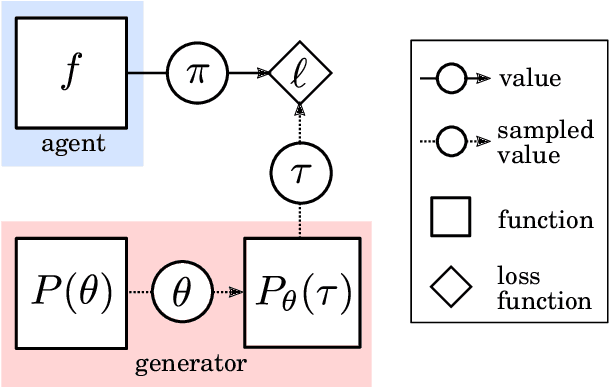
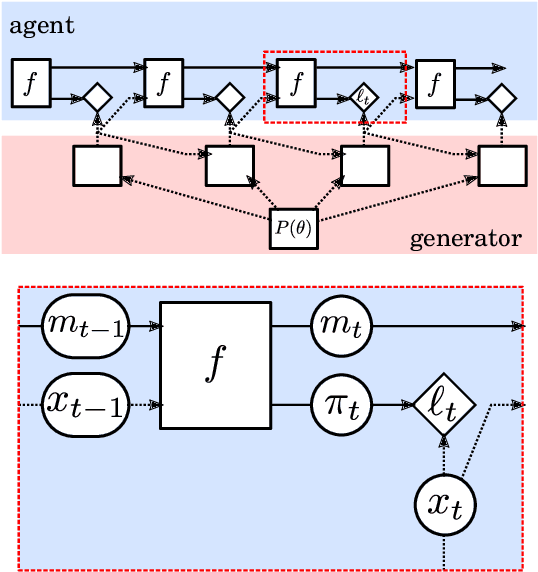
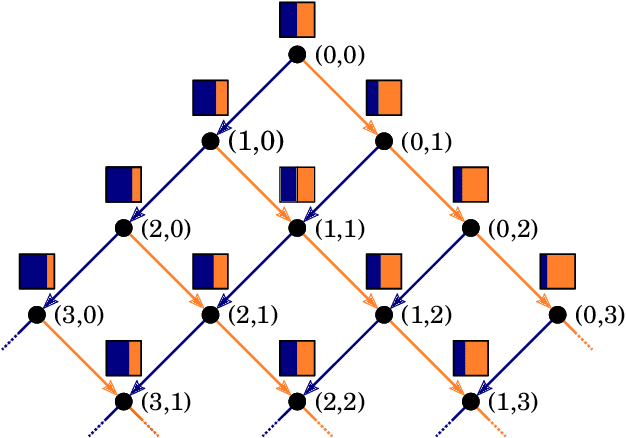
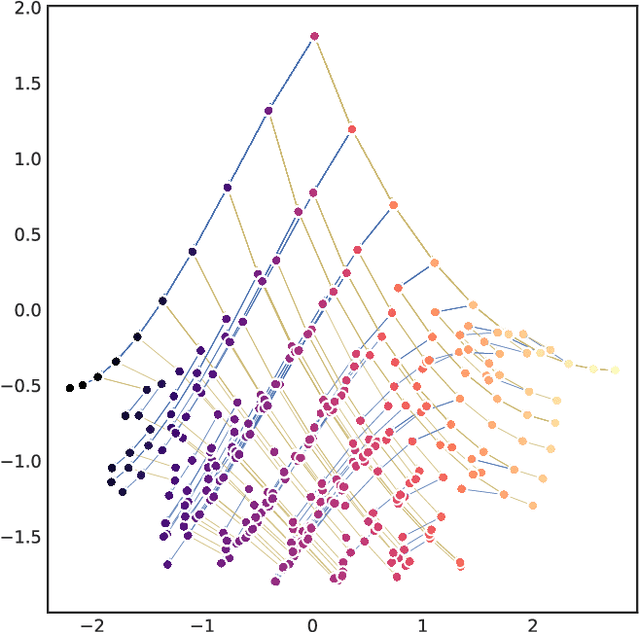
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Information asymmetry in KL-regularized RL
May 03, 2019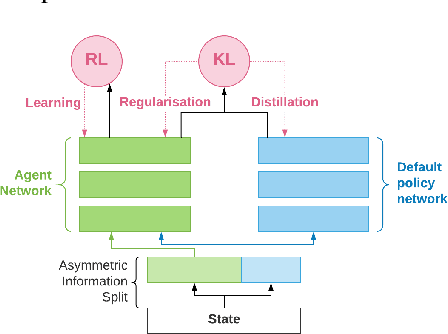

Many real world tasks exhibit rich structure that is repeated across different parts of the state space or in time. In this work we study the possibility of leveraging such repeated structure to speed up and regularize learning. We start from the KL regularized expected reward objective which introduces an additional component, a default policy. Instead of relying on a fixed default policy, we learn it from data. But crucially, we restrict the amount of information the default policy receives, forcing it to learn reusable behaviors that help the policy learn faster. We formalize this strategy and discuss connections to information bottleneck approaches and to the variational EM algorithm. We present empirical results in both discrete and continuous action domains and demonstrate that, for certain tasks, learning a default policy alongside the policy can significantly speed up and improve learning.
Augmented Neural ODEs
Apr 02, 2019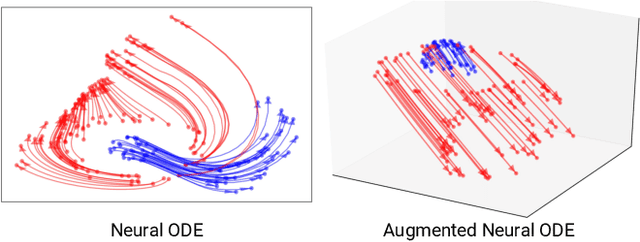
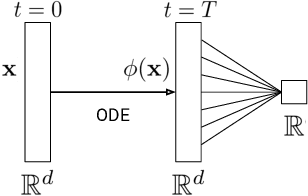
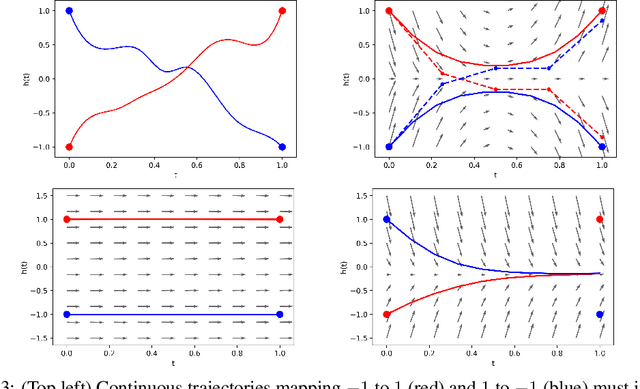
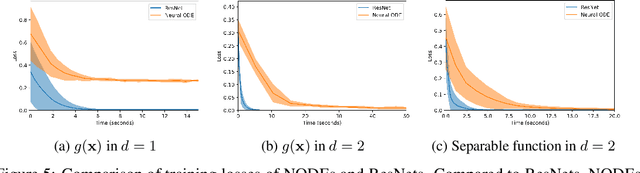
We show that Neural Ordinary Differential Equations (ODEs) learn representations that preserve the topology of the input space and prove that this implies the existence of functions Neural ODEs cannot represent. To address these limitations, we introduce Augmented Neural ODEs which, in addition to being more expressive models, are empirically more stable, generalize better and have a lower computational cost than Neural ODEs.
Meta-Learning surrogate models for sequential decision making
Mar 28, 2019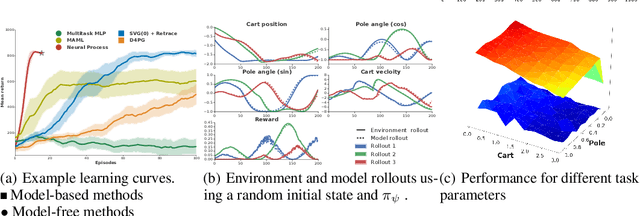

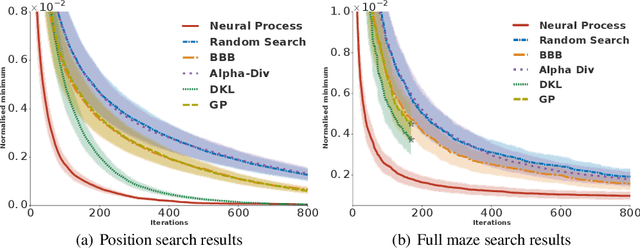
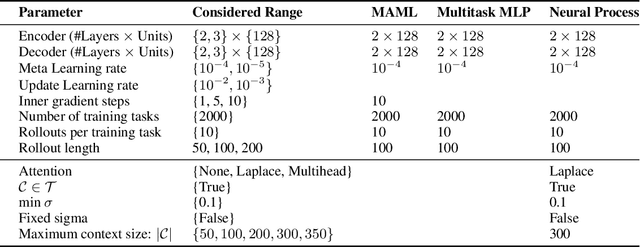
Meta-learning methods leverage past experience to learn data-driven inductive biases from related problems, increasing learning efficiency on new tasks. This ability renders them particularly suitable for sequential decision making with limited experience. Within this problem family, we argue for the use of such approaches in the study of model-based approaches to Bayesian Optimisation, contextual bandits and Reinforcement Learning. We approach the problem by learning distributions over functions using Neural Processes (NPs), a recently introduced probabilistic meta-learning method. This allows the treatment of model uncertainty to tackle the exploration/exploitation dilemma. We show that NPs are suitable for sequential decision making on a diverse set of domains, including adversarial task search, recommender systems and model-based reinforcement learning.
Exploiting Hierarchy for Learning and Transfer in KL-regularized RL
Mar 18, 2019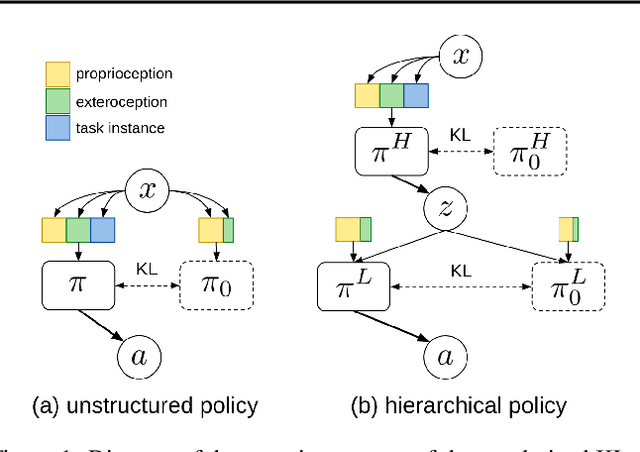
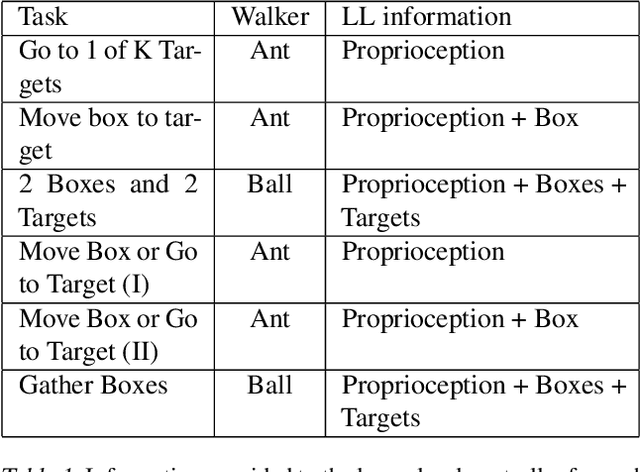

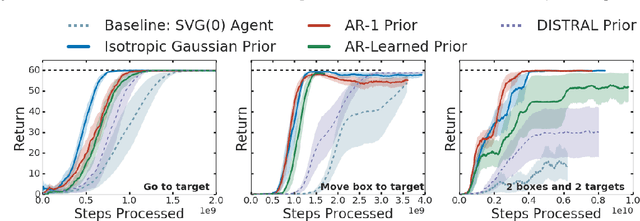
As reinforcement learning agents are tasked with solving more challenging and diverse tasks, the ability to incorporate prior knowledge into the learning system and to exploit reusable structure in solution space is likely to become increasingly important. The KL-regularized expected reward objective constitutes one possible tool to this end. It introduces an additional component, a default or prior behavior, which can be learned alongside the policy and as such partially transforms the reinforcement learning problem into one of behavior modelling. In this work we consider the implications of this framework in cases where both the policy and default behavior are augmented with latent variables. We discuss how the resulting hierarchical structures can be used to implement different inductive biases and how their modularity can benefit transfer. Empirically we find that they can lead to faster learning and transfer on a range of continuous control tasks.
Variational Estimators for Bayesian Optimal Experimental Design
Mar 13, 2019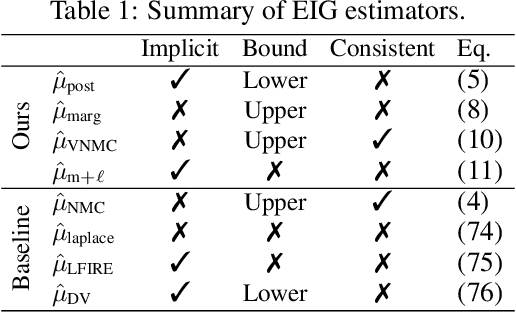
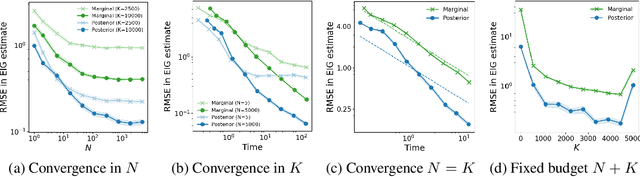
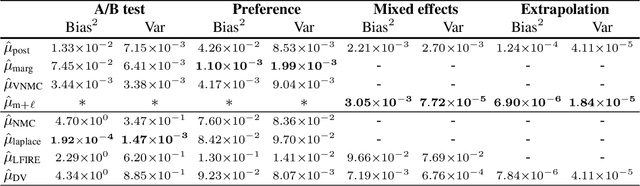
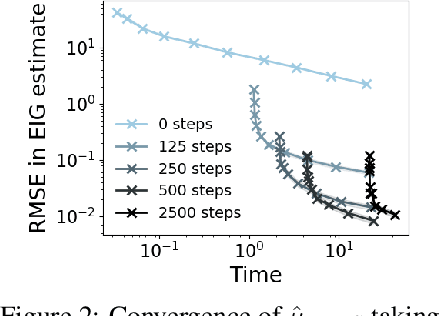
Bayesian optimal experimental design (BOED) is a principled framework for making efficient use of limited experimental resources. Unfortunately, its applicability is hampered by the difficulty of obtaining accurate estimates of the expected information gain (EIG) of an experiment. To address this, we introduce several classes of fast EIG estimators suited to the experiment design context by building on ideas from variational inference and mutual information estimation. We show theoretically and empirically that these estimators can provide significant gains in speed and accuracy over previous approaches. We demonstrate the practicality of our approach via a number of experiments, including an adaptive experiment with human participants.
Hybrid Models with Deep and Invertible Features
Feb 07, 2019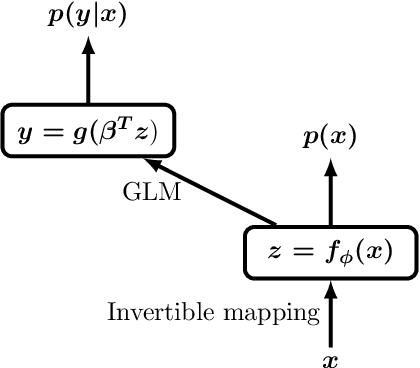
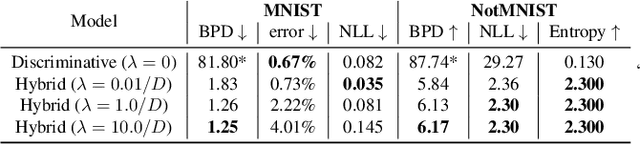
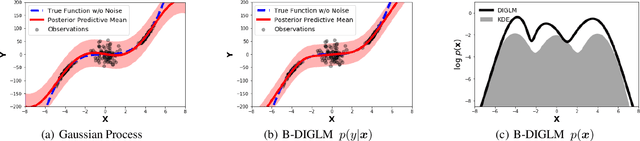
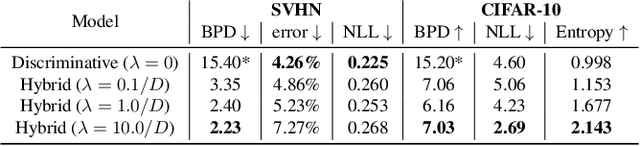
We propose a neural hybrid model consisting of a linear model defined on a set of features computed by a deep, invertible transformation (i.e. a normalizing flow). An attractive property of our model is that both p(features), the features' density, and p(targets | features), the predictive distribution, can be computed exactly in a single feed-forward pass. We show that our hybrid model, despite the invertibility constraints, achieves similar accuracy to purely predictive models. Yet the generative component remains a good model of the input features despite the hybrid optimization objective. This offers additional capabilities such as detection of out-of-distribution inputs and enabling semi-supervised learning. The availability of the exact joint density p(targets, features) also allows us to compute many quantities readily, making our hybrid model a useful building block for downstream applications of probabilistic deep learning.
Functional Regularisation for Continual Learning using Gaussian Processes
Jan 31, 2019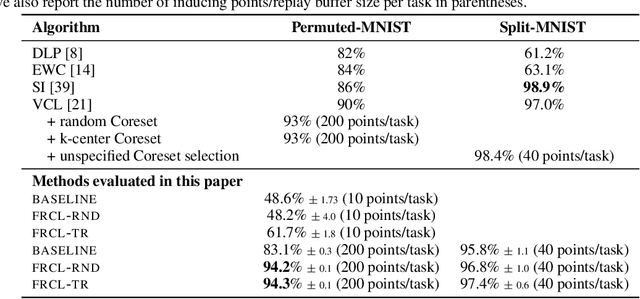
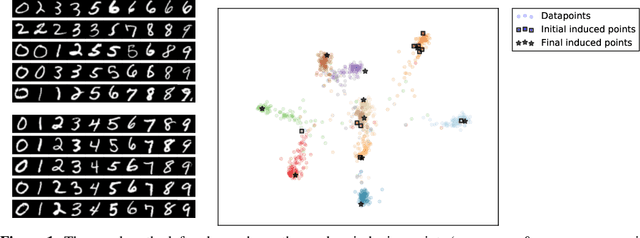
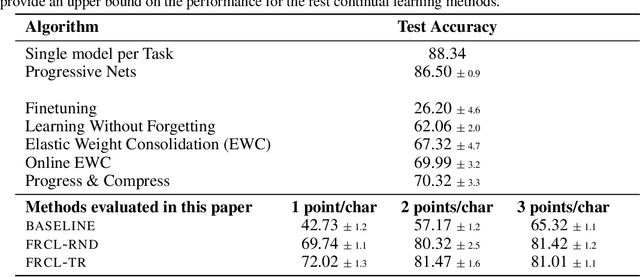
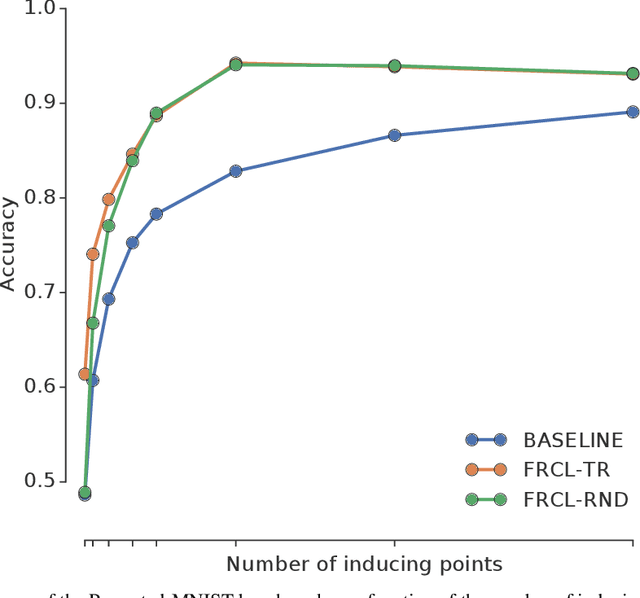
We introduce a novel approach for supervised continual learning based on approximate Bayesian inference over function space rather than the parameters of a deep neural network. We use a Gaussian process obtained by treating the weights of the last layer of a neural network as random and Gaussian distributed. Functional regularisation for continual learning naturally arises by applying the variational sparse GP inference method in a sequential fashion as new tasks are encountered. At each step of the process, a summary is constructed for the current task that consists of (i) inducing inputs and (ii) a posterior distribution over the function values at these inputs. This summary then regularises learning of future tasks, through Kullback-Leibler regularisation terms that appear in the variational lower bound, and reduces the effects of catastrophic forgetting. We fully develop the theory of the method and we demonstrate its effectiveness in classification datasets, such as Split-MNIST, Permuted-MNIST and Omniglot.
Probabilistic symmetry and invariant neural networks
Jan 18, 2019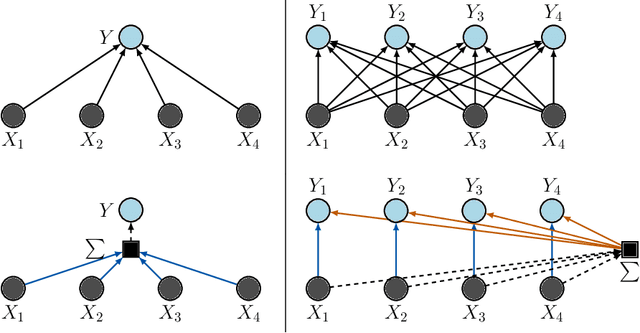
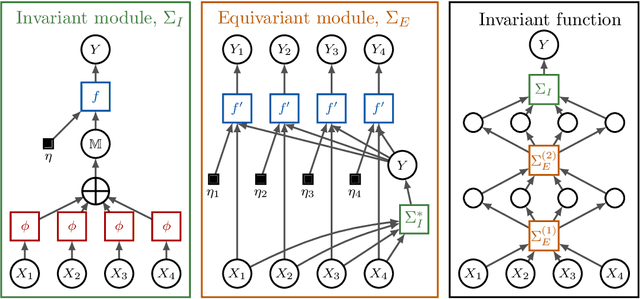
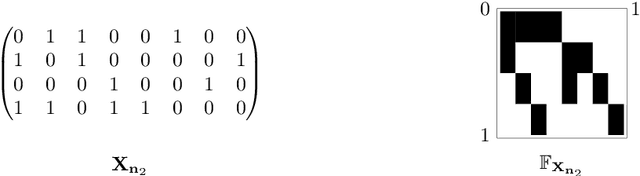
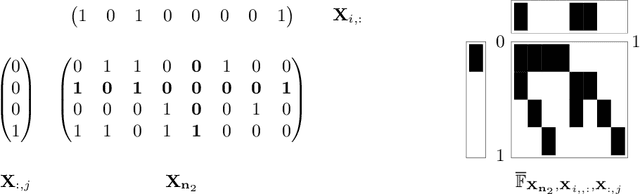
In an effort to improve the performance of deep neural networks in data-scarce, non-i.i.d., or unsupervised settings, much recent research has been devoted to encoding invariance under symmetry transformations into neural network architectures. We treat the neural network input and output as random variables, and consider group invariance from the perspective of probabilistic symmetry. Drawing on tools from probability and statistics, we establish a link between functional and probabilistic symmetry, and obtain generative functional representations of joint and conditional probability distributions that are invariant or equivariant under the action of a compact group. Those representations completely characterize the structure of neural networks that can be used to model such distributions and yield a general program for constructing invariant stochastic or deterministic neural networks. We develop the details of the general program for exchangeable sequences and arrays, recovering a number of recent examples as special cases.