 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquiPocket: an E(3)-Equivariant Geometric Graph Neural Network for Ligand Binding Site Prediction
Feb 23, 2023Predicting the binding sites of the target proteins plays a fundamental role in drug discovery. Most existing deep-learning methods consider a protein as a 3D image by spatially clustering its atoms into voxels and then feed the voxelized protein into a 3D CNN for prediction. However, the CNN-based methods encounter several critical issues: 1) defective in representing irregular protein structures; 2) sensitive to rotations; 3) insufficient to characterize the protein surface; 4) unaware of data distribution shift. To address the above issues, this work proposes EquiPocket, an E(3)-equivariant Graph Neural Network (GNN) for binding site prediction. In particular, EquiPocket consists of three modules: the first one to extract local geometric information for each surface atom, the second one to model both the chemical and spatial structure of the protein, and the last one to capture the geometry of the surface via equivariant message passing over the surface atoms. We further propose a dense attention output layer to better alleviate the data distribution shift effect incurred by the variable protein size. Extensive experiments on several representative benchmarks demonstrate the superiority of our framework to the state-of-the-art methods.
Almost Sure Saddle Avoidance of Stochastic Gradient Methods without the Bounded Gradient Assumption
Feb 15, 2023We prove that various stochastic gradient descent methods, including the stochastic gradient descent (SGD), stochastic heavy-ball (SHB), and stochastic Nesterov's accelerated gradient (SNAG) methods, almost surely avoid any strict saddle manifold. To the best of our knowledge, this is the first time such results are obtained for SHB and SNAG methods. Moreover, our analysis expands upon previous studies on SGD by removing the need for bounded gradients of the objective function and uniformly bounded noise. Instead, we introduce a more practical local boundedness assumption for the noisy gradient, which is naturally satisfied in empirical risk minimization problems typically seen in training of neural networks.
PhysDiff: Physics-Guided Human Motion Diffusion Model
Dec 09, 2022Denoising diffusion models hold great promise for generating diverse and realistic human motions. However, existing motion diffusion models largely disregard the laws of physics in the diffusion process and often generate physically-implausible motions with pronounced artifacts such as floating, foot sliding, and ground penetration. This seriously impacts the quality of generated motions and limits their real-world application. To address this issue, we present a novel physics-guided motion diffusion model (PhysDiff), which incorporates physical constraints into the diffusion process. Specifically, we propose a physics-based motion projection module that uses motion imitation in a physics simulator to project the denoised motion of a diffusion step to a physically-plausible motion. The projected motion is further used in the next diffusion step to guide the denoising diffusion process. Intuitively, the use of physics in our model iteratively pulls the motion toward a physically-plausible space. Experiments on large-scale human motion datasets show that our approach achieves state-of-the-art motion quality and improves physical plausibility drastically (>78% for all datasets).
A Node-collaboration-informed Graph Convolutional Network for Precise Representation to Undirected Weighted Graphs
Nov 30, 2022An undirected weighted graph (UWG) is frequently adopted to describe the interactions among a solo set of nodes from real applications, such as the user contact frequency from a social network services system. A graph convolutional network (GCN) is widely adopted to perform representation learning to a UWG for subsequent pattern analysis tasks such as clustering or missing data estimation. However, existing GCNs mostly neglects the latent collaborative information hidden in its connected node pairs. To address this issue, this study proposes to model the node collaborations via a symmetric latent factor analysis model, and then regards it as a node-collaboration module for supplementing the collaboration loss in a GCN. Based on this idea, a Node-collaboration-informed Graph Convolutional Network (NGCN) is proposed with three-fold ideas: a) Learning latent collaborative information from the interaction of node pairs via a node-collaboration module; b) Building the residual connection and weighted representation propagation to obtain high representation capacity; and c) Implementing the model optimization in an end-to-end fashion to achieve precise representation to the target UWG. Empirical studies on UWGs emerging from real applications demonstrate that owing to its efficient incorporation of node-collaborations, the proposed NGCN significantly outperforms state-of-the-art GCNs in addressing the task of missing weight estimation. Meanwhile, its good scalability ensures its compatibility with more advanced GCN extensions, which will be further investigated in our future studies.
Prototype as Query for Few Shot Semantic Segmentation
Nov 27, 2022



Few-shot Semantic Segmentation (FSS) was proposed to segment unseen classes in a query image, referring to only a few annotated examples named support images. One of the characteristics of FSS is spatial inconsistency between query and support targets, e.g., texture or appearance. This greatly challenges the generalization ability of methods for FSS, which requires to effectively exploit the dependency of the query image and the support examples. Most existing methods abstracted support features into prototype vectors and implemented the interaction with query features using cosine similarity or feature concatenation. However, this simple interaction may not capture spatial details in query features. To alleviate this limitation, a few methods utilized all pixel-wise support information via computing the pixel-wise correlations between paired query and support features implemented with the attention mechanism of Transformer. These approaches suffer from heavy computation on the dot-product attention between all pixels of support and query features. In this paper, we propose a simple yet effective framework built upon Transformer termed as ProtoFormer to fully capture spatial details in query features. It views the abstracted prototype of the target class in support features as Query and the query features as Key and Value embeddings, which are input to the Transformer decoder. In this way, the spatial details can be better captured and the semantic features of target class in the query image can be focused. The output of the Transformer-based module can be viewed as semantic-aware dynamic kernels to filter out the segmentation mask from the enriched query features. Extensive experiments on PASCAL-$5^{i}$ and COCO-$20^{i}$ show that our ProtoFormer significantly advances the state-of-the-art methods.
1st Place Solutions for UG2+ Challenge 2022 ATMOSPHERIC TURBULENCE MITIGATION
Oct 30, 2022



In this technical report, we briefly introduce the solution of our team ''summer'' for Atomospheric Turbulence Mitigation in UG$^2$+ Challenge in CVPR 2022. In this task, we propose a unified end-to-end framework to reconstruct a high quality image from distorted frames, which is mainly consists of a Restormer-based image reconstruction module and a NIMA-based image quality assessment module. Our framework is efficient and generic, which is adapted to both hot-air image and text pattern. Moreover, we elaborately synthesize more than 10 thousands of images to simulate atmospheric turbulence. And these images improve the robustness of the model. Finally, we achieve the average accuracy of 98.53\% on the reconstruction result of the text patterns, ranking 1st on the final leaderboard.
PALT: Parameter-Lite Transfer of Language Models for Knowledge Graph Completion
Oct 25, 2022



This paper presents a parameter-lite transfer learning approach of pretrained language models (LM) for knowledge graph (KG) completion. Instead of finetuning, which modifies all LM parameters, we only tune a few new parameters while keeping the original LM parameters fixed. We establish this via reformulating KG completion as a "fill-in-the-blank" task, and introducing a parameter-lite encoder on top of the original LMs. We show that, by tuning far fewer parameters than finetuning, LMs transfer non-trivially to most tasks and reach competitiveness with prior state-of-the-art approaches. For instance, we outperform the fully finetuning approaches on a KG completion benchmark by tuning only 1% of the parameters. The code and datasets are available at \url{https://github.com/yuanyehome/PALT}.
Beta R-CNN: Looking into Pedestrian Detection from Another Perspective
Oct 23, 2022



Recently significant progress has been made in pedestrian detection, but it remains challenging to achieve high performance in occluded and crowded scenes. It could be attributed mostly to the widely used representation of pedestrians, i.e., 2D axis-aligned bounding box, which just describes the approximate location and size of the object. Bounding box models the object as a uniform distribution within the boundary, making pedestrians indistinguishable in occluded and crowded scenes due to much noise. To eliminate the problem, we propose a novel representation based on 2D beta distribution, named Beta Representation. It pictures a pedestrian by explicitly constructing the relationship between full-body and visible boxes, and emphasizes the center of visual mass by assigning different probability values to pixels. As a result, Beta Representation is much better for distinguishing highly-overlapped instances in crowded scenes with a new NMS strategy named BetaNMS. What's more, to fully exploit Beta Representation, a novel pipeline Beta R-CNN equipped with BetaHead and BetaMask is proposed, leading to high detection performance in occluded and crowded scenes.
Global Prototype Encoding for Incremental Video Highlights Detection
Sep 14, 2022

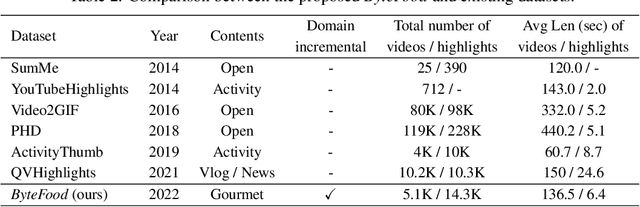
Video highlights detection has been long researched as a topic in computer vision tasks, digging the user-appealing clips out given unexposed raw video inputs. However, in most case, the mainstream methods in this line of research are built on the closed world assumption, where a fixed number of highlight categories is defined properly in advance and need all training data to be available at the same time, and as a result, leads to poor scalability with respect to both the highlight categories and the size of the dataset. To tackle the problem mentioned above, we propose a video highlights detector that is able to learn incrementally, namely \textbf{G}lobal \textbf{P}rototype \textbf{E}ncoding (GPE), capturing newly defined video highlights in the extended dataset via their corresponding prototypes. Alongside, we present a well annotated and costly dataset termed \emph{ByteFood}, including more than 5.1k gourmet videos belongs to four different domains which are \emph{cooking}, \emph{eating}, \emph{food material}, and \emph{presentation} respectively. To the best of our knowledge, this is the first time the incremental learning settings are introduced to video highlights detection, which in turn relieves the burden of training video inputs and promotes the scalability of conventional neural networks in proportion to both the size of the dataset and the quantity of domains. Moreover, the proposed GPE surpasses current incremental learning methods on \emph{ByteFood}, reporting an improvement of 1.57\% mAP at least. The code and dataset will be made available sooner.
A Nonlinear PID-Enhanced Adaptive Latent Factor Analysis Model
Aug 04, 2022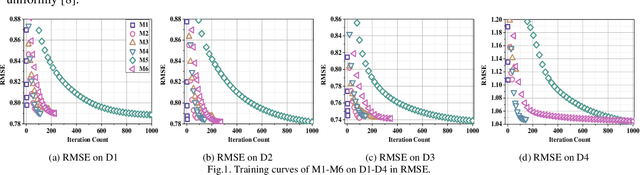
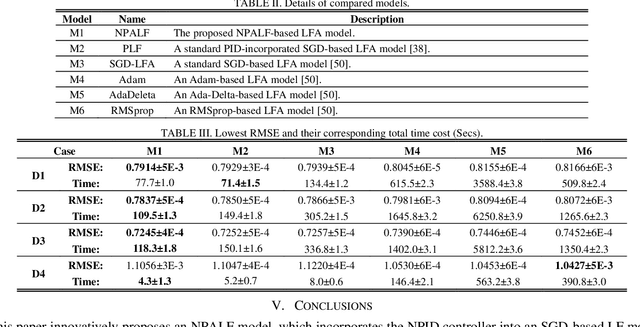
High-dimensional and incomplete (HDI) data holds tremendous interactive information in various industrial applications. A latent factor (LF) model is remarkably effective in extracting valuable information from HDI data with stochastic gradient decent (SGD) algorithm. However, an SGD-based LFA model suffers from slow convergence since it only considers the current learning error. To address this critical issue, this paper proposes a Nonlinear PID-enhanced Adaptive Latent Factor (NPALF) model with two-fold ideas: 1) rebuilding the learning error via considering the past learning errors following the principle of a nonlinear PID controller; b) implementing all parameters adaptation effectively following the principle of a particle swarm optimization (PSO) algorithm. Experience results on four representative HDI datasets indicate that compared with five state-of-the-art LFA models, the NPALF model achieves better convergence rate and prediction accuracy for missing data of an HDI data.