 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Rotational Odometry with Incremental Rotation Averaging and Loop Closure
Oct 05, 2020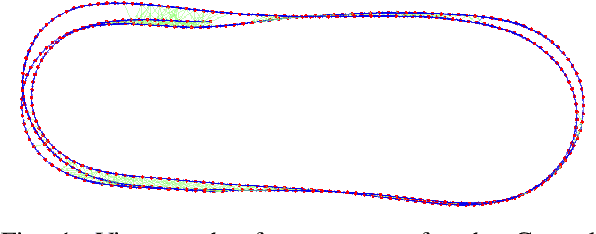
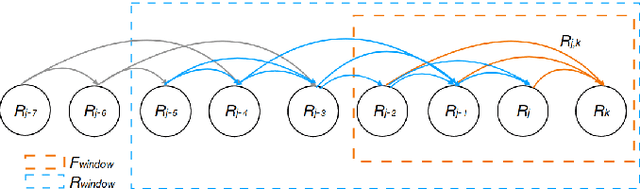
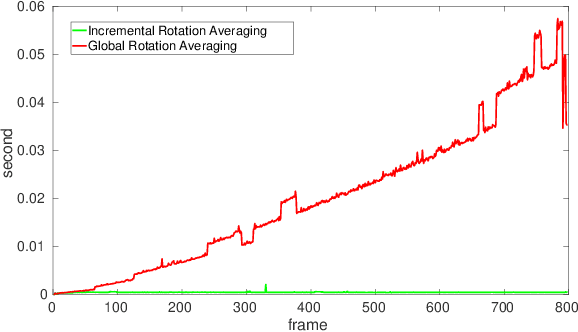
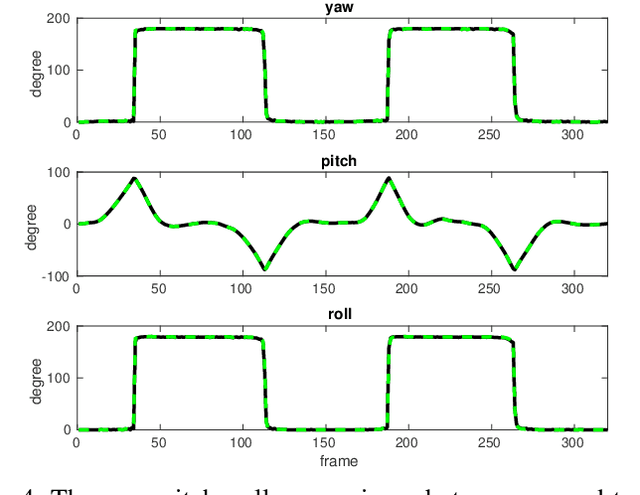
Estimating absolute camera orientations is essential for attitude estimation tasks. An established approach is to first carry out visual odometry (VO) or visual SLAM (V-SLAM), and retrieve the camera orientations (3 DOF) from the camera poses (6 DOF) estimated by VO or V-SLAM. One drawback of this approach, besides the redundancy in estimating full 6 DOF camera poses, is the dependency on estimating a map (3D scene points) jointly with the 6 DOF poses due to the basic constraint on structure-and-motion. To simplify the task of absolute orientation estimation, we formulate the monocular rotational odometry problem and devise a fast algorithm to accurately estimate camera orientations with 2D-2D feature matches alone. Underpinning our system is a new incremental rotation averaging method for fast and constant time iterative updating. Furthermore, our system maintains a view-graph that 1) allows solving loop closure to remove camera orientation drift, and 2) can be used to warm start a V-SLAM system. We conduct extensive quantitative experiments on real-world datasets to demonstrate the accuracy of our incremental camera orientation solver. Finally, we showcase the benefit of our algorithm to V-SLAM: 1) solving the known rotation problem to estimate the trajectory of the camera and the surrounding map, and 2)enabling V-SLAM systems to track pure rotational motions.
Improved Visual Localization via Graph Smoothing
Nov 07, 2019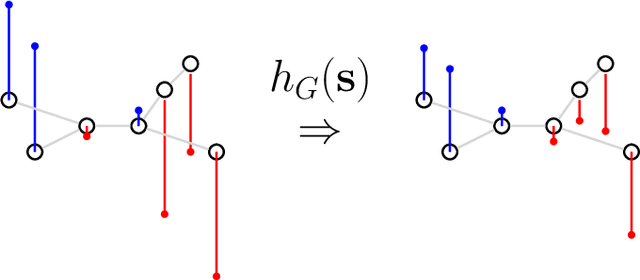
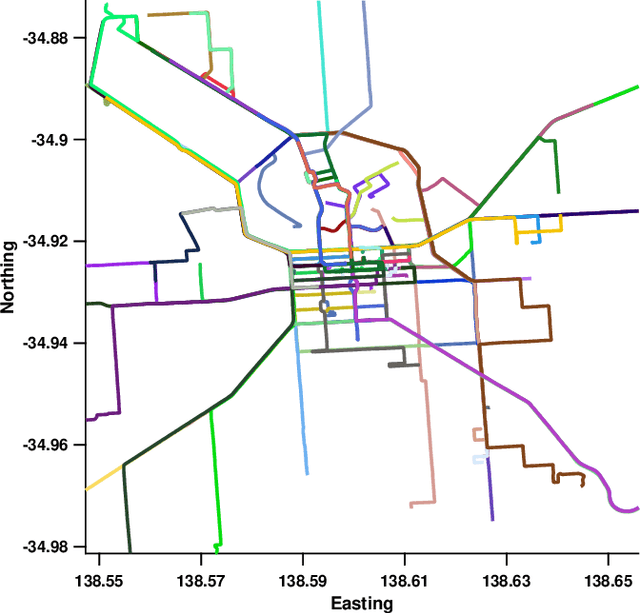
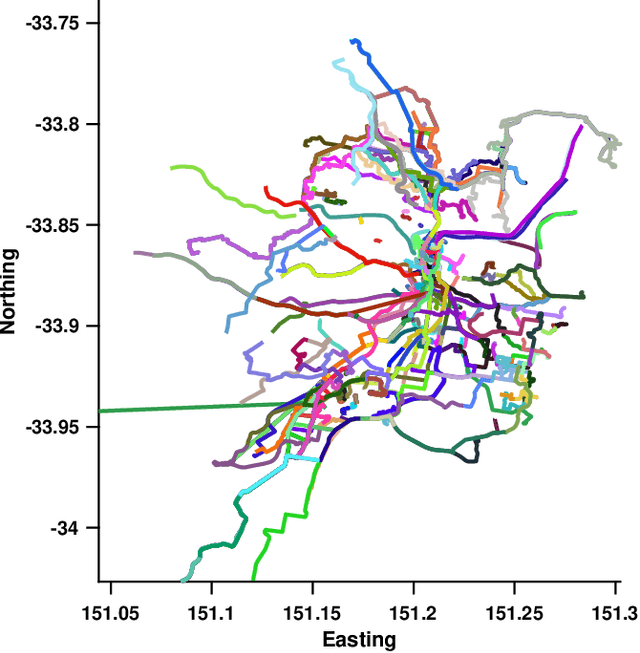
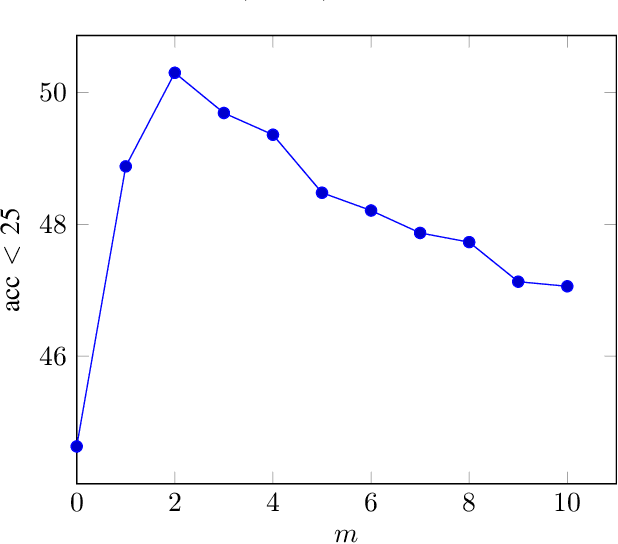
Vision based localization is the problem of inferring the pose of the camera given a single image. One solution to this problem is to learn a deep neural network to infer the pose of a query image after learning on a dataset of images with known poses. Another more commonly used approach rely on image retrieval where the query image is compared against the database of images and its pose is inferred with the help of the retrieved images. The latter approach assumes that images taken from the same places consists of the same landmarks and, thus would have similar feature representations. These representation can be learned using full supervision to be robust to different variations in capture conditions like time of the day and weather. In this work, we introduce a framework to enhance the performance of these retrieval based localization methods by taking into account the additional information including GPS coordinates and temporal neighbourhood of the images provided by the acquisition process in addition to the descriptor similarity of pairs of images in the reference or query database which is used traditionally for localization. Our method constructs a graph based on this additional information and use it for robust retrieval by smoothing the feature representation of reference and/or query images. We show that the proposed method is able to significantly improve the localization accuracy on two large scale datasets over the baselines.
Scalable Place Recognition Under Appearance Change for Autonomous Driving
Aug 01, 2019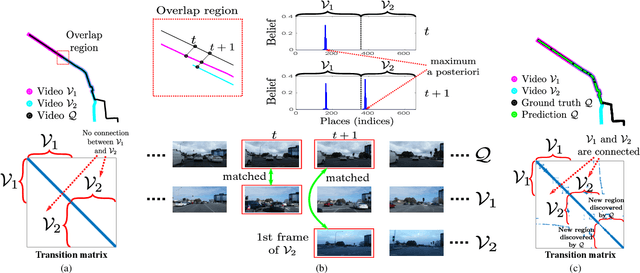
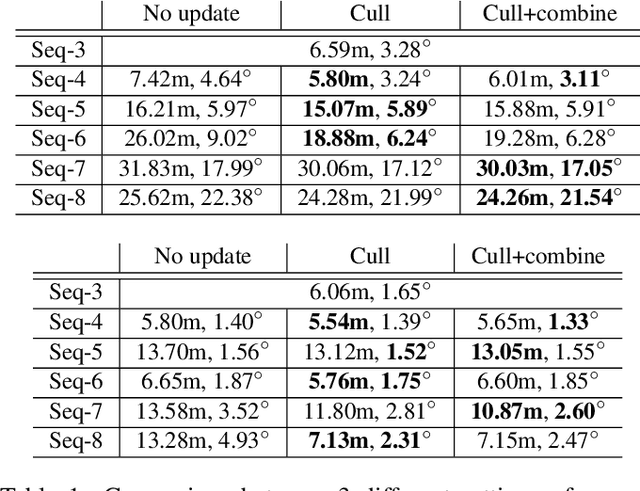
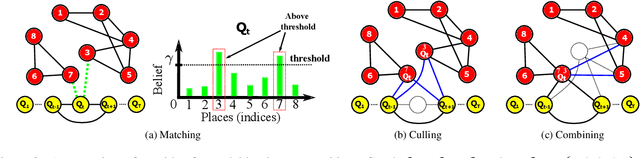
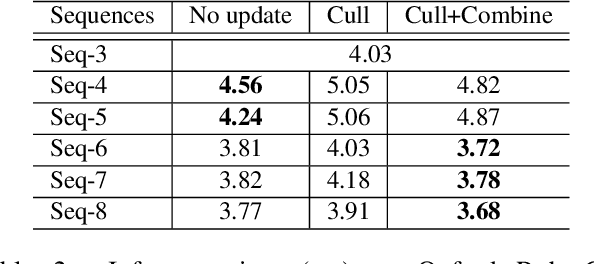
A major challenge in place recognition for autonomous driving is to be robust against appearance changes due to short-term (e.g., weather, lighting) and long-term (seasons, vegetation growth, etc.) environmental variations. A promising solution is to continuously accumulate images to maintain an adequate sample of the conditions and incorporate new changes into the place recognition decision. However, this demands a place recognition technique that is scalable on an ever growing dataset. To this end, we propose a novel place recognition technique that can be efficiently retrained and compressed, such that the recognition of new queries can exploit all available data (including recent changes) without suffering from visible growth in computational cost. Underpinning our method is a novel temporal image matching technique based on Hidden Markov Models. Our experiments show that, compared to state-of-the-art techniques, our method has much greater potential for large-scale place recognition for autonomous driving.
Real-Time Monocular Object-Model Aware Sparse SLAM
Mar 06, 2019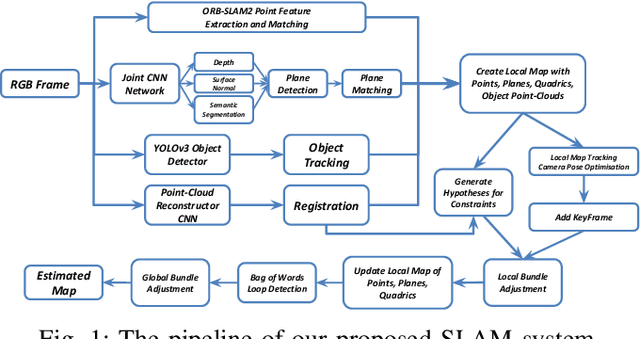
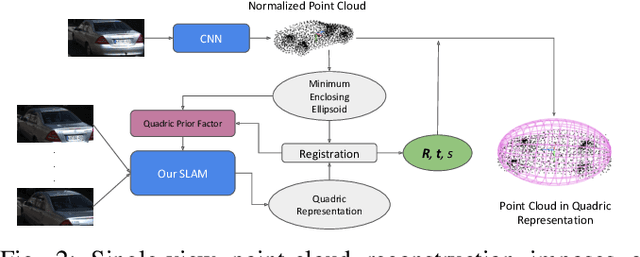
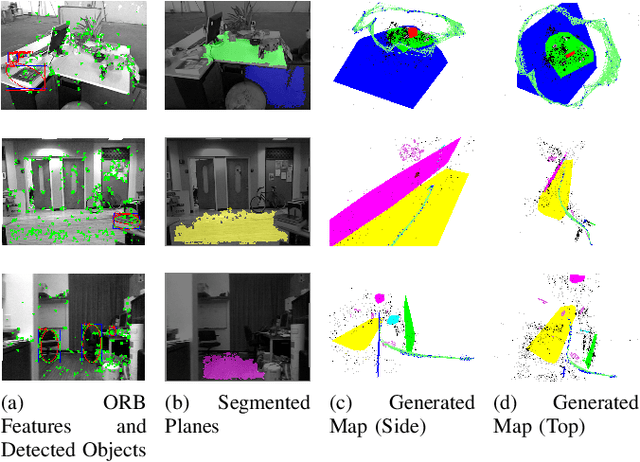
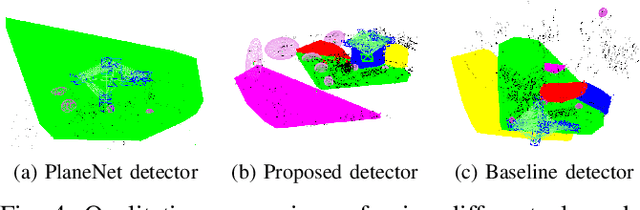
Simultaneous Localization And Mapping (SLAM) is a fundamental problem in mobile robotics. While sparse point-based SLAM methods provide accurate camera localization, the generated maps lack semantic information. On the other hand, state of the art object detection methods provide rich information about entities present in the scene from a single image. This work incorporates a real-time deep-learned object detector to the monocular SLAM framework for representing generic objects as quadrics that permit detections to be seamlessly integrated while allowing the real-time performance. Finer reconstruction of an object, learned by a CNN network, is also incorporated and provides a shape prior for the quadric leading further refinement. To capture the dominant structure of the scene, additional planar landmarks are detected by a CNN-based plane detector and modeled as independent landmarks in the map. Extensive experiments support our proposed inclusion of semantic objects and planar structures directly in the bundle-adjustment of SLAM - Semantic SLAM - that enriches the reconstructed map semantically, while significantly improving the camera localization. The performance of our SLAM system is demonstrated in https://youtu.be/UMWXd4sHONw and https://youtu.be/QPQqVrvP0dE .
Practical Visual Localization for Autonomous Driving: Why Not Filter?
Nov 20, 2018
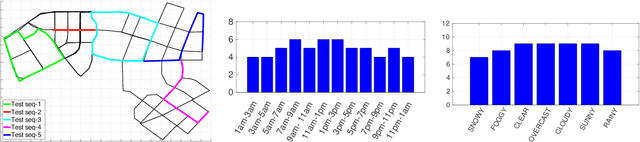

A major focus of current research on place recognition is visual localization for autonomous driving. However, while many visual localization algorithms for autonomous driving have achieved impressive results, it seems not all previous works have been set in a realistic setting for the problem, namely using training and testing videos that were collected in a distributed manner from multiple vehicles, all traversing through a road network in an urban area under different environmental conditions (weather, lighting, etc.). More importantly, in this setting, we show that exploiting temporal continuity in the testing sequence significantly improves visual localization - qualitatively and quantitatively. Although intuitive, this idea has not been fully explored in recent works. Our main contribution is a novel particle filtering technique that works in conjunction with a visual localization method to achieve accurate city-scale localization that is robust against environmental variations. We provide convincing results on synthetic and real datasets.
Structure Aware SLAM using Quadrics and Planes
Nov 02, 2018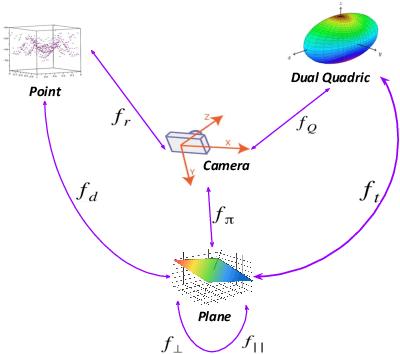
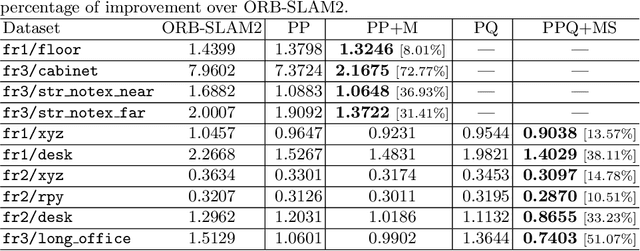

Simultaneous Localization And Mapping (SLAM) is a fundamental problem in mobile robotics. While point-based SLAM methods provide accurate camera localization, the generated maps lack semantic information. On the other hand, state of the art object detection methods provide rich information about entities present in the scene from a single image. This work marries the two and proposes a method for representing generic objects as quadrics which allows object detections to be seamlessly integrated in a SLAM framework. For scene coverage, additional dominant planar structures are modeled as infinite planes. Experiments show that the proposed points-planes-quadrics representation can easily incorporate Manhattan and object affordance constraints, greatly improving camera localization and leading to semantically meaningful maps. The performance of our SLAM system is demonstrated in https://youtu.be/dR-rB9keF8M .
Addressing Challenging Place Recognition Tasks using Generative Adversarial Networks
Feb 27, 2018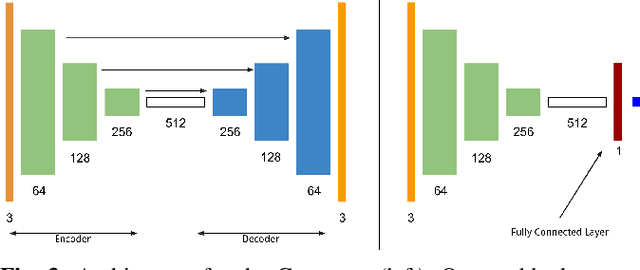
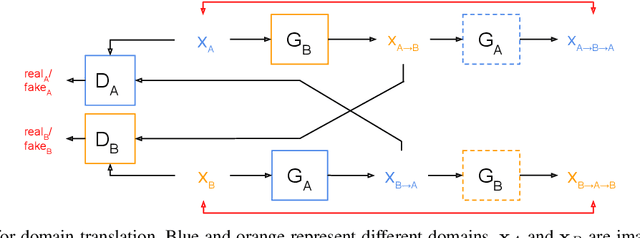

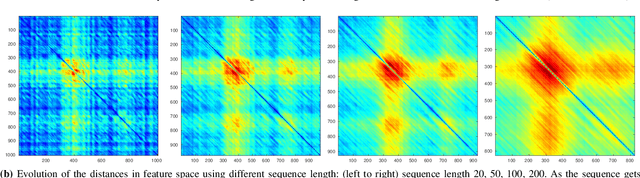
Place recognition is an essential component of Simultaneous Localization And Mapping (SLAM). Under severe appearance change, reliable place recognition is a difficult perception task since the same place is perceptually very different in the morning, at night, or over different seasons. This work addresses place recognition as a domain translation task. Using a pair of coupled Generative Adversarial Networks (GANs), we show that it is possible to generate the appearance of one domain (such as summer) from another (such as winter) without requiring image-to-image correspondences across the domains. Mapping between domains is learned from sets of images in each domain without knowing the instance-to-instance correspondence by enforcing a cyclic consistency constraint. In the process, meaningful feature spaces are learned for each domain, the distances in which can be used for the task of place recognition. Experiments show that learned features correspond to visual similarity and can be effectively used for place recognition across seasons.
Meaningful Maps With Object-Oriented Semantic Mapping
Aug 03, 2017
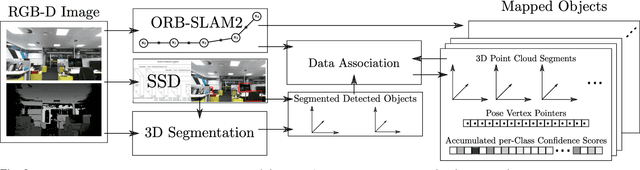


For intelligent robots to interact in meaningful ways with their environment, they must understand both the geometric and semantic properties of the scene surrounding them. The majority of research to date has addressed these mapping challenges separately, focusing on either geometric or semantic mapping. In this paper we address the problem of building environmental maps that include both semantically meaningful, object-level entities and point- or mesh-based geometrical representations. We simultaneously build geometric point cloud models of previously unseen instances of known object classes and create a map that contains these object models as central entities. Our system leverages sparse, feature-based RGB-D SLAM, image-based deep-learning object detection and 3D unsupervised segmentation.
Sparse Optimization for Robust and Efficient Loop Closing
Jan 31, 2017
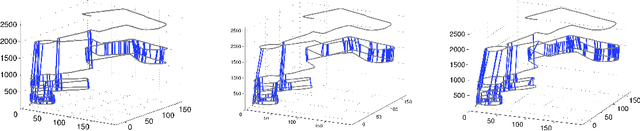

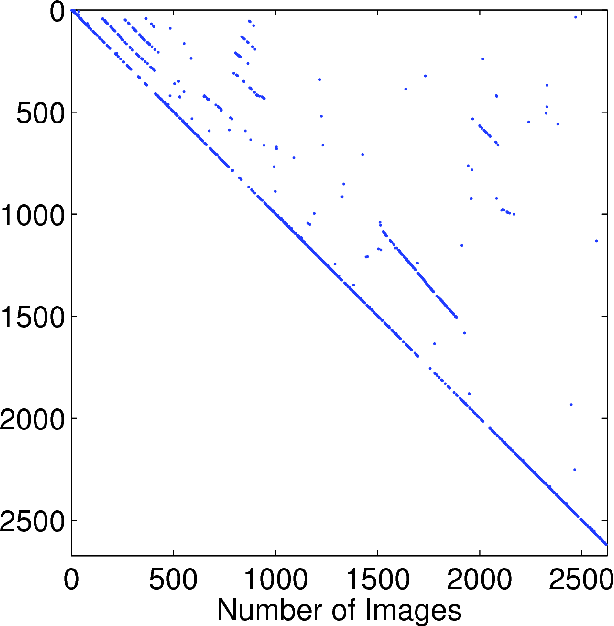
It is essential for a robot to be able to detect revisits or loop closures for long-term visual navigation.A key insight explored in this work is that the loop-closing event inherently occurs sparsely, that is, the image currently being taken matches with only a small subset (if any) of previous images. Based on this observation, we formulate the problem of loop-closure detection as a sparse, convex $\ell_1$-minimization problem. By leveraging fast convex optimization techniques, we are able to efficiently find loop closures, thus enabling real-time robot navigation. This novel formulation requires no offline dictionary learning, as required by most existing approaches, and thus allows online incremental operation. Our approach ensures a unique hypothesis by choosing only a single globally optimal match when making a loop-closure decision. Furthermore, the proposed formulation enjoys a flexible representation with no restriction imposed on how images should be represented, while requiring only that the representations are "close" to each other when the corresponding images are visually similar. The proposed algorithm is validated extensively using real-world datasets.
Past, Present, and Future of Simultaneous Localization And Mapping: Towards the Robust-Perception Age
Jan 30, 2017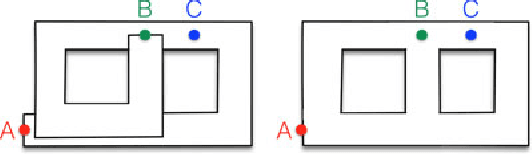
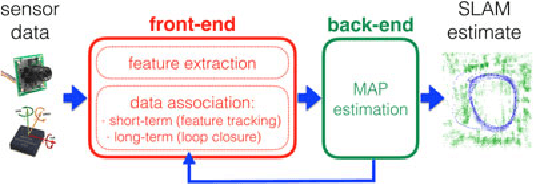
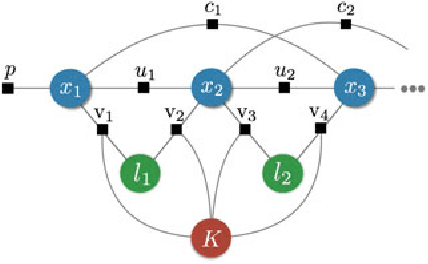
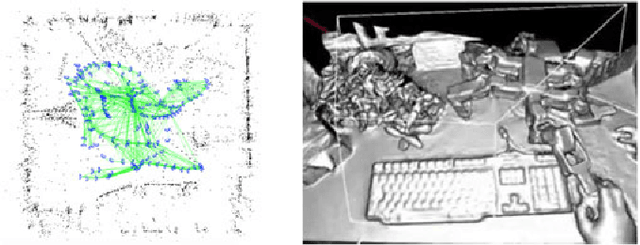
Simultaneous Localization and Mapping (SLAM)consists in the concurrent construction of a model of the environment (the map), and the estimation of the state of the robot moving within it. The SLAM community has made astonishing progress over the last 30 years, enabling large-scale real-world applications, and witnessing a steady transition of this technology to industry. We survey the current state of SLAM. We start by presenting what is now the de-facto standard formulation for SLAM. We then review related work, covering a broad set of topics including robustness and scalability in long-term mapping, metric and semantic representations for mapping, theoretical performance guarantees, active SLAM and exploration, and other new frontiers. This paper simultaneously serves as a position paper and tutorial to those who are users of SLAM. By looking at the published research with a critical eye, we delineate open challenges and new research issues, that still deserve careful scientific investigation. The paper also contains the authors' take on two questions that often animate discussions during robotics conferences: Do robots need SLAM? and Is SLAM solved?