 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Star Tracking under Spacecraft Jitter: the e-STURT Dataset
May 19, 2025



Jitter degrades a spacecraft's fine-pointing ability required for optical communication, earth observation, and space domain awareness. Development of jitter estimation and compensation algorithms requires high-fidelity sensor observations representative of on-board jitter. In this work, we present the Event-based Star Tracking Under Jitter (e-STURT) dataset -- the first event camera based dataset of star observations under controlled jitter conditions. Specialized hardware employed for the dataset emulates an event-camera undergoing on-board jitter. While the event camera provides asynchronous, high temporal resolution star observations, systematic and repeatable jitter is introduced using a micrometer accurate piezoelectric actuator. Various jitter sources are simulated using distinct frequency bands and utilizing both axes of motion. Ground-truth jitter is captured in hardware from the piezoelectric actuator. The resulting dataset consists of 200 sequences and is made publicly available. This work highlights the dataset generation process, technical challenges and the resulting limitations. To serve as a baseline, we propose a high-frequency jitter estimation algorithm that operates directly on the event stream. The e-STURT dataset will enable the development of jitter aware algorithms for mission critical event-based space sensing applications.
Test-Time Certifiable Self-Supervision to Bridge the Sim2Real Gap in Event-Based Satellite Pose Estimation
Sep 10, 2024



Deep learning plays a critical role in vision-based satellite pose estimation. However, the scarcity of real data from the space environment means that deep models need to be trained using synthetic data, which raises the Sim2Real domain gap problem. A major cause of the Sim2Real gap are novel lighting conditions encountered during test time. Event sensors have been shown to provide some robustness against lighting variations in vision-based pose estimation. However, challenging lighting conditions due to strong directional light can still cause undesirable effects in the output of commercial off-the-shelf event sensors, such as noisy/spurious events and inhomogeneous event densities on the object. Such effects are non-trivial to simulate in software, thus leading to Sim2Real gap in the event domain. To close the Sim2Real gap in event-based satellite pose estimation, the paper proposes a test-time self-supervision scheme with a certifier module. Self-supervision is enabled by an optimisation routine that aligns a dense point cloud of the predicted satellite pose with the event data to attempt to rectify the inaccurately estimated pose. The certifier attempts to verify the corrected pose, and only certified test-time inputs are backpropagated via implicit differentiation to refine the predicted landmarks, thus improving the pose estimates and closing the Sim2Real gap. Results show that the our method outperforms established test-time adaptation schemes.
On-chain Validation of Tracking Data Messages (TDM) Using Distributed Deep Learning on a Proof of Stake (PoS) Blockchain
Sep 03, 2024



Trustless tracking of Resident Space Objects (RSOs) is crucial for Space Situational Awareness (SSA), especially during adverse situations. The importance of transparent SSA cannot be overstated, as it is vital for ensuring space safety and security. In an era where RSO location information can be easily manipulated, the risk of RSOs being used as weapons is a growing concern. The Tracking Data Message (TDM) is a standardized format for broadcasting RSO observations. However, the varying quality of observations from diverse sensors poses challenges to SSA reliability. While many countries operate space assets, relatively few have SSA capabilities, making it crucial to ensure the accuracy and reliability of the data. Current practices assume complete trust in the transmitting party, leaving SSA capabilities vulnerable to adversarial actions such as spoofing TDMs. This work introduces a trustless mechanism for TDM validation and verification using deep learning over blockchain. By leveraging the trustless nature of blockchain, our approach eliminates the need for a central authority, establishing consensus-based truth. We propose a state-of-the-art, transformer-based orbit propagator that outperforms traditional methods like SGP4, enabling cross-validation of multiple observations for a single RSO. This deep learning-based transformer model can be distributed over a blockchain, allowing interested parties to host a node that contains a part of the distributed deep learning model. Our system comprises decentralised observers and validators within a Proof of Stake (PoS) blockchain. Observers contribute TDM data along with a stake to ensure honesty, while validators run the propagation and validation algorithms. The system rewards observers for contributing verified TDMs and penalizes those submitting unverifiable data.
Event-based Structure-from-Orbit
May 10, 2024



Event sensors offer high temporal resolution visual sensing, which makes them ideal for perceiving fast visual phenomena without suffering from motion blur. Certain applications in robotics and vision-based navigation require 3D perception of an object undergoing circular or spinning motion in front of a static camera, such as recovering the angular velocity and shape of the object. The setting is equivalent to observing a static object with an orbiting camera. In this paper, we propose event-based structure-from-orbit (eSfO), where the aim is to simultaneously reconstruct the 3D structure of a fast spinning object observed from a static event camera, and recover the equivalent orbital motion of the camera. Our contributions are threefold: since state-of-the-art event feature trackers cannot handle periodic self-occlusion due to the spinning motion, we develop a novel event feature tracker based on spatio-temporal clustering and data association that can better track the helical trajectories of valid features in the event data. The feature tracks are then fed to our novel factor graph-based structure-from-orbit back-end that calculates the orbital motion parameters (e.g., spin rate, relative rotational axis) that minimize the reprojection error. For evaluation, we produce a new event dataset of objects under spinning motion. Comparisons against ground truth indicate the efficacy of eSfO.
High Frequency, High Accuracy Pointing onboard Nanosats using Neuromorphic Event Sensing and Piezoelectric Actuation
Sep 11, 2023As satellites become smaller, the ability to maintain stable pointing decreases as external forces acting on the satellite come into play. At the same time, reaction wheels used in the attitude determination and control system (ADCS) introduce high frequency jitter which can disrupt pointing stability. For space domain awareness (SDA) tasks that track objects tens of thousands of kilometres away, the pointing accuracy offered by current nanosats, typically in the range of 10 to 100 arcseconds, is not sufficient. In this work, we develop a novel payload that utilises a neuromorphic event sensor (for high frequency and highly accurate relative attitude estimation) paired in a closed loop with a piezoelectric stage (for active attitude corrections) to provide highly stable sensor-specific pointing. Event sensors are especially suited for space applications due to their desirable characteristics of low power consumption, asynchronous operation, and high dynamic range. We use the event sensor to first estimate a reference background star field from which instantaneous relative attitude is estimated at high frequency. The piezoelectric stage works in a closed control loop with the event sensor to perform attitude corrections based on the discrepancy between the current and desired attitude. Results in a controlled setting show that we can achieve a pointing accuracy in the range of 1-5 arcseconds using our novel payload at an operating frequency of up to 50Hz using a prototype built from commercial-off-the-shelf components. Further details can be found at https://ylatif.github.io/ultrafinestabilisation
Globally Optimal Event-Based Divergence Estimation for Ventral Landing
Sep 27, 2022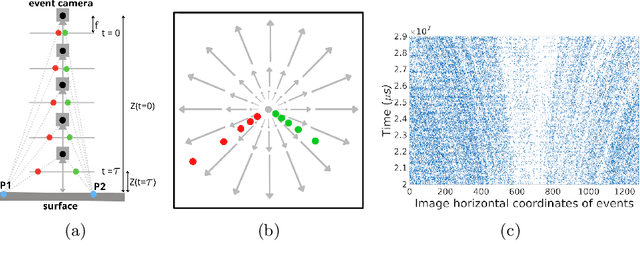

Event sensing is a major component in bio-inspired flight guidance and control systems. We explore the usage of event cameras for predicting time-to-contact (TTC) with the surface during ventral landing. This is achieved by estimating divergence (inverse TTC), which is the rate of radial optic flow, from the event stream generated during landing. Our core contributions are a novel contrast maximisation formulation for event-based divergence estimation, and a branch-and-bound algorithm to exactly maximise contrast and find the optimal divergence value. GPU acceleration is conducted to speed up the global algorithm. Another contribution is a new dataset containing real event streams from ventral landing that was employed to test and benchmark our method. Owing to global optimisation, our algorithm is much more capable at recovering the true divergence, compared to other heuristic divergence estimators or event-based optic flow methods. With GPU acceleration, our method also achieves competitive runtimes.
Towards Bridging the Space Domain Gap for Satellite Pose Estimation using Event Sensing
Sep 24, 2022
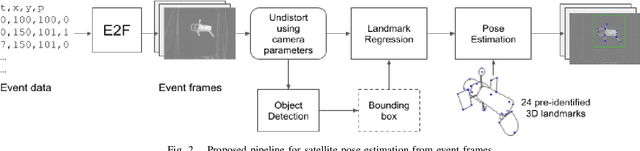
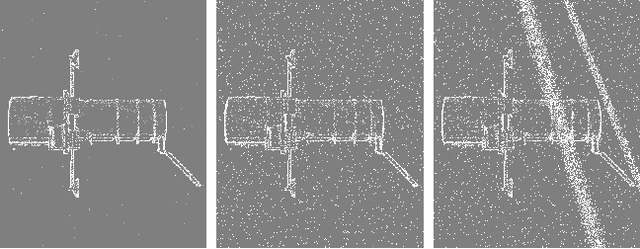
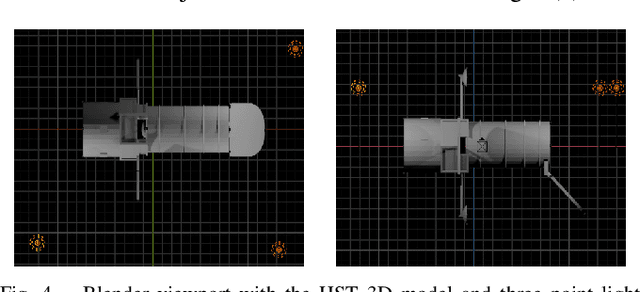
Deep models trained using synthetic data require domain adaptation to bridge the gap between the simulation and target environments. State-of-the-art domain adaptation methods often demand sufficient amounts of (unlabelled) data from the target domain. However, this need is difficult to fulfil when the target domain is an extreme environment, such as space. In this paper, our target problem is close proximity satellite pose estimation, where it is costly to obtain images of satellites from actual rendezvous missions. We demonstrate that event sensing offers a promising solution to generalise from the simulation to the target domain under stark illumination differences. Our main contribution is an event-based satellite pose estimation technique, trained purely on synthetic event data with basic data augmentation to improve robustness against practical (noisy) event sensors. Underpinning our method is a novel dataset with carefully calibrated ground truth, comprising of real event data obtained by emulating satellite rendezvous scenarios in the lab under drastic lighting conditions. Results on the dataset showed that our event-based satellite pose estimation method, trained only on synthetic data without adaptation, could generalise to the target domain effectively.
Asynchronous Optimisation for Event-based Visual Odometry
Mar 02, 2022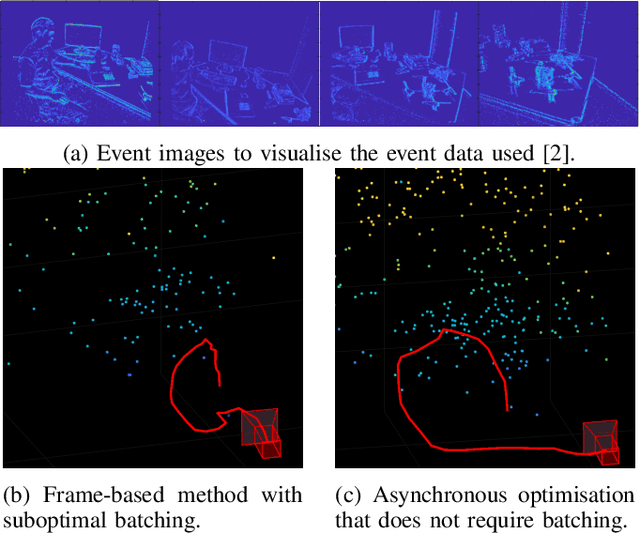

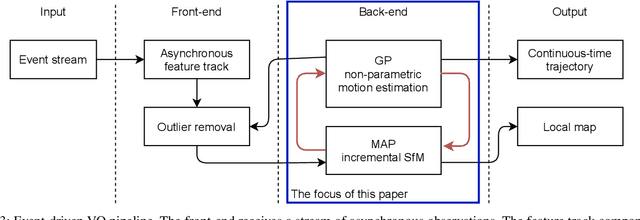
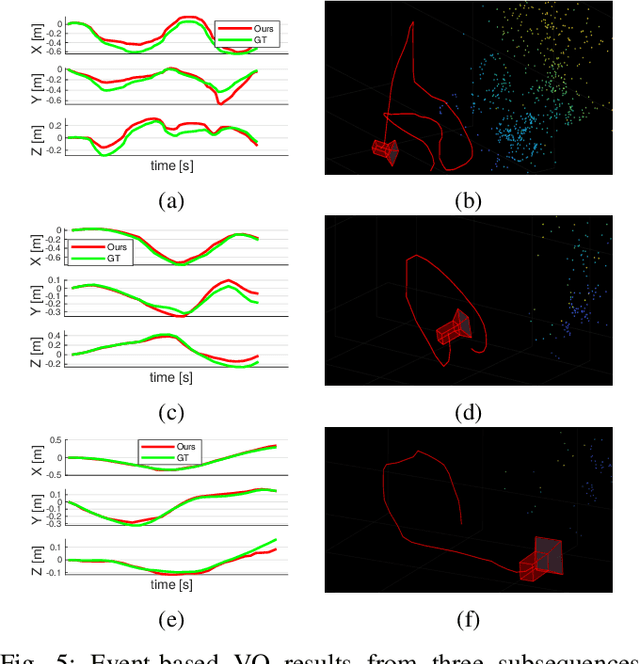
Event cameras open up new possibilities for robotic perception due to their low latency and high dynamic range. On the other hand, developing effective event-based vision algorithms that fully exploit the beneficial properties of event cameras remains work in progress. In this paper, we focus on event-based visual odometry (VO). While existing event-driven VO pipelines have adopted continuous-time representations to asynchronously process event data, they either assume a known map, restrict the camera to planar trajectories, or integrate other sensors into the system. Towards map-free event-only monocular VO in SE(3), we propose an asynchronous structure-from-motion optimisation back-end. Our formulation is underpinned by a principled joint optimisation problem involving non-parametric Gaussian Process motion modelling and incremental maximum a posteriori inference. A high-performance incremental computation engine is employed to reason about the camera trajectory with every incoming event. We demonstrate the robustness of our asynchronous back-end in comparison to frame-based methods which depend on accurate temporal accumulation of measurements.
Learning to Predict Repeatability of Interest Points
May 08, 2021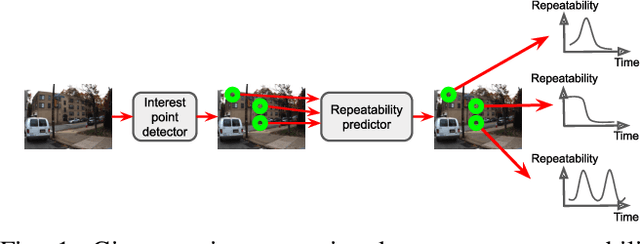
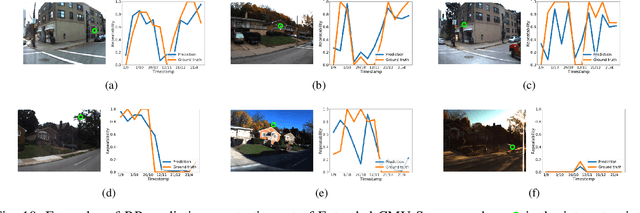
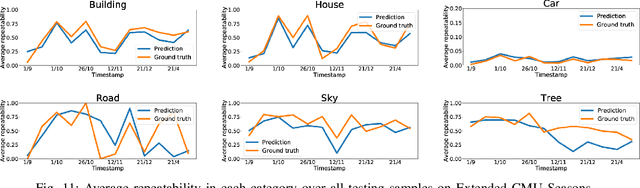
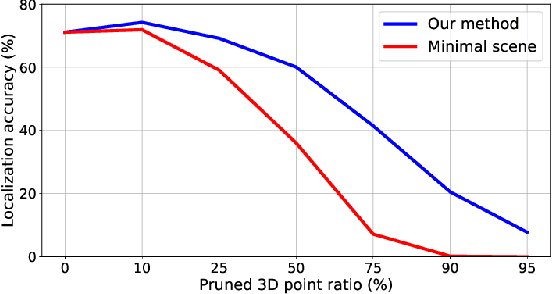
Many robotics applications require interest points that are highly repeatable under varying viewpoints and lighting conditions. However, this requirement is very challenging as the environment changes continuously and indefinitely, leading to appearance changes of interest points with respect to time. This paper proposes to predict the repeatability of an interest point as a function of time, which can tell us the lifespan of the interest point considering daily or seasonal variation. The repeatability predictor (RP) is formulated as a regressor trained on repeated interest points from multiple viewpoints over a long period of time. Through comprehensive experiments, we demonstrate that our RP can estimate when a new interest point is repeated, and also highlight an insightful analysis about this problem. For further comparison, we apply our RP to the map summarization under visual localization framework, which builds a compact representation of the full context map given the query time. The experimental result shows a careful selection of potentially repeatable interest points predicted by our RP can significantly mitigate the degeneration of localization accuracy from map summarization.
HM4: Hidden Markov Model with Memory Management for Visual Place Recognition
Nov 01, 2020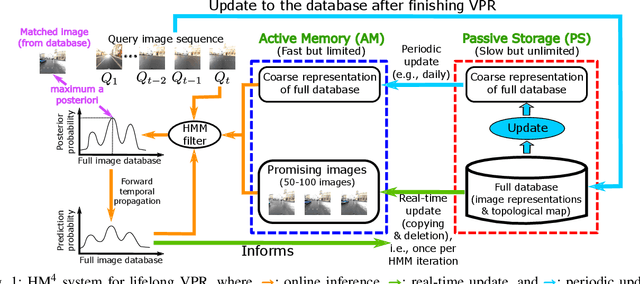
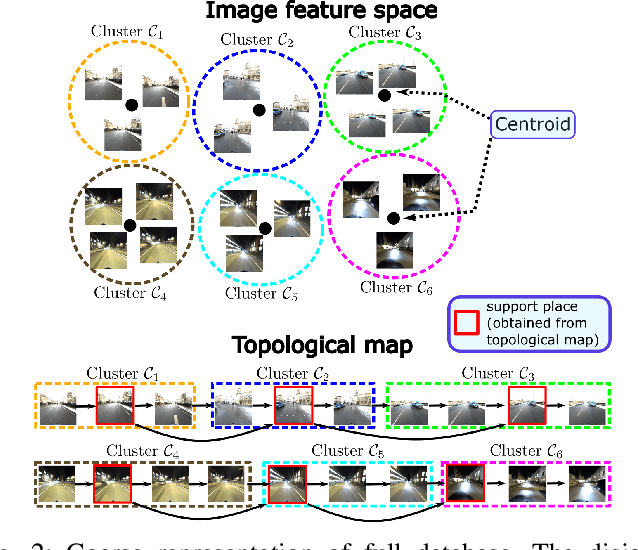
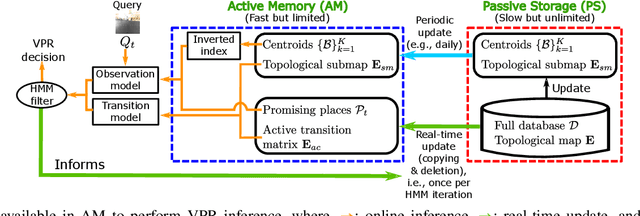
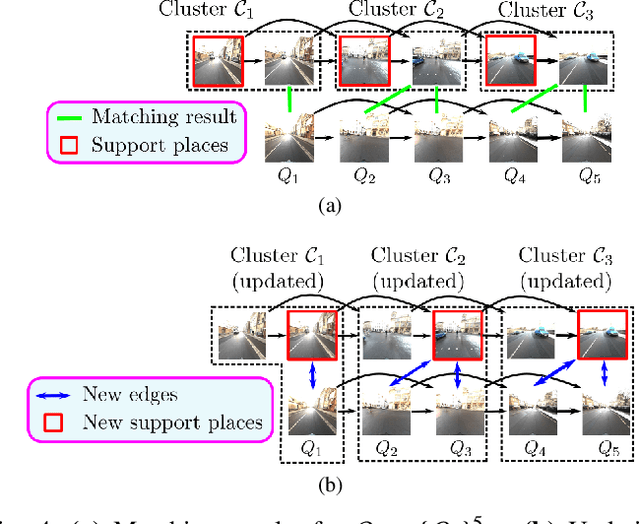
Visual place recognition needs to be robust against appearance variability due to natural and man-made causes. Training data collection should thus be an ongoing process to allow continuous appearance changes to be recorded. However, this creates an unboundedly-growing database that poses time and memory scalability challenges for place recognition methods. To tackle the scalability issue for visual place recognition in autonomous driving, we develop a Hidden Markov Model approach with a two-tiered memory management. Our algorithm, dubbed HM$^4$, exploits temporal look-ahead to transfer promising candidate images between passive storage and active memory when needed. The inference process takes into account both promising images and a coarse representations of the full database. We show that this allows constant time and space inference for a fixed coverage area. The coarse representations can also be updated incrementally to absorb new data. To further reduce the memory requirements, we derive a compact image representation inspired by Locality Sensitive Hashing (LSH). Through experiments on real world data, we demonstrate the excellent scalability and accuracy of the approach under appearance changes and provide comparisons against state-of-the-art techniques.