 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Calibration with Multi-domain Temperature Scaling
Jun 06, 2022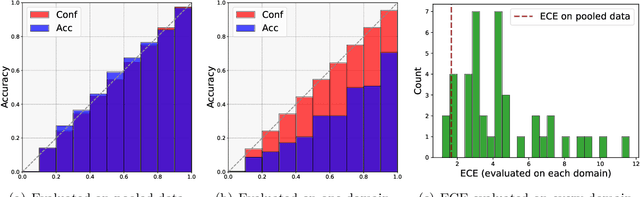
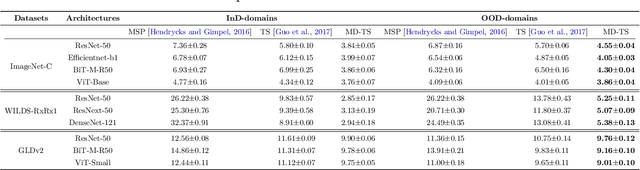
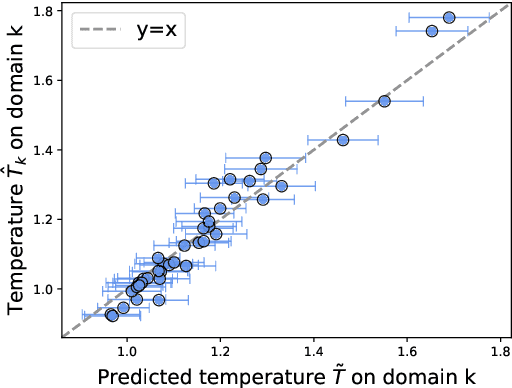
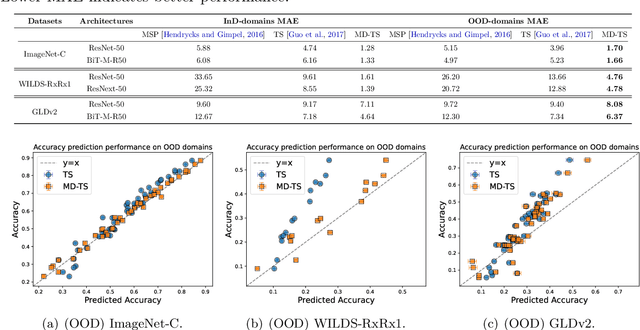
Uncertainty quantification is essential for the reliable deployment of machine learning models to high-stakes application domains. Uncertainty quantification is all the more challenging when training distribution and test distribution are different, even the distribution shifts are mild. Despite the ubiquity of distribution shifts in real-world applications, existing uncertainty quantification approaches mainly study the in-distribution setting where the train and test distributions are the same. In this paper, we develop a systematic calibration model to handle distribution shifts by leveraging data from multiple domains. Our proposed method -- multi-domain temperature scaling -- uses the heterogeneity in the domains to improve calibration robustness under distribution shift. Through experiments on three benchmark data sets, we find our proposed method outperforms existing methods as measured on both in-distribution and out-of-distribution test sets.
Conditional Supervised Contrastive Learning for Fair Text Classification
May 23, 2022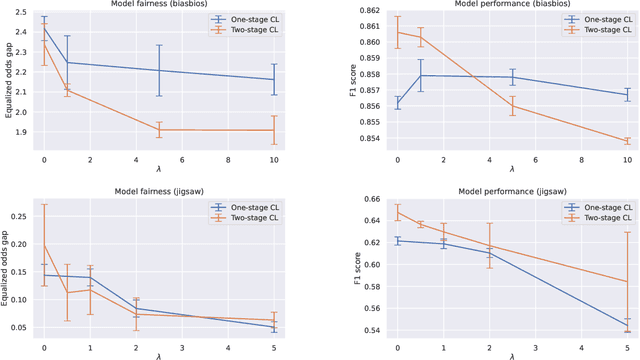
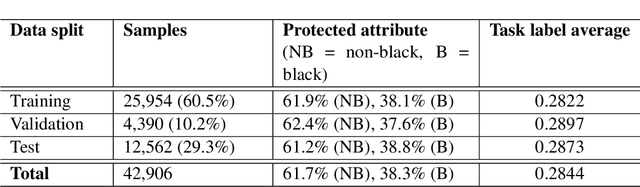
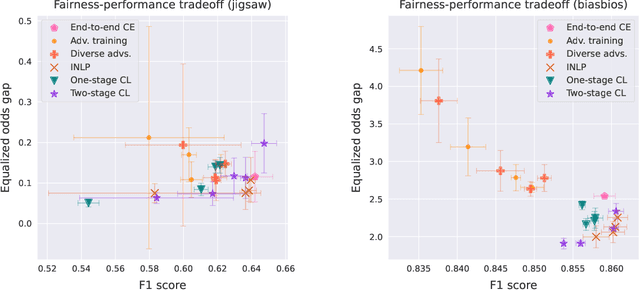
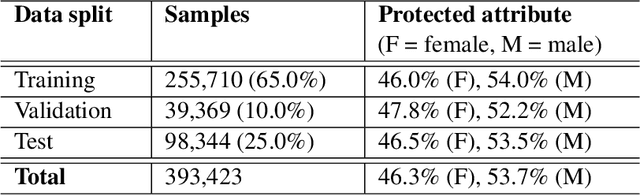
Contrastive representation learning has gained much attention due to its superior performance in learning representations from both image and sequential data. However, the learned representations could potentially lead to performance disparities in downstream tasks, such as increased silencing of underrepresented groups in toxicity comment classification. In light of this challenge, in this work, we study learning fair representations that satisfy a notion of fairness known as equalized odds for text classification via contrastive learning. Specifically, we first theoretically analyze the connections between learning representations with fairness constraint and conditional supervised contrastive objectives. Inspired by our theoretical findings, we propose to use conditional supervised contrastive objectives to learn fair representations for text classification. We conduct experiments on two text datasets to demonstrate the effectiveness of our approaches in balancing the trade-offs between task performance and bias mitigation among existing baselines for text classification. Furthermore, we also show that the proposed methods are stable in different hyperparameter settings.
Online Nonsubmodular Minimization with Delayed Costs: From Full Information to Bandit Feedback
May 15, 2022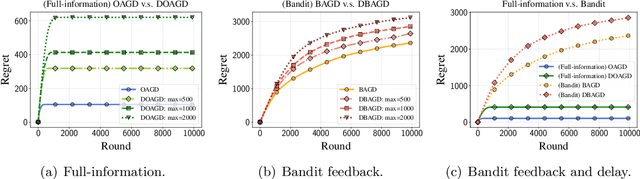
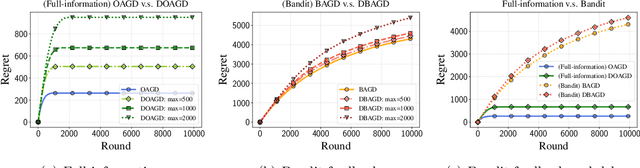
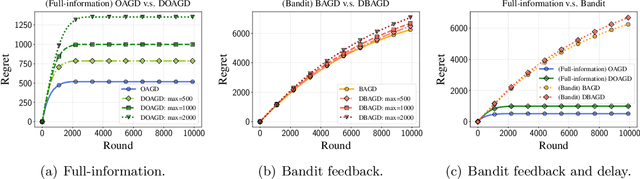
Motivated by applications to online learning in sparse estimation and Bayesian optimization, we consider the problem of online unconstrained nonsubmodular minimization with delayed costs in both full information and bandit feedback settings. In contrast to previous works on online unconstrained submodular minimization, we focus on a class of nonsubmodular functions with special structure, and prove regret guarantees for several variants of the online and approximate online bandit gradient descent algorithms in static and delayed scenarios. We derive bounds for the agent's regret in the full information and bandit feedback setting, even if the delay between choosing a decision and receiving the incurred cost is unbounded. Key to our approach is the notion of $(\alpha, \beta)$-regret and the extension of the generic convex relaxation model from~\citet{El-2020-Optimal}, the analysis of which is of independent interest. We conduct and showcase several simulation studies to demonstrate the efficacy of our algorithms.
What You See is What You Get: Distributional Generalization for Algorithm Design in Deep Learning
Apr 07, 2022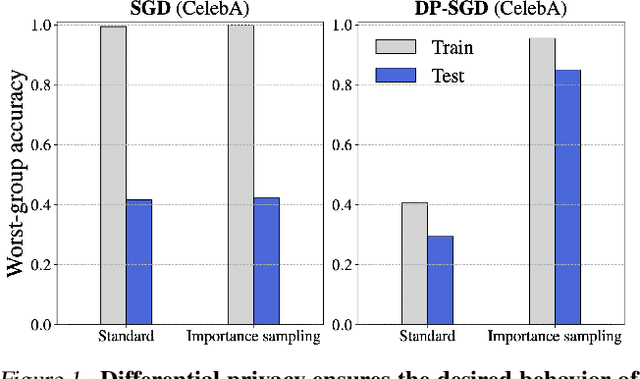
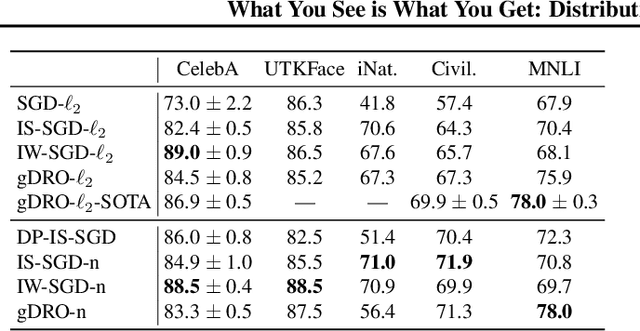
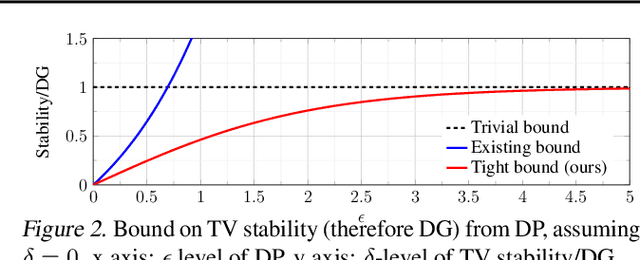
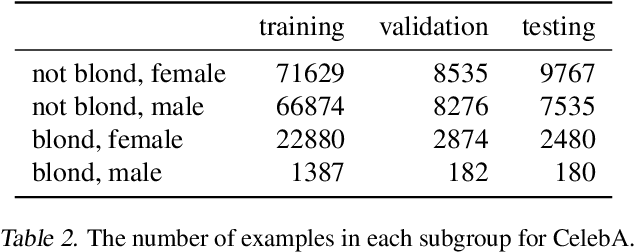
We investigate and leverage a connection between Differential Privacy (DP) and the recently proposed notion of Distributional Generalization (DG). Applying this connection, we introduce new conceptual tools for designing deep-learning methods that bypass "pathologies" of standard stochastic gradient descent (SGD). First, we prove that differentially private methods satisfy a "What You See Is What You Get (WYSIWYG)" generalization guarantee: whatever a model does on its train data is almost exactly what it will do at test time. This guarantee is formally captured by distributional generalization. WYSIWYG enables principled algorithm design in deep learning by reducing $\textit{generalization}$ concerns to $\textit{optimization}$ ones: in order to mitigate unwanted behavior at test time, it is provably sufficient to mitigate this behavior on the train data. This is notably false for standard (non-DP) methods, hence this observation has applications even when privacy is not required. For example, importance sampling is known to fail for standard SGD, but we show that it has exactly the intended effect for DP-trained models. Thus, with DP-SGD, unlike with SGD, we can influence test-time behavior by making principled train-time interventions. We use these insights to construct simple algorithms which match or outperform SOTA in several distributional robustness applications, and to significantly improve the privacy vs. disparate impact trade-off of DP-SGD. Finally, we also improve on known theoretical bounds relating differential privacy, stability, and distributional generalization.
Predicting Out-of-Distribution Error with the Projection Norm
Feb 11, 2022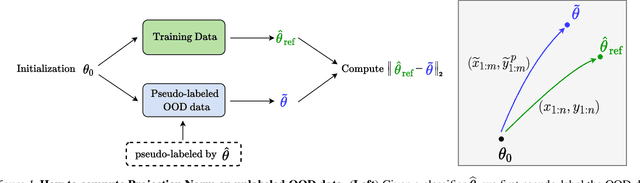
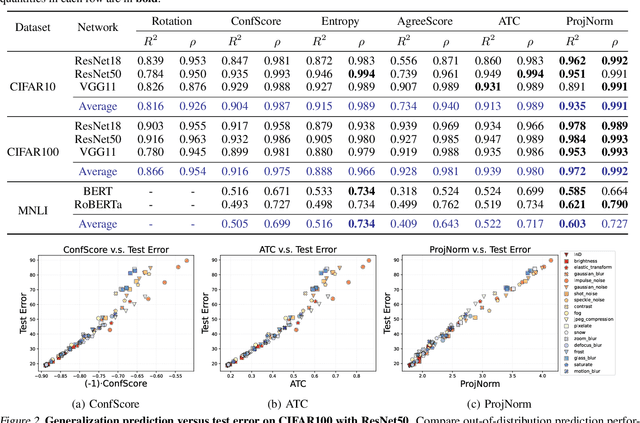
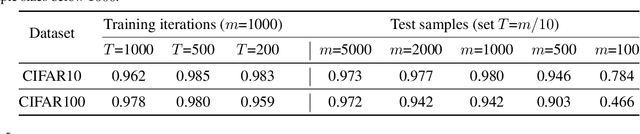
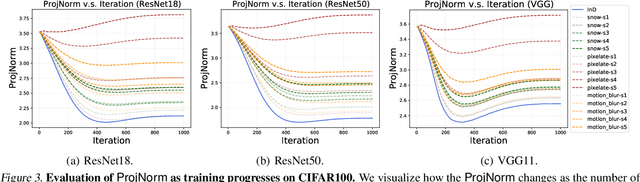
We propose a metric -- Projection Norm -- to predict a model's performance on out-of-distribution (OOD) data without access to ground truth labels. Projection Norm first uses model predictions to pseudo-label test samples and then trains a new model on the pseudo-labels. The more the new model's parameters differ from an in-distribution model, the greater the predicted OOD error. Empirically, our approach outperforms existing methods on both image and text classification tasks and across different network architectures. Theoretically, we connect our approach to a bound on the test error for overparameterized linear models. Furthermore, we find that Projection Norm is the only approach that achieves non-trivial detection performance on adversarial examples. Our code is available at https://github.com/yaodongyu/ProjNorm.
The Effect of Model Size on Worst-Group Generalization
Dec 08, 2021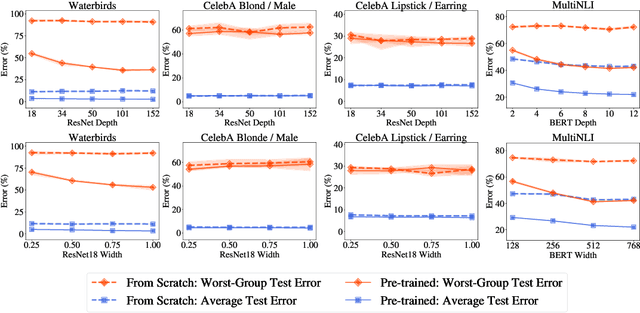
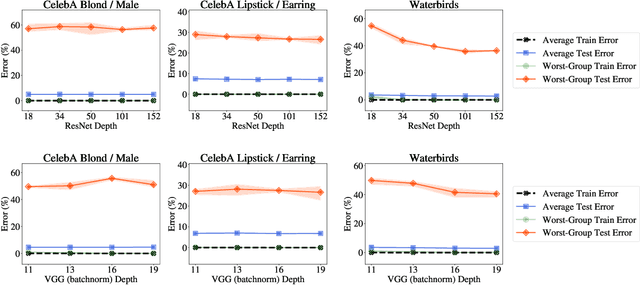
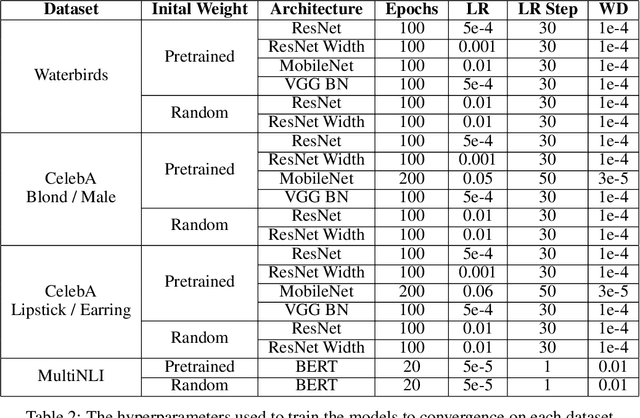
Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.
Closed-Loop Data Transcription to an LDR via Minimaxing Rate Reduction
Nov 12, 2021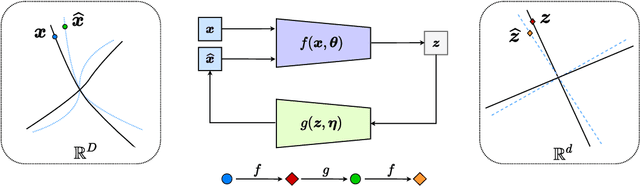
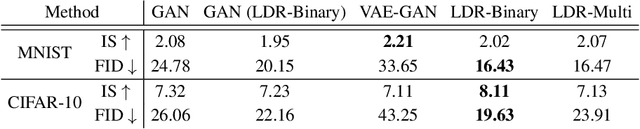
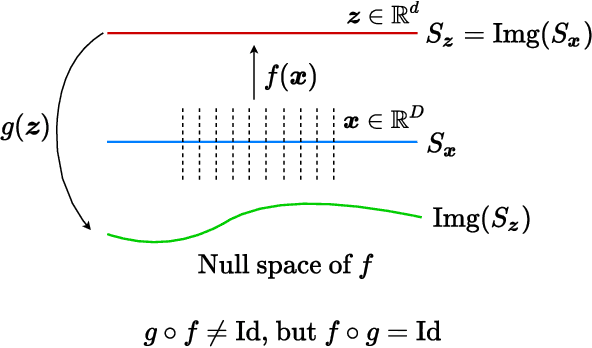
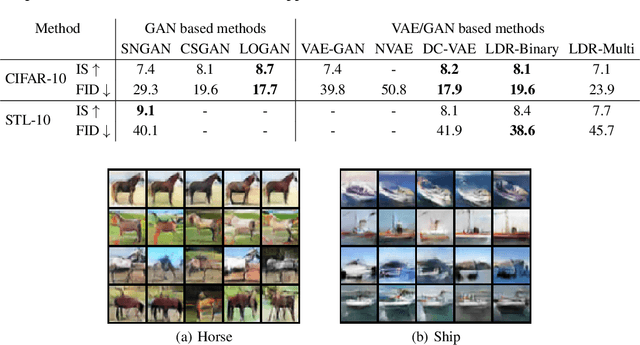
This work proposes a new computational framework for learning an explicit generative model for real-world datasets. In particular we propose to learn {\em a closed-loop transcription} between a multi-class multi-dimensional data distribution and a { linear discriminative representation (LDR)} in the feature space that consists of multiple independent multi-dimensional linear subspaces. In particular, we argue that the optimal encoding and decoding mappings sought can be formulated as the equilibrium point of a {\em two-player minimax game between the encoder and decoder}. A natural utility function for this game is the so-called {\em rate reduction}, a simple information-theoretic measure for distances between mixtures of subspace-like Gaussians in the feature space. Our formulation draws inspiration from closed-loop error feedback from control systems and avoids expensive evaluating and minimizing approximated distances between arbitrary distributions in either the data space or the feature space. To a large extent, this new formulation unifies the concepts and benefits of Auto-Encoding and GAN and naturally extends them to the settings of learning a {\em both discriminative and generative} representation for multi-class and multi-dimensional real-world data. Our extensive experiments on many benchmark imagery datasets demonstrate tremendous potential of this new closed-loop formulation: under fair comparison, visual quality of the learned decoder and classification performance of the encoder is competitive and often better than existing methods based on GAN, VAE, or a combination of both. We notice that the so learned features of different classes are explicitly mapped onto approximately {\em independent principal subspaces} in the feature space; and diverse visual attributes within each class are modeled by the {\em independent principal components} within each subspace.
On the Convergence of Stochastic Extragradient for Bilinear Games with Restarted Iteration Averaging
Jun 30, 2021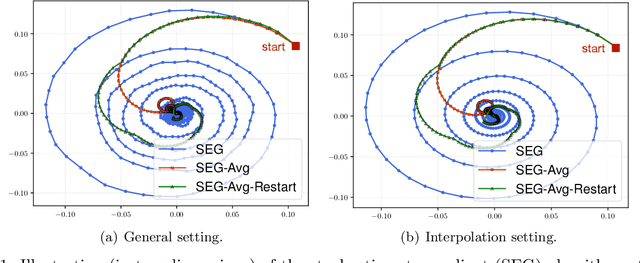
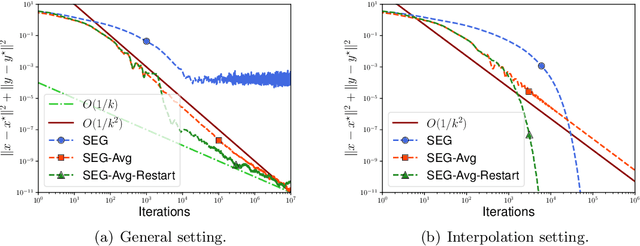
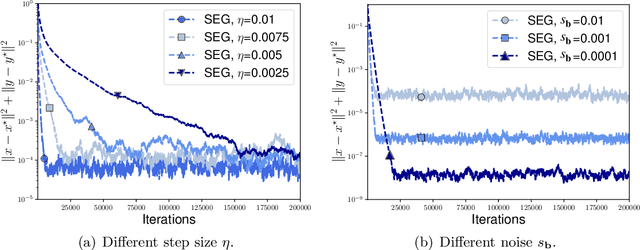
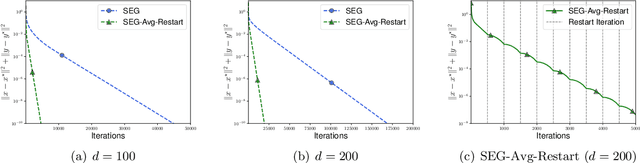
We study the stochastic bilinear minimax optimization problem, presenting an analysis of the Stochastic ExtraGradient (SEG) method with constant step size, and presenting variations of the method that yield favorable convergence. We first note that the last iterate of the basic SEG method only contracts to a fixed neighborhood of the Nash equilibrium, independent of the step size. This contrasts sharply with the standard setting of minimization where standard stochastic algorithms converge to a neighborhood that vanishes in proportion to the square-root (constant) step size. Under the same setting, however, we prove that when augmented with iteration averaging, SEG provably converges to the Nash equilibrium, and such a rate is provably accelerated by incorporating a scheduled restarting procedure. In the interpolation setting, we achieve an optimal convergence rate up to tight constants. We present numerical experiments that validate our theoretical findings and demonstrate the effectiveness of the SEG method when equipped with iteration averaging and restarting.
ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction
Jun 10, 2021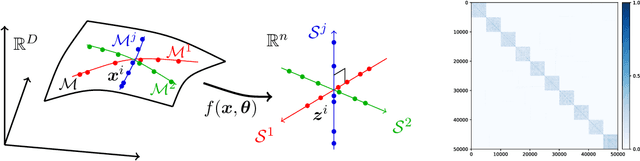
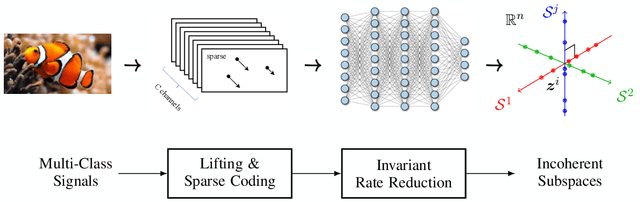

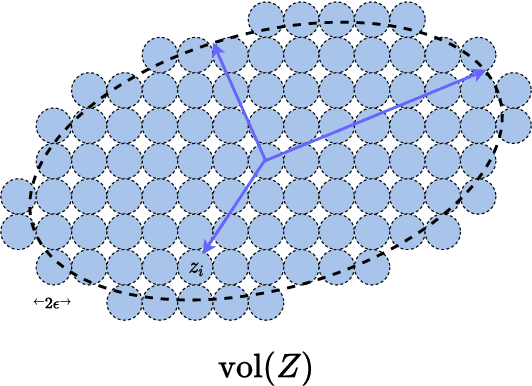
This work attempts to provide a plausible theoretical framework that aims to interpret modern deep (convolutional) networks from the principles of data compression and discriminative representation. We argue that for high-dimensional multi-class data, the optimal linear discriminative representation maximizes the coding rate difference between the whole dataset and the average of all the subsets. We show that the basic iterative gradient ascent scheme for optimizing the rate reduction objective naturally leads to a multi-layer deep network, named ReduNet, which shares common characteristics of modern deep networks. The deep layered architectures, linear and nonlinear operators, and even parameters of the network are all explicitly constructed layer-by-layer via forward propagation, although they are amenable to fine-tuning via back propagation. All components of so-obtained ``white-box'' network have precise optimization, statistical, and geometric interpretation. Moreover, all linear operators of the so-derived network naturally become multi-channel convolutions when we enforce classification to be rigorously shift-invariant. The derivation in the invariant setting suggests a trade-off between sparsity and invariance, and also indicates that such a deep convolution network is significantly more efficient to construct and learn in the spectral domain. Our preliminary simulations and experiments clearly verify the effectiveness of both the rate reduction objective and the associated ReduNet. All code and data are available at https://github.com/Ma-Lab-Berkeley.
Fast Distributionally Robust Learning with Variance Reduced Min-Max Optimization
Apr 27, 2021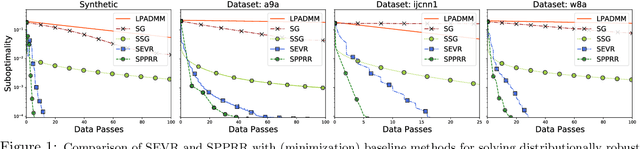
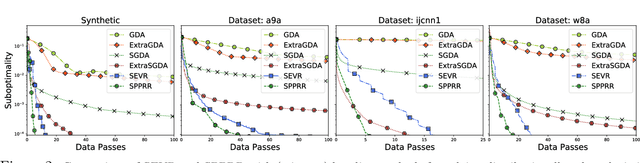
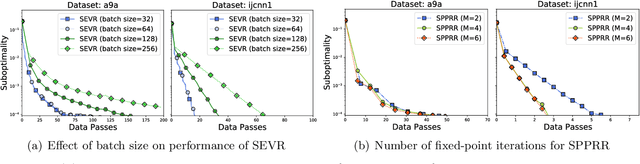
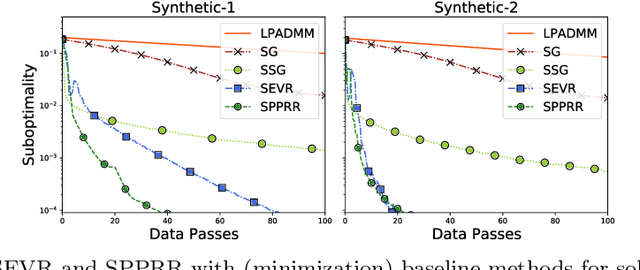
Distributionally robust supervised learning (DRSL) is emerging as a key paradigm for building reliable machine learning systems for real-world applications -- reflecting the need for classifiers and predictive models that are robust to the distribution shifts that arise from phenomena such as selection bias or nonstationarity. Existing algorithms for solving Wasserstein DRSL -- one of the most popular DRSL frameworks based around robustness to perturbations in the Wasserstein distance -- involve solving complex subproblems or fail to make use of stochastic gradients, limiting their use in large-scale machine learning problems. We revisit Wasserstein DRSL through the lens of min-max optimization and derive scalable and efficiently implementable stochastic extra-gradient algorithms which provably achieve faster convergence rates than existing approaches. We demonstrate their effectiveness on synthetic and real data when compared to existing DRSL approaches. Key to our results is the use of variance reduction and random reshuffling to accelerate stochastic min-max optimization, the analysis of which may be of independent interest.