 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Time Variations of DNN Inference in Autonomous Driving
Sep 12, 2022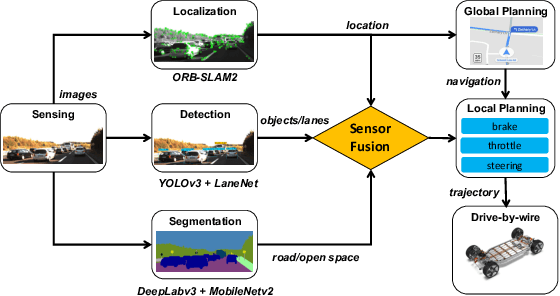
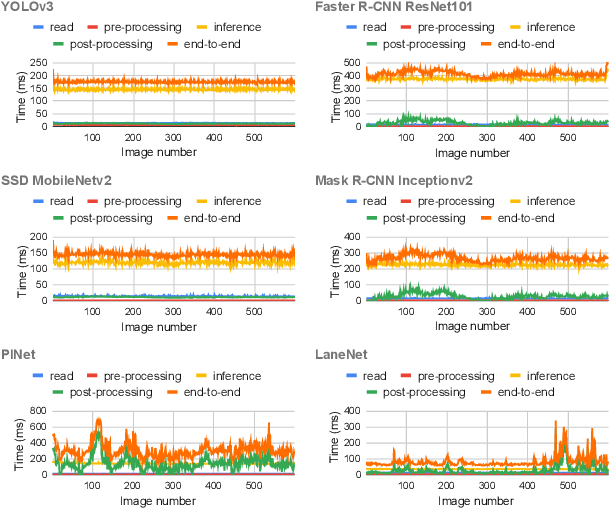
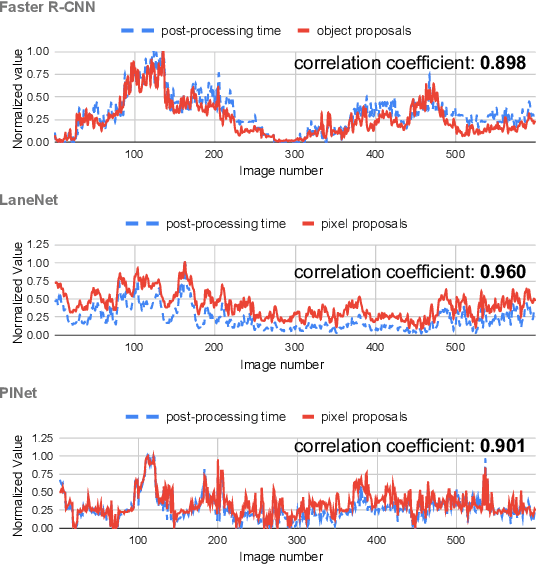
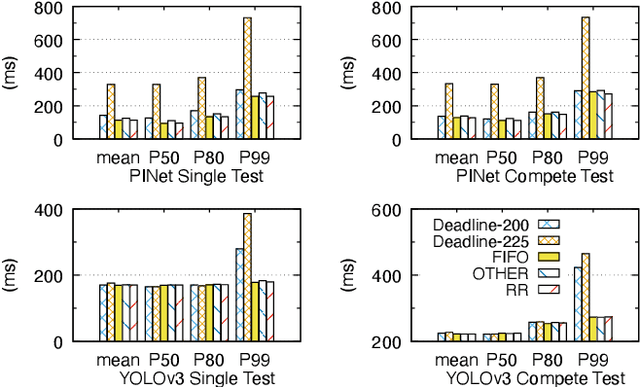
Deep neural networks (DNNs) are widely used in autonomous driving due to their high accuracy for perception, decision, and control. In safety-critical systems like autonomous driving, executing tasks like sensing and perception in real-time is vital to the vehicle's safety, which requires the application's execution time to be predictable. However, non-negligible time variations are observed in DNN inference. Current DNN inference studies either ignore the time variation issue or rely on the scheduler to handle it. None of the current work explains the root causes of DNN inference time variations. Understanding the time variations of the DNN inference becomes a fundamental challenge in real-time scheduling for autonomous driving. In this work, we analyze the time variation in DNN inference in fine granularity from six perspectives: data, I/O, model, runtime, hardware, and end-to-end perception system. Six insights are derived in understanding the time variations for DNN inference.
Survey: Exploiting Data Redundancy for Optimization of Deep Learning
Aug 29, 2022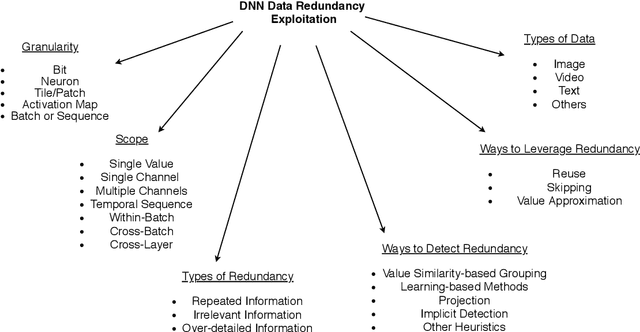
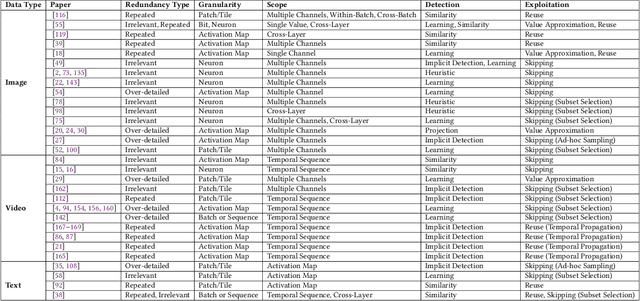
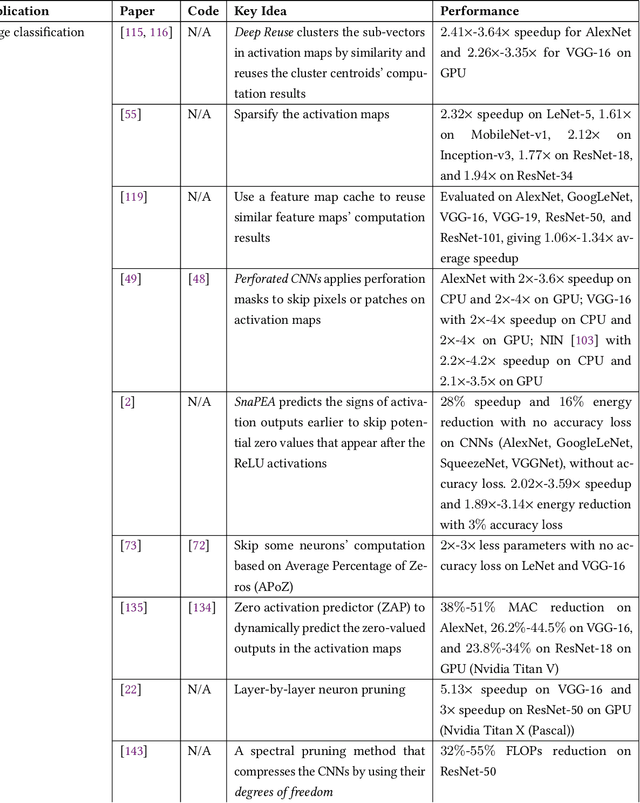
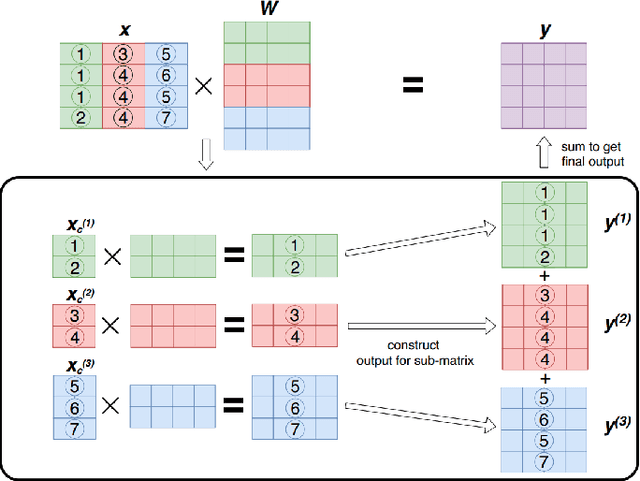
Data redundancy is ubiquitous in the inputs and intermediate results of Deep Neural Networks (DNN). It offers many significant opportunities for improving DNN performance and efficiency and has been explored in a large body of work. These studies have scattered in many venues across several years. The targets they focus on range from images to videos and texts, and the techniques they use to detect and exploit data redundancy also vary in many aspects. There is not yet a systematic examination and summary of the many efforts, making it difficult for researchers to get a comprehensive view of the prior work, the state of the art, differences and shared principles, and the areas and directions yet to explore. This article tries to fill the void. It surveys hundreds of recent papers on the topic, introduces a novel taxonomy to put the various techniques into a single categorization framework, offers a comprehensive description of the main methods used for exploiting data redundancy in improving multiple kinds of DNNs on data, and points out a set of research opportunities for future to explore.
Compiler-Aware Neural Architecture Search for On-Mobile Real-time Super-Resolution
Jul 25, 2022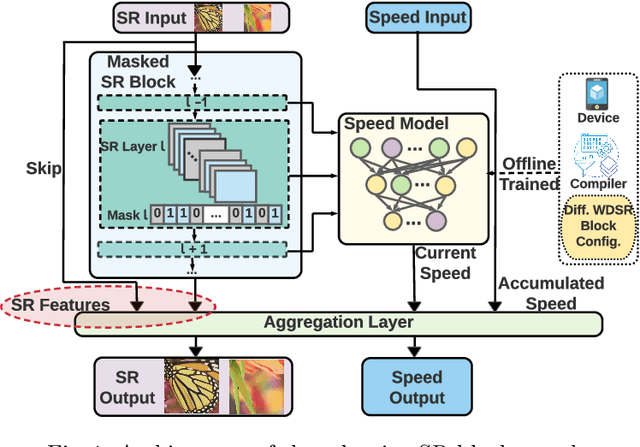
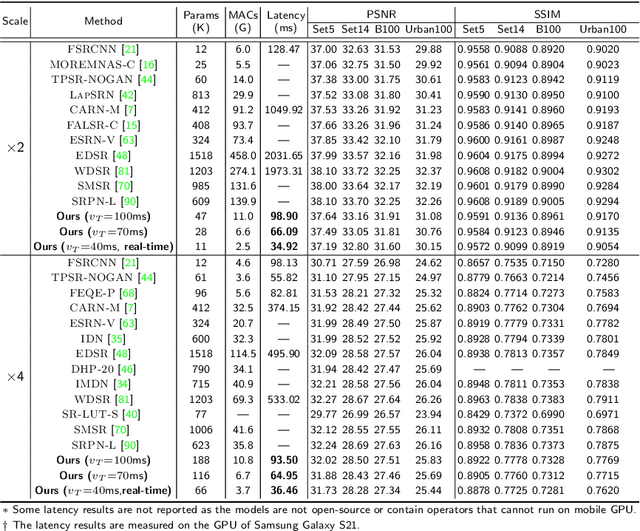
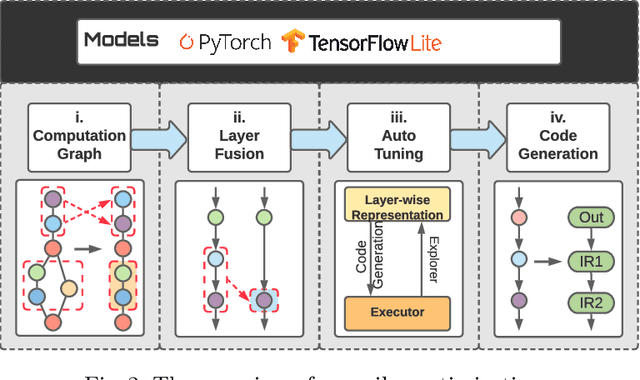
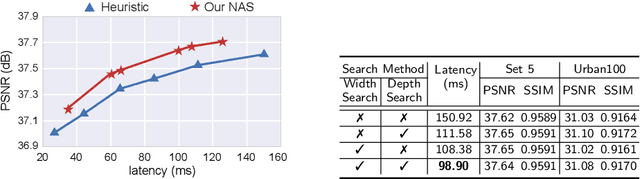
Deep learning-based super-resolution (SR) has gained tremendous popularity in recent years because of its high image quality performance and wide application scenarios. However, prior methods typically suffer from large amounts of computations and huge power consumption, causing difficulties for real-time inference, especially on resource-limited platforms such as mobile devices. To mitigate this, we propose a compiler-aware SR neural architecture search (NAS) framework that conducts depth search and per-layer width search with adaptive SR blocks. The inference speed is directly taken into the optimization along with the SR loss to derive SR models with high image quality while satisfying the real-time inference requirement. Instead of measuring the speed on mobile devices at each iteration during the search process, a speed model incorporated with compiler optimizations is leveraged to predict the inference latency of the SR block with various width configurations for faster convergence. With the proposed framework, we achieve real-time SR inference for implementing 720p resolution with competitive SR performance (in terms of PSNR and SSIM) on GPU/DSP of mobile platforms (Samsung Galaxy S21).
Quantum Neural Network Compression
Jul 05, 2022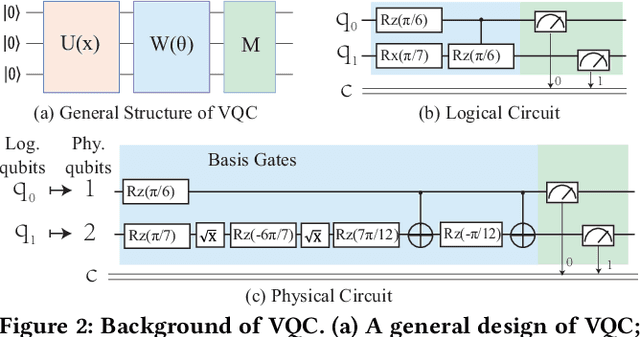
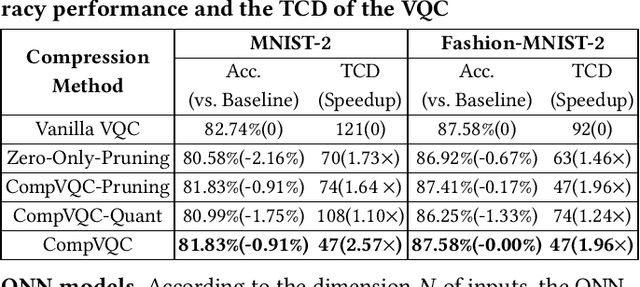
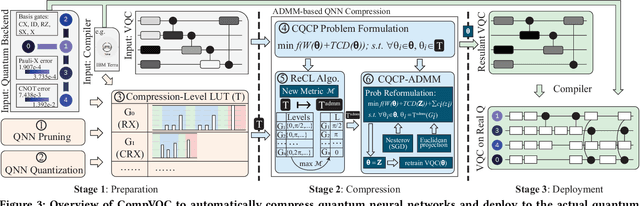
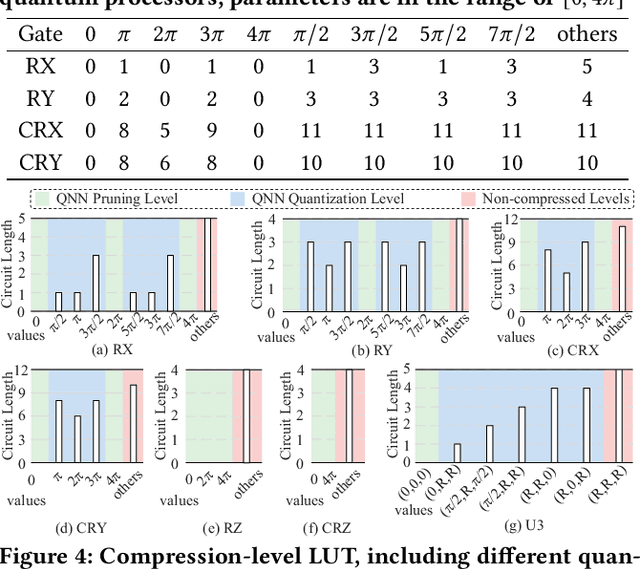
Model compression, such as pruning and quantization, has been widely applied to optimize neural networks on resource-limited classical devices. Recently, there are growing interest in variational quantum circuits (VQC), that is, a type of neural network on quantum computers (a.k.a., quantum neural networks). It is well known that the near-term quantum devices have high noise and limited resources (i.e., quantum bits, qubits); yet, how to compress quantum neural networks has not been thoroughly studied. One might think it is straightforward to apply the classical compression techniques to quantum scenarios. However, this paper reveals that there exist differences between the compression of quantum and classical neural networks. Based on our observations, we claim that the compilation/traspilation has to be involved in the compression process. On top of this, we propose the very first systematical framework, namely CompVQC, to compress quantum neural networks (QNNs).In CompVQC, the key component is a novel compression algorithm, which is based on the alternating direction method of multipliers (ADMM) approach. Experiments demonstrate the advantage of the CompVQC, reducing the circuit depth (almost over 2.5 %) with a negligible accuracy drop (<1%), which outperforms other competitors. Another promising truth is our CompVQC can indeed promote the robustness of the QNN on the near-term noisy quantum devices.
CoCoPIE XGen: A Full-Stack AI-Oriented Optimizing Framework
Jun 21, 2022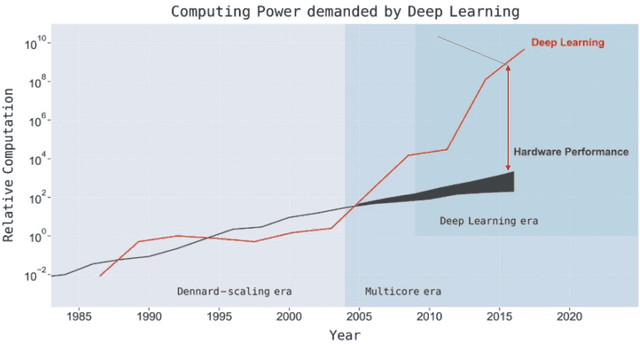
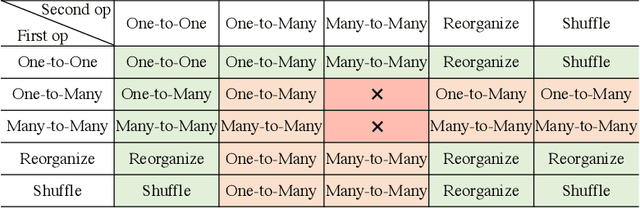
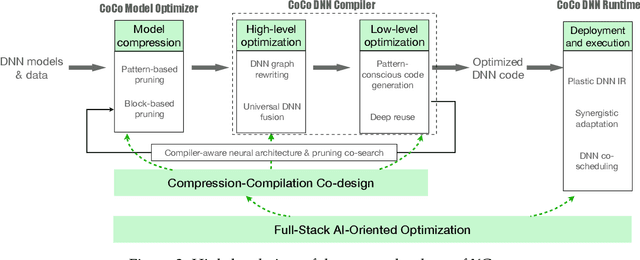

There is a growing demand for shifting the delivery of AI capability from data centers on the cloud to edge or end devices, exemplified by the fast emerging real-time AI-based apps running on smartphones, AR/VR devices, autonomous vehicles, and various IoT devices. The shift has however been seriously hampered by the large growing gap between DNN computing demands and the computing power on edge or end devices. This article presents the design of XGen, an optimizing framework for DNN designed to bridge the gap. XGen takes cross-cutting co-design as its first-order consideration. Its full-stack AI-oriented optimizations consist of a number of innovative optimizations at every layer of the DNN software stack, all designed in a cooperative manner. The unique technology makes XGen able to optimize various DNNs, including those with an extreme depth (e.g., BERT, GPT, other transformers), and generate code that runs several times faster than those from existing DNN frameworks, while delivering the same level of accuracy.
Real-Time Portrait Stylization on the Edge
Jun 02, 2022
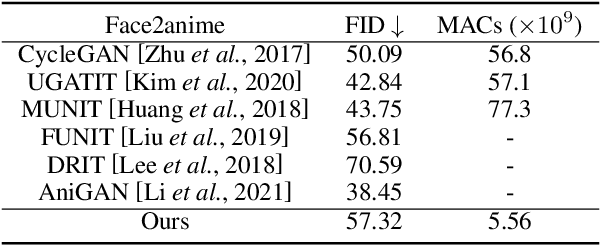


In this work we demonstrate real-time portrait stylization, specifically, translating self-portrait into cartoon or anime style on mobile devices. We propose a latency-driven differentiable architecture search method, maintaining realistic generative quality. With our framework, we obtain $10\times$ computation reduction on the generative model and achieve real-time video stylization on off-the-shelf smartphone using mobile GPUs.
Pruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
Jun 02, 2022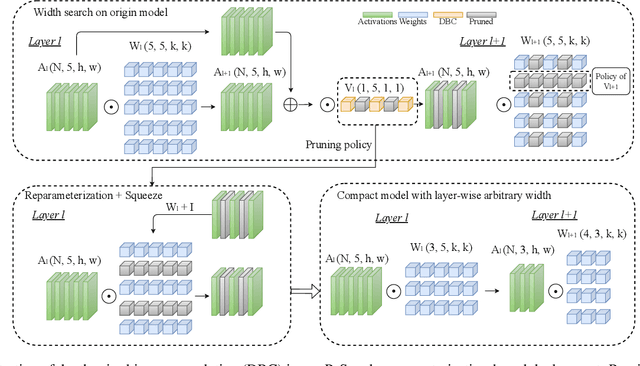
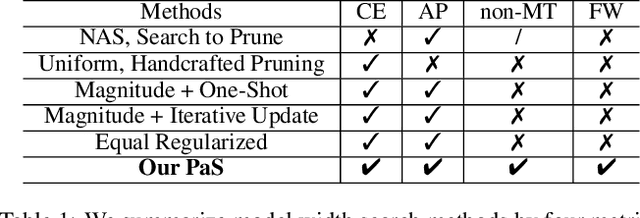

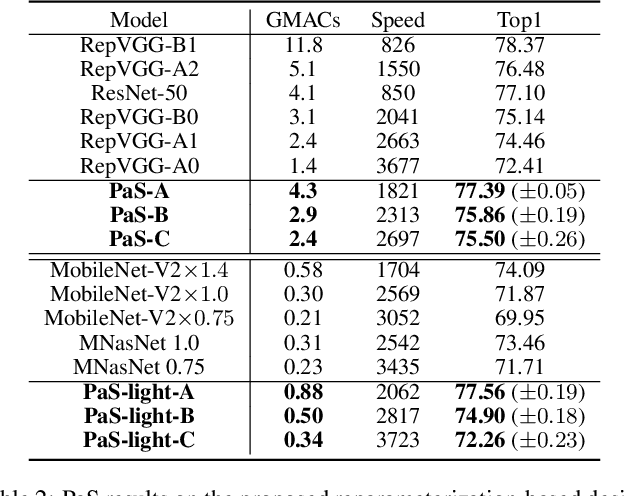
Neural architecture search (NAS) and network pruning are widely studied efficient AI techniques, but not yet perfect. NAS performs exhaustive candidate architecture search, incurring tremendous search cost. Though (structured) pruning can simply shrink model dimension, it remains unclear how to decide the per-layer sparsity automatically and optimally. In this work, we revisit the problem of layer-width optimization and propose Pruning-as-Search (PaS), an end-to-end channel pruning method to search out desired sub-network automatically and efficiently. Specifically, we add a depth-wise binary convolution to learn pruning policies directly through gradient descent. By combining the structural reparameterization and PaS, we successfully searched out a new family of VGG-like and lightweight networks, which enable the flexibility of arbitrary width with respect to each layer instead of each stage. Experimental results show that our proposed architecture outperforms prior arts by around $1.0\%$ top-1 accuracy under similar inference speed on ImageNet-1000 classification task. Furthermore, we demonstrate the effectiveness of our width search on complex tasks including instance segmentation and image translation. Code and models are released.
EfficientFormer: Vision Transformers at MobileNet Speed
Jun 02, 2022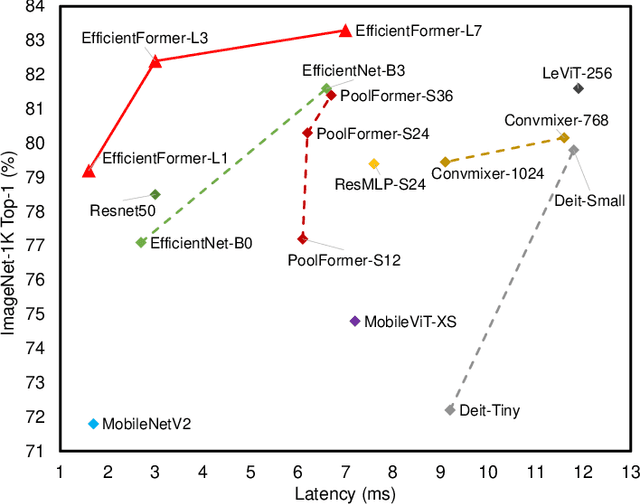
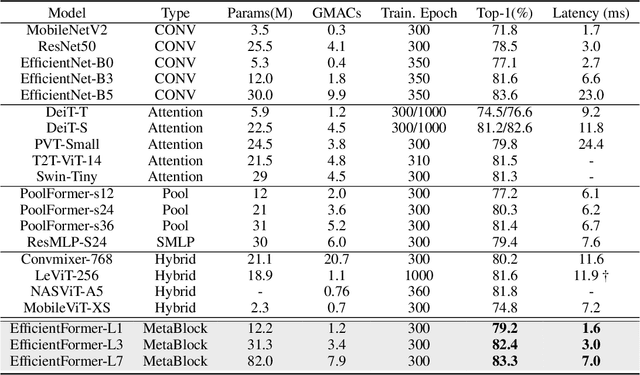
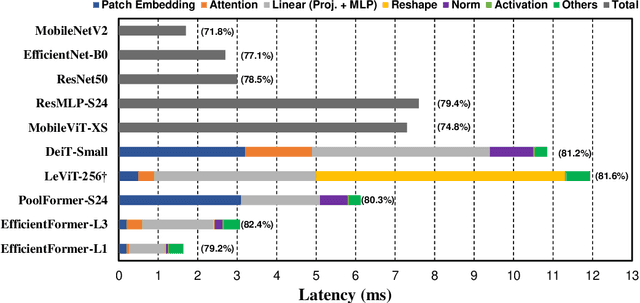
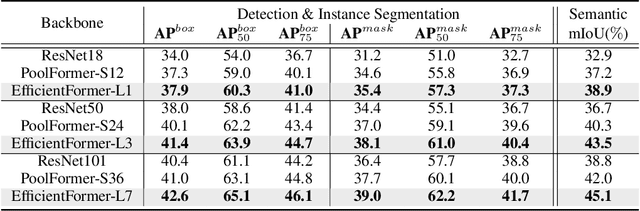
Vision Transformers (ViT) have shown rapid progress in computer vision tasks, achieving promising results on various benchmarks. However, due to the massive number of parameters and model design, e.g., attention mechanism, ViT-based models are generally times slower than lightweight convolutional networks. Therefore, the deployment of ViT for real-time applications is particularly challenging, especially on resource-constrained hardware such as mobile devices. Recent efforts try to reduce the computation complexity of ViT through network architecture search or hybrid design with MobileNet block, yet the inference speed is still unsatisfactory. This leads to an important question: can transformers run as fast as MobileNet while obtaining high performance? To answer this, we first revisit the network architecture and operators used in ViT-based models and identify inefficient designs. Then we introduce a dimension-consistent pure transformer (without MobileNet blocks) as design paradigm. Finally, we perform latency-driven slimming to get a series of final models dubbed EfficientFormer. Extensive experiments show the superiority of EfficientFormer in performance and speed on mobile devices. Our fastest model, EfficientFormer-L1, achieves 79.2% top-1 accuracy on ImageNet-1K with only 1.6 ms inference latency on iPhone 12 (compiled with CoreML), which is even a bit faster than MobileNetV2 (1.7 ms, 71.8% top-1), and our largest model, EfficientFormer-L7, obtains 83.3% accuracy with only 7.0 ms latency. Our work proves that properly designed transformers can reach extremely low latency on mobile devices while maintaining high performance
Neural Network-based OFDM Receiver for Resource Constrained IoT Devices
May 12, 2022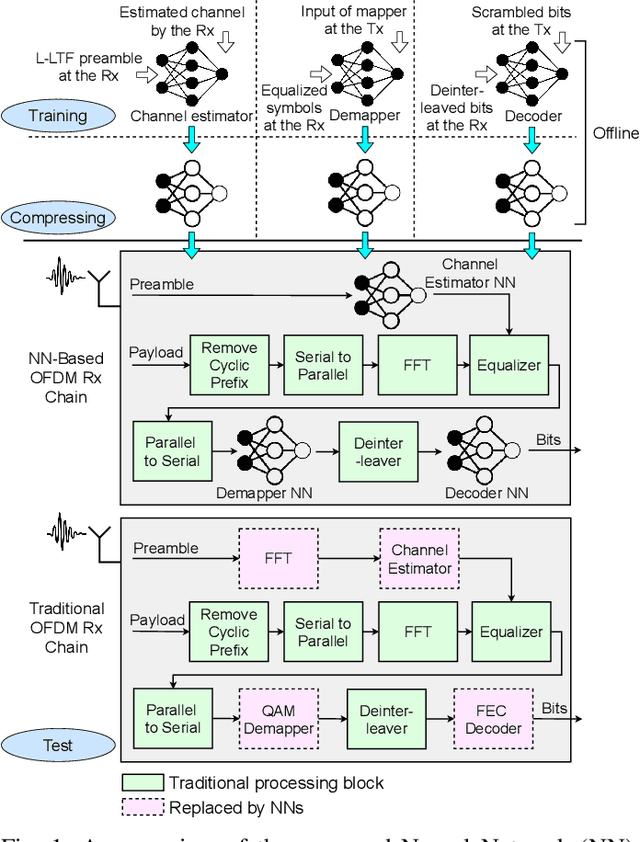
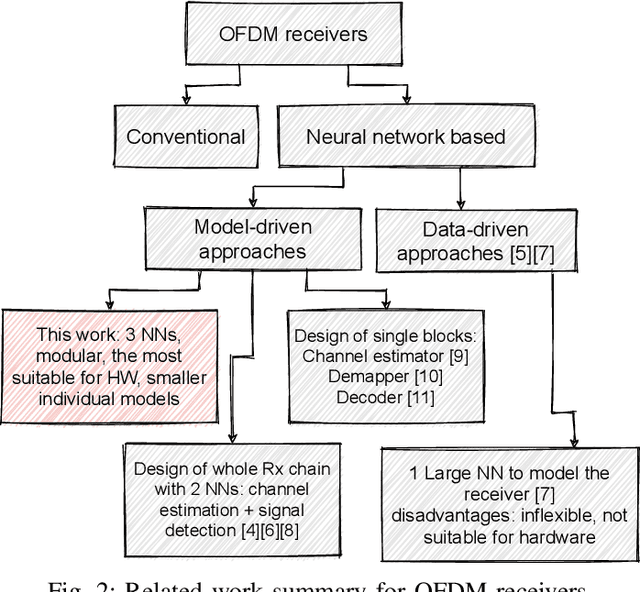
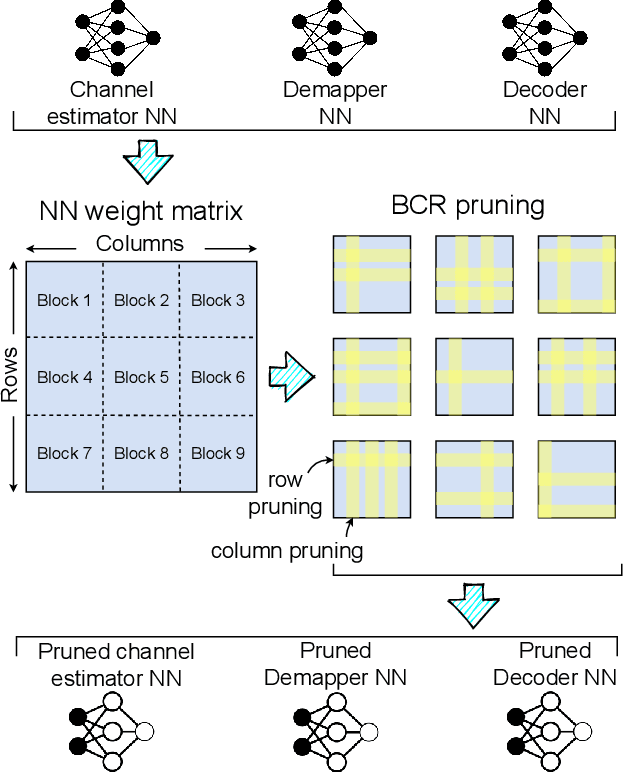
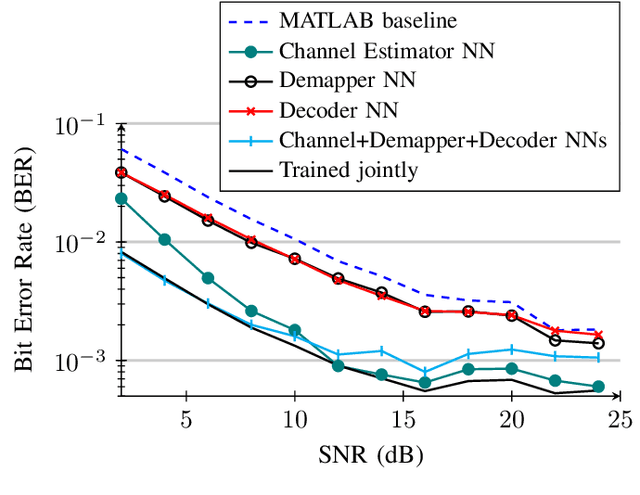
Orthogonal Frequency Division Multiplexing (OFDM)-based waveforms are used for communication links in many current and emerging Internet of Things (IoT) applications, including the latest WiFi standards. For such OFDM-based transceivers, many core physical layer functions related to channel estimation, demapping, and decoding are implemented for specific choices of channel types and modulation schemes, among others. To decouple hard-wired choices from the receiver chain and thereby enhance the flexibility of IoT deployment in many novel scenarios without changing the underlying hardware, we explore a novel, modular Machine Learning (ML)-based receiver chain design. Here, ML blocks replace the individual processing blocks of an OFDM receiver, and we specifically describe this swapping for the legacy channel estimation, symbol demapping, and decoding blocks with Neural Networks (NNs). A unique aspect of this modular design is providing flexible allocation of processing functions to the legacy or ML blocks, allowing them to interchangeably coexist. Furthermore, we study the implementation cost-benefits of the proposed NNs in resource-constrained IoT devices through pruning and quantization, as well as emulation of these compressed NNs within Field Programmable Gate Arrays (FPGAs). Our evaluations demonstrate that the proposed modular NN-based receiver improves bit error rate of the traditional non-ML receiver by averagely 61% and 10% for the simulated and over-the-air datasets, respectively. We further show complexity-performance tradeoffs by presenting computational complexity comparisons between the traditional algorithms and the proposed compressed NNs.
Deep neural network goes lighter: A case study of deep compression techniques on automatic RF modulation recognition for Beyond 5G networks
Apr 09, 2022
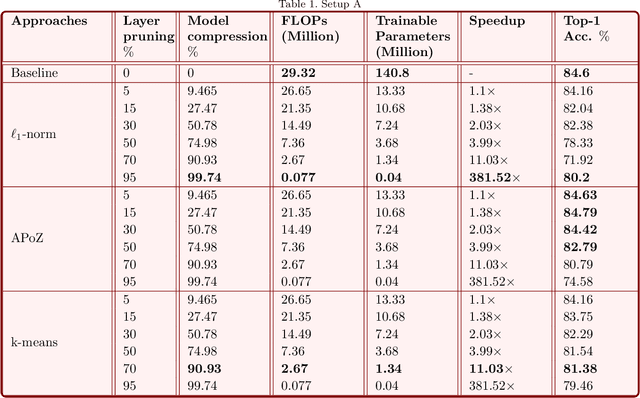
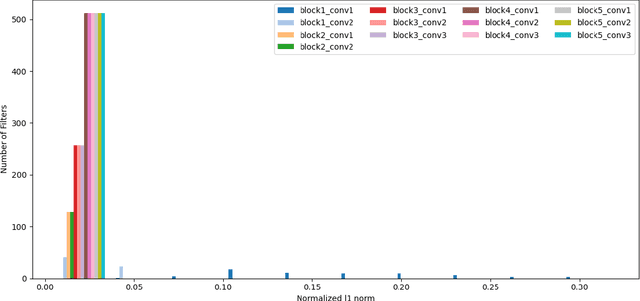
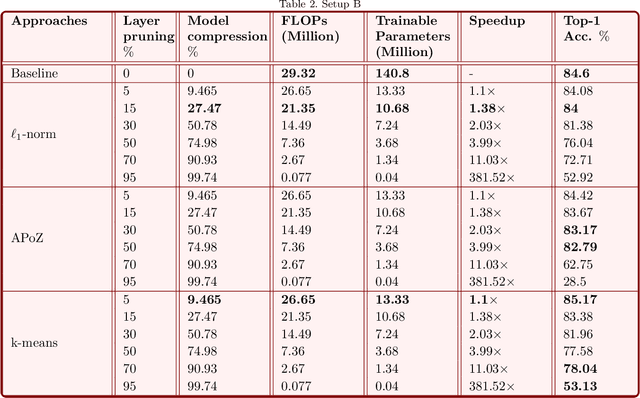
Automatic RF modulation recognition is a primary signal intelligence (SIGINT) technique that serves as a physical layer authentication enabler and automated signal processing scheme for the beyond 5G and military networks. Most existing works rely on adopting deep neural network architectures to enable RF modulation recognition. The application of deep compression for the wireless domain, especially automatic RF modulation classification, is still in its infancy. Lightweight neural networks are key to sustain edge computation capability on resource-constrained platforms. In this letter, we provide an in-depth view of the state-of-the-art deep compression and acceleration techniques with an emphasis on edge deployment for beyond 5G networks. Finally, we present an extensive analysis of the representative acceleration approaches as a case study on automatic radar modulation classification and evaluate them in terms of the computational metrics.