 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SSL Interplay: Augmentations, Inductive Bias, and Generalization
Feb 06, 2023



Self-supervised learning (SSL) has emerged as a powerful framework to learn representations from raw data without supervision. Yet in practice, engineers face issues such as instability in tuning optimizers and collapse of representations during training. Such challenges motivate the need for a theory to shed light on the complex interplay between the choice of data augmentation, network architecture, and training algorithm. We study such an interplay with a precise analysis of generalization performance on both pretraining and downstream tasks in a theory friendly setup, and highlight several insights for SSL practitioners that arise from our theory.
Blockwise Self-Supervised Learning at Scale
Feb 03, 2023Current state-of-the-art deep networks are all powered by backpropagation. In this paper, we explore alternatives to full backpropagation in the form of blockwise learning rules, leveraging the latest developments in self-supervised learning. We show that a blockwise pretraining procedure consisting of training independently the 4 main blocks of layers of a ResNet-50 with Barlow Twins' loss function at each block performs almost as well as end-to-end backpropagation on ImageNet: a linear probe trained on top of our blockwise pretrained model obtains a top-1 classification accuracy of 70.48%, only 1.1% below the accuracy of an end-to-end pretrained network (71.57% accuracy). We perform extensive experiments to understand the impact of different components within our method and explore a variety of adaptations of self-supervised learning to the blockwise paradigm, building an exhaustive understanding of the critical avenues for scaling local learning rules to large networks, with implications ranging from hardware design to neuroscience.
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Jan 19, 2023



This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervised learning from images. The idea behind I-JEPA is simple: from a single context block, predict the representations of various target blocks in the same image. A core design choice to guide I-JEPA towards producing semantic representations is the masking strategy; specifically, it is crucial to (a) predict several target blocks in the image, (b) sample target blocks with sufficiently large scale (occupying 15%-20% of the image), and (c) use a sufficiently informative (spatially distributed) context block. Empirically, when combined with Vision Transformers, we find I-JEPA to be highly scalable. For instance, we train a ViT-Huge/16 on ImageNet using 32 A100 GPUs in under 38 hours to achieve strong downstream performance across a wide range of tasks requiring various levels of abstraction, from linear classification to object counting and depth prediction.
A Generalization of ViT/MLP-Mixer to Graphs
Dec 27, 2022



Graph Neural Networks (GNNs) have shown great potential in the field of graph representation learning. Standard GNNs define a local message-passing mechanism which propagates information over the whole graph domain by stacking multiple layers. This paradigm suffers from two major limitations, over-squashing and poor long-range dependencies, that can be solved using global attention but significantly increases the computational cost to quadratic complexity. In this work, we propose an alternative approach to overcome these structural limitations by leveraging the ViT/MLP-Mixer architectures introduced in computer vision. We introduce a new class of GNNs, called Graph MLP-Mixer, that holds three key properties. First, they capture long-range dependency and mitigate the issue of over-squashing as demonstrated on the Long Range Graph Benchmark (LRGB) and the TreeNeighbourMatch datasets. Second, they offer better speed and memory efficiency with a complexity linear to the number of nodes and edges, surpassing the related Graph Transformer and expressive GNN models. Third, they show high expressivity in terms of graph isomorphism as they can distinguish at least 3-WL non-isomorphic graphs. We test our architecture on 4 simulated datasets and 7 real-world benchmarks, and show highly competitive results on all of them.
Joint Embedding Predictive Architectures Focus on Slow Features
Nov 20, 2022



Many common methods for learning a world model for pixel-based environments use generative architectures trained with pixel-level reconstruction objectives. Recently proposed Joint Embedding Predictive Architectures (JEPA) offer a reconstruction-free alternative. In this work, we analyze performance of JEPA trained with VICReg and SimCLR objectives in the fully offline setting without access to rewards, and compare the results to the performance of the generative architecture. We test the methods in a simple environment with a moving dot with various background distractors, and probe learned representations for the dot's location. We find that JEPA methods perform on par or better than reconstruction when distractor noise changes every time step, but fail when the noise is fixed. Furthermore, we provide a theoretical explanation for the poor performance of JEPA-based methods with fixed noise, highlighting an important limitation.
POLICE: Provably Optimal Linear Constraint Enforcement for Deep Neural Networks
Nov 07, 2022



Deep Neural Networks (DNNs) outshine alternative function approximators in many settings thanks to their modularity in composing any desired differentiable operator. The formed parametrized functional is then tuned to solve a task at hand from simple gradient descent. This modularity comes at the cost of making strict enforcement of constraints on DNNs, e.g. from a priori knowledge of the task, or from desired physical properties, an open challenge. In this paper we propose the first provable affine constraint enforcement method for DNNs that requires minimal changes into a given DNN's forward-pass, that is computationally friendly, and that leaves the optimization of the DNN's parameter to be unconstrained i.e. standard gradient-based method can be employed. Our method does not require any sampling and provably ensures that the DNN fulfills the affine constraint on a given input space's region at any point during training, and testing. We coin this method POLICE, standing for Provably Optimal LInear Constraint Enforcement.
Unsupervised Learning of Structured Representations via Closed-Loop Transcription
Oct 30, 2022



This paper proposes an unsupervised method for learning a unified representation that serves both discriminative and generative purposes. While most existing unsupervised learning approaches focus on a representation for only one of these two goals, we show that a unified representation can enjoy the mutual benefits of having both. Such a representation is attainable by generalizing the recently proposed \textit{closed-loop transcription} framework, known as CTRL, to the unsupervised setting. This entails solving a constrained maximin game over a rate reduction objective that expands features of all samples while compressing features of augmentations of each sample. Through this process, we see discriminative low-dimensional structures emerge in the resulting representations. Under comparable experimental conditions and network complexities, we demonstrate that these structured representations enable classification performance close to state-of-the-art unsupervised discriminative representations, and conditionally generated image quality significantly higher than that of state-of-the-art unsupervised generative models. Source code can be found at https://github.com/Delay-Xili/uCTRL.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment
Oct 09, 2022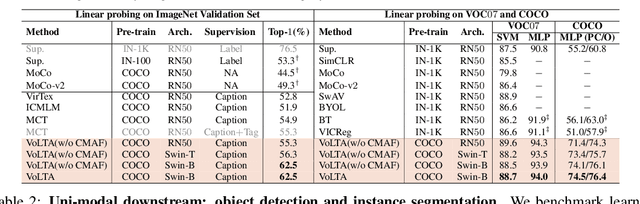
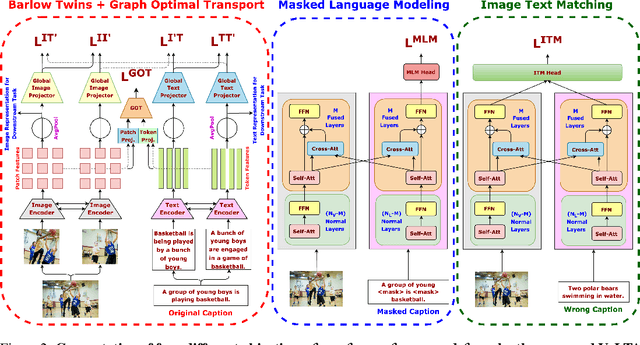
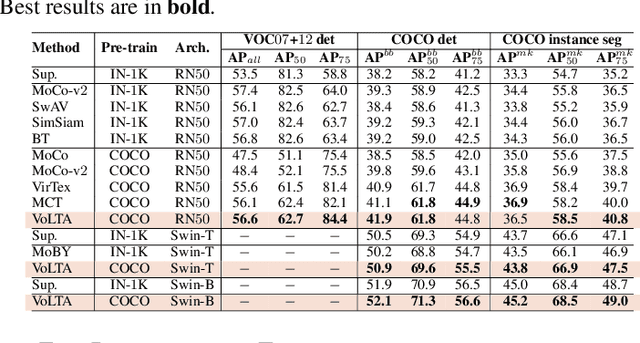

Vision-language pre-training (VLP) has recently proven highly effective for various uni- and multi-modal downstream applications. However, most existing end-to-end VLP methods use high-resolution image-text box data to perform well on fine-grained region-level tasks, such as object detection, segmentation, and referring expression comprehension. Unfortunately, such high-resolution images with accurate bounding box annotations are expensive to collect and use for supervision at scale. In this work, we propose VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new VLP paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the use of expensive box annotations. VoLTA adopts graph optimal transport-based weakly-supervised alignment on local image patches and text tokens to germinate an explicit, self-normalized, and interpretable low-level matching criterion. In addition, VoLTA pushes multi-modal fusion deep into the uni-modal backbones during pre-training and removes fusion-specific transformer layers, further reducing memory requirements. Extensive experiments on a wide range of vision- and vision-language downstream tasks demonstrate the effectiveness of VoLTA on fine-grained applications without compromising the coarse-grained downstream performance, often outperforming methods using significantly more caption and box annotations.
VICRegL: Self-Supervised Learning of Local Visual Features
Oct 04, 2022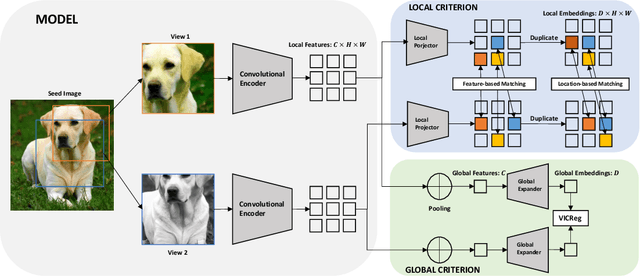
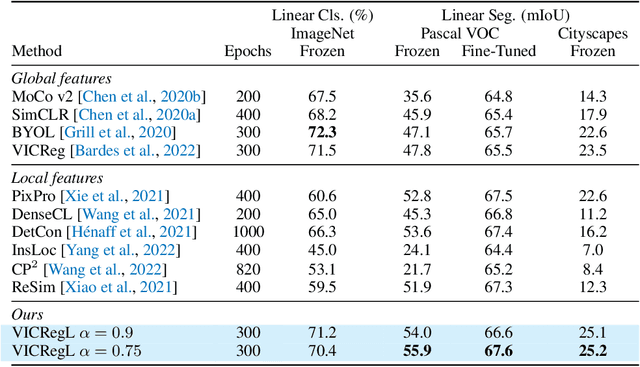
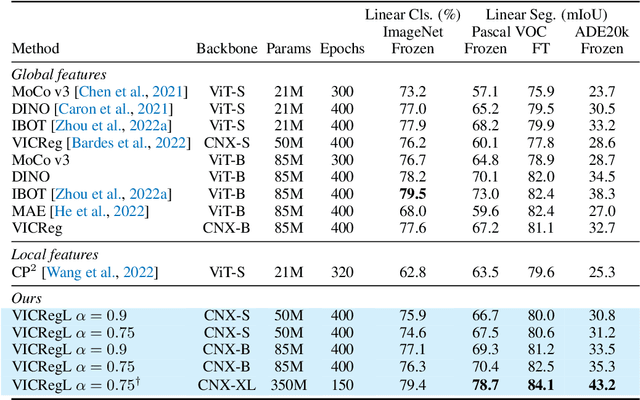
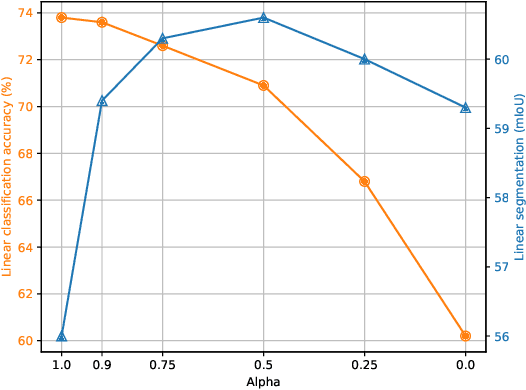
Most recent self-supervised methods for learning image representations focus on either producing a global feature with invariance properties, or producing a set of local features. The former works best for classification tasks while the latter is best for detection and segmentation tasks. This paper explores the fundamental trade-off between learning local and global features. A new method called VICRegL is proposed that learns good global and local features simultaneously, yielding excellent performance on detection and segmentation tasks while maintaining good performance on classification tasks. Concretely, two identical branches of a standard convolutional net architecture are fed two differently distorted versions of the same image. The VICReg criterion is applied to pairs of global feature vectors. Simultaneously, the VICReg criterion is applied to pairs of local feature vectors occurring before the last pooling layer. Two local feature vectors are attracted to each other if their l2-distance is below a threshold or if their relative locations are consistent with a known geometric transformation between the two input images. We demonstrate strong performance on linear classification and segmentation transfer tasks. Code and pretrained models are publicly available at: https://github.com/facebookresearch/VICRegL