 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbing Inputs for Fragile Interpretations in Deep Natural Language Processing
Aug 11, 2021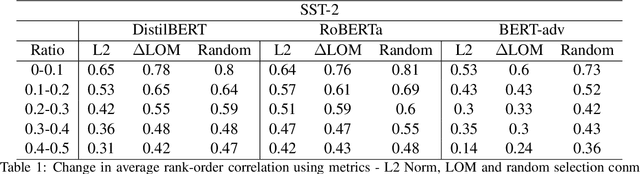
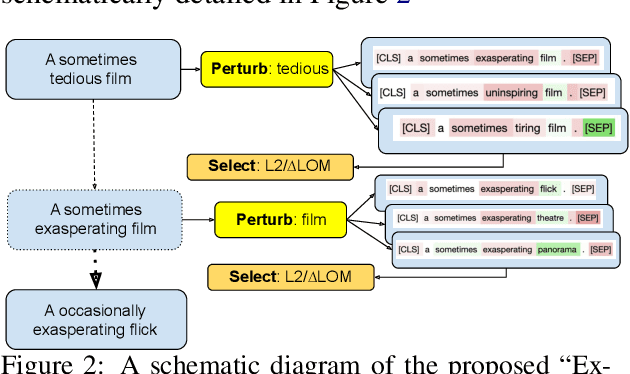
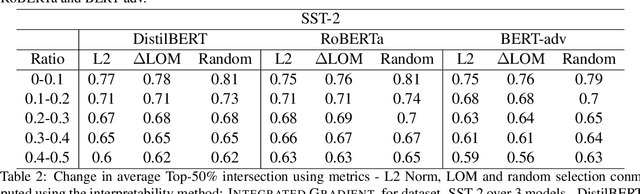
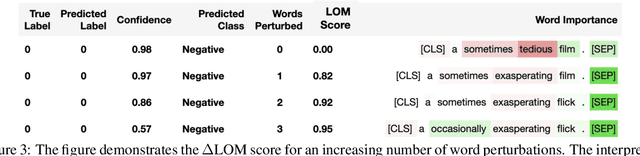
Interpretability methods like Integrated Gradient and LIME are popular choices for explaining natural language model predictions with relative word importance scores. These interpretations need to be robust for trustworthy NLP applications in high-stake areas like medicine or finance. Our paper demonstrates how interpretations can be manipulated by making simple word perturbations on an input text. Via a small portion of word-level swaps, these adversarial perturbations aim to make the resulting text semantically and spatially similar to its seed input (therefore sharing similar interpretations). Simultaneously, the generated examples achieve the same prediction label as the seed yet are given a substantially different explanation by the interpretation methods. Our experiments generate fragile interpretations to attack two SOTA interpretation methods, across three popular Transformer models and on two different NLP datasets. We observe that the rank order correlation drops by over 20% when less than 10% of words are perturbed on average. Further, rank-order correlation keeps decreasing as more words get perturbed. Furthermore, we demonstrate that candidates generated from our method have good quality metrics.
Explaining Neural Network Predictions on Sentence Pairs via Learning Word-Group Masks
Apr 13, 2021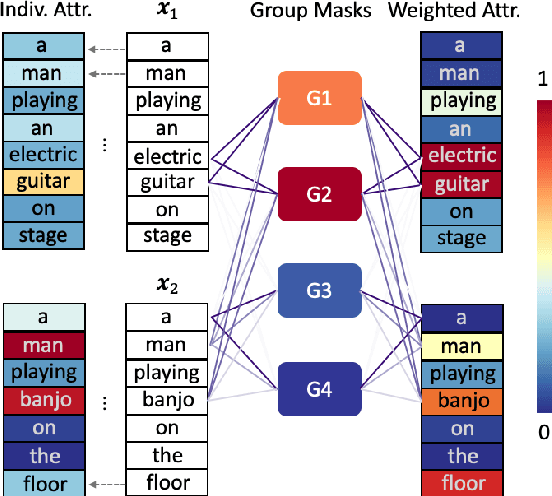
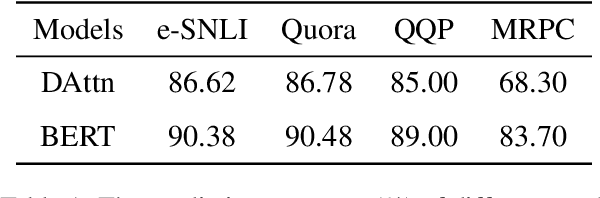
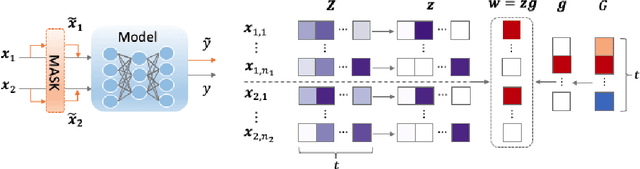
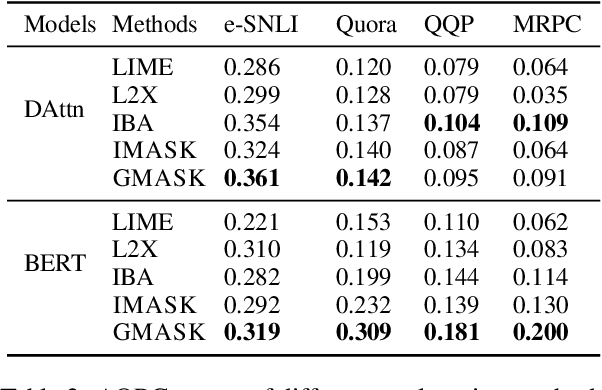
Explaining neural network models is important for increasing their trustworthiness in real-world applications. Most existing methods generate post-hoc explanations for neural network models by identifying individual feature attributions or detecting interactions between adjacent features. However, for models with text pairs as inputs (e.g., paraphrase identification), existing methods are not sufficient to capture feature interactions between two texts and their simple extension of computing all word-pair interactions between two texts is computationally inefficient. In this work, we propose the Group Mask (GMASK) method to implicitly detect word correlations by grouping correlated words from the input text pair together and measure their contribution to the corresponding NLP tasks as a whole. The proposed method is evaluated with two different model architectures (decomposable attention model and BERT) across four datasets, including natural language inference and paraphrase identification tasks. Experiments show the effectiveness of GMASK in providing faithful explanations to these models.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Finding Friends and Flipping Frenemies: Automatic Paraphrase Dataset Augmentation Using Graph Theory
Nov 03, 2020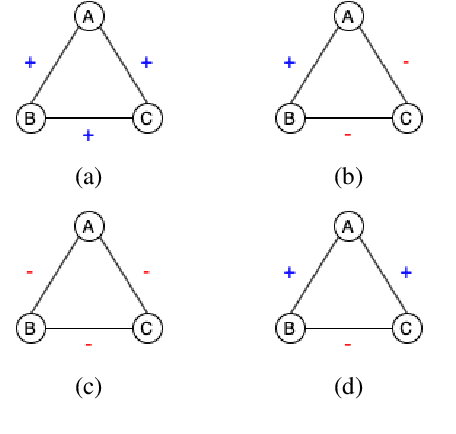
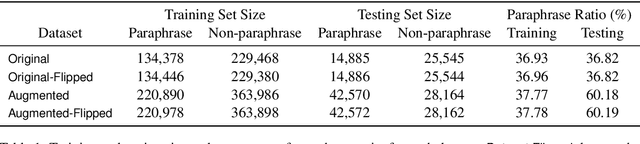
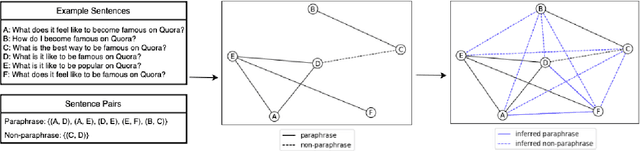
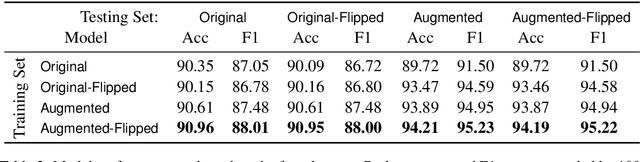
Most NLP datasets are manually labeled, so suffer from inconsistent labeling or limited size. We propose methods for automatically improving datasets by viewing them as graphs with expected semantic properties. We construct a paraphrase graph from the provided sentence pair labels, and create an augmented dataset by directly inferring labels from the original sentence pairs using a transitivity property. We use structural balance theory to identify likely mislabelings in the graph, and flip their labels. We evaluate our methods on paraphrase models trained using these datasets starting from a pretrained BERT model, and find that the automatically-enhanced training sets result in more accurate models.
Learning Variational Word Masks to Improve the Interpretability of Neural Text Classifiers
Oct 01, 2020
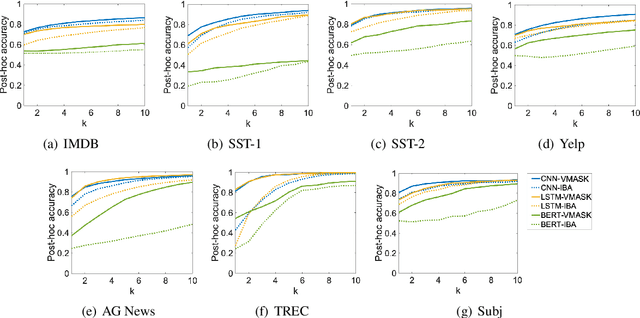
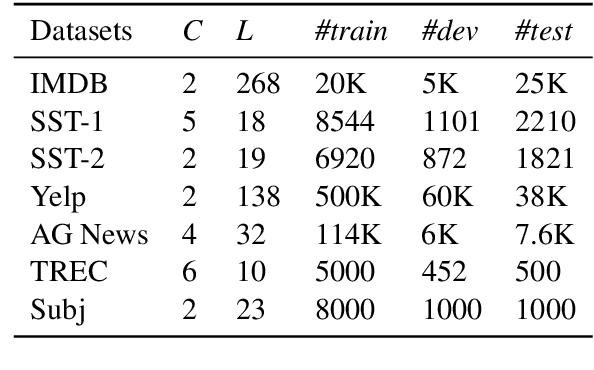
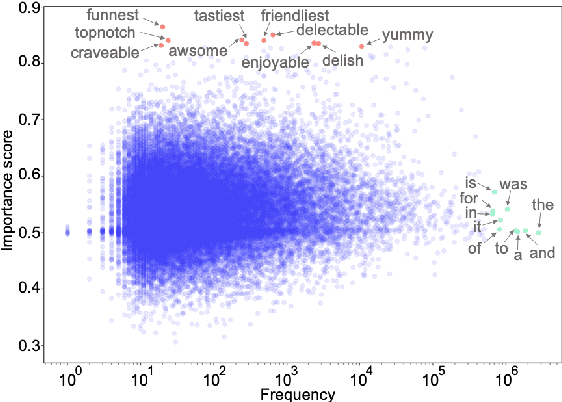
To build an interpretable neural text classifier, most of the prior work has focused on designing inherently interpretable models or finding faithful explanations. A new line of work on improving model interpretability has just started, and many existing methods require either prior information or human annotations as additional inputs in training. To address this limitation, we propose the variational word mask (VMASK) method to automatically learn task-specific important words and reduce irrelevant information on classification, which ultimately improves the interpretability of model predictions. The proposed method is evaluated with three neural text classifiers (CNN, LSTM, and BERT) on seven benchmark text classification datasets. Experiments show the effectiveness of VMASK in improving both model prediction accuracy and interpretability.
A Tale of Two Linkings: Dynamically Gating between Schema Linking and Structural Linking for Text-to-SQL Parsing
Sep 30, 2020
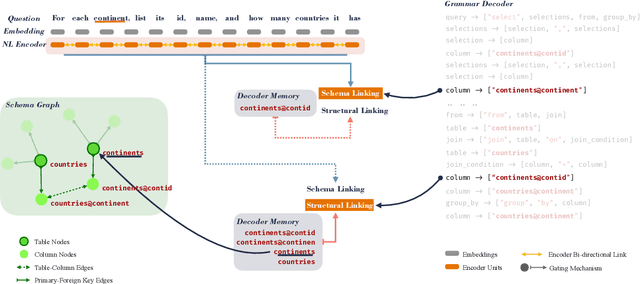
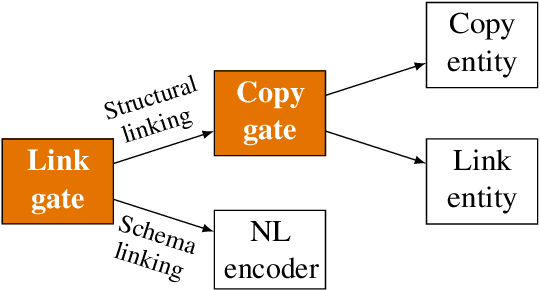

In Text-to-SQL semantic parsing, selecting the correct entities (tables and columns) to output is both crucial and challenging; the parser is required to connect the natural language (NL) question and the current SQL prediction with the structured world, i.e., the database. We formulate two linking processes to address this challenge: schema linking which links explicit NL mentions to the database and structural linking which links the entities in the output SQL with their structural relationships in the database schema. Intuitively, the effects of these two linking processes change based on the entity being generated, thus we propose to dynamically choose between them using a gating mechanism. Integrating the proposed method with two graph neural network based semantic parsers together with BERT representations demonstrates substantial gains in parsing accuracy on the challenging Spider dataset. Analyses show that our method helps to enhance the structure of the model output when generating complicated SQL queries and offers explainable predictions.
HittER: Hierarchical Transformers for Knowledge Graph Embeddings
Aug 28, 2020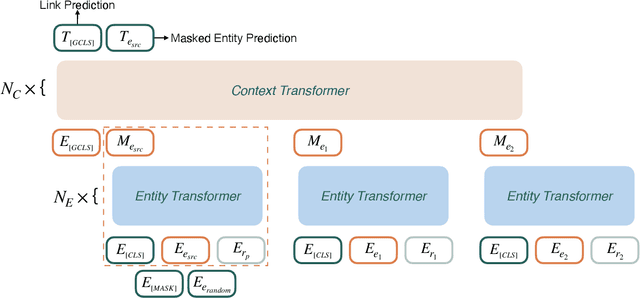
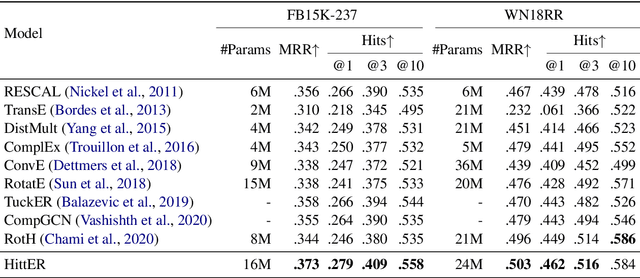
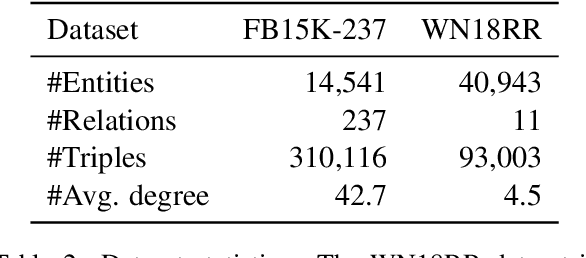

This paper examines the challenging problem of learning representations of entities and relations in a complex multi-relational knowledge graph. We propose HittER, a Hierarchical Transformer model to jointly learn Entity-relation composition and Relational contextualization based on a source entity's neighborhood. Our proposed model consists of two different Transformer blocks: the bottom block extracts features of each entity-relation pair in the local neighborhood of the source entity and the top block aggregates the relational information from the outputs of the bottom block. We further design a masked entity prediction task to balance information from the relational context and the source entity itself. Evaluated on the task of link prediction, our approach achieves new state-of-the-art results on two standard benchmark datasets FB15K-237 and WN18RR.
Pointwise Paraphrase Appraisal is Potentially Problematic
Jun 05, 2020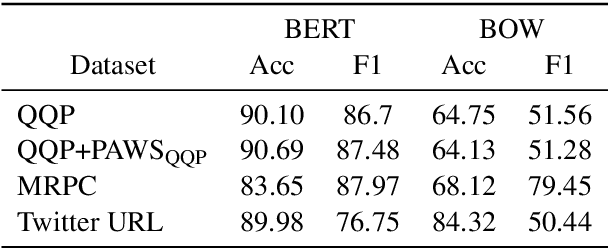
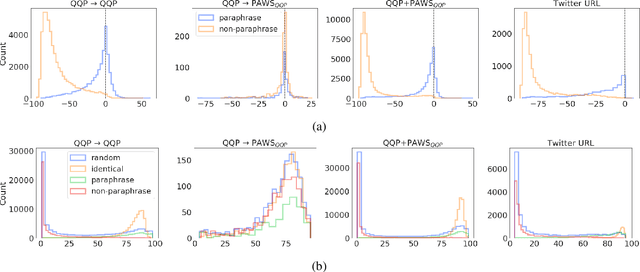
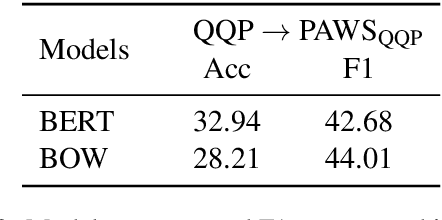
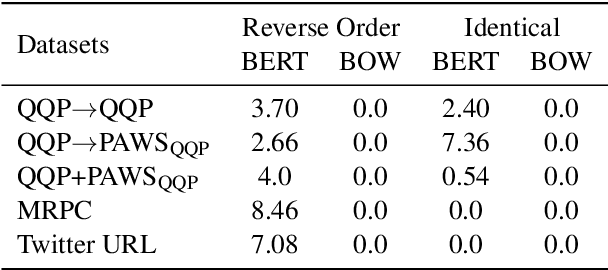
The prevailing approach for training and evaluating paraphrase identification models is constructed as a binary classification problem: the model is given a pair of sentences, and is judged by how accurately it classifies pairs as either paraphrases or non-paraphrases. This pointwise-based evaluation method does not match well the objective of most real world applications, so the goal of our work is to understand how models which perform well under pointwise evaluation may fail in practice and find better methods for evaluating paraphrase identification models. As a first step towards that goal, we show that although the standard way of fine-tuning BERT for paraphrase identification by pairing two sentences as one sequence results in a model with state-of-the-art performance, that model may perform poorly on simple tasks like identifying pairs with two identical sentences. Moreover, we show that these models may even predict a pair of randomly-selected sentences with higher paraphrase score than a pair of identical ones.
Reevaluating Adversarial Examples in Natural Language
Apr 25, 2020
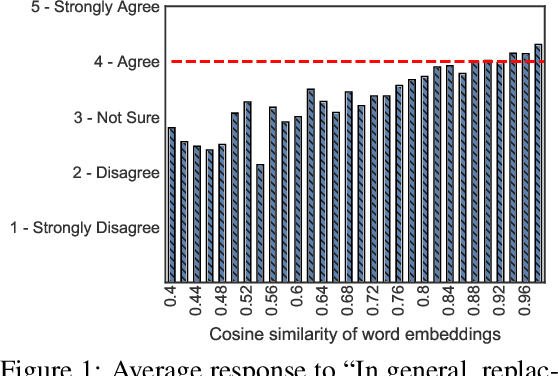
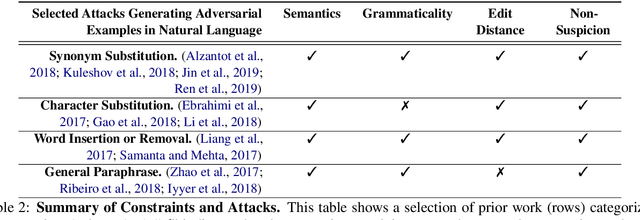
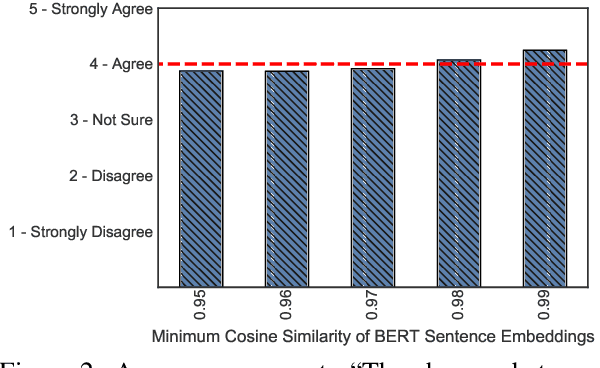
State-of-the-art attacks on NLP models have different definitions of what constitutes a successful attack. These differences make the attacks difficult to compare. We propose to standardize definitions of natural language adversarial examples based on a set of linguistic constraints: semantics, grammaticality, edit distance, and non-suspicion. We categorize previous attacks based on these constraints. For each constraint, we suggest options for human and automatic evaluation methods. We use these methods to evaluate two state-of-the-art synonym substitution attacks. We find that perturbations often do not preserve semantics, and 45\% introduce grammatical errors. Next, we conduct human studies to find a threshold for each evaluation method that aligns with human judgment. Human surveys reveal that to truly preserve semantics, we need to significantly increase the minimum cosine similarity between the embeddings of swapped words and sentence encodings of original and perturbed inputs. After tightening these constraints to agree with the judgment of our human annotators, the attacks produce valid, successful adversarial examples. But quality comes at a cost: attack success rate drops by over 70 percentage points. Finally, we introduce TextAttack, a library for adversarial attacks in NLP.
Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
Apr 04, 2020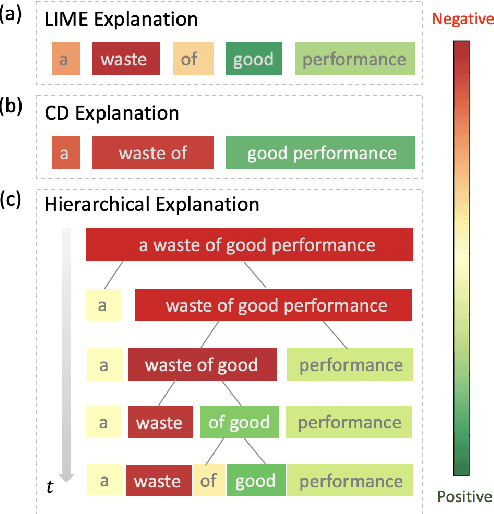
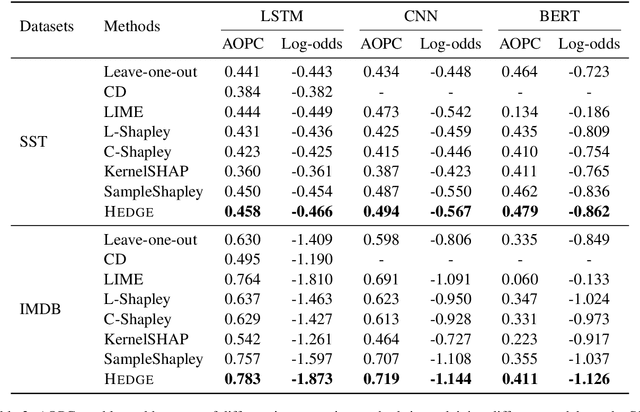
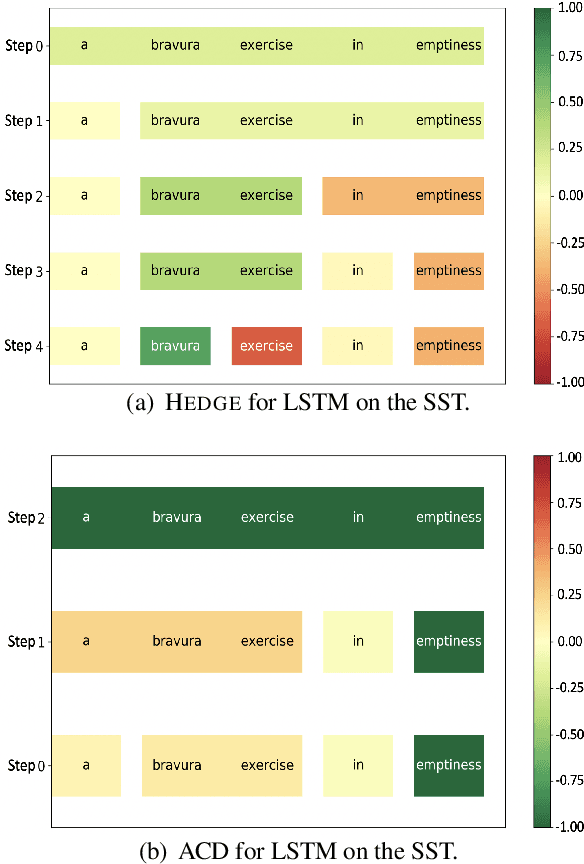
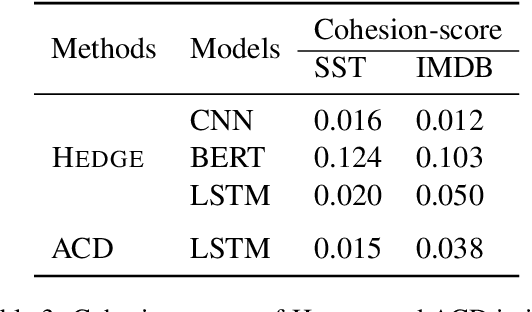
Generating explanations for neural networks has become crucial for their applications in real-world with respect to reliability and trustworthiness. In natural language processing, existing methods usually provide important features which are words or phrases selected from an input text as an explanation, but ignore the interactions between them. It poses challenges for humans to interpret an explanation and connect it to model prediction. In this work, we build hierarchical explanations by detecting feature interactions. Such explanations visualize how words and phrases are combined at different levels of the hierarchy, which can help users understand the decision-making of black-box models. The proposed method is evaluated with three neural text classifiers (LSTM, CNN, and BERT) on two benchmark datasets, via both automatic and human evaluations. Experiments show the effectiveness of the proposed method in providing explanations that are both faithful to models and interpretable to humans.