 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Spuriousness-Aware Guided Prompt Exploration for Mitigating Multimodal Bias
Nov 17, 2025Large vision-language models, such as CLIP, have shown strong zero-shot classification performance by aligning images and text in a shared embedding space. However, CLIP models often develop multimodal spurious biases, which is the undesirable tendency to rely on spurious features. For example, CLIP may infer object types in images based on frequently co-occurring backgrounds rather than the object's core features. This bias significantly impairs the robustness of pre-trained CLIP models on out-of-distribution data, where such cross-modal associations no longer hold. Existing methods for mitigating multimodal spurious bias typically require fine-tuning on downstream data or prior knowledge of the bias, which undermines the out-of-the-box usability of CLIP. In this paper, we first theoretically analyze the impact of multimodal spurious bias in zero-shot classification. Based on this insight, we propose Spuriousness-Aware Guided Exploration (SAGE), a simple and effective method that mitigates spurious bias through guided prompt selection. SAGE requires no training, fine-tuning, or external annotations. It explores a space of prompt templates and selects the prompts that induce the largest semantic separation between classes, thereby improving worst-group robustness. Extensive experiments on four real-world benchmark datasets and five popular backbone models demonstrate that SAGE consistently improves zero-shot performance and generalization, outperforming previous zero-shot approaches without any external knowledge or model updates.
Rectifying Shortcut Behaviors in Preference-based Reward Learning
Oct 21, 2025In reinforcement learning from human feedback, preference-based reward models play a central role in aligning large language models to human-aligned behavior. However, recent studies show that these models are prone to reward hacking and often fail to generalize well due to over-optimization. They achieve high reward scores by exploiting shortcuts, that is, exploiting spurious features (e.g., response verbosity, agreeable tone, or sycophancy) that correlate with human preference labels in the training data rather than genuinely reflecting the intended objectives. In this paper, instead of probing these issues one at a time, we take a broader view of the reward hacking problem as shortcut behaviors and introduce a principled yet flexible approach to mitigate shortcut behaviors in preference-based reward learning. Inspired by the invariant theory in the kernel perspective, we propose Preference-based Reward Invariance for Shortcut Mitigation (PRISM), which learns group-invariant kernels with feature maps in a closed-form learning objective. Experimental results in several benchmarks show that our method consistently improves the accuracy of the reward model on diverse out-of-distribution tasks and reduces the dependency on shortcuts in downstream policy models, establishing a robust framework for preference-based alignment.
NeuronTune: Towards Self-Guided Spurious Bias Mitigation
May 29, 2025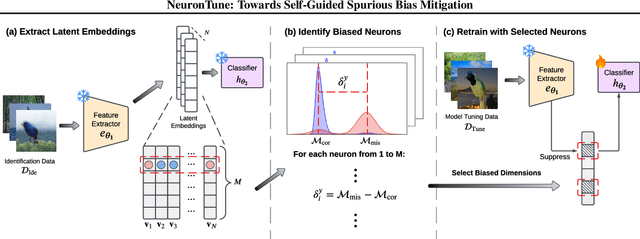
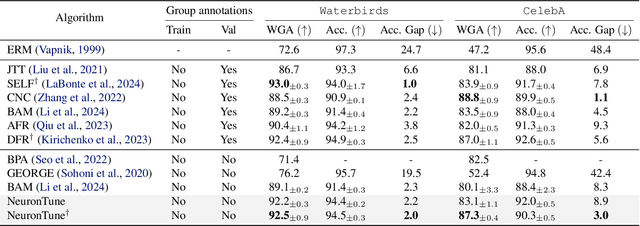
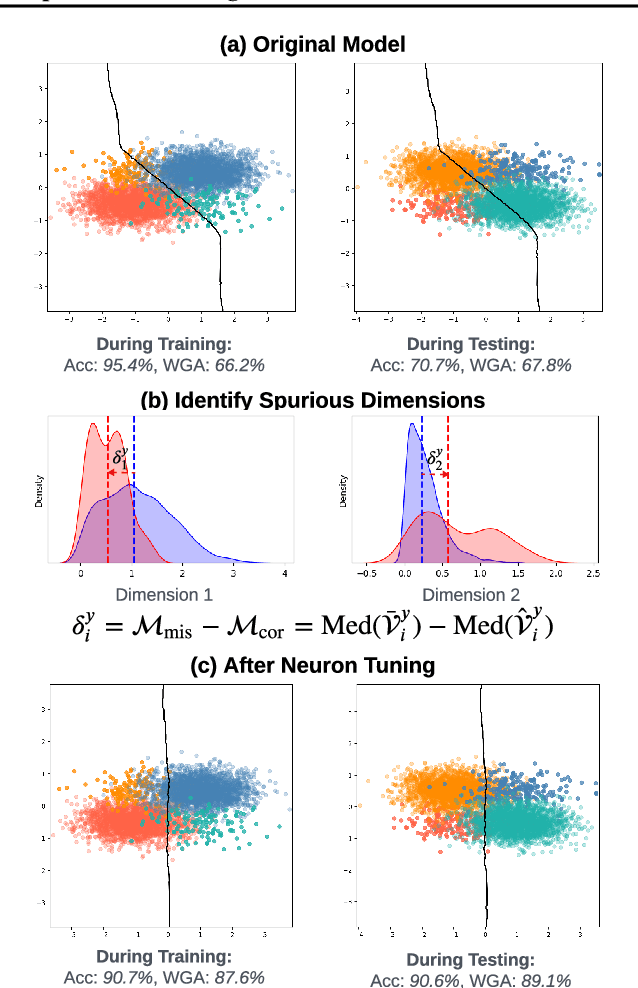
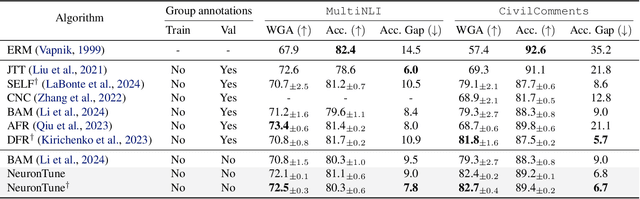
Deep neural networks often develop spurious bias, reliance on correlations between non-essential features and classes for predictions. For example, a model may identify objects based on frequently co-occurring backgrounds rather than intrinsic features, resulting in degraded performance on data lacking these correlations. Existing mitigation approaches typically depend on external annotations of spurious correlations, which may be difficult to obtain and are not relevant to the spurious bias in a model. In this paper, we take a step towards self-guided mitigation of spurious bias by proposing NeuronTune, a post hoc method that directly intervenes in a model's internal decision process. Our method probes in a model's latent embedding space to identify and regulate neurons that lead to spurious prediction behaviors. We theoretically justify our approach and show that it brings the model closer to an unbiased one. Unlike previous methods, NeuronTune operates without requiring spurious correlation annotations, making it a practical and effective tool for improving model robustness. Experiments across different architectures and data modalities demonstrate that our method significantly mitigates spurious bias in a self-guided way.
ShortcutProbe: Probing Prediction Shortcuts for Learning Robust Models
May 20, 2025Deep learning models often achieve high performance by inadvertently learning spurious correlations between targets and non-essential features. For example, an image classifier may identify an object via its background that spuriously correlates with it. This prediction behavior, known as spurious bias, severely degrades model performance on data that lacks the learned spurious correlations. Existing methods on spurious bias mitigation typically require a variety of data groups with spurious correlation annotations called group labels. However, group labels require costly human annotations and often fail to capture subtle spurious biases such as relying on specific pixels for predictions. In this paper, we propose a novel post hoc spurious bias mitigation framework without requiring group labels. Our framework, termed ShortcutProbe, identifies prediction shortcuts that reflect potential non-robustness in predictions in a given model's latent space. The model is then retrained to be invariant to the identified prediction shortcuts for improved robustness. We theoretically analyze the effectiveness of the framework and empirically demonstrate that it is an efficient and practical tool for improving a model's robustness to spurious bias on diverse datasets.
Benchmarking Spurious Bias in Few-Shot Image Classifiers
Sep 04, 2024Few-shot image classifiers are designed to recognize and classify new data with minimal supervision and limited data but often show reliance on spurious correlations between classes and spurious attributes, known as spurious bias. Spurious correlations commonly hold in certain samples and few-shot classifiers can suffer from spurious bias induced from them. There is an absence of an automatic benchmarking system to assess the robustness of few-shot classifiers against spurious bias. In this paper, we propose a systematic and rigorous benchmark framework, termed FewSTAB, to fairly demonstrate and quantify varied degrees of robustness of few-shot classifiers to spurious bias. FewSTAB creates few-shot evaluation tasks with biased attributes so that using them for predictions can demonstrate poor performance. To construct these tasks, we propose attribute-based sample selection strategies based on a pre-trained vision-language model, eliminating the need for manual dataset curation. This allows FewSTAB to automatically benchmark spurious bias using any existing test data. FewSTAB offers evaluation results in a new dimension along with a new design guideline for building robust classifiers. Moreover, it can benchmark spurious bias in varied degrees and enable designs for varied degrees of robustness. Its effectiveness is demonstrated through experiments on ten few-shot learning methods across three datasets. We hope our framework can inspire new designs of robust few-shot classifiers. Our code is available at https://github.com/gtzheng/FewSTAB.
MM-SpuBench: Towards Better Understanding of Spurious Biases in Multimodal LLMs
Jun 24, 2024



Spurious bias, a tendency to use spurious correlations between non-essential input attributes and target variables for predictions, has revealed a severe robustness pitfall in deep learning models trained on single modality data. Multimodal Large Language Models (MLLMs), which integrate both vision and language models, have demonstrated strong capability in joint vision-language understanding. However, whether spurious biases are prevalent in MLLMs remains under-explored. We mitigate this gap by analyzing the spurious biases in a multimodal setting, uncovering the specific test data patterns that can manifest this problem when biases in the vision model cascade into the alignment between visual and text tokens in MLLMs. To better understand this problem, we introduce MM-SpuBench, a comprehensive visual question-answering (VQA) benchmark designed to evaluate MLLMs' reliance on nine distinct categories of spurious correlations from five open-source image datasets. The VQA dataset is built from human-understandable concept information (attributes). Leveraging this benchmark, we conduct a thorough evaluation of current state-of-the-art MLLMs. Our findings illuminate the persistence of the reliance on spurious correlations from these models and underscore the urge for new methodologies to mitigate spurious biases. To support the MLLM robustness research, we release our VQA benchmark at https://huggingface.co/datasets/mmbench/MM-SpuBench.
Spuriousness-Aware Meta-Learning for Learning Robust Classifiers
Jun 15, 2024Spurious correlations are brittle associations between certain attributes of inputs and target variables, such as the correlation between an image background and an object class. Deep image classifiers often leverage them for predictions, leading to poor generalization on the data where the correlations do not hold. Mitigating the impact of spurious correlations is crucial towards robust model generalization, but it often requires annotations of the spurious correlations in data -- a strong assumption in practice. In this paper, we propose a novel learning framework based on meta-learning, termed SPUME -- SPUriousness-aware MEta-learning, to train an image classifier to be robust to spurious correlations. We design the framework to iteratively detect and mitigate the spurious correlations that the classifier excessively relies on for predictions. To achieve this, we first propose to utilize a pre-trained vision-language model to extract text-format attributes from images. These attributes enable us to curate data with various class-attribute correlations, and we formulate a novel metric to measure the degree of these correlations' spuriousness. Then, to mitigate the reliance on spurious correlations, we propose a meta-learning strategy in which the support (training) sets and query (test) sets in tasks are curated with different spurious correlations that have high degrees of spuriousness. By meta-training the classifier on these spuriousness-aware meta-learning tasks, our classifier can learn to be invariant to the spurious correlations. We demonstrate that our method is robust to spurious correlations without knowing them a priori and achieves the best on five benchmark datasets with different robustness measures.
Learning Robust Classifiers with Self-Guided Spurious Correlation Mitigation
May 06, 2024



Deep neural classifiers tend to rely on spurious correlations between spurious attributes of inputs and targets to make predictions, which could jeopardize their generalization capability. Training classifiers robust to spurious correlations typically relies on annotations of spurious correlations in data, which are often expensive to get. In this paper, we tackle an annotation-free setting and propose a self-guided spurious correlation mitigation framework. Our framework automatically constructs fine-grained training labels tailored for a classifier obtained with empirical risk minimization to improve its robustness against spurious correlations. The fine-grained training labels are formulated with different prediction behaviors of the classifier identified in a novel spuriousness embedding space. We construct the space with automatically detected conceptual attributes and a novel spuriousness metric which measures how likely a class-attribute correlation is exploited for predictions. We demonstrate that training the classifier to distinguish different prediction behaviors reduces its reliance on spurious correlations without knowing them a priori and outperforms prior methods on five real-world datasets.
Spurious Correlations in Machine Learning: A Survey
Feb 20, 2024


Machine learning systems are known to be sensitive to spurious correlations between biased features of the inputs (e.g., background, texture, and secondary objects) and the corresponding labels. These features and their correlations with the labels are known as "spurious" because they tend to change with shifts in real-world data distributions, which can negatively impact the model's generalization and robustness. In this survey, we provide a comprehensive review of this issue, along with a taxonomy of current state-of-the-art methods for addressing spurious correlations in machine learning models. Additionally, we summarize existing datasets, benchmarks, and metrics to aid future research. The paper concludes with a discussion of the recent advancements and future research challenges in this field, aiming to provide valuable insights for researchers in the related domains.
AdvST: Revisiting Data Augmentations for Single Domain Generalization
Dec 20, 2023



Single domain generalization (SDG) aims to train a robust model against unknown target domain shifts using data from a single source domain. Data augmentation has been proven an effective approach to SDG. However, the utility of standard augmentations, such as translate, or invert, has not been fully exploited in SDG; practically, these augmentations are used as a part of a data preprocessing procedure. Although it is intuitive to use many such augmentations to boost the robustness of a model to out-of-distribution domain shifts, we lack a principled approach to harvest the benefit brought from multiple these augmentations. Here, we conceptualize standard data augmentations with learnable parameters as semantics transformations that can manipulate certain semantics of a sample, such as the geometry or color of an image. Then, we propose Adversarial learning with Semantics Transformations (AdvST) that augments the source domain data with semantics transformations and learns a robust model with the augmented data. We theoretically show that AdvST essentially optimizes a distributionally robust optimization objective defined on a set of semantics distributions induced by the parameters of semantics transformations. We demonstrate that AdvST can produce samples that expand the coverage on target domain data. Compared with the state-of-the-art methods, AdvST, despite being a simple method, is surprisingly competitive and achieves the best average SDG performance on the Digits, PACS, and DomainNet datasets. Our code is available at https://github.com/gtzheng/AdvST.