 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Field Neural Network
Feb 24, 2025In recent years, with the rapid development of machine learning, physicists have been exploring its new applications in solving or alleviating the curse of dimensionality in many-body problems. In order to accurately reflect the underlying physics of the problem, domain knowledge must be encoded into the machine learning algorithms. In this work, inspired by field theory, we propose a new set of machine learning models called effective field neural networks (EFNNs) that can automatically and efficiently capture important many-body interactions through multiple self-refining processes. Taking the classical $3$-spin infinite-range model and the quantum double exchange model as case studies, we explicitly demonstrate that EFNNs significantly outperform fully-connected deep neural networks (DNNs) and the effective model. Furthermore, with the help of convolution operations, the EFNNs learned in a small system can be seamlessly used in a larger system without additional training and the relative errors even decrease, which further demonstrates the efficacy of EFNNs in representing core physical behaviors.
EDocNet: Efficient Datasheet Layout Analysis Based on Focus and Global Knowledge Distillation
Feb 23, 2025



When designing circuits, engineers obtain the information of electronic devices by browsing a large number of documents, which is low efficiency and heavy workload. The use of artificial intelligence technology to automatically parse documents can greatly improve the efficiency of engineers. However, the current document layout analysis model is aimed at various types of documents and is not suitable for electronic device documents. This paper proposes to use EDocNet to realize the document layout analysis function for document analysis, and use the electronic device document data set created by myself for training. The training method adopts the focus and global knowledge distillation method, and a model suitable for electronic device documents is obtained, which can divide the contents of electronic device documents into 21 categories. It has better average accuracy and average recall rate. It also greatly improves the speed of model checking.
Advanced Chain-of-Thought Reasoning for Parameter Extraction from Documents Using Large Language Models
Feb 23, 2025Extracting parameters from technical documentation is crucial for ensuring design precision and simulation reliability in electronic design. However, current methods struggle to handle high-dimensional design data and meet the demands of real-time processing. In electronic design automation (EDA), engineers often manually search through extensive documents to retrieve component parameters required for constructing PySpice models, a process that is both labor-intensive and time-consuming. To address this challenge, we propose an innovative framework that leverages large language models (LLMs) to automate the extraction of parameters and the generation of PySpice models directly from datasheets. Our framework introduces three Chain-of-Thought (CoT) based techniques: (1) Targeted Document Retrieval (TDR), which enables the rapid identification of relevant technical sections; (2) Iterative Retrieval Optimization (IRO), which refines the parameter search through iterative improvements; and (3) Preference Optimization (PO), which dynamically prioritizes key document sections based on relevance. Experimental results show that applying all three methods together improves retrieval precision by 47.69% and reduces processing latency by 37.84%. Furthermore, effect size analysis using Cohen's d reveals that PO significantly reduces latency, while IRO contributes most to precision enhancement. These findings underscore the potential of our framework to streamline EDA processes, enhance design accuracy, and shorten development timelines. Additionally, our algorithm has model-agnostic generalization, meaning it can improve parameter search performance across different LLMs.
High-Fidelity Novel View Synthesis via Splatting-Guided Diffusion
Feb 18, 2025



Despite recent advances in Novel View Synthesis (NVS), generating high-fidelity views from single or sparse observations remains a significant challenge. Existing splatting-based approaches often produce distorted geometry due to splatting errors. While diffusion-based methods leverage rich 3D priors to achieve improved geometry, they often suffer from texture hallucination. In this paper, we introduce SplatDiff, a pixel-splatting-guided video diffusion model designed to synthesize high-fidelity novel views from a single image. Specifically, we propose an aligned synthesis strategy for precise control of target viewpoints and geometry-consistent view synthesis. To mitigate texture hallucination, we design a texture bridge module that enables high-fidelity texture generation through adaptive feature fusion. In this manner, SplatDiff leverages the strengths of splatting and diffusion to generate novel views with consistent geometry and high-fidelity details. Extensive experiments verify the state-of-the-art performance of SplatDiff in single-view NVS. Additionally, without extra training, SplatDiff shows remarkable zero-shot performance across diverse tasks, including sparse-view NVS and stereo video conversion.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Pre-Trained Video Generative Models as World Simulators
Feb 10, 2025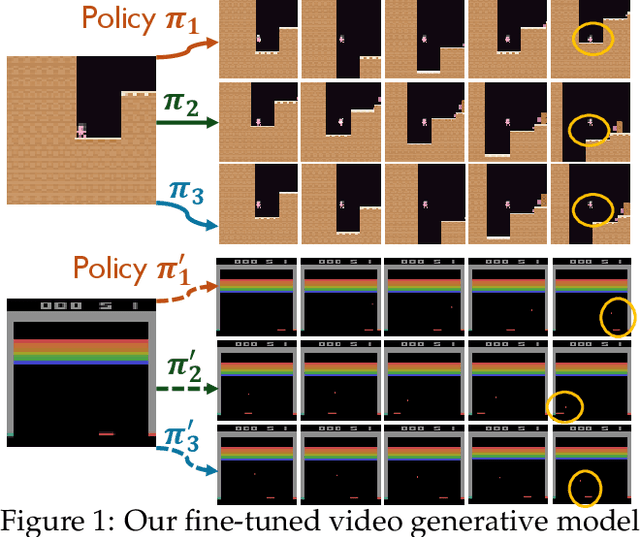

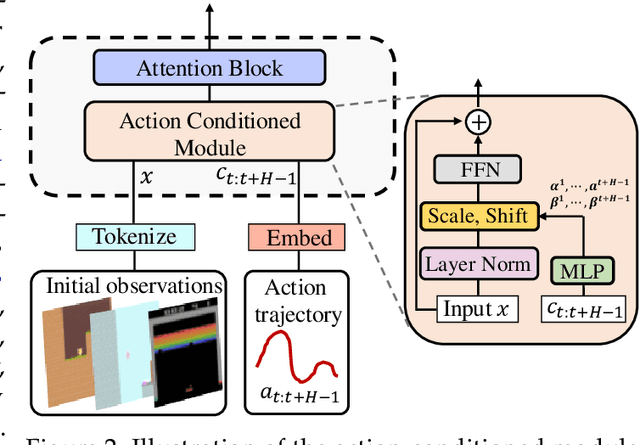
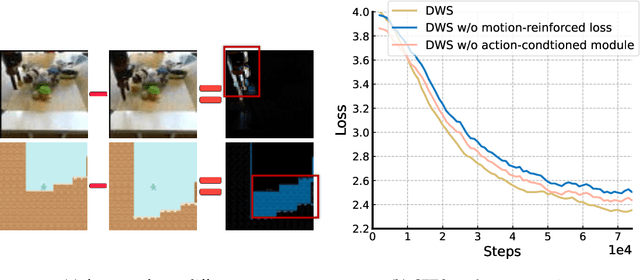
Video generative models pre-trained on large-scale internet datasets have achieved remarkable success, excelling at producing realistic synthetic videos. However, they often generate clips based on static prompts (e.g., text or images), limiting their ability to model interactive and dynamic scenarios. In this paper, we propose Dynamic World Simulation (DWS), a novel approach to transform pre-trained video generative models into controllable world simulators capable of executing specified action trajectories. To achieve precise alignment between conditioned actions and generated visual changes, we introduce a lightweight, universal action-conditioned module that seamlessly integrates into any existing model. Instead of focusing on complex visual details, we demonstrate that consistent dynamic transition modeling is the key to building powerful world simulators. Building upon this insight, we further introduce a motion-reinforced loss that enhances action controllability by compelling the model to capture dynamic changes more effectively. Experiments demonstrate that DWS can be versatilely applied to both diffusion and autoregressive transformer models, achieving significant improvements in generating action-controllable, dynamically consistent videos across games and robotics domains. Moreover, to facilitate the applications of the learned world simulator in downstream tasks such as model-based reinforcement learning, we propose prioritized imagination to improve sample efficiency, demonstrating competitive performance compared with state-of-the-art methods.
CAMEF: Causal-Augmented Multi-Modality Event-Driven Financial Forecasting by Integrating Time Series Patterns and Salient Macroeconomic Announcements
Feb 07, 2025



Accurately forecasting the impact of macroeconomic events is critical for investors and policymakers. Salient events like monetary policy decisions and employment reports often trigger market movements by shaping expectations of economic growth and risk, thereby establishing causal relationships between events and market behavior. Existing forecasting methods typically focus either on textual analysis or time-series modeling, but fail to capture the multi-modal nature of financial markets and the causal relationship between events and price movements. To address these gaps, we propose CAMEF (Causal-Augmented Multi-Modality Event-Driven Financial Forecasting), a multi-modality framework that effectively integrates textual and time-series data with a causal learning mechanism and an LLM-based counterfactual event augmentation technique for causal-enhanced financial forecasting. Our contributions include: (1) a multi-modal framework that captures causal relationships between policy texts and historical price data; (2) a new financial dataset with six types of macroeconomic releases from 2008 to April 2024, and high-frequency real trading data for five key U.S. financial assets; and (3) an LLM-based counterfactual event augmentation strategy. We compare CAMEF to state-of-the-art transformer-based time-series and multi-modal baselines, and perform ablation studies to validate the effectiveness of the causal learning mechanism and event types.
A Decade of Action Quality Assessment: Largest Systematic Survey of Trends, Challenges, and Future Directions
Feb 05, 2025



Action Quality Assessment (AQA) -- the ability to quantify the quality of human motion, actions, or skill levels and provide feedback -- has far-reaching implications in areas such as low-cost physiotherapy, sports training, and workforce development. As such, it has become a critical field in computer vision & video understanding over the past decade. Significant progress has been made in AQA methodologies, datasets, & applications, yet a pressing need remains for a comprehensive synthesis of this rapidly evolving field. In this paper, we present a thorough survey of the AQA landscape, systematically reviewing over 200 research papers using the preferred reporting items for systematic reviews & meta-analyses (PRISMA) framework. We begin by covering foundational concepts & definitions, then move to general frameworks & performance metrics, & finally discuss the latest advances in methodologies & datasets. This survey provides a detailed analysis of research trends, performance comparisons, challenges, & future directions. Through this work, we aim to offer a valuable resource for both newcomers & experienced researchers, promoting further exploration & progress in AQA. Data are available at https://haoyin116.github.io/Survey_of_AQA/
CodeSteer: Symbolic-Augmented Language Models via Code/Text Guidance
Feb 04, 2025



Existing methods fail to effectively steer Large Language Models (LLMs) between textual reasoning and code generation, leaving symbolic computing capabilities underutilized. We introduce CodeSteer, an effective method for guiding LLM code/text generation. We construct a comprehensive benchmark SymBench comprising 37 symbolic tasks with adjustable complexity and also synthesize datasets of 12k multi-round guidance/generation trajectories and 5.5k guidance comparison pairs. We fine-tune the Llama-3-8B model with a newly designed multi-round supervised fine-tuning (SFT) and direct preference optimization (DPO). The resulting model, CodeSteerLLM, augmented with the proposed symbolic and self-answer checkers, effectively guides the code/text generation of larger models. Augmenting GPT-4o with CodeSteer raises its average performance score from 53.3 to 86.4, even outperforming the existing best LLM OpenAI o1 (82.7), o1-preview (74.8), and DeepSeek R1 (76.8) across all 37 tasks (28 seen, 9 unseen). Trained for GPT-4o, CodeSteer demonstrates superior generalizability, providing an average 41.8 performance boost on Claude, Mistral, and GPT-3.5. CodeSteer-guided LLMs fully harness symbolic computing to maintain strong performance on highly complex tasks. Models, Datasets, and Codes are available at https://github.com/yongchao98/CodeSteer-v1.0.
Large Language Models for Recommendation with Deliberative User Preference Alignment
Feb 04, 2025



While recent advancements in aligning Large Language Models (LLMs) with recommendation tasks have shown great potential and promising performance overall, these aligned recommendation LLMs still face challenges in complex scenarios. This is primarily due to the current alignment approach focusing on optimizing LLMs to generate user feedback directly, without incorporating deliberation. To overcome this limitation and develop more reliable LLMs for recommendations, we propose a new Deliberative Recommendation task, which incorporates explicit reasoning about user preferences as an additional alignment goal. We then introduce the Deliberative User Preference Alignment framework, designed to enhance reasoning capabilities by utilizing verbalized user feedback in a step-wise manner to tackle this task. The framework employs collaborative step-wise experts and tailored training strategies for each expert. Experimental results across three real-world datasets demonstrate the rationality of the deliberative task formulation and the superior performance of the proposed framework in improving both prediction accuracy and reasoning quality.