 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Compression of Seismic Velocity Models via SIREN Auto-Decoders
Mar 17, 2026Implicit Neural Representations (INRs) have emerged as a powerful paradigm for representing continuous signals independently of grid resolution. In this paper, we propose a high-fidelity neural compression framework based on a SIREN (Sinusoidal Representation Networks) auto-decoder to represent multi-structural seismic velocity models from the OpenFWI benchmark. Our method compresses each 70x70 velocity map (4,900 points) into a compact 256-dimensional latent vector, achieving a compression ratio of 19:1. We evaluate the framework on 1,000 samples across five diverse geological families: FlatVel, CurveVel, FlatFault, CurveFault, and Style. Experimental results demonstrate an average PSNR of 32.47 dB and SSIM of 0.956, indicating high-quality reconstruction. Furthermore, we showcase two key advantages of our implicit representation: (1) smooth latent space interpolation that generates plausible intermediate velocity structures, and (2) zero-shot super-resolution capability that reconstructs velocity fields at arbitrary resolutions up to 280x280 without additional training. The results highlight the potential of INR-based auto-decoders for efficient storage, multi-scale analysis, and downstream geophysical applications such as full waveform inversion.
Conditional Rectified Flow-based End-to-End Rapid Seismic Inversion Method
Mar 16, 2026Seismic inversion is a core problem in geophysical exploration, where traditional methods suffer from high computational costs and are susceptible to initial model dependence. In recent years, deep generative model-based seismic inversion methods have achieved remarkable progress, but existing generative models struggle to balance sampling efficiency and inversion accuracy. This paper proposes an end-to-end fast seismic inversion method based on Conditional Rectified Flow[1], which designs a dedicated seismic encoder to extract multi-scale seismic features and adopts a layer-by-layer injection control strategy to achieve fine-grained conditional control. Experimental results demonstrate that the proposed method achieves excellent inversion accuracy on the OpenFWI[2] benchmark dataset. Compared with Diffusion[3,4] methods, it achieves sampling acceleration; compared with InversionNet[5,6,7] methods, it achieves higher accuracy in generation. Our zero-shot generalization experiments on Marmousi[8,9] real data further verify the practical value of the method. Experimental results show that the proposed method achieves excellent inversion accuracy on the OpenFWI benchmark dataset; compared with Diffusion methods, it achieves sampling acceleration while maintaining higher accuracy than InversionNet methods; experiments based on the Marmousi standard model further verify that this method can generate high-quality initial velocity models in a zero-shot manner, effectively alleviating the initial model dependency problem in traditional Full Waveform Inversion (FWI), and possesses industrial practical value.
Seismic full-waveform inversion based on a physics-driven generative adversarial network
Mar 16, 2026Objectives: Full-waveform inversion (FWI) is a high-resolution geophysical imaging technique that reconstructs subsurface velocity models by iteratively minimizing the misfit between predicted and observed seismic data. However, under complex geological conditions, conventional FWI suffers from strong dependence on the initial model and tends to produce unstable results when the data are sparse or contaminated by noise. Methods: To address these limitations, this paper proposes a physics-driven generative adversarial network-based full-waveform inversion method. The proposed approach integrates the data-driven capability of deep neural networks with the physical constraints imposed by the seismic wave equation, and employs adversarial training through a discriminator to enhance the stability and robustness of the inversion results. Results: Experimental results on two representative benchmark geological models demonstrate that the proposed method can effectively recover complex velocity structures and achieves superior performance in terms of structural similarity (SSIM) and signal-to-noise ratio (SNR). Conclusions: This method provides a promising solution for alleviating the initial-model dependence in full-waveform inversion and shows strong potential for practical applications.
CAMEF: Causal-Augmented Multi-Modality Event-Driven Financial Forecasting by Integrating Time Series Patterns and Salient Macroeconomic Announcements
Feb 07, 2025



Accurately forecasting the impact of macroeconomic events is critical for investors and policymakers. Salient events like monetary policy decisions and employment reports often trigger market movements by shaping expectations of economic growth and risk, thereby establishing causal relationships between events and market behavior. Existing forecasting methods typically focus either on textual analysis or time-series modeling, but fail to capture the multi-modal nature of financial markets and the causal relationship between events and price movements. To address these gaps, we propose CAMEF (Causal-Augmented Multi-Modality Event-Driven Financial Forecasting), a multi-modality framework that effectively integrates textual and time-series data with a causal learning mechanism and an LLM-based counterfactual event augmentation technique for causal-enhanced financial forecasting. Our contributions include: (1) a multi-modal framework that captures causal relationships between policy texts and historical price data; (2) a new financial dataset with six types of macroeconomic releases from 2008 to April 2024, and high-frequency real trading data for five key U.S. financial assets; and (3) an LLM-based counterfactual event augmentation strategy. We compare CAMEF to state-of-the-art transformer-based time-series and multi-modal baselines, and perform ablation studies to validate the effectiveness of the causal learning mechanism and event types.
Input-to-State Stable Neural Ordinary Differential Equations with Applications to Transient Modeling of Circuits
Feb 14, 2022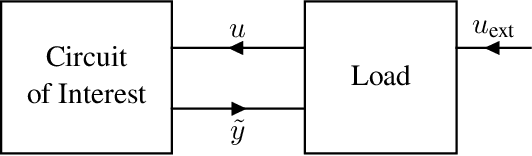

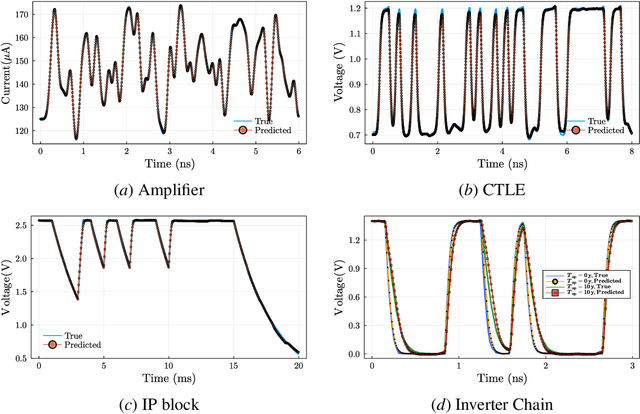
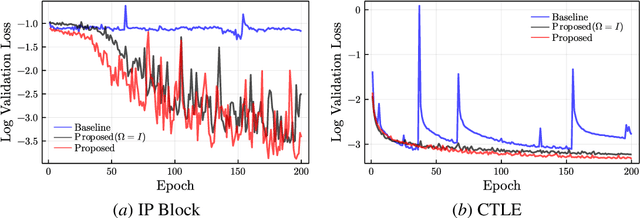
This paper proposes a class of neural ordinary differential equations parametrized by provably input-to-state stable continuous-time recurrent neural networks. The model dynamics are defined by construction to be input-to-state stable (ISS) with respect to an ISS-Lyapunov function that is learned jointly with the dynamics. We use the proposed method to learn cheap-to-simulate behavioral models for electronic circuits that can accurately reproduce the behavior of various digital and analog circuits when simulated by a commercial circuit simulator, even when interconnected with circuit components not encountered during training. We also demonstrate the feasibility of learning ISS-preserving perturbations to the dynamics for modeling degradation effects due to circuit aging.
RF-Based Human Activity Recognition Using Signal Adapted Convolutional Neural Network
Oct 28, 2021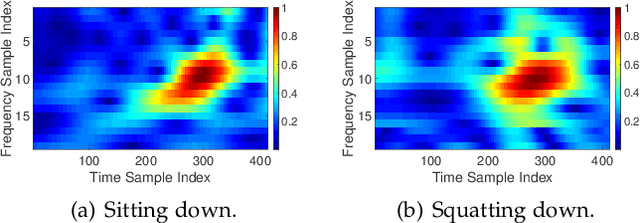

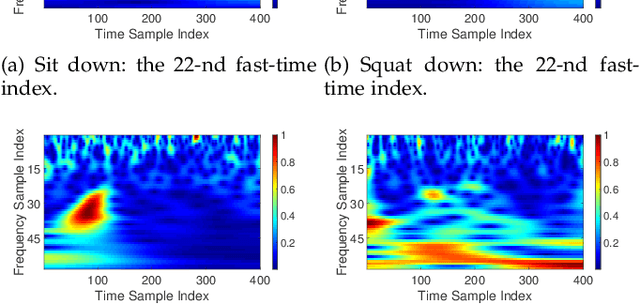
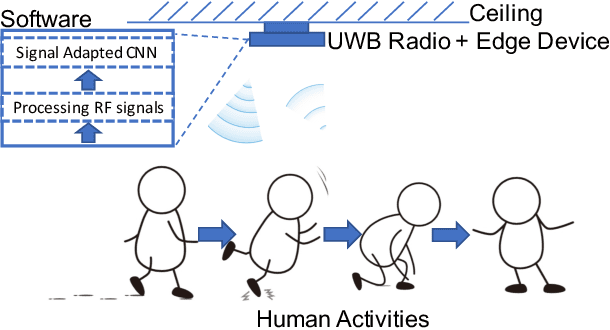
Human Activity Recognition (HAR) plays a critical role in a wide range of real-world applications, and it is traditionally achieved via wearable sensing. Recently, to avoid the burden and discomfort caused by wearable devices, device-free approaches exploiting RF signals arise as a promising alternative for HAR. Most of the latest device-free approaches require training a large deep neural network model in either time or frequency domain, entailing extensive storage to contain the model and intensive computations to infer activities. Consequently, even with some major advances on device-free HAR, current device-free approaches are still far from practical in real-world scenarios where the computation and storage resources possessed by, for example, edge devices, are limited. Therefore, we introduce HAR-SAnet which is a novel RF-based HAR framework. It adopts an original signal adapted convolutional neural network architecture: instead of feeding the handcraft features of RF signals into a classifier, HAR-SAnet fuses them adaptively from both time and frequency domains to design an end-to-end neural network model. We apply point-wise grouped convolution and depth-wise separable convolutions to confine the model scale and to speed up the inference execution time. The experiment results show that the recognition accuracy of HAR-SAnet outperforms state-of-the-art algorithms and systems.
* 13 pages
Marginal and simultaneous predictive classification using stratified graphical models
Jan 31, 2014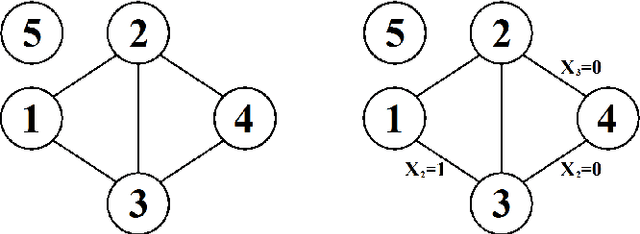
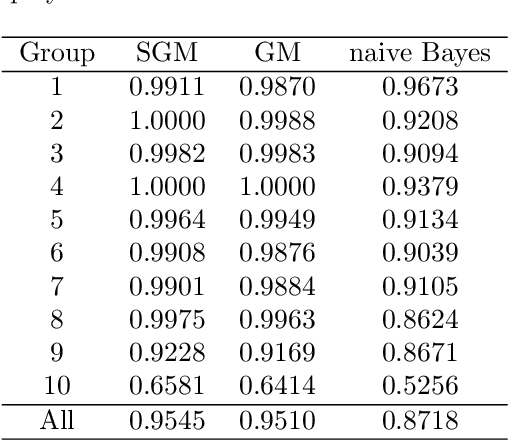
An inductive probabilistic classification rule must generally obey the principles of Bayesian predictive inference, such that all observed and unobserved stochastic quantities are jointly modeled and the parameter uncertainty is fully acknowledged through the posterior predictive distribution. Several such rules have been recently considered and their asymptotic behavior has been characterized under the assumption that the observed features or variables used for building a classifier are conditionally independent given a simultaneous labeling of both the training samples and those from an unknown origin. Here we extend the theoretical results to predictive classifiers acknowledging feature dependencies either through graphical models or sparser alternatives defined as stratified graphical models. We also show through experimentation with both synthetic and real data that the predictive classifiers based on stratified graphical models have consistently best accuracy compared with the predictive classifiers based on either conditionally independent features or on ordinary graphical models.