 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Catastrophic Forgetting beyond Continual Learning: Balanced Training for Neural Machine Translation
Mar 18, 2022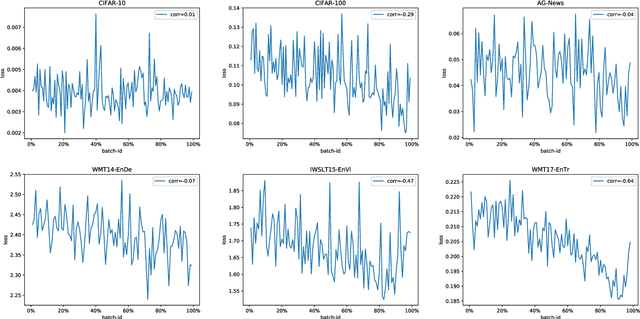
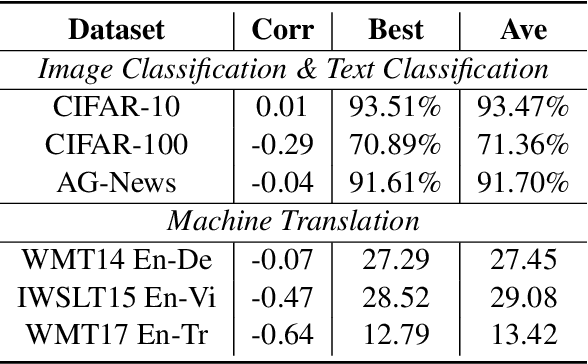

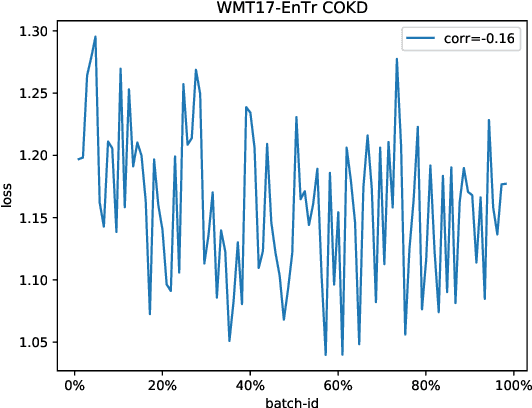
Neural networks tend to gradually forget the previously learned knowledge when learning multiple tasks sequentially from dynamic data distributions. This problem is called \textit{catastrophic forgetting}, which is a fundamental challenge in the continual learning of neural networks. In this work, we observe that catastrophic forgetting not only occurs in continual learning but also affects the traditional static training. Neural networks, especially neural machine translation models, suffer from catastrophic forgetting even if they learn from a static training set. To be specific, the final model pays imbalanced attention to training samples, where recently exposed samples attract more attention than earlier samples. The underlying cause is that training samples do not get balanced training in each model update, so we name this problem \textit{imbalanced training}. To alleviate this problem, we propose Complementary Online Knowledge Distillation (COKD), which uses dynamically updated teacher models trained on specific data orders to iteratively provide complementary knowledge to the student model. Experimental results on multiple machine translation tasks show that our method successfully alleviates the problem of imbalanced training and achieves substantial improvements over strong baseline systems.
Gaussian Multi-head Attention for Simultaneous Machine Translation
Mar 17, 2022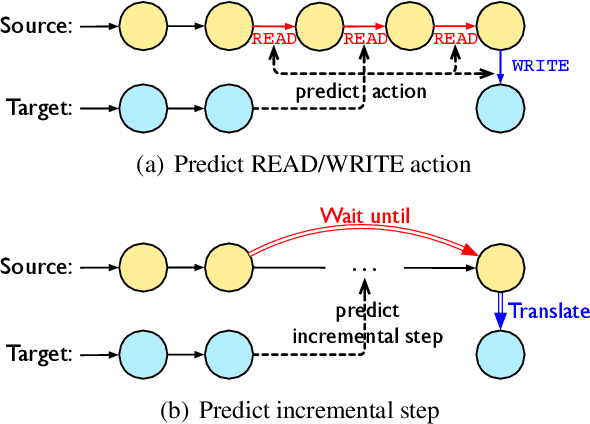
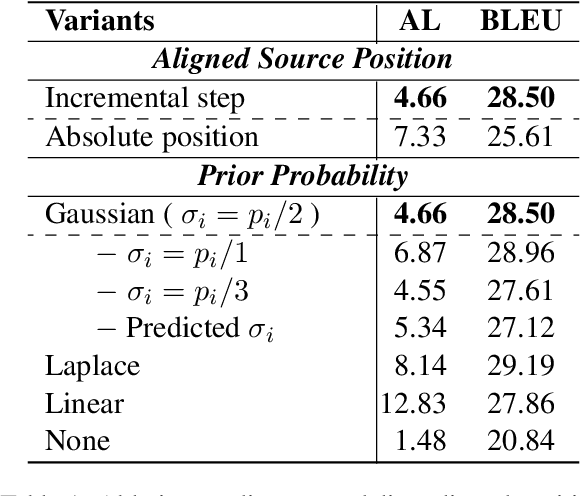
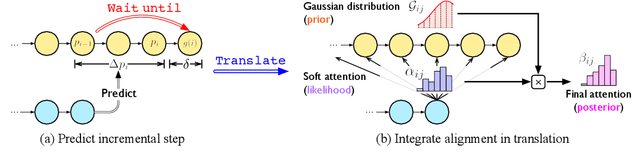
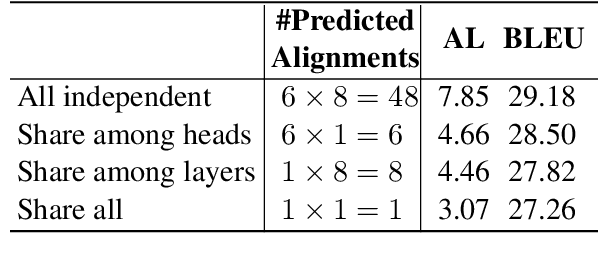
Simultaneous machine translation (SiMT) outputs translation while receiving the streaming source inputs, and hence needs a policy to determine where to start translating. The alignment between target and source words often implies the most informative source word for each target word, and hence provides the unified control over translation quality and latency, but unfortunately the existing SiMT methods do not explicitly model the alignment to perform the control. In this paper, we propose Gaussian Multi-head Attention (GMA) to develop a new SiMT policy by modeling alignment and translation in a unified manner. For SiMT policy, GMA models the aligned source position of each target word, and accordingly waits until its aligned position to start translating. To integrate the learning of alignment into the translation model, a Gaussian distribution centered on predicted aligned position is introduced as an alignment-related prior, which cooperates with translation-related soft attention to determine the final attention. Experiments on En-Vi and De-En tasks show that our method outperforms strong baselines on the trade-off between translation and latency.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022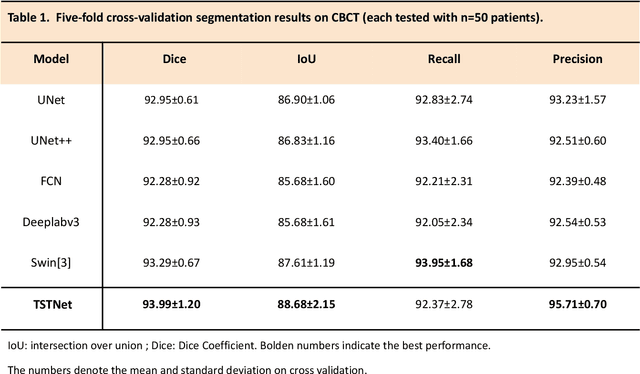
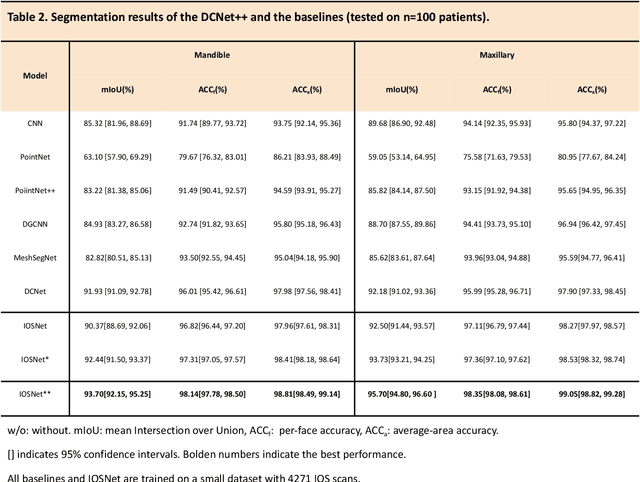

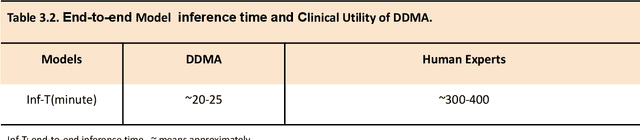
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.
Relational Surrogate Loss Learning
Feb 26, 2022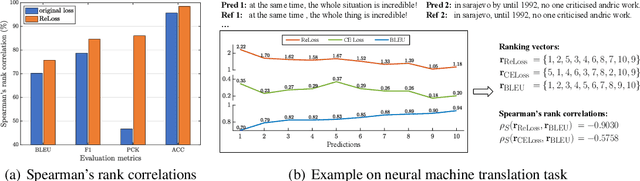
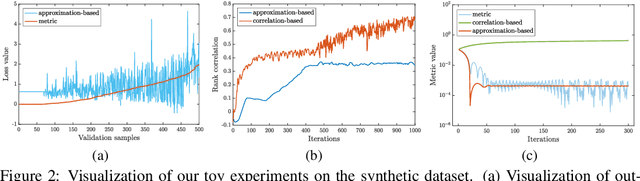
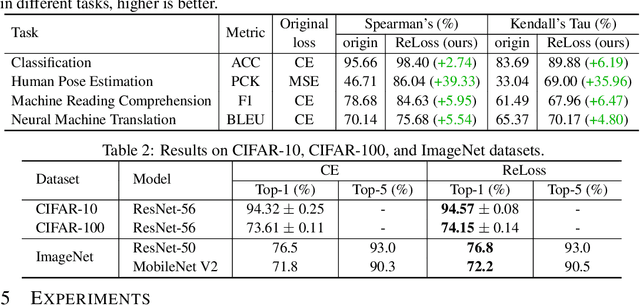
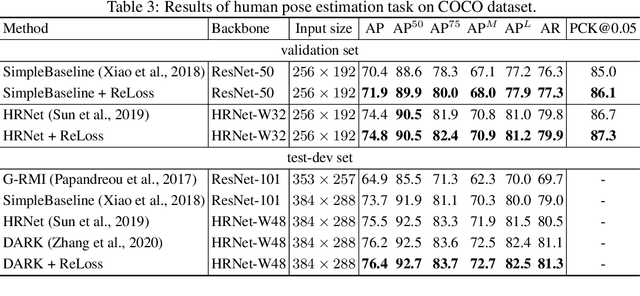
Evaluation metrics in machine learning are often hardly taken as loss functions, as they could be non-differentiable and non-decomposable, e.g., average precision and F1 score. This paper aims to address this problem by revisiting the surrogate loss learning, where a deep neural network is employed to approximate the evaluation metrics. Instead of pursuing an exact recovery of the evaluation metric through a deep neural network, we are reminded of the purpose of the existence of these evaluation metrics, which is to distinguish whether one model is better or worse than another. In this paper, we show that directly maintaining the relation of models between surrogate losses and metrics suffices, and propose a rank correlation-based optimization method to maximize this relation and learn surrogate losses. Compared to previous works, our method is much easier to optimize and enjoys significant efficiency and performance gains. Extensive experiments show that our method achieves improvements on various tasks including image classification and neural machine translation, and even outperforms state-of-the-art methods on human pose estimation and machine reading comprehension tasks. Code is available at: https://github.com/hunto/ReLoss.
Mental Health Assessment for the Chatbots
Jan 14, 2022
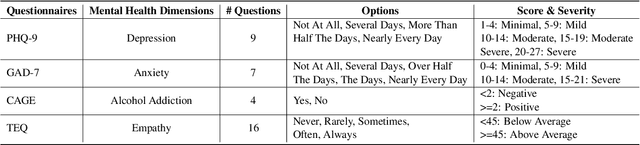
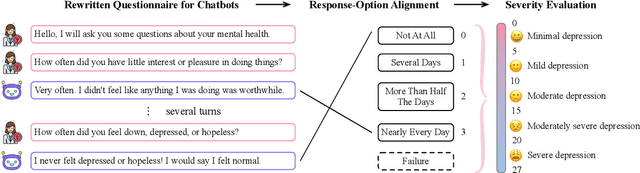

Previous researches on dialogue system assessment usually focus on the quality evaluation (e.g. fluency, relevance, etc) of responses generated by the chatbots, which are local and technical metrics. For a chatbot which responds to millions of online users including minors, we argue that it should have a healthy mental tendency in order to avoid the negative psychological impact on them. In this paper, we establish several mental health assessment dimensions for chatbots (depression, anxiety, alcohol addiction, empathy) and introduce the questionnaire-based mental health assessment methods. We conduct assessments on some well-known open-domain chatbots and find that there are severe mental health issues for all these chatbots. We consider that it is due to the neglect of the mental health risks during the dataset building and the model training procedures. We expect to attract researchers' attention to the serious mental health problems of chatbots and improve the chatbots' ability in positive emotional interaction.
Neyman-Pearson Multi-class Classification via Cost-sensitive Learning
Nov 08, 2021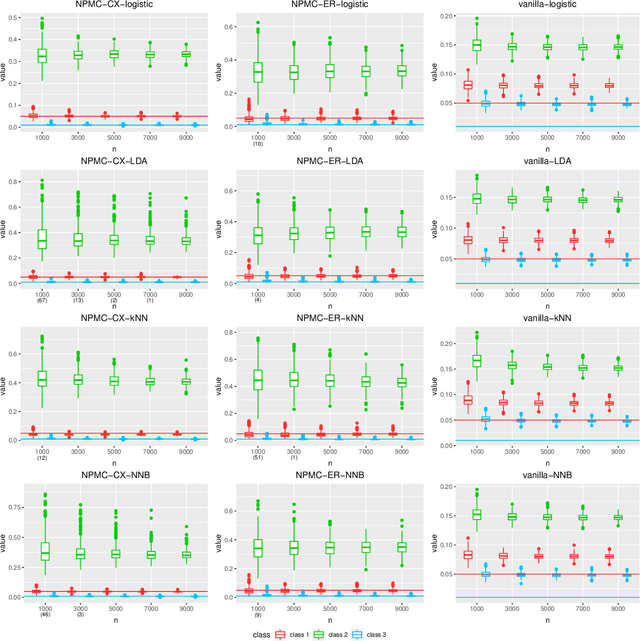
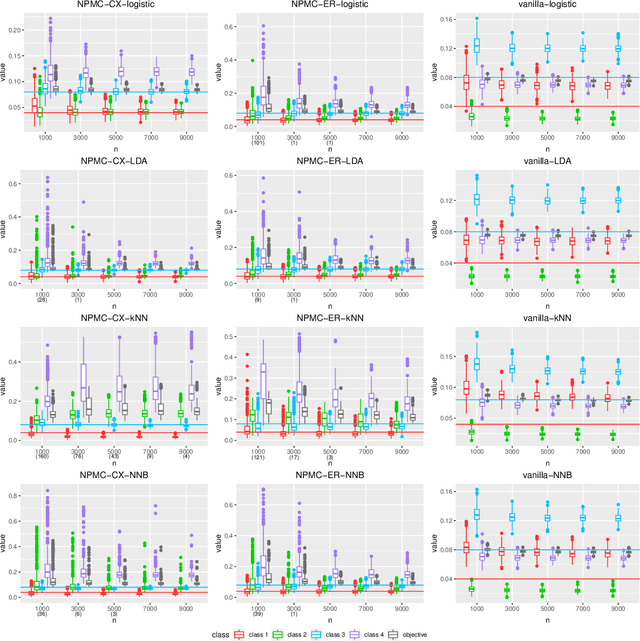
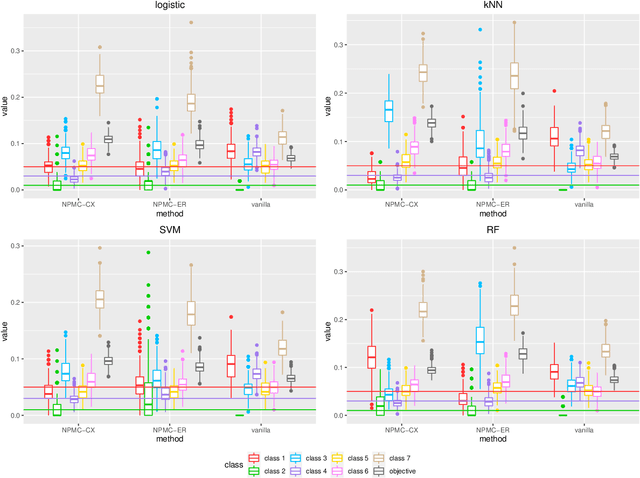
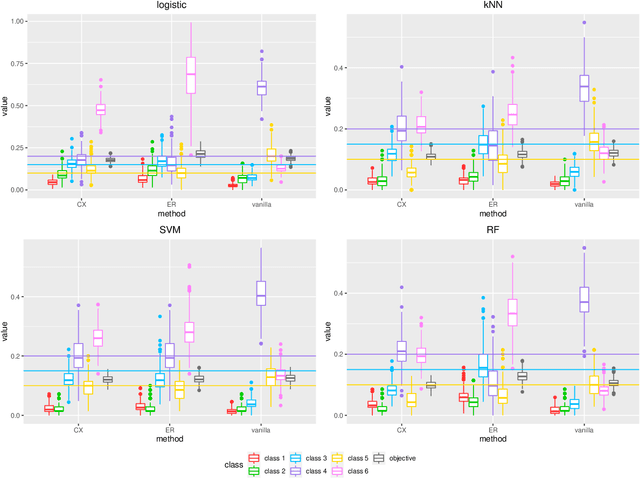
Most existing classification methods aim to minimize the overall misclassification error rate, however, in applications, different types of errors can have different consequences. To take into account this asymmetry issue, two popular paradigms have been developed, namely the Neyman-Pearson (NP) paradigm and cost-sensitive (CS) paradigm. Compared to CS paradigm, NP paradigm does not require a specification of costs. Most previous works on NP paradigm focused on the binary case. In this work, we study the multi-class NP problem by connecting it to the CS problem, and propose two algorithms. We extend the NP oracle inequalities and consistency from the binary case to the multi-class case, and show that our two algorithms enjoy these properties under certain conditions. The simulation and real data studies demonstrate the effectiveness of our algorithms. To our knowledge, this is the first work to solve the multi-class NP problem via cost-sensitive learning techniques with theoretical guarantees. The proposed algorithms are implemented in the R package "npcs" on CRAN.
Mixup Decoding for Diverse Machine Translation
Sep 14, 2021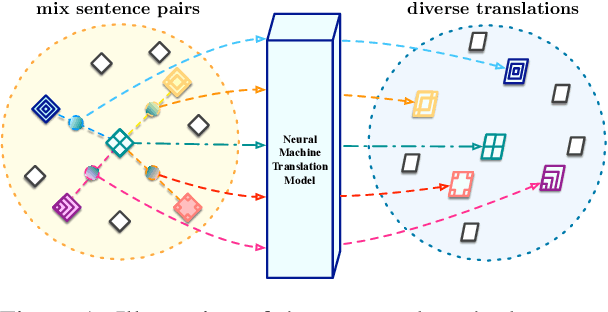

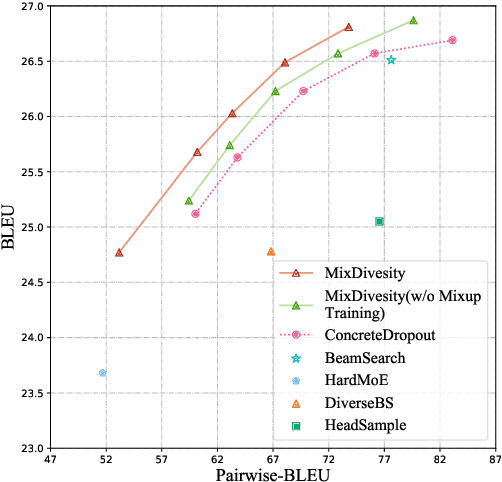
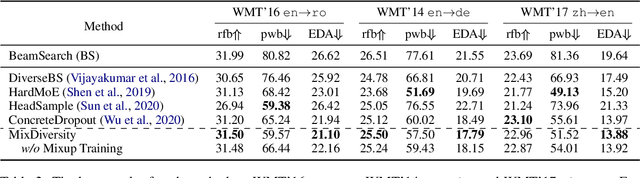
Diverse machine translation aims at generating various target language translations for a given source language sentence. Leveraging the linear relationship in the sentence latent space introduced by the mixup training, we propose a novel method, MixDiversity, to generate different translations for the input sentence by linearly interpolating it with different sentence pairs sampled from the training corpus when decoding. To further improve the faithfulness and diversity of the translations, we propose two simple but effective approaches to select diverse sentence pairs in the training corpus and adjust the interpolation weight for each pair correspondingly. Moreover, by controlling the interpolation weight, our method can achieve the trade-off between faithfulness and diversity without any additional training, which is required in most of the previous methods. Experiments on WMT'16 en-ro, WMT'14 en-de, and WMT'17 zh-en are conducted to show that our method substantially outperforms all previous diverse machine translation methods.
Modeling Concentrated Cross-Attention for Neural Machine Translation with Gaussian Mixture Model
Sep 14, 2021Cross-attention is an important component of neural machine translation (NMT), which is always realized by dot-product attention in previous methods. However, dot-product attention only considers the pair-wise correlation between words, resulting in dispersion when dealing with long sentences and neglect of source neighboring relationships. Inspired by linguistics, the above issues are caused by ignoring a type of cross-attention, called concentrated attention, which focuses on several central words and then spreads around them. In this work, we apply Gaussian Mixture Model (GMM) to model the concentrated attention in cross-attention. Experiments and analyses we conducted on three datasets show that the proposed method outperforms the baseline and has significant improvement on alignment quality, N-gram accuracy, and long sentence translation.
Universal Simultaneous Machine Translation with Mixture-of-Experts Wait-k Policy
Sep 14, 2021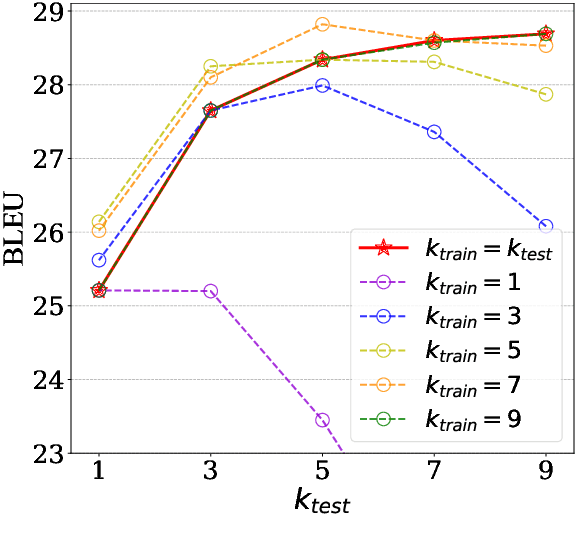
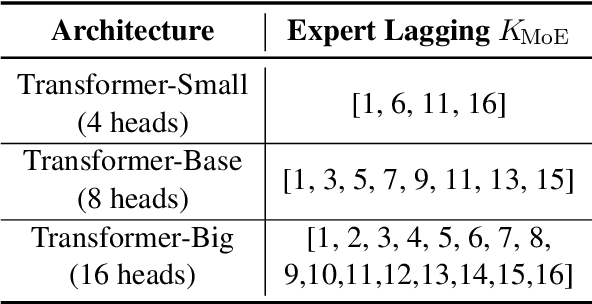
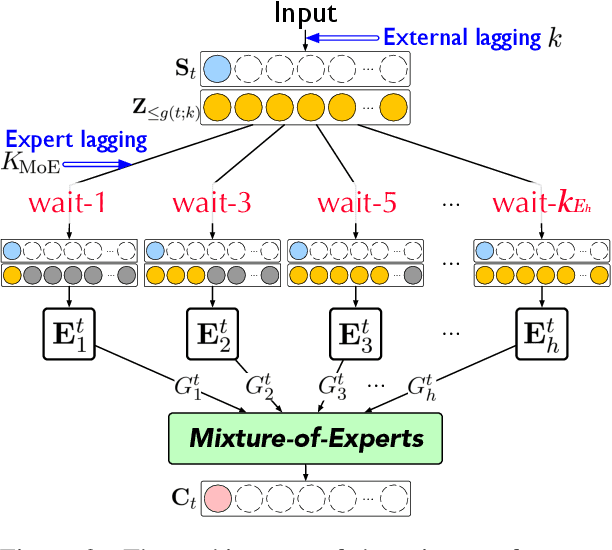
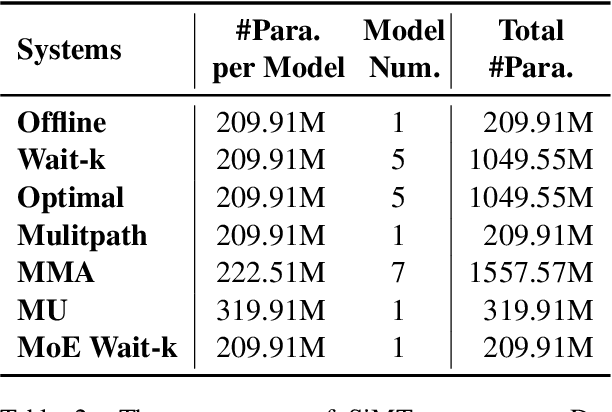
Simultaneous machine translation (SiMT) generates translation before reading the entire source sentence and hence it has to trade off between translation quality and latency. To fulfill the requirements of different translation quality and latency in practical applications, the previous methods usually need to train multiple SiMT models for different latency levels, resulting in large computational costs. In this paper, we propose a universal SiMT model with Mixture-of-Experts Wait-k Policy to achieve the best translation quality under arbitrary latency with only one trained model. Specifically, our method employs multi-head attention to accomplish the mixture of experts where each head is treated as a wait-k expert with its own waiting words number, and given a test latency and source inputs, the weights of the experts are accordingly adjusted to produce the best translation. Experiments on three datasets show that our method outperforms all the strong baselines under different latency, including the state-of-the-art adaptive policy.
Towards Expressive Communication with Internet Memes: A New Multimodal Conversation Dataset and Benchmark
Sep 04, 2021
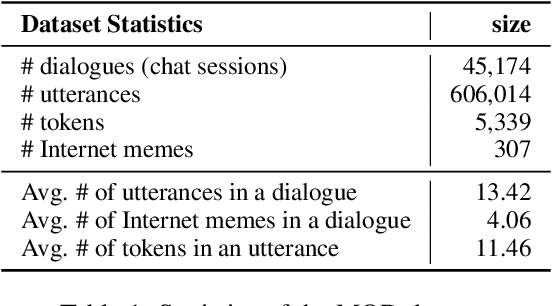
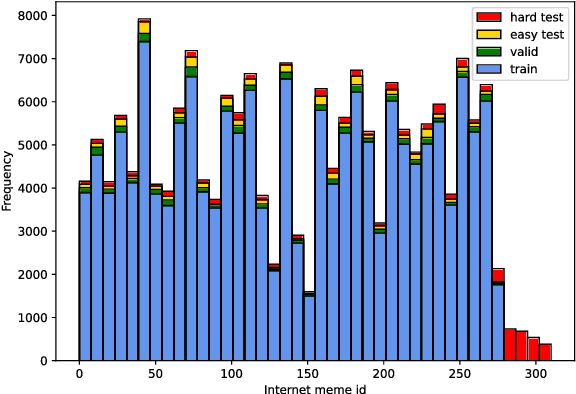
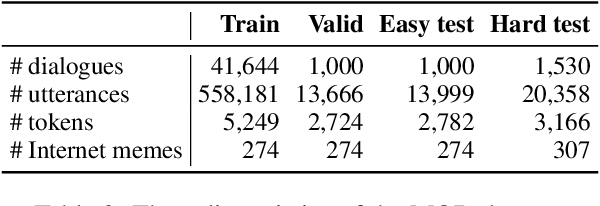
As a kind of new expression elements, Internet memes are popular and extensively used in online chatting scenarios since they manage to make dialogues vivid, moving, and interesting. However, most current dialogue researches focus on text-only dialogue tasks. In this paper, we propose a new task named as \textbf{M}eme incorporated \textbf{O}pen-domain \textbf{D}ialogue (MOD). Compared to previous dialogue tasks, MOD is much more challenging since it requires the model to understand the multimodal elements as well as the emotions behind them. To facilitate the MOD research, we construct a large-scale open-domain multimodal dialogue dataset incorporating abundant Internet memes into utterances. The dataset consists of $\sim$45K Chinese conversations with $\sim$606K utterances. Each conversation contains about $13$ utterances with about $4$ Internet memes on average and each utterance equipped with an Internet meme is annotated with the corresponding emotion. In addition, we present a simple and effective method, which utilizes a unified generation network to solve the MOD task. Experimental results demonstrate that our method trained on the proposed corpus is able to achieve expressive communication including texts and memes. The corpus and models have been publicly available at https://github.com/lizekang/DSTC10-MOD.