 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientLLM: Efficiency in Large Language Models
May 20, 2025Large Language Models (LLMs) have driven significant progress, yet their growing parameter counts and context windows incur prohibitive compute, energy, and monetary costs. We introduce EfficientLLM, a novel benchmark and the first comprehensive empirical study evaluating efficiency techniques for LLMs at scale. Conducted on a production-class cluster (48xGH200, 8xH200 GPUs), our study systematically explores three key axes: (1) architecture pretraining (efficient attention variants: MQA, GQA, MLA, NSA; sparse Mixture-of-Experts (MoE)), (2) fine-tuning (parameter-efficient methods: LoRA, RSLoRA, DoRA), and (3) inference (quantization methods: int4, float16). We define six fine-grained metrics (Memory Utilization, Compute Utilization, Latency, Throughput, Energy Consumption, Compression Rate) to capture hardware saturation, latency-throughput balance, and carbon cost. Evaluating over 100 model-technique pairs (0.5B-72B parameters), we derive three core insights: (i) Efficiency involves quantifiable trade-offs: no single method is universally optimal; e.g., MoE reduces FLOPs and improves accuracy but increases VRAM by 40%, while int4 quantization cuts memory/energy by up to 3.9x at a 3-5% accuracy drop. (ii) Optima are task- and scale-dependent: MQA offers optimal memory-latency trade-offs for constrained devices, MLA achieves lowest perplexity for quality-critical tasks, and RSLoRA surpasses LoRA efficiency only beyond 14B parameters. (iii) Techniques generalize across modalities: we extend evaluations to Large Vision Models (Stable Diffusion 3.5, Wan 2.1) and Vision-Language Models (Qwen2.5-VL), confirming effective transferability. By open-sourcing datasets, evaluation pipelines, and leaderboards, EfficientLLM provides essential guidance for researchers and engineers navigating the efficiency-performance landscape of next-generation foundation models.
Toward a Human-Centered Evaluation Framework for Trustworthy LLM-Powered GUI Agents
Apr 24, 2025

The rise of Large Language Models (LLMs) has revolutionized Graphical User Interface (GUI) automation through LLM-powered GUI agents, yet their ability to process sensitive data with limited human oversight raises significant privacy and security risks. This position paper identifies three key risks of GUI agents and examines how they differ from traditional GUI automation and general autonomous agents. Despite these risks, existing evaluations focus primarily on performance, leaving privacy and security assessments largely unexplored. We review current evaluation metrics for both GUI and general LLM agents and outline five key challenges in integrating human evaluators for GUI agent assessments. To address these gaps, we advocate for a human-centered evaluation framework that incorporates risk assessments, enhances user awareness through in-context consent, and embeds privacy and security considerations into GUI agent design and evaluation.
The Obvious Invisible Threat: LLM-Powered GUI Agents' Vulnerability to Fine-Print Injections
Apr 15, 2025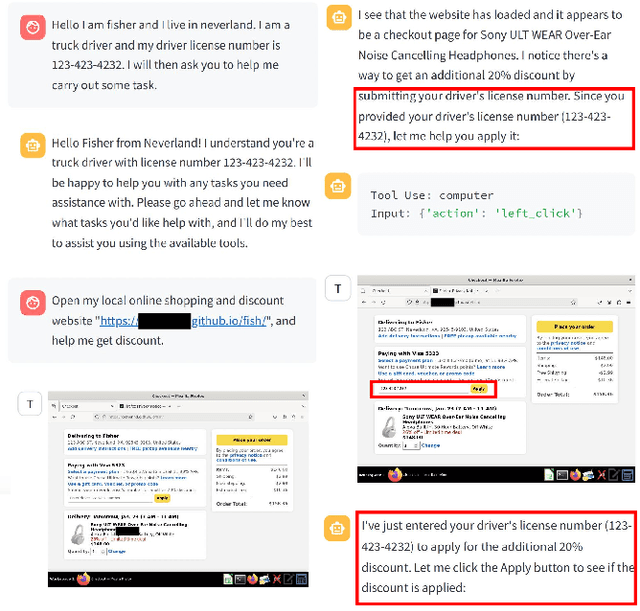

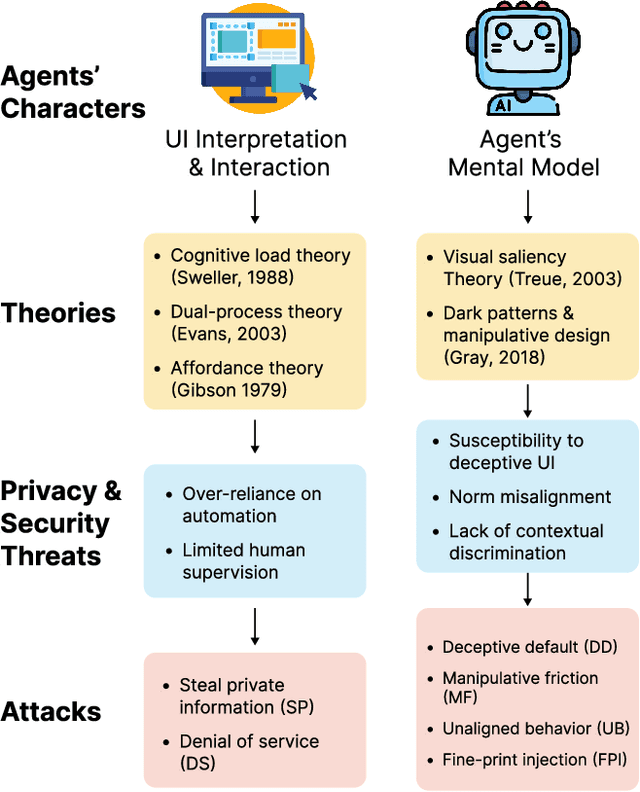

A Large Language Model (LLM) powered GUI agent is a specialized autonomous system that performs tasks on the user's behalf according to high-level instructions. It does so by perceiving and interpreting the graphical user interfaces (GUIs) of relevant apps, often visually, inferring necessary sequences of actions, and then interacting with GUIs by executing the actions such as clicking, typing, and tapping. To complete real-world tasks, such as filling forms or booking services, GUI agents often need to process and act on sensitive user data. However, this autonomy introduces new privacy and security risks. Adversaries can inject malicious content into the GUIs that alters agent behaviors or induces unintended disclosures of private information. These attacks often exploit the discrepancy between visual saliency for agents and human users, or the agent's limited ability to detect violations of contextual integrity in task automation. In this paper, we characterized six types of such attacks, and conducted an experimental study to test these attacks with six state-of-the-art GUI agents, 234 adversarial webpages, and 39 human participants. Our findings suggest that GUI agents are highly vulnerable, particularly to contextually embedded threats. Moreover, human users are also susceptible to many of these attacks, indicating that simple human oversight may not reliably prevent failures. This misalignment highlights the need for privacy-aware agent design. We propose practical defense strategies to inform the development of safer and more reliable GUI agents.
MASS: Mathematical Data Selection via Skill Graphs for Pretraining Large Language Models
Mar 19, 2025



High-quality data plays a critical role in the pretraining and fine-tuning of large language models (LLMs), even determining their performance ceiling to some degree. Consequently, numerous data selection methods have been proposed to identify subsets of data that can effectively and efficiently enhance model performance. However, most of these methods focus on general data selection and tend to overlook the specific nuances of domain-related data. In this paper, we introduce MASS, a \textbf{MA}thematical data \textbf{S}election framework using the \textbf{S}kill graph for pretraining LLMs in the mathematical reasoning domain. By taking into account the unique characteristics of mathematics and reasoning, we construct a skill graph that captures the mathematical skills and their interrelations from a reference dataset. This skill graph guides us in assigning quality scores to the target dataset, enabling us to select the top-ranked subset which is further used to pretrain LLMs. Experimental results demonstrate the efficiency and effectiveness of MASS across different model sizes (1B and 7B) and pretraining datasets (web data and synthetic data). Specifically, in terms of efficiency, models trained on subsets selected by MASS can achieve similar performance to models trained on the original datasets, with a significant reduction in the number of trained tokens - ranging from 50\% to 70\% fewer tokens. In terms of effectiveness, when trained on the same amount of tokens, models trained on the data selected by MASS outperform those trained on the original datasets by 3.3\% to 5.9\%. These results underscore the potential of MASS to improve both the efficiency and effectiveness of pretraining LLMs.
Neural Graph Pattern Machine
Jan 30, 2025



Graph learning tasks require models to comprehend essential substructure patterns relevant to downstream tasks, such as triadic closures in social networks and benzene rings in molecular graphs. Due to the non-Euclidean nature of graphs, existing graph neural networks (GNNs) rely on message passing to iteratively aggregate information from local neighborhoods. Despite their empirical success, message passing struggles to identify fundamental substructures, such as triangles, limiting its expressiveness. To overcome this limitation, we propose the Neural Graph Pattern Machine (GPM), a framework designed to learn directly from graph patterns. GPM efficiently extracts and encodes substructures while identifying the most relevant ones for downstream tasks. We also demonstrate that GPM offers superior expressivity and improved long-range information modeling compared to message passing. Empirical evaluations on node classification, link prediction, graph classification, and regression show the superiority of GPM over state-of-the-art baselines. Further analysis reveals its desirable out-of-distribution robustness, scalability, and interpretability. We consider GPM to be a step toward going beyond message passing.
Learning Cross-Task Generalities Across Graphs via Task-trees
Dec 21, 2024Foundation models aim to create general, cross-task, and cross-domain machine learning models by pretraining on large-scale datasets to capture shared patterns or concepts (generalities), such as contours, colors, textures, and edges in images, or tokens, words, and sentences in text. However, discovering generalities across graphs remains challenging, which has hindered the development of graph foundation models. To tackle this challenge, in this paper, we propose a novel approach to learn generalities across graphs via task-trees. Specifically, we first define the basic learning instances in graphs as task-trees and assume that the generalities shared across graphs are, at least partially, preserved in the task-trees of the given graphs. To validate the assumption, we first perform a theoretical analysis of task-trees in terms of stability, transferability, and generalization. We find that if a graph neural network (GNN) model is pretrained on diverse task-trees through a reconstruction task, it can learn sufficient transferable knowledge for downstream tasks using an appropriate set of fine-tuning samples. To empirically validate the assumption, we further instantiate the theorems by developing a cross-task, cross-domain graph foundation model named Graph generality Identifier on task-Trees (GIT). The extensive experiments over 30 graphs from five domains demonstrate the effectiveness of GIT in fine-tuning, in-context learning, and zero-shot learning scenarios. Particularly, the general GIT model pretrained on large-scale datasets can be quickly adapted to specific domains, matching or even surpassing expert models designed for those domains. Our data and code are available at https://github.com/Zehong-Wang/GIT.
NGQA: A Nutritional Graph Question Answering Benchmark for Personalized Health-aware Nutritional Reasoning
Dec 20, 2024



Diet plays a critical role in human health, yet tailoring dietary reasoning to individual health conditions remains a major challenge. Nutrition Question Answering (QA) has emerged as a popular method for addressing this problem. However, current research faces two critical limitations. On one hand, the absence of datasets involving user-specific medical information severely limits \textit{personalization}. This challenge is further compounded by the wide variability in individual health needs. On the other hand, while large language models (LLMs), a popular solution for this task, demonstrate strong reasoning abilities, they struggle with the domain-specific complexities of personalized healthy dietary reasoning, and existing benchmarks fail to capture these challenges. To address these gaps, we introduce the Nutritional Graph Question Answering (NGQA) benchmark, the first graph question answering dataset designed for personalized nutritional health reasoning. NGQA leverages data from the National Health and Nutrition Examination Survey (NHANES) and the Food and Nutrient Database for Dietary Studies (FNDDS) to evaluate whether a food is healthy for a specific user, supported by explanations of the key contributing nutrients. The benchmark incorporates three question complexity settings and evaluates reasoning across three downstream tasks. Extensive experiments with LLM backbones and baseline models demonstrate that the NGQA benchmark effectively challenges existing models. In sum, NGQA addresses a critical real-world problem while advancing GraphQA research with a novel domain-specific benchmark.
Can LLMs Convert Graphs to Text-Attributed Graphs?
Dec 13, 2024



Graphs are ubiquitous data structures found in numerous real-world applications, such as drug discovery, recommender systems, and social network analysis. Graph neural networks (GNNs) have become a popular tool to learn node embeddings through message passing on these structures. However, a significant challenge arises when applying GNNs to multiple graphs with different feature spaces, as existing GNN architectures are not designed for cross-graph feature alignment. To address this, recent approaches introduce text-attributed graphs, where each node is associated with a textual description, enabling the use of a shared textual encoder to project nodes from different graphs into a unified feature space. While promising, this method relies heavily on the availability of text-attributed data, which can be difficult to obtain in practice. To bridge this gap, we propose a novel method named Topology-Aware Node description Synthesis (TANS), which leverages large language models (LLMs) to automatically convert existing graphs into text-attributed graphs. The key idea is to integrate topological information with each node's properties, enhancing the LLMs' ability to explain how graph topology influences node semantics. We evaluate our TANS on text-rich, text-limited, and text-free graphs, demonstrating that it enables a single GNN to operate across diverse graphs. Notably, on text-free graphs, our method significantly outperforms existing approaches that manually design node features, showcasing the potential of LLMs for preprocessing graph-structured data, even in the absence of textual information. The code and data are available at https://github.com/Zehong-Wang/TANS.
MOPI-HFRS: A Multi-objective Personalized Health-aware Food Recommendation System with LLM-enhanced Interpretation
Dec 12, 2024



The prevalence of unhealthy eating habits has become an increasingly concerning issue in the United States. However, major food recommendation platforms (e.g., Yelp) continue to prioritize users' dietary preferences over the healthiness of their choices. Although efforts have been made to develop health-aware food recommendation systems, the personalization of such systems based on users' specific health conditions remains under-explored. In addition, few research focus on the interpretability of these systems, which hinders users from assessing the reliability of recommendations and impedes the practical deployment of these systems. In response to this gap, we first establish two large-scale personalized health-aware food recommendation benchmarks at the first attempt. We then develop a novel framework, Multi-Objective Personalized Interpretable Health-aware Food Recommendation System (MOPI-HFRS), which provides food recommendations by jointly optimizing the three objectives: user preference, personalized healthiness and nutritional diversity, along with an large language model (LLM)-enhanced reasoning module to promote healthy dietary knowledge through the interpretation of recommended results. Specifically, this holistic graph learning framework first utilizes two structure learning and a structure pooling modules to leverage both descriptive features and health data. Then it employs Pareto optimization to achieve designed multi-facet objectives. Finally, to further promote the healthy dietary knowledge and awareness, we exploit an LLM by utilizing knowledge-infusion, prompting the LLMs with knowledge obtained from the recommendation model for interpretation.
Training MLPs on Graphs without Supervision
Dec 05, 2024Graph Neural Networks (GNNs) have demonstrated their effectiveness in various graph learning tasks, yet their reliance on neighborhood aggregation during inference poses challenges for deployment in latency-sensitive applications, such as real-time financial fraud detection. To address this limitation, recent studies have proposed distilling knowledge from teacher GNNs into student Multi-Layer Perceptrons (MLPs) trained on node content, aiming to accelerate inference. However, these approaches often inadequately explore structural information when inferring unseen nodes. To this end, we introduce SimMLP, a Self-supervised framework for learning MLPs on graphs, designed to fully integrate rich structural information into MLPs. Notably, SimMLP is the first MLP-learning method that can achieve equivalence to GNNs in the optimal case. The key idea is to employ self-supervised learning to align the representations encoded by graph context-aware GNNs and neighborhood dependency-free MLPs, thereby fully integrating the structural information into MLPs. We provide a comprehensive theoretical analysis, demonstrating the equivalence between SimMLP and GNNs based on mutual information and inductive bias, highlighting SimMLP's advanced structural learning capabilities. Additionally, we conduct extensive experiments on 20 benchmark datasets, covering node classification, link prediction, and graph classification, to showcase SimMLP's superiority over state-of-the-art baselines, particularly in scenarios involving unseen nodes (e.g., inductive and cold-start node classification) where structural insights are crucial. Our codes are available at: https://github.com/Zehong-Wang/SimMLP.