 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-UAV Coverage Path Planning for the Inspection of Large and Complex Structures
Jul 26, 2020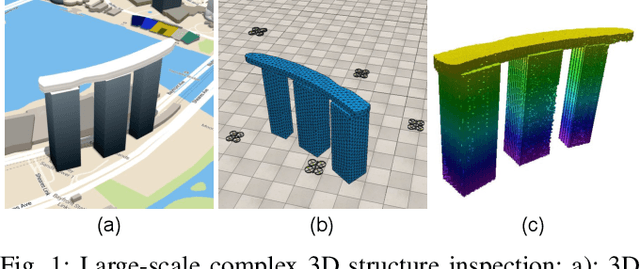
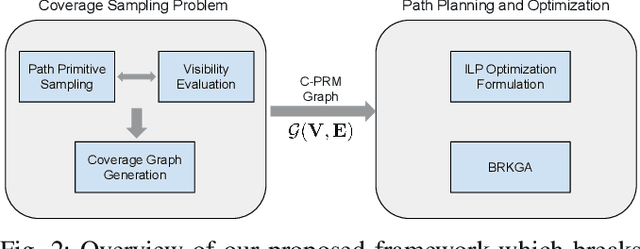
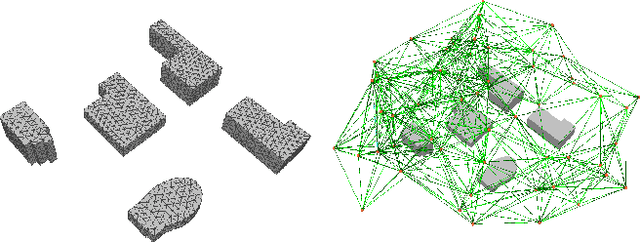
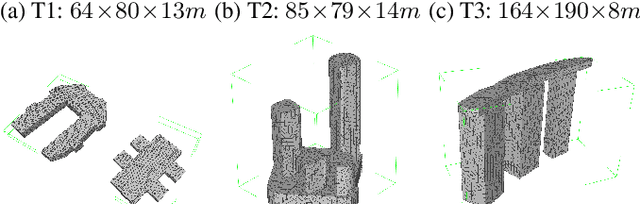
We present a multi-UAV Coverage Path Planning (CPP) framework for the inspection of large-scale, complex 3D structures. In the proposed sampling-based coverage path planning method, we formulate the multi-UAV inspection applications as a multi-agent coverage path planning problem. By combining two NP-hard problems: Set Covering Problem (SCP) and Vehicle Routing Problem (VRP), a Set-Covering Vehicle Routing Problem (SC-VRP) is formulated and subsequently solved by a modified Biased Random Key Genetic Algorithm (BRKGA) with novel, efficient encoding strategies and local improvement heuristics. We test our proposed method for several complex 3D structures with the 3D model extracted from OpenStreetMap. The proposed method outperforms previous methods, by reducing the length of the planned inspection path by up to 48%
Product Kanerva Machines: Factorized Bayesian Memory
Feb 06, 2020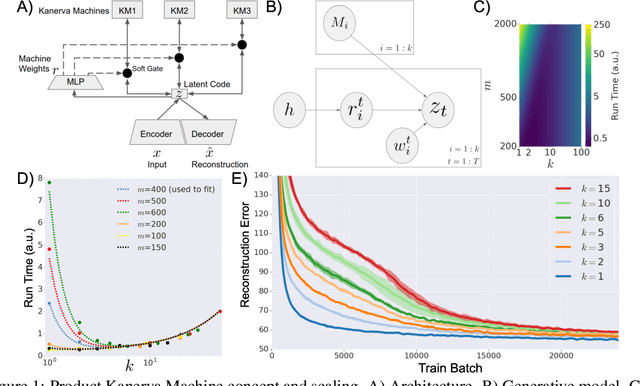
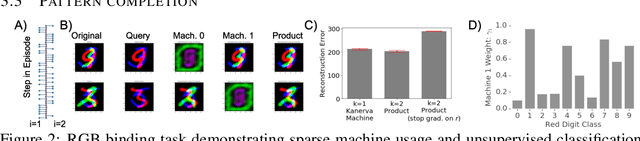
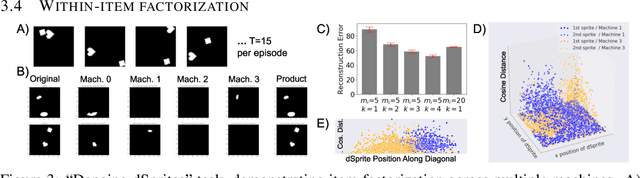
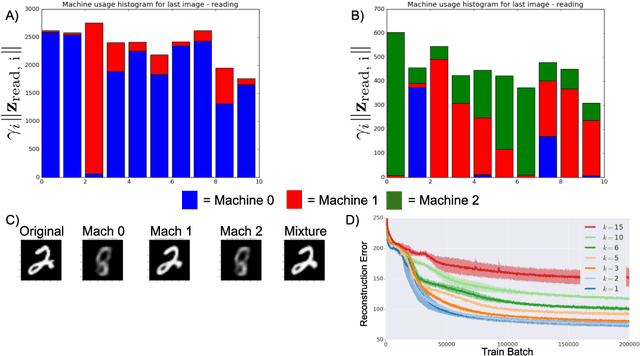
An ideal cognitively-inspired memory system would compress and organize incoming items. The Kanerva Machine (Wu et al, 2018) is a Bayesian model that naturally implements online memory compression. However, the organization of the Kanerva Machine is limited by its use of a single Gaussian random matrix for storage. Here we introduce the Product Kanerva Machine, which dynamically combines many smaller Kanerva Machines. Its hierarchical structure provides a principled way to abstract invariant features and gives scaling and capacity advantages over single Kanerva Machines. We show that it can exhibit unsupervised clustering, find sparse and combinatorial allocation patterns, and discover spatial tunings that approximately factorize simple images by object.
Efficient Robotic Task Generalization Using Deep Model Fusion Reinforcement Learning
Dec 11, 2019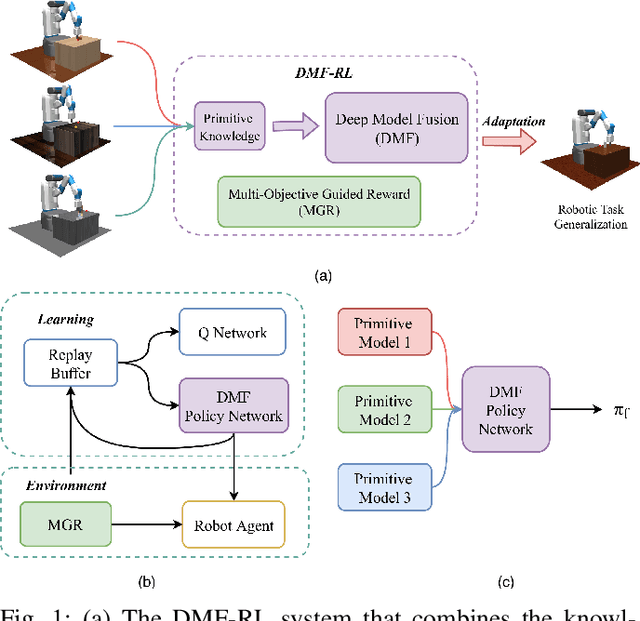
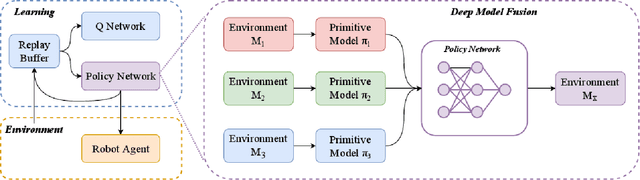
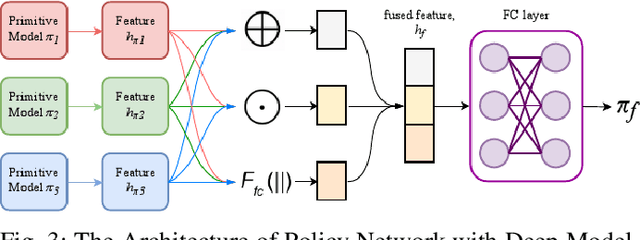
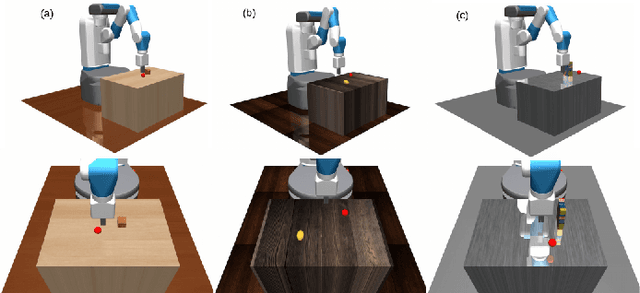
Learning-based methods have been used to pro-gram robotic tasks in recent years. However, extensive training is usually required not only for the initial task learning but also for generalizing the learned model to the same task but in different environments. In this paper, we propose a novel Deep Reinforcement Learning algorithm for efficient task generalization and environment adaptation in the robotic task learning problem. The proposed method is able to efficiently generalize the previously learned task by model fusion to solve the environment adaptation problem. The proposed Deep Model Fusion (DMF) method reuses and combines the previously trained model to improve the learning efficiency and results.Besides, we also introduce a Multi-objective Guided Reward(MGR) shaping technique to further improve training efficiency.The proposed method was benchmarked with previous methods in various environments to validate its effectiveness.
LOGAN: Latent Optimisation for Generative Adversarial Networks
Dec 02, 2019

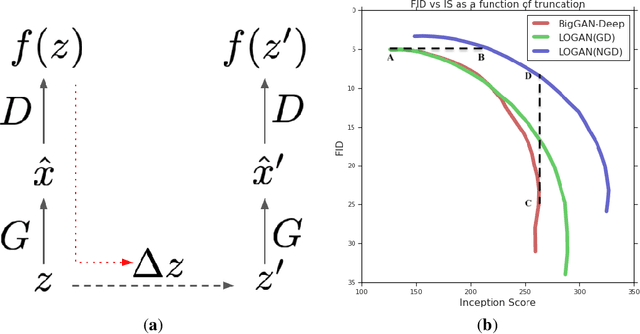
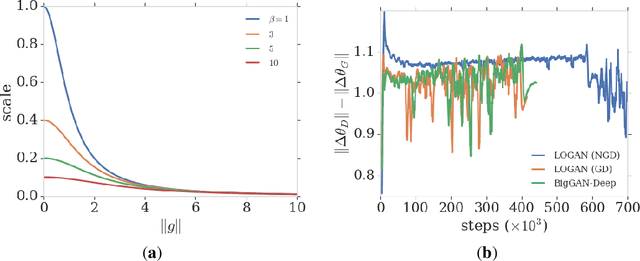
Training generative adversarial networks requires balancing of delicate adversarial dynamics. Even with careful tuning, training may diverge or end up in a bad equilibrium with dropped modes. In this work, we introduce a new form of latent optimisation inspired by the CS-GAN and show that it improves adversarial dynamics by enhancing interactions between the discriminator and the generator. We develop supporting theoretical analysis from the perspectives of differentiable games and stochastic approximation. Our experiments demonstrate that latent optimisation can significantly improve GAN training, obtaining state-of-the-art performance for the ImageNet (128 x 128) dataset. Our model achieves an Inception Score (IS) of 148 and an Fr\'echet Inception Distance (FID) of 3.4, an improvement of 17% and 32% in IS and FID respectively, compared with the baseline BigGAN-deep model with the same architecture and number of parameters.
Pixel-Wise PolSAR Image Classification via a Novel Complex-Valued Deep Fully Convolutional Network
Sep 29, 2019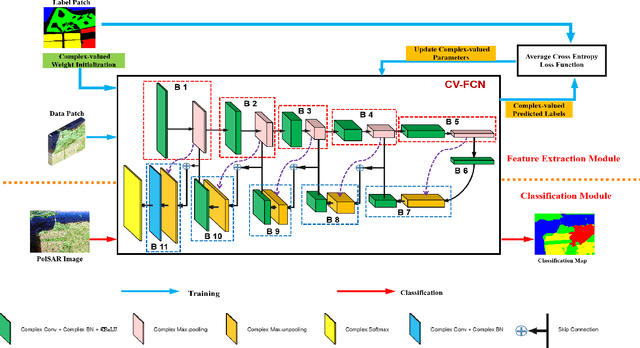
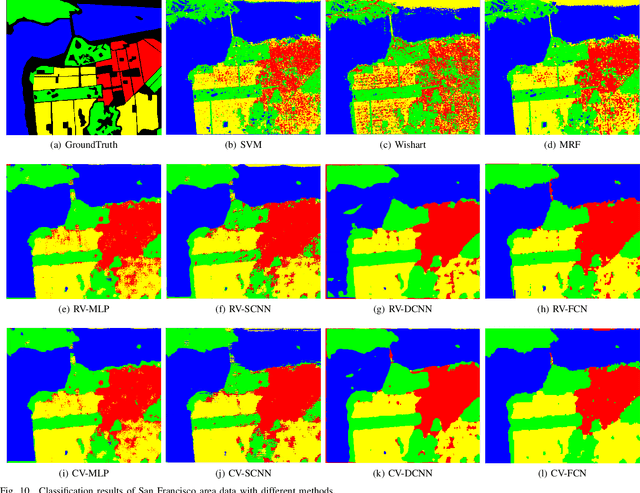
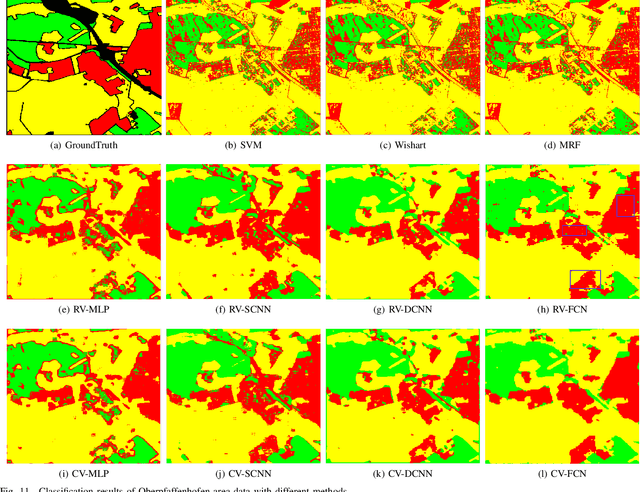
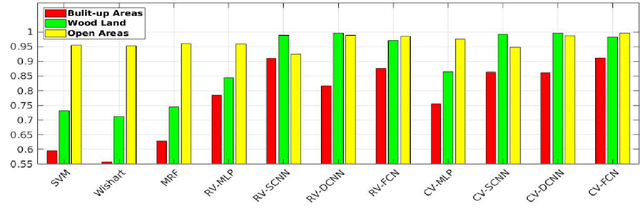
Although complex-valued (CV) neural networks have shown better classification results compared to their real-valued (RV) counterparts for polarimetric synthetic aperture radar (PolSAR) classification, the extension of pixel-level RV networks to the complex domain has not yet thoroughly examined. This paper presents a novel complex-valued deep fully convolutional neural network (CV-FCN) designed for PolSAR image classification. Specifically, CV-FCN uses PolSAR CV data that includes the phase information and utilizes the deep FCN architecture that performs pixel-level labeling. It integrates the feature extraction module and the classification module in a united framework. Technically, for the particularity of PolSAR data, a dedicated complex-valued weight initialization scheme is defined to initialize CV-FCN. It considers the distribution of polarization data to conduct CV-FCN training from scratch in an efficient and fast manner. CV-FCN employs a complex downsampling-then-upsampling scheme to extract dense features. To enrich discriminative information, multi-level CV features that retain more polarization information are extracted via the complex downsampling scheme. Then, a complex upsampling scheme is proposed to predict dense CV labeling. It employs complex max-unpooling layers to greatly capture more spatial information for better robustness to speckle noise. In addition, to achieve faster convergence and obtain more precise classification results, a novel average cross-entropy loss function is derived for CV-FCN optimization. Experiments on real PolSAR datasets demonstrate that CV-FCN achieves better classification performance than other state-of-art methods.
6D Pose Estimation with Correlation Fusion
Sep 24, 2019
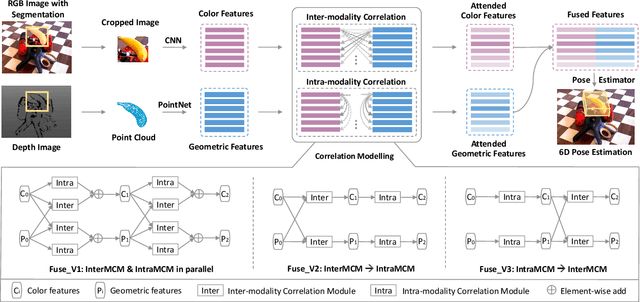
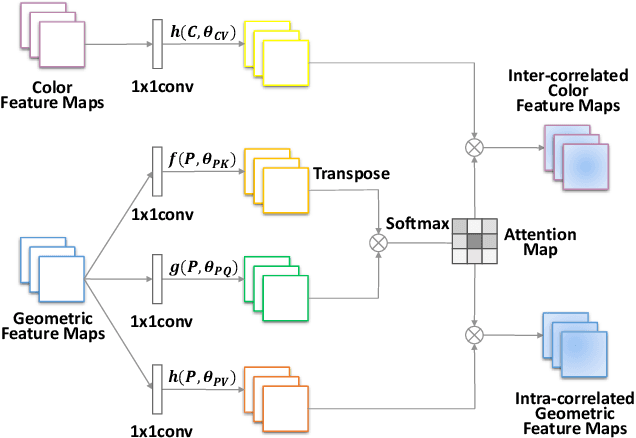

6D object pose estimation is widely applied in robotic tasks such as grasping and manipulation. Prior methods using RGB-only images are vulnerable to heavy occlusion and poor illumination, so it is important to complement them with depth information. However, existing methods using RGB-D data don't adequately exploit consistent and complementary information between two modalities. In this paper, we present a novel method to effectively consider the correlation within and across RGB and depth modalities with attention mechanism to learn discriminative multi-modal features. Then, effective fusion strategies for intra- and inter-correlation modules are explored to ensure efficient information flow between RGB and depth. To the best of our knowledge, this is the first work to explore effective intra- and inter-modality fusion in 6D pose estimation and experimental results show that our method can help achieve the state-of-the-art performance on LineMOD and YCB-Video datasets as well as benefit robot grasping task.
Real-time Multi-target Path Prediction and Planning for Autonomous Driving aided by FCN
Sep 17, 2019
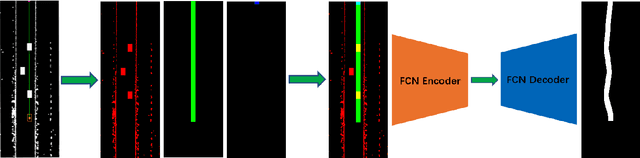
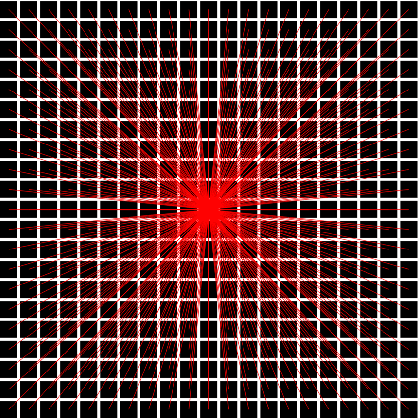
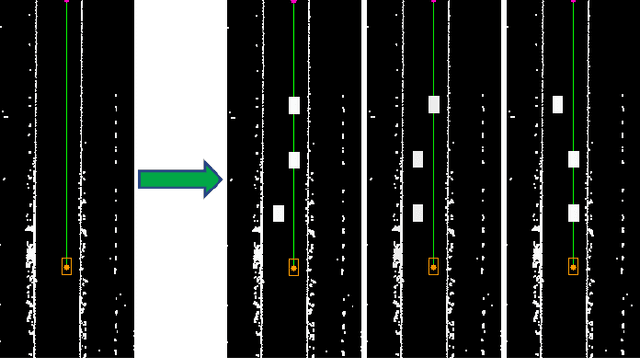
Real-time multi-target path planning is a key issue in the field of autonomous driving. Although multiple paths can be generated in real-time with polynomial curves, the generated paths are not flexible enough to deal with complex road scenes such as S-shaped road and unstructured scenes such as parking lots. Search and sampling-based methods, such as A* and RRT and their derived methods, are flexible in generating paths for these complex road environments. However, the existing algorithms require significant time to plan to multiple targets, which greatly limits their application in autonomous driving. In this paper, a real-time path planning method for multi-targets is proposed. We train a fully convolutional neural network (FCN) to predict a path region for the target at first. By taking the predicted path region as soft constraints, the A* algorithm is then applied to search the exact path to the target. Experiments show that FCN can make multiple predictions in a very short time (50 times in 40ms), and the predicted path region effectively restrict the searching space for the following A* search. Therefore, the A* can search much faster so that the multi-target path planning can be achieved in real-time (3 targets in less than 100ms).
U-net super-neural segmentation and similarity calculation to realize vegetation change assessment in satellite imagery
Sep 10, 2019
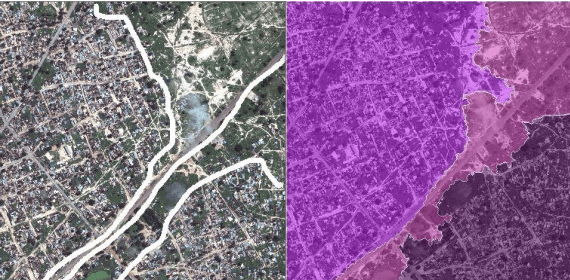
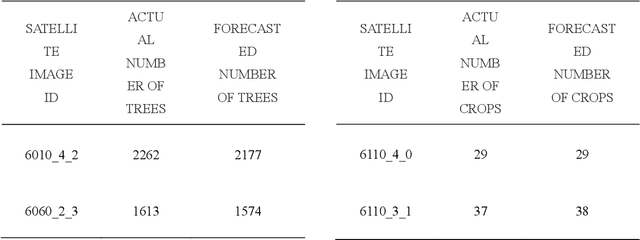
Vegetation is the natural linkage connecting soil, atmosphere and water. It can represent the change of land cover to a certain extent and serve as an indicator for global change research. Methods for measuring coverage can be divided into two types: surface measurement and remote sensing. Because vegetation cover has significant spatial and temporal differentiation characteristics, remote sensing has become an important technical means to estimate vegetation coverage. This paper firstly uses U-net to perform remote sensing image semantic segmentation training, then uses the result of semantic segmentation, and then uses the integral progressive method to calculate the forestland change rate, and finally realizes automated valuation of woodland change rate.
Shaping Belief States with Generative Environment Models for RL
Jun 24, 2019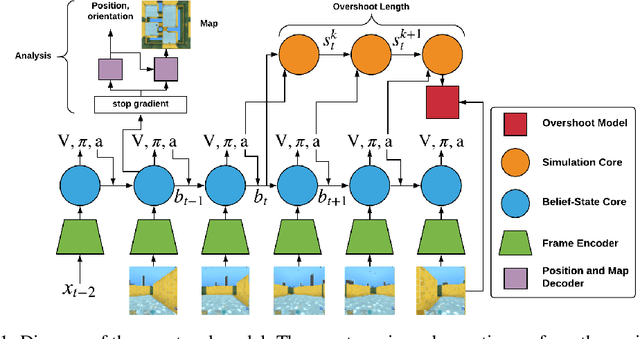


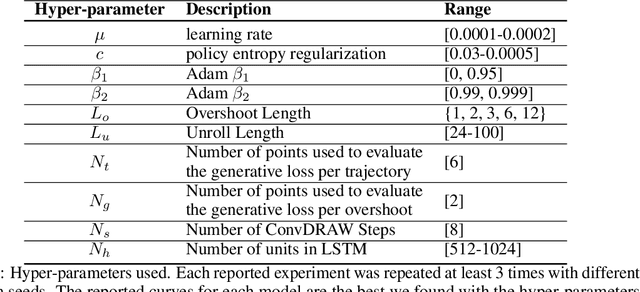
When agents interact with a complex environment, they must form and maintain beliefs about the relevant aspects of that environment. We propose a way to efficiently train expressive generative models in complex environments. We show that a predictive algorithm with an expressive generative model can form stable belief-states in visually rich and dynamic 3D environments. More precisely, we show that the learned representation captures the layout of the environment as well as the position and orientation of the agent. Our experiments show that the model substantially improves data-efficiency on a number of reinforcement learning (RL) tasks compared with strong model-free baseline agents. We find that predicting multiple steps into the future (overshooting), in combination with an expressive generative model, is critical for stable representations to emerge. In practice, using expressive generative models in RL is computationally expensive and we propose a scheme to reduce this computational burden, allowing us to build agents that are competitive with model-free baselines.
Deep Compressed Sensing
May 18, 2019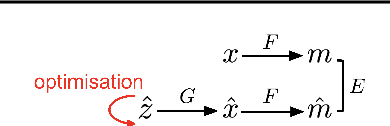

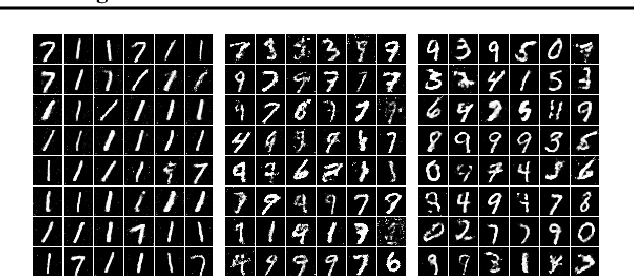
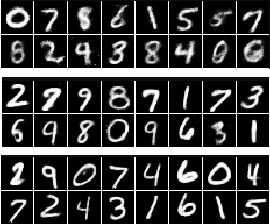
Compressed sensing (CS) provides an elegant framework for recovering sparse signals from compressed measurements. For example, CS can exploit the structure of natural images and recover an image from only a few random measurements. CS is flexible and data efficient, but its application has been restricted by the strong assumption of sparsity and costly reconstruction process. A recent approach that combines CS with neural network generators has removed the constraint of sparsity, but reconstruction remains slow. Here we propose a novel framework that significantly improves both the performance and speed of signal recovery by jointly training a generator and the optimisation process for reconstruction via meta-learning. We explore training the measurements with different objectives, and derive a family of models based on minimising measurement errors. We show that Generative Adversarial Nets (GANs) can be viewed as a special case in this family of models. Borrowing insights from the CS perspective, we develop a novel way of improving GANs using gradient information from the discriminator.