 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
May 05, 2026On-policy distillation (OPD) has recently emerged as an effective post-training paradigm for consolidating the capabilities of specialized expert models into a single student model. Despite its empirical success, the conditions under which OPD yields reliable improvement remain poorly understood. In this work, we identify two fundamental bottlenecks that limit effective OPD: insufficient exploration of informative states and unreliable teacher supervision for student rollouts. Building on this insight, we propose Uni-OPD, a unified OPD framework that generalizes across Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), centered on a dual-perspective optimization strategy. Specifically, from the student's perspective, we adopt two data balancing strategies to promote exploration of informative student-generated states during training. From the teacher's perspective, we show that reliable supervision hinges on whether aggregated token-level guidance remains order-consistent with the outcome reward. To this end, we develop an outcome-guided margin calibration mechanism to restore order consistency between correct and incorrect trajectories. We conduct extensive experiments on 5 domains and 16 benchmarks covering diverse settings, including single-teacher and multi-teacher distillation across LLMs and MLLMs, strong-to-weak distillation, and cross-modal distillation. Our results verify the effectiveness and versatility of Uni-OPD and provide practical insights into reliable OPD.
Direct Behavior Optimization: Unlocking the Potential of Lightweight LLMs
Jun 06, 2025



Lightweight Large Language Models (LwLLMs) are reduced-parameter, optimized models designed to run efficiently on consumer-grade hardware, offering significant advantages in resource efficiency, cost-effectiveness, and data privacy. However, these models often struggle with limited inference and reasoning capabilities, which restrict their performance on complex tasks and limit their practical applicability. Moreover, existing prompt optimization methods typically rely on extensive manual effort or the meta-cognitive abilities of state-of-the-art LLMs, making them less effective for LwLLMs. To address these challenges, we introduce DeBoP, a new Direct Behavior Optimization Paradigm, original from the Chain-of-Thought (CoT) prompting technique. Unlike CoT Prompting, DeBoP is an automatic optimization method, which focuses on the optimization directly on the behavior of LwLLMs. In particular, DeBoP transforms the optimization of complex prompts into the optimization of discrete, quantifiable execution sequences using a gradient-free Monte Carlo Tree Search. We evaluate DeBoP on seven challenging tasks where state-of-the-art LLMs excel but LwLLMs generally underperform. Experimental results demonstrate that DeBoP significantly outperforms recent prompt optimization methods on most tasks. In particular, DeBoP-optimized LwLLMs surpass GPT-3.5 on most tasks while reducing computational time by approximately 60% compared to other automatic prompt optimization methods.
Efffcient Sensing Parameter Estimation with Direct Clutter Mitigation in Perceptive Mobile Networks
Jul 24, 2024



In this work, we investigate sensing parameter estimation in the presence of clutter in perceptive mobile networks (PMNs) that integrate radar sensing into mobile communications. Performing clutter suppression before sensing parameter estimation is generally desirable as the number of sensing parameters can be signiffcantly reduced. However, existing methods require high-complexity clutter mitigation and sensing parameter estimation, where clutter is ffrstly identiffed and then removed. In this correspondence, we propose a much simpler but more effective method by incorporating a clutter cancellation mechanism in formulating a sparse signal model for sensing parameter estimation. In particular, clutter mitigation is performed directly on the received signals and the unitary approximate message passing (UAMP) is leveraged to exploit the common support for sensing parameter estimation in the formulated sparse signal recovery problem. Simulation results show that, compared to state-of-theart methods, the proposed method delivers signiffcantly better performance while with substantially reduced complexity.
U-net super-neural segmentation and similarity calculation to realize vegetation change assessment in satellite imagery
Sep 10, 2019
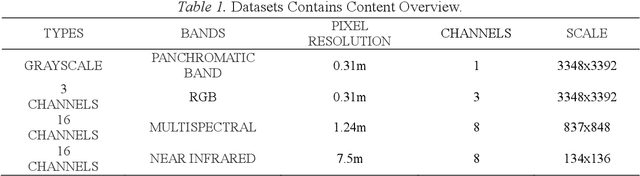
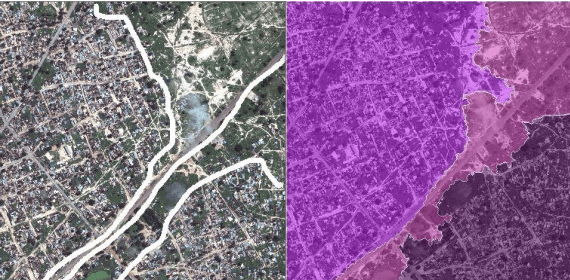
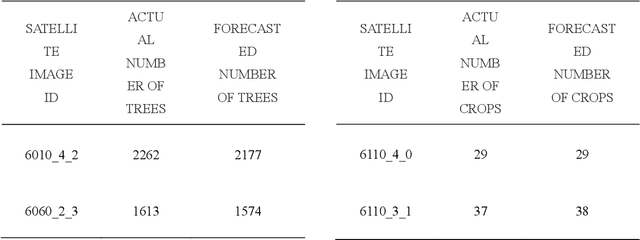
Vegetation is the natural linkage connecting soil, atmosphere and water. It can represent the change of land cover to a certain extent and serve as an indicator for global change research. Methods for measuring coverage can be divided into two types: surface measurement and remote sensing. Because vegetation cover has significant spatial and temporal differentiation characteristics, remote sensing has become an important technical means to estimate vegetation coverage. This paper firstly uses U-net to perform remote sensing image semantic segmentation training, then uses the result of semantic segmentation, and then uses the integral progressive method to calculate the forestland change rate, and finally realizes automated valuation of woodland change rate.