 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaGMLP: AdaBoosting GNN-to-MLP Knowledge Distillation
May 23, 2024



Graph Neural Networks (GNNs) have revolutionized graph-based machine learning, but their heavy computational demands pose challenges for latency-sensitive edge devices in practical industrial applications. In response, a new wave of methods, collectively known as GNN-to-MLP Knowledge Distillation, has emerged. They aim to transfer GNN-learned knowledge to a more efficient MLP student, which offers faster, resource-efficient inference while maintaining competitive performance compared to GNNs. However, these methods face significant challenges in situations with insufficient training data and incomplete test data, limiting their applicability in real-world applications. To address these challenges, we propose AdaGMLP, an AdaBoosting GNN-to-MLP Knowledge Distillation framework. It leverages an ensemble of diverse MLP students trained on different subsets of labeled nodes, addressing the issue of insufficient training data. Additionally, it incorporates a Node Alignment technique for robust predictions on test data with missing or incomplete features. Our experiments on seven benchmark datasets with different settings demonstrate that AdaGMLP outperforms existing G2M methods, making it suitable for a wide range of latency-sensitive real-world applications. We have submitted our code to the GitHub repository (https://github.com/WeigangLu/AdaGMLP-KDD24).
* Accepted by KDD 2024
Deep Learning-Based Detection for Marker Codes over Insertion and Deletion Channels
Jan 02, 2024Marker code is an effective coding scheme to protect data from insertions and deletions. It has potential applications in future storage systems, such as DNA storage and racetrack memory. When decoding marker codes, perfect channel state information (CSI), i.e., insertion and deletion probabilities, are required to detect insertion and deletion errors. Sometimes, the perfect CSI is not easy to obtain or the accurate channel model is unknown. Therefore, it is deserved to develop detecting algorithms for marker code without the knowledge of perfect CSI. In this paper, we propose two CSI-agnostic detecting algorithms for marker code based on deep learning. The first one is a model-driven deep learning method, which deep unfolds the original iterative detecting algorithm of marker code. In this method, CSI become weights in neural networks and these weights can be learned from training data. The second one is a data-driven method which is an end-to-end system based on the deep bidirectional gated recurrent unit network. Simulation results show that error performances of the proposed methods are significantly better than that of the original detection algorithm with CSI uncertainty. Furthermore, the proposed data-driven method exhibits better error performances than other methods for unknown channel models.
NodeMixup: Tackling Under-Reaching for Graph Neural Networks
Dec 21, 2023Graph Neural Networks (GNNs) have become mainstream methods for solving the semi-supervised node classification problem. However, due to the uneven location distribution of labeled nodes in the graph, labeled nodes are only accessible to a small portion of unlabeled nodes, leading to the \emph{under-reaching} issue. In this study, we firstly reveal under-reaching by conducting an empirical investigation on various well-known graphs. Then, we demonstrate that under-reaching results in unsatisfactory distribution alignment between labeled and unlabeled nodes through systematic experimental analysis, significantly degrading GNNs' performance. To tackle under-reaching for GNNs, we propose an architecture-agnostic method dubbed NodeMixup. The fundamental idea is to (1) increase the reachability of labeled nodes by labeled-unlabeled pairs mixup, (2) leverage graph structures via fusing the neighbor connections of intra-class node pairs to improve performance gains of mixup, and (3) use neighbor label distribution similarity incorporating node degrees to determine sampling weights for node mixup. Extensive experiments demonstrate the efficacy of NodeMixup in assisting GNNs in handling under-reaching. The source code is available at \url{https://github.com/WeigangLu/NodeMixup}.
Self-Supervised Multi-Modal Sequential Recommendation
Apr 26, 2023



With the increasing development of e-commerce and online services, personalized recommendation systems have become crucial for enhancing user satisfaction and driving business revenue. Traditional sequential recommendation methods that rely on explicit item IDs encounter challenges in handling item cold start and domain transfer problems. Recent approaches have attempted to use modal features associated with items as a replacement for item IDs, enabling the transfer of learned knowledge across different datasets. However, these methods typically calculate the correlation between the model's output and item embeddings, which may suffer from inconsistencies between high-level feature vectors and low-level feature embeddings, thereby hindering further model learning. To address this issue, we propose a dual-tower retrieval architecture for sequence recommendation. In this architecture, the predicted embedding from the user encoder is used to retrieve the generated embedding from the item encoder, thereby alleviating the issue of inconsistent feature levels. Moreover, in order to further improve the retrieval performance of the model, we also propose a self-supervised multi-modal pretraining method inspired by the consistency property of contrastive learning. This pretraining method enables the model to align various feature combinations of items, thereby effectively generalizing to diverse datasets with different item features. We evaluate the proposed method on five publicly available datasets and conduct extensive experiments. The results demonstrate significant performance improvement of our method.
Pseudo Contrastive Learning for Graph-based Semi-supervised Learning
Feb 19, 2023



Pseudo Labeling is a technique used to improve the performance of semi-supervised Graph Neural Networks (GNNs) by generating additional pseudo-labels based on confident predictions. However, the quality of generated pseudo-labels has long been a concern due to the sensitivity of the classification objective to given labels. To avoid the untrustworthy classification supervision indicating ``a node belongs to a specific class,'' we favor the fault-tolerant contrasting supervision demonstrating ``two nodes do not belong to the same class.'' Thus, the problem of generating high-quality pseudo-labels is then transformed into a relaxed version, i.e., finding reliable contrasting pairs. To achieve this, we propose a general framework for GNNs, termed Pseudo Contrastive Learning (PCL). It separates two nodes whose positive and negative pseudo-labels target the same class. To incorporate topological knowledge into learning, we devise a topologically weighted contrastive loss that spends more effort separating negative pairs with smaller topological distances. Additionally, to alleviate the heavy reliance on data augmentation, we augment nodes only by applying dropout to the encoded representations. Theoretically, we prove that PCL with the lightweight augmentation works like a representation regularizer to effectively learn separation between negative pairs. Experimentally, we employ PCL on various models, which consistently outperform their counterparts using other popular general techniques on five real-world graphs.
Convolution-enhanced Evolving Attention Networks
Dec 16, 2022



Attention-based neural networks, such as Transformers, have become ubiquitous in numerous applications, including computer vision, natural language processing, and time-series analysis. In all kinds of attention networks, the attention maps are crucial as they encode semantic dependencies between input tokens. However, most existing attention networks perform modeling or reasoning based on representations, wherein the attention maps of different layers are learned separately without explicit interactions. In this paper, we propose a novel and generic evolving attention mechanism, which directly models the evolution of inter-token relationships through a chain of residual convolutional modules. The major motivations are twofold. On the one hand, the attention maps in different layers share transferable knowledge, thus adding a residual connection can facilitate the information flow of inter-token relationships across layers. On the other hand, there is naturally an evolutionary trend among attention maps at different abstraction levels, so it is beneficial to exploit a dedicated convolution-based module to capture this process. Equipped with the proposed mechanism, the convolution-enhanced evolving attention networks achieve superior performance in various applications, including time-series representation, natural language understanding, machine translation, and image classification. Especially on time-series representation tasks, Evolving Attention-enhanced Dilated Convolutional (EA-DC-) Transformer outperforms state-of-the-art models significantly, achieving an average of 17% improvement compared to the best SOTA. To the best of our knowledge, this is the first work that explicitly models the layer-wise evolution of attention maps. Our implementation is available at https://github.com/pkuyym/EvolvingAttention
MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation
Nov 16, 2022



Responding with multi-modal content has been recognized as an essential capability for an intelligent conversational agent. In this paper, we introduce the MMDialog dataset to better facilitate multi-modal conversation. MMDialog is composed of a curated set of 1.08 million real-world dialogues with 1.53 million unique images across 4,184 topics. MMDialog has two main and unique advantages. First, it is the largest multi-modal conversation dataset by the number of dialogues by 88x. Second, it contains massive topics to generalize the open-domain. To build engaging dialogue system with this dataset, we propose and normalize two response producing tasks based on retrieval and generative scenarios. In addition, we build two baselines for above tasks with state-of-the-art techniques and report their experimental performance. We also propose a novel evaluation metric MM-Relevance to measure the multi-modal responses. Our dataset and scripts are available in https://github.com/victorsungo/MMDialog.
Self-supervised Heterogeneous Graph Pre-training Based on Structural Clustering
Oct 19, 2022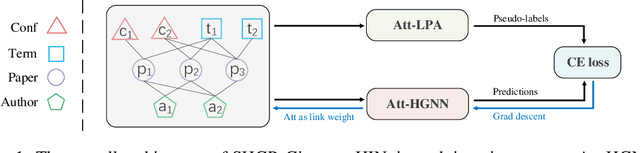

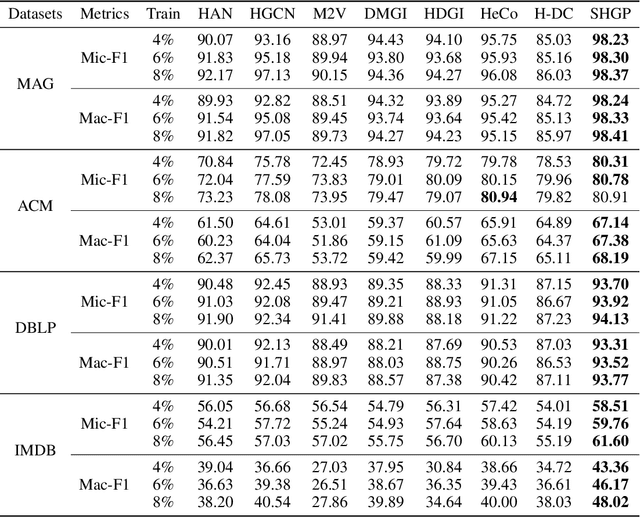
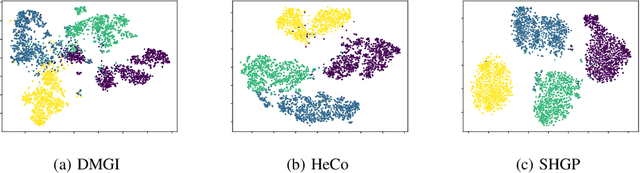
Recent self-supervised pre-training methods on Heterogeneous Information Networks (HINs) have shown promising competitiveness over traditional semi-supervised Heterogeneous Graph Neural Networks (HGNNs). Unfortunately, their performance heavily depends on careful customization of various strategies for generating high-quality positive examples and negative examples, which notably limits their flexibility and generalization ability. In this work, we present SHGP, a novel Self-supervised Heterogeneous Graph Pre-training approach, which does not need to generate any positive examples or negative examples. It consists of two modules that share the same attention-aggregation scheme. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. The two modules can effectively utilize and enhance each other, promoting the model to learn discriminative embeddings. Extensive experiments on four real-world datasets demonstrate the superior effectiveness of SHGP against state-of-the-art unsupervised baselines and even semi-supervised baselines. We release our source code at: https://github.com/kepsail/SHGP.
Entropy Induced Pruning Framework for Convolutional Neural Networks
Aug 13, 2022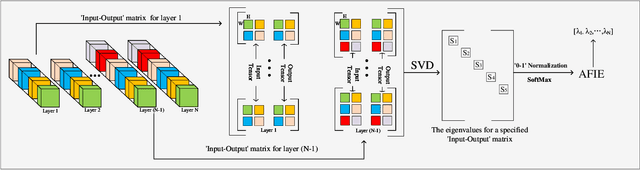
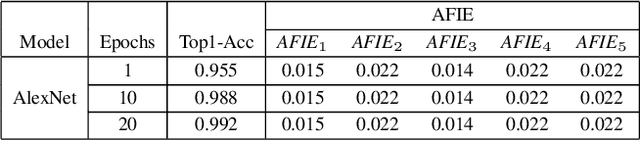
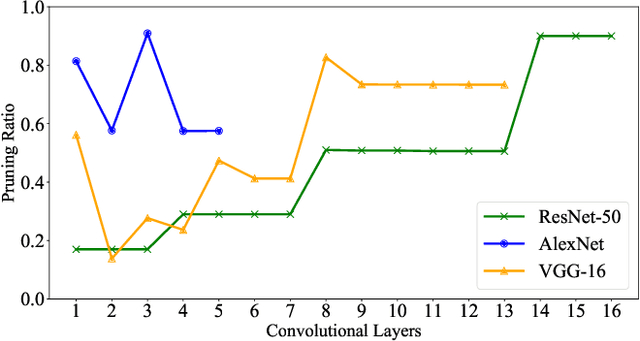

Structured pruning techniques have achieved great compression performance on convolutional neural networks for image classification task. However, the majority of existing methods are weight-oriented, and their pruning results may be unsatisfactory when the original model is trained poorly. That is, a fully-trained model is required to provide useful weight information. This may be time-consuming, and the pruning results are sensitive to the updating process of model parameters. In this paper, we propose a metric named Average Filter Information Entropy (AFIE) to measure the importance of each filter. It is calculated by three major steps, i.e., low-rank decomposition of the "input-output" matrix of each convolutional layer, normalization of the obtained eigenvalues, and calculation of filter importance based on information entropy. By leveraging the proposed AFIE, the proposed framework is able to yield a stable importance evaluation of each filter no matter whether the original model is trained fully. We implement our AFIE based on AlexNet, VGG-16, and ResNet-50, and test them on MNIST, CIFAR-10, and ImageNet, respectively. The experimental results are encouraging. We surprisingly observe that for our methods, even when the original model is only trained with one epoch, the importance evaluation of each filter keeps identical to the results when the model is fully-trained. This indicates that the proposed pruning strategy can perform effectively at the beginning stage of the training process for the original model.
Binary Classification with Positive Labeling Sources
Aug 02, 2022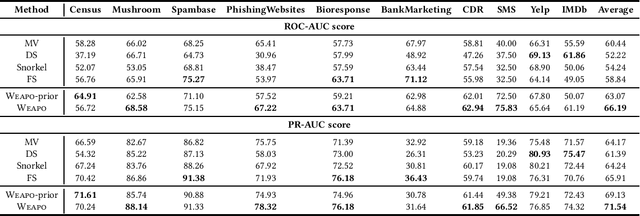
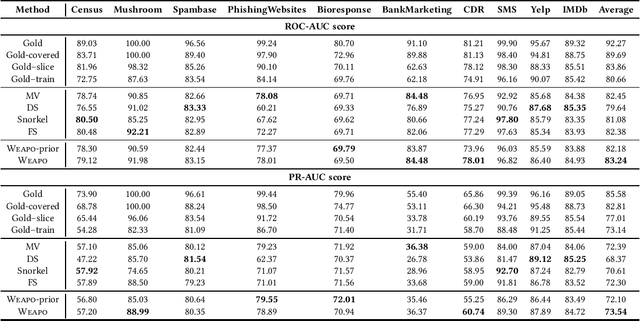
To create a large amount of training labels for machine learning models effectively and efficiently, researchers have turned to Weak Supervision (WS), which uses programmatic labeling sources rather than manual annotation. Existing works of WS for binary classification typically assume the presence of labeling sources that are able to assign both positive and negative labels to data in roughly balanced proportions. However, for many tasks of interest where there is a minority positive class, negative examples could be too diverse for developers to generate indicative labeling sources. Thus, in this work, we study the application of WS on binary classification tasks with positive labeling sources only. We propose WEAPO, a simple yet competitive WS method for producing training labels without negative labeling sources. On 10 benchmark datasets, we show WEAPO achieves the highest averaged performance in terms of both the quality of synthesized labels and the performance of the final classifier supervised with these labels. We incorporated the implementation of \method into WRENCH, an existing benchmarking platform.