 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025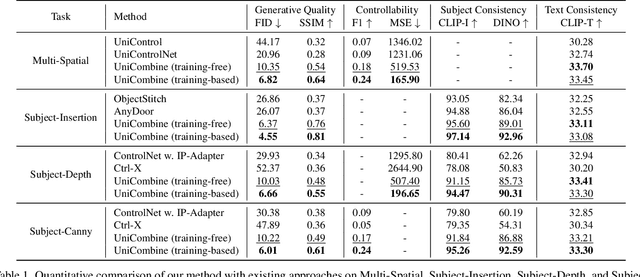
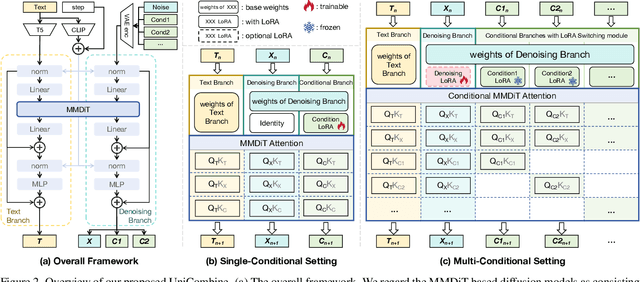
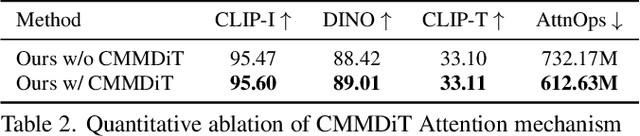
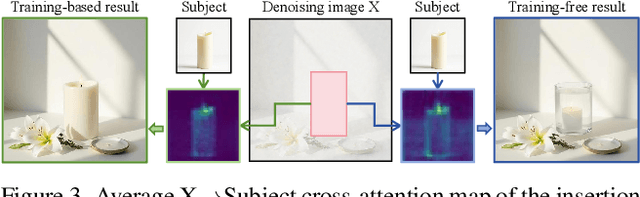
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
Improving Autoregressive Visual Generation with Cluster-Oriented Token Prediction
Jan 01, 2025



Employing LLMs for visual generation has recently become a research focus. However, the existing methods primarily transfer the LLM architecture to visual generation but rarely investigate the fundamental differences between language and vision. This oversight may lead to suboptimal utilization of visual generation capabilities within the LLM framework. In this paper, we explore the characteristics of visual embedding space under the LLM framework and discover that the correlation between visual embeddings can help achieve more stable and robust generation results. We present IAR, an Improved AutoRegressive Visual Generation Method that enhances the training efficiency and generation quality of LLM-based visual generation models. Firstly, we propose a Codebook Rearrangement strategy that uses balanced k-means clustering algorithm to rearrange the visual codebook into clusters, ensuring high similarity among visual features within each cluster. Leveraging the rearranged codebook, we propose a Cluster-oriented Cross-entropy Loss that guides the model to correctly predict the cluster where the token is located. This approach ensures that even if the model predicts the wrong token index, there is a high probability the predicted token is located in the correct cluster, which significantly enhances the generation quality and robustness. Extensive experiments demonstrate that our method consistently enhances the model training efficiency and performance from 100M to 1.4B, reducing the training time by half while achieving the same FID. Additionally, our approach can be applied to various LLM-based visual generation models and adheres to the scaling law, providing a promising direction for future research in LLM-based visual generation.
EMOv2: Pushing 5M Vision Model Frontier
Dec 09, 2024



This work focuses on developing parameter-efficient and lightweight models for dense predictions while trading off parameters, FLOPs, and performance. Our goal is to set up the new frontier of the 5M magnitude lightweight model on various downstream tasks. Inverted Residual Block (IRB) serves as the infrastructure for lightweight CNNs, but no counterparts have been recognized by attention-based design. Our work rethinks the lightweight infrastructure of efficient IRB and practical components in Transformer from a unified perspective, extending CNN-based IRB to attention-based models and abstracting a one-residual Meta Mobile Block (MMBlock) for lightweight model design. Following neat but effective design criterion, we deduce a modern Improved Inverted Residual Mobile Block (i2RMB) and improve a hierarchical Efficient MOdel (EMOv2) with no elaborate complex structures. Considering the imperceptible latency for mobile users when downloading models under 4G/5G bandwidth and ensuring model performance, we investigate the performance upper limit of lightweight models with a magnitude of 5M. Extensive experiments on various vision recognition, dense prediction, and image generation tasks demonstrate the superiority of our EMOv2 over state-of-the-art methods, e.g., EMOv2-1M/2M/5M achieve 72.3, 75.8, and 79.4 Top-1 that surpass equal-order CNN-/Attention-based models significantly. At the same time, EMOv2-5M equipped RetinaNet achieves 41.5 mAP for object detection tasks that surpasses the previous EMO-5M by +2.6. When employing the more robust training recipe, our EMOv2-5M eventually achieves 82.9 Top-1 accuracy, which elevates the performance of 5M magnitude models to a new level. Code is available at https://github.com/zhangzjn/EMOv2.
Exploring Real&Synthetic Dataset and Linear Attention in Image Restoration
Dec 05, 2024



Image Restoration aims to restore degraded images, with deep learning, especially CNNs and Transformers, enhancing performance. However, there's a lack of a unified training benchmark for IR. We identified a bias in image complexity between training and testing datasets, affecting restoration quality. To address this, we created ReSyn, a large-scale IR dataset with balanced complexity, including real and synthetic images. We also established a unified training standard for IR models. Our RWKV-IR model integrates linear complexity RWKV into transformers for global and local receptive fields. It replaces Q-Shift with Depth-wise Convolution for local dependencies and combines Bi-directional attention for global-local awareness. The Cross-Bi-WKV module balances horizontal and vertical attention. Experiments show RWKV-IR's effectiveness in image restoration.
DynamicControl: Adaptive Condition Selection for Improved Text-to-Image Generation
Dec 04, 2024



To enhance the controllability of text-to-image diffusion models, current ControlNet-like models have explored various control signals to dictate image attributes. However, existing methods either handle conditions inefficiently or use a fixed number of conditions, which does not fully address the complexity of multiple conditions and their potential conflicts. This underscores the need for innovative approaches to manage multiple conditions effectively for more reliable and detailed image synthesis. To address this issue, we propose a novel framework, DynamicControl, which supports dynamic combinations of diverse control signals, allowing adaptive selection of different numbers and types of conditions. Our approach begins with a double-cycle controller that generates an initial real score sorting for all input conditions by leveraging pre-trained conditional generation models and discriminative models. This controller evaluates the similarity between extracted conditions and input conditions, as well as the pixel-level similarity with the source image. Then, we integrate a Multimodal Large Language Model (MLLM) to build an efficient condition evaluator. This evaluator optimizes the ordering of conditions based on the double-cycle controller's score ranking. Our method jointly optimizes MLLMs and diffusion models, utilizing MLLMs' reasoning capabilities to facilitate multi-condition text-to-image (T2I) tasks. The final sorted conditions are fed into a parallel multi-control adapter, which learns feature maps from dynamic visual conditions and integrates them to modulate ControlNet, thereby enhancing control over generated images. Through both quantitative and qualitative comparisons, DynamicControl demonstrates its superiority over existing methods in terms of controllability, generation quality and composability under various conditional controls.
MobileMamba: Lightweight Multi-Receptive Visual Mamba Network
Nov 24, 2024



Previous research on lightweight models has primarily focused on CNNs and Transformer-based designs. CNNs, with their local receptive fields, struggle to capture long-range dependencies, while Transformers, despite their global modeling capabilities, are limited by quadratic computational complexity in high-resolution scenarios. Recently, state-space models have gained popularity in the visual domain due to their linear computational complexity. Despite their low FLOPs, current lightweight Mamba-based models exhibit suboptimal throughput. In this work, we propose the MobileMamba framework, which balances efficiency and performance. We design a three-stage network to enhance inference speed significantly. At a fine-grained level, we introduce the Multi-Receptive Field Feature Interaction(MRFFI) module, comprising the Long-Range Wavelet Transform-Enhanced Mamba(WTE-Mamba), Efficient Multi-Kernel Depthwise Convolution(MK-DeConv), and Eliminate Redundant Identity components. This module integrates multi-receptive field information and enhances high-frequency detail extraction. Additionally, we employ training and testing strategies to further improve performance and efficiency. MobileMamba achieves up to 83.6% on Top-1, surpassing existing state-of-the-art methods which is maximum x21 faster than LocalVim on GPU. Extensive experiments on high-resolution downstream tasks demonstrate that MobileMamba surpasses current efficient models, achieving an optimal balance between speed and accuracy.
Textual Decomposition Then Sub-motion-space Scattering for Open-Vocabulary Motion Generation
Nov 06, 2024



Text-to-motion generation is a crucial task in computer vision, which generates the target 3D motion by the given text. The existing annotated datasets are limited in scale, resulting in most existing methods overfitting to the small datasets and unable to generalize to the motions of the open domain. Some methods attempt to solve the open-vocabulary motion generation problem by aligning to the CLIP space or using the Pretrain-then-Finetuning paradigm. However, the current annotated dataset's limited scale only allows them to achieve mapping from sub-text-space to sub-motion-space, instead of mapping between full-text-space and full-motion-space (full mapping), which is the key to attaining open-vocabulary motion generation. To this end, this paper proposes to leverage the atomic motion (simple body part motions over a short time period) as an intermediate representation, and leverage two orderly coupled steps, i.e., Textual Decomposition and Sub-motion-space Scattering, to address the full mapping problem. For Textual Decomposition, we design a fine-grained description conversion algorithm, and combine it with the generalization ability of a large language model to convert any given motion text into atomic texts. Sub-motion-space Scattering learns the compositional process from atomic motions to the target motions, to make the learned sub-motion-space scattered to form the full-motion-space. For a given motion of the open domain, it transforms the extrapolation into interpolation and thereby significantly improves generalization. Our network, $DSO$-Net, combines textual $d$ecomposition and sub-motion-space $s$cattering to solve the $o$pen-vocabulary motion generation. Extensive experiments demonstrate that our DSO-Net achieves significant improvements over the state-of-the-art methods on open-vocabulary motion generation. Code is available at https://vankouf.github.io/DSONet/.
OSV: One Step is Enough for High-Quality Image to Video Generation
Sep 17, 2024



Video diffusion models have shown great potential in generating high-quality videos, making them an increasingly popular focus. However, their inherent iterative nature leads to substantial computational and time costs. While efforts have been made to accelerate video diffusion by reducing inference steps (through techniques like consistency distillation) and GAN training (these approaches often fall short in either performance or training stability). In this work, we introduce a two-stage training framework that effectively combines consistency distillation with GAN training to address these challenges. Additionally, we propose a novel video discriminator design, which eliminates the need for decoding the video latents and improves the final performance. Our model is capable of producing high-quality videos in merely one-step, with the flexibility to perform multi-step refinement for further performance enhancement. Our quantitative evaluation on the OpenWebVid-1M benchmark shows that our model significantly outperforms existing methods. Notably, our 1-step performance(FVD 171.15) exceeds the 8-step performance of the consistency distillation based method, AnimateLCM (FVD 184.79), and approaches the 25-step performance of advanced Stable Video Diffusion (FVD 156.94).
Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection
Sep 16, 2024



Open-vocabulary detection (OVD) aims to detect objects beyond a predefined set of categories. As a pioneering model incorporating the YOLO series into OVD, YOLO-World is well-suited for scenarios prioritizing speed and efficiency. However, its performance is hindered by its neck feature fusion mechanism, which causes the quadratic complexity and the limited guided receptive fields. To address these limitations, we present Mamba-YOLO-World, a novel YOLO-based OVD model employing the proposed MambaFusion Path Aggregation Network (MambaFusion-PAN) as its neck architecture. Specifically, we introduce an innovative State Space Model-based feature fusion mechanism consisting of a Parallel-Guided Selective Scan algorithm and a Serial-Guided Selective Scan algorithm with linear complexity and globally guided receptive fields. It leverages multi-modal input sequences and mamba hidden states to guide the selective scanning process. Experiments demonstrate that our model outperforms the original YOLO-World on the COCO and LVIS benchmarks in both zero-shot and fine-tuning settings while maintaining comparable parameters and FLOPs. Additionally, it surpasses existing state-of-the-art OVD methods with fewer parameters and FLOPs.