 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
How Order-Sensitive Are LLMs? OrderProbe for Deterministic Structural Reconstruction
Jan 13, 2026Large language models (LLMs) excel at semantic understanding, yet their ability to reconstruct internal structure from scrambled inputs remains underexplored. Sentence-level restoration is ill-posed for automated evaluation because multiple valid word orders often exist. We introduce OrderProbe, a deterministic benchmark for structural reconstruction using fixed four-character expressions in Chinese, Japanese, and Korean, which have a unique canonical order and thus support exact-match scoring. We further propose a diagnostic framework that evaluates models beyond recovery accuracy, including semantic fidelity, logical validity, consistency, robustness sensitivity, and information density. Experiments on twelve widely used LLMs show that structural reconstruction remains difficult even for frontier systems: zero-shot recovery frequently falls below 35%. We also observe a consistent dissociation between semantic recall and structural planning, suggesting that structural robustness is not an automatic byproduct of semantic competence.
HSSBench: Benchmarking Humanities and Social Sciences Ability for Multimodal Large Language Models
Jun 04, 2025



Multimodal Large Language Models (MLLMs) have demonstrated significant potential to advance a broad range of domains. However, current benchmarks for evaluating MLLMs primarily emphasize general knowledge and vertical step-by-step reasoning typical of STEM disciplines, while overlooking the distinct needs and potential of the Humanities and Social Sciences (HSS). Tasks in the HSS domain require more horizontal, interdisciplinary thinking and a deep integration of knowledge across related fields, which presents unique challenges for MLLMs, particularly in linking abstract concepts with corresponding visual representations. Addressing this gap, we present HSSBench, a dedicated benchmark designed to assess the capabilities of MLLMs on HSS tasks in multiple languages, including the six official languages of the United Nations. We also introduce a novel data generation pipeline tailored for HSS scenarios, in which multiple domain experts and automated agents collaborate to generate and iteratively refine each sample. HSSBench contains over 13,000 meticulously designed samples, covering six key categories. We benchmark more than 20 mainstream MLLMs on HSSBench and demonstrate that it poses significant challenges even for state-of-the-art models. We hope that this benchmark will inspire further research into enhancing the cross-disciplinary reasoning abilities of MLLMs, especially their capacity to internalize and connect knowledge across fields.
Accelerated Robot Learning via Human Brain Signals
Oct 01, 2019
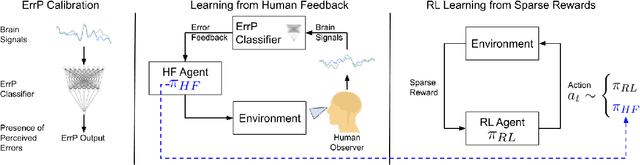
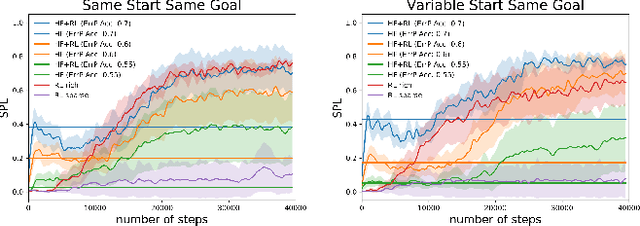

In reinforcement learning (RL), sparse rewards are a natural way to specify the task to be learned. However, most RL algorithms struggle to learn in this setting since the learning signal is mostly zeros. In contrast, humans are good at assessing and predicting the future consequences of actions and can serve as good reward/policy shapers to accelerate the robot learning process. Previous works have shown that the human brain generates an error-related signal, measurable using electroencephelography (EEG), when the human perceives the task being done erroneously. In this work, we propose a method that uses evaluative feedback obtained from human brain signals measured via scalp EEG to accelerate RL for robotic agents in sparse reward settings. As the robot learns the task, the EEG of a human observer watching the robot attempts is recorded and decoded into noisy error feedback signal. From this feedback, we use supervised learning to obtain a policy that subsequently augments the behavior policy and guides exploration in the early stages of RL. This bootstraps the RL learning process to enable learning from sparse reward. Using a robotic navigation task as a test bed, we show that our method achieves a stable obstacle-avoidance policy with high success rate, outperforming learning from sparse rewards only that struggles to achieve obstacle avoidance behavior or fails to advance to the goal.