 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Weakly-labeled Web Videos via Exploring Sub-Concepts
Jan 11, 2021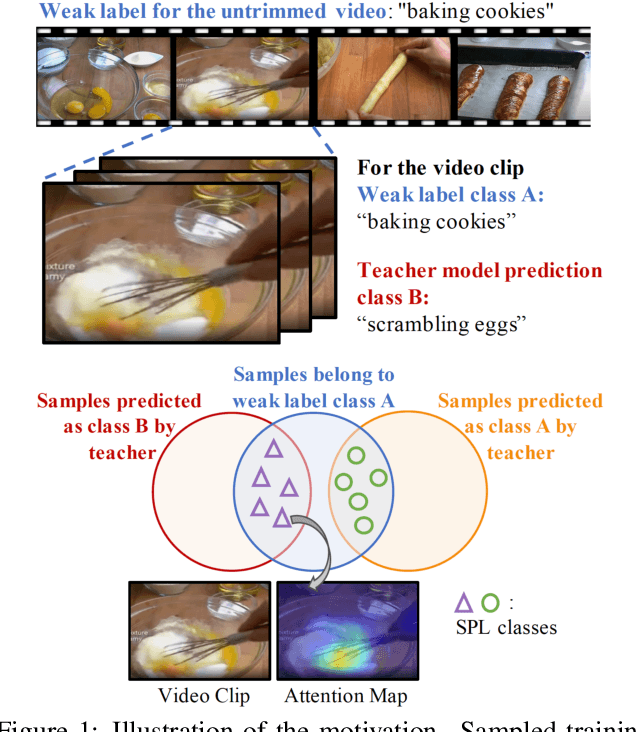
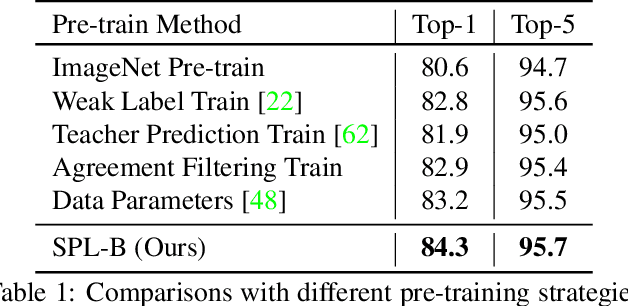
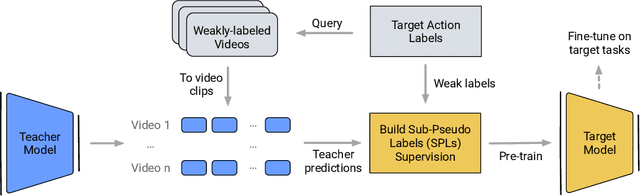
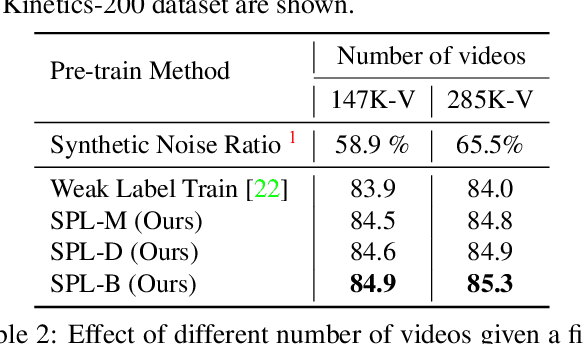
Learning visual knowledge from massive weakly-labeled web videos has attracted growing research interests thanks to the large corpus of easily accessible video data on the Internet. However, for video action recognition, the action of interest might only exist in arbitrary clips of untrimmed web videos, resulting in high label noises in the temporal space. To address this issue, we introduce a new method for pre-training video action recognition models using queried web videos. Instead of trying to filter out, we propose to convert the potential noises in these queried videos to useful supervision signals by defining the concept of Sub-Pseudo Label (SPL). Specifically, SPL spans out a new set of meaningful "middle ground" label space constructed by extrapolating the original weak labels during video querying and the prior knowledge distilled from a teacher model. Consequently, SPL provides enriched supervision for video models to learn better representations. SPL is fairly simple and orthogonal to popular teacher-student self-training frameworks without extra training cost. We validate the effectiveness of our method on four video action recognition datasets and a weakly-labeled image dataset to study the generalization ability. Experiments show that SPL outperforms several existing pre-training strategies using pseudo-labels and the learned representations lead to competitive results when fine-tuning on HMDB-51 and UCF-101 compared with recent pre-training methods.
Spatial-Temporal Alignment Network for Action Recognition and Detection
Dec 04, 2020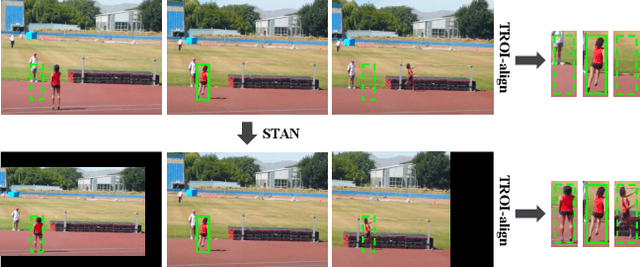
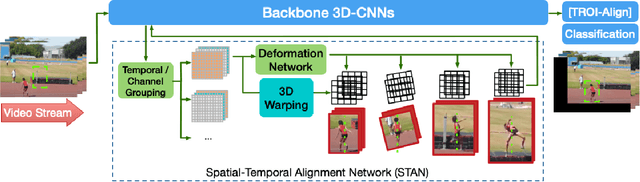
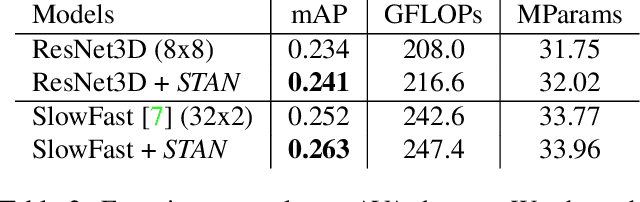
This paper studies how to introduce viewpoint-invariant feature representations that can help action recognition and detection. Although we have witnessed great progress of action recognition in the past decade, it remains challenging yet interesting how to efficiently model the geometric variations in large scale datasets. This paper proposes a novel Spatial-Temporal Alignment Network (STAN) that aims to learn geometric invariant representations for action recognition and action detection. The STAN model is very light-weighted and generic, which could be plugged into existing action recognition models like ResNet3D and the SlowFast with a very low extra computational cost. We test our STAN model extensively on AVA, Kinetics-400, AVA-Kinetics, Charades, and Charades-Ego datasets. The experimental results show that the STAN model can consistently improve the state of the arts in both action detection and action recognition tasks. We will release our data, models and code.
PERF-Net: Pose Empowered RGB-Flow Net
Sep 28, 2020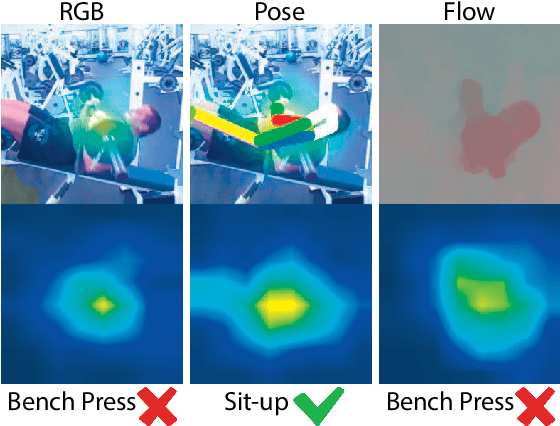
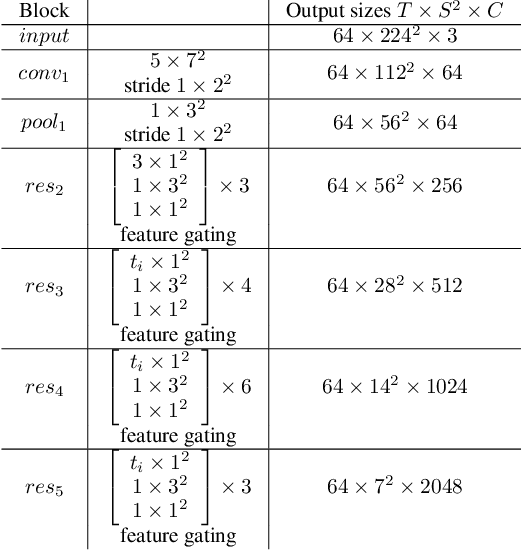

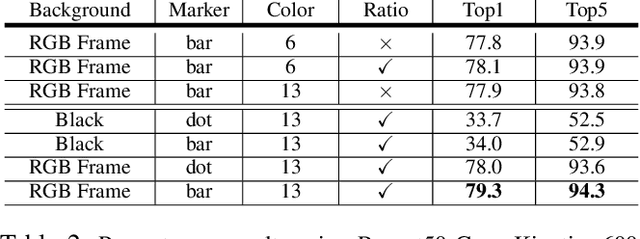
In recent years, many works in the video action recognition literature have shown that two stream models (combining spatial and temporal input streams) are necessary for achieving state of the art performance. In this paper we show the benefits of including yet another stream based on human pose estimated from each frame -- specifically by rendering pose on input RGB frames. At first blush, this additional stream may seem redundant given that human pose is fully determined by RGB pixel values -- however we show (perhaps surprisingly) that this simple and flexible addition can provide complementary gains. Using this insight, we then propose a new model, which we dub PERF-Net (short for Pose Empowered RGB-Flow Net), which combines this new pose stream with the standard RGB and flow based input streams via distillation techniques and show that our model outperforms the state-of-the-art by a large margin in a number of human action recognition datasets while not requiring flow or pose to be explicitly computed at inference time.
AttentionNAS: Spatiotemporal Attention Cell Search for Video Classification
Jul 31, 2020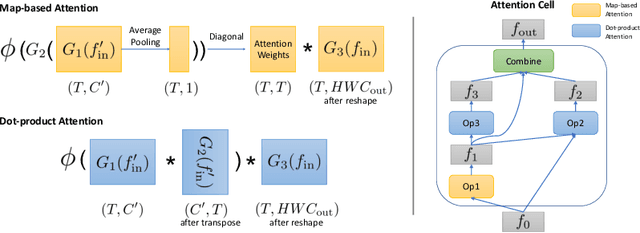
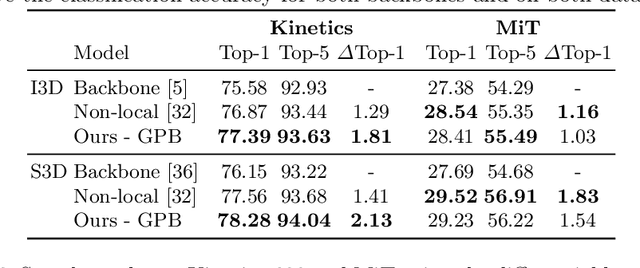
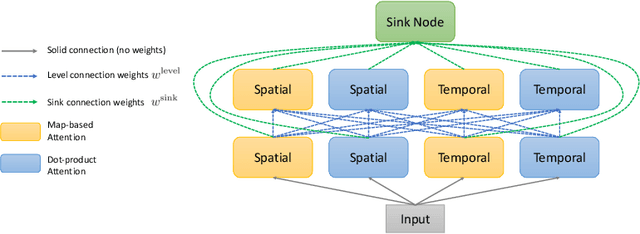
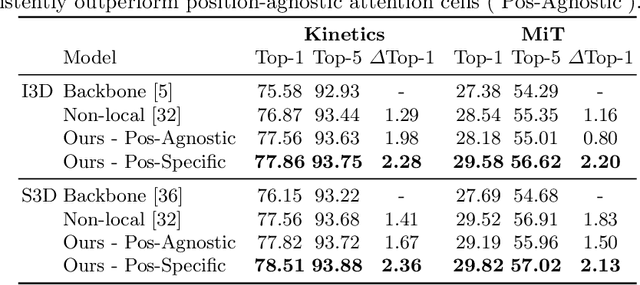
Convolutional operations have two limitations: (1) do not explicitly model where to focus as the same filter is applied to all the positions, and (2) are unsuitable for modeling long-range dependencies as they only operate on a small neighborhood. While both limitations can be alleviated by attention operations, many design choices remain to be determined to use attention, especially when applying attention to videos. Towards a principled way of applying attention to videos, we address the task of spatiotemporal attention cell search. We propose a novel search space for spatiotemporal attention cells, which allows the search algorithm to flexibly explore various design choices in the cell. The discovered attention cells can be seamlessly inserted into existing backbone networks, e.g., I3D or S3D, and improve video classification accuracy by more than 2% on both Kinetics-600 and MiT datasets. The discovered attention cells outperform non-local blocks on both datasets, and demonstrate strong generalization across different modalities, backbones, and datasets. Inserting our attention cells into I3D-R50 yields state-of-the-art performance on both datasets.
An Aggressive Genetic Programming Approach for Searching Neural Network Structure Under Computational Constraints
Jun 03, 2018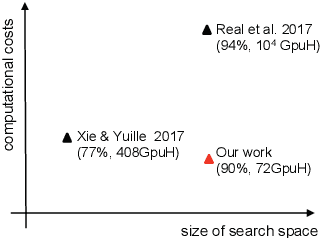
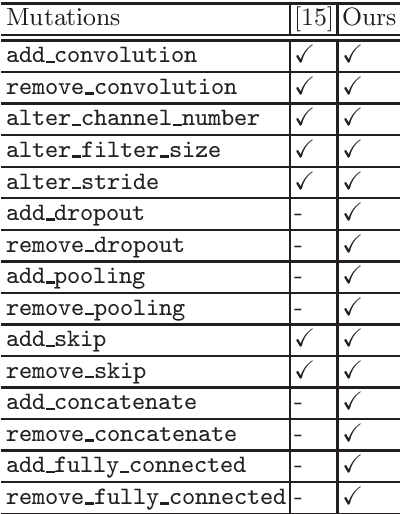
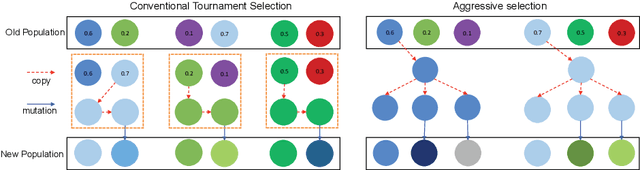
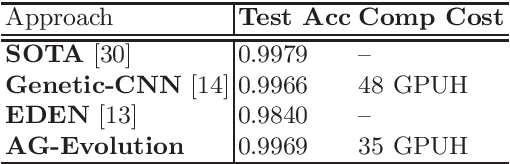
Recently, there emerged revived interests of designing automatic programs (e.g., using genetic/evolutionary algorithms) to optimize the structure of Convolutional Neural Networks (CNNs) for a specific task. The challenge in designing such programs lies in how to balance between large search space of the network structures and high computational costs. Existing works either impose strong restrictions on the search space or use enormous computing resources. In this paper, we study how to design a genetic programming approach for optimizing the structure of a CNN for a given task under limited computational resources yet without imposing strong restrictions on the search space. To reduce the computational costs, we propose two general strategies that are observed to be helpful: (i) aggressively selecting strongest individuals for survival and reproduction, and killing weaker individuals at a very early age; (ii) increasing mutation frequency to encourage diversity and faster evolution. The combined strategy with additional optimization techniques allows us to explore a large search space but with affordable computational costs. Our results on standard benchmark datasets (MNIST, SVHN, CIFAR-10, CIFAR-100) are competitive to similar approaches with significantly reduced computational costs.
Efficient Video Object Segmentation via Network Modulation
Feb 04, 2018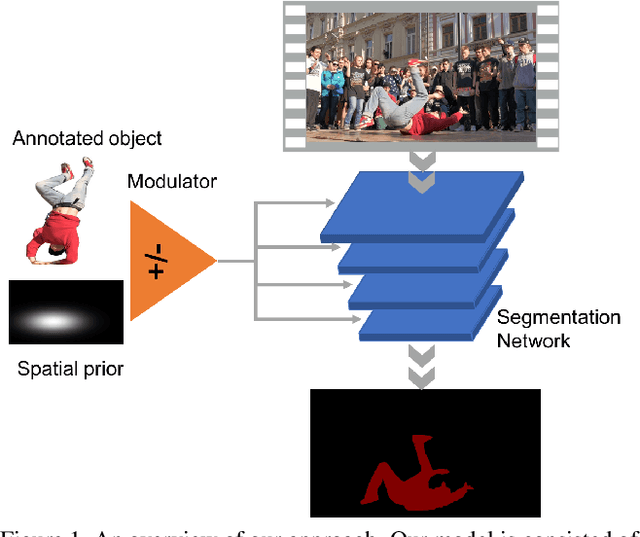
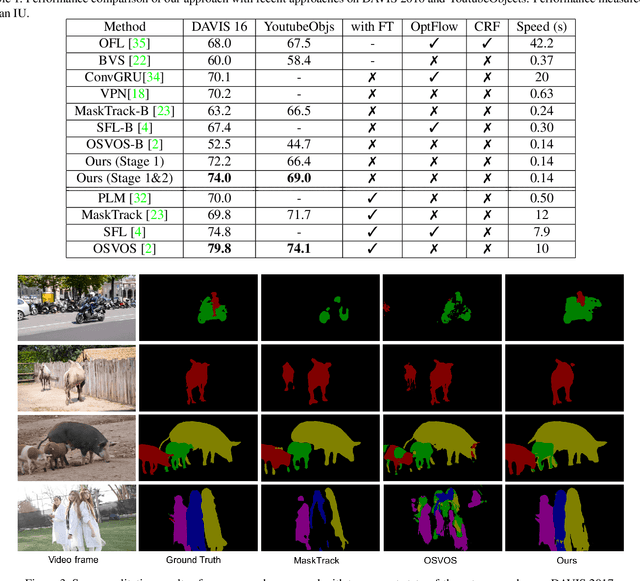
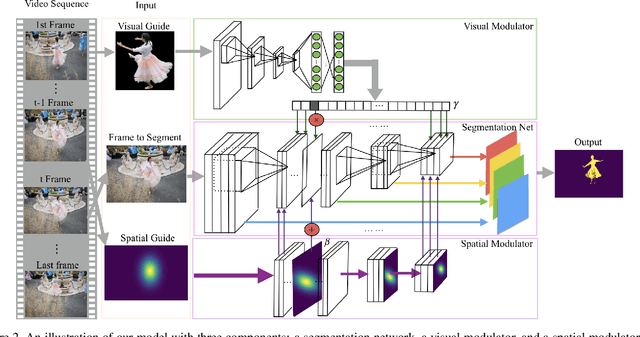
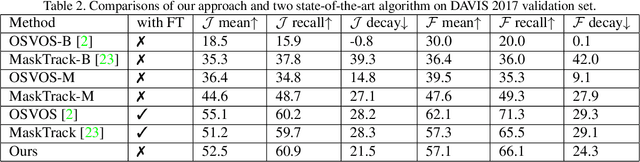
Video object segmentation targets at segmenting a specific object throughout a video sequence, given only an annotated first frame. Recent deep learning based approaches find it effective by fine-tuning a general-purpose segmentation model on the annotated frame using hundreds of iterations of gradient descent. Despite the high accuracy these methods achieve, the fine-tuning process is inefficient and fail to meet the requirements of real world applications. We propose a novel approach that uses a single forward pass to adapt the segmentation model to the appearance of a specific object. Specifically, a second meta neural network named modulator is learned to manipulate the intermediate layers of the segmentation network given limited visual and spatial information of the target object. The experiments show that our approach is 70times faster than fine-tuning approaches while achieving similar accuracy.
Supervised Descent Method for Solving Nonlinear Least Squares Problems in Computer Vision
May 03, 2014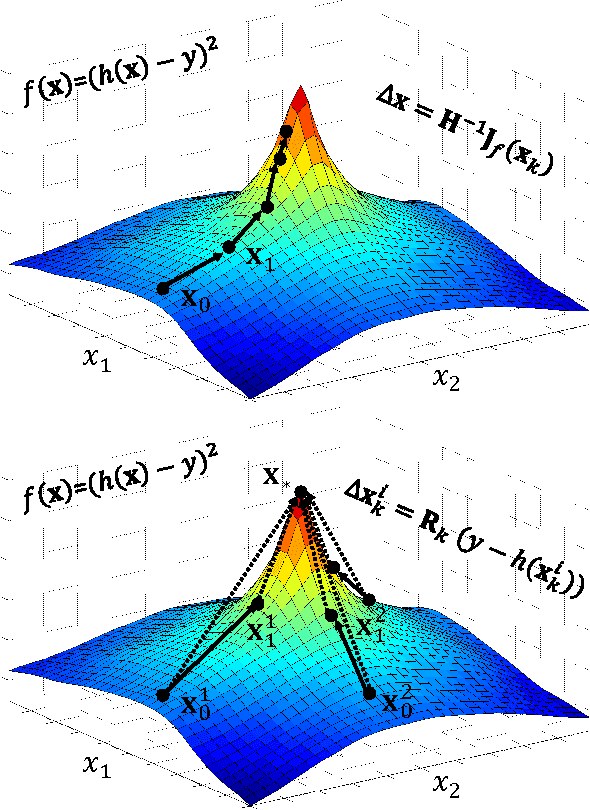
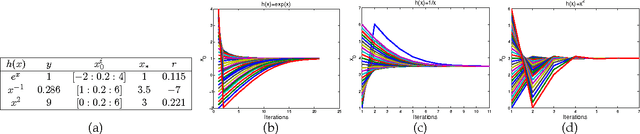
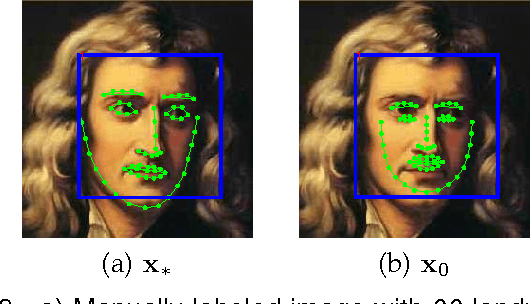

Many computer vision problems (e.g., camera calibration, image alignment, structure from motion) are solved with nonlinear optimization methods. It is generally accepted that second order descent methods are the most robust, fast, and reliable approaches for nonlinear optimization of a general smooth function. However, in the context of computer vision, second order descent methods have two main drawbacks: (1) the function might not be analytically differentiable and numerical approximations are impractical, and (2) the Hessian may be large and not positive definite. To address these issues, this paper proposes generic descent maps, which are average "descent directions" and rescaling factors learned in a supervised fashion. Using generic descent maps, we derive a practical algorithm - Supervised Descent Method (SDM) - for minimizing Nonlinear Least Squares (NLS) problems. During training, SDM learns a sequence of decent maps that minimize the NLS. In testing, SDM minimizes the NLS objective using the learned descent maps without computing the Jacobian or the Hessian. We prove the conditions under which the SDM is guaranteed to converge. We illustrate the effectiveness and accuracy of SDM in three computer vision problems: rigid image alignment, non-rigid image alignment, and 3D pose estimation. In particular, we show how SDM achieves state-of-the-art performance in the problem of facial feature detection. The code has been made available at www.humansensing.cs.cmu.edu/intraface.
Bayesian Optimal Active Search and Surveying
Jun 27, 2012
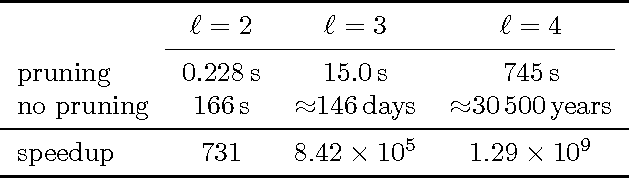
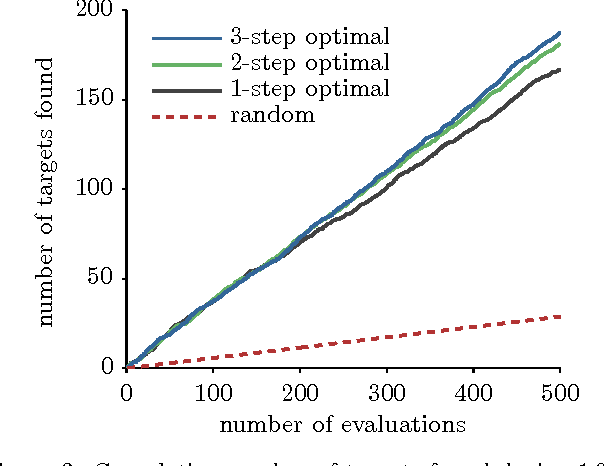
We consider two active binary-classification problems with atypical objectives. In the first, active search, our goal is to actively uncover as many members of a given class as possible. In the second, active surveying, our goal is to actively query points to ultimately predict the proportion of a given class. Numerous real-world problems can be framed in these terms, and in either case typical model-based concerns such as generalization error are only of secondary importance. We approach these problems via Bayesian decision theory; after choosing natural utility functions, we derive the optimal policies. We provide three contributions. In addition to introducing the active surveying problem, we extend previous work on active search in two ways. First, we prove a novel theoretical result, that less-myopic approximations to the optimal policy can outperform more-myopic approximations by any arbitrary degree. We then derive bounds that for certain models allow us to reduce (in practice dramatically) the exponential search space required by a naive implementation of the optimal policy, enabling further lookahead while still ensuring that optimal decisions are always made.