 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Generative and Dense Retrieval for Sequential Recommendation
Nov 27, 2024



Sequential dense retrieval models utilize advanced sequence learning techniques to compute item and user representations, which are then used to rank relevant items for a user through inner product computation between the user and all item representations. However, this approach requires storing a unique representation for each item, resulting in significant memory requirements as the number of items grow. In contrast, the recently proposed generative retrieval paradigm offers a promising alternative by directly predicting item indices using a generative model trained on semantic IDs that encapsulate items' semantic information. Despite its potential for large-scale applications, a comprehensive comparison between generative retrieval and sequential dense retrieval under fair conditions is still lacking, leaving open questions regarding performance, and computation trade-offs. To address this, we compare these two approaches under controlled conditions on academic benchmarks and propose LIGER (LeveragIng dense retrieval for GEnerative Retrieval), a hybrid model that combines the strengths of these two widely used methods. LIGER integrates sequential dense retrieval into generative retrieval, mitigating performance differences and enhancing cold-start item recommendation in the datasets evaluated. This hybrid approach provides insights into the trade-offs between these approaches and demonstrates improvements in efficiency and effectiveness for recommendation systems in small-scale benchmarks.
AdaSociety: An Adaptive Environment with Social Structures for Multi-Agent Decision-Making
Nov 06, 2024Traditional interactive environments limit agents' intelligence growth with fixed tasks. Recently, single-agent environments address this by generating new tasks based on agent actions, enhancing task diversity. We consider the decision-making problem in multi-agent settings, where tasks are further influenced by social connections, affecting rewards and information access. However, existing multi-agent environments lack a combination of adaptive physical surroundings and social connections, hindering the learning of intelligent behaviors. To address this, we introduce AdaSociety, a customizable multi-agent environment featuring expanding state and action spaces, alongside explicit and alterable social structures. As agents progress, the environment adaptively generates new tasks with social structures for agents to undertake. In AdaSociety, we develop three mini-games showcasing distinct social structures and tasks. Initial results demonstrate that specific social structures can promote both individual and collective benefits, though current reinforcement learning and LLM-based algorithms show limited effectiveness in leveraging social structures to enhance performance. Overall, AdaSociety serves as a valuable research platform for exploring intelligence in diverse physical and social settings. The code is available at https://github.com/bigai-ai/AdaSociety.
Learning to Balance Altruism and Self-interest Based on Empathy in Mixed-Motive Games
Oct 10, 2024



Real-world multi-agent scenarios often involve mixed motives, demanding altruistic agents capable of self-protection against potential exploitation. However, existing approaches often struggle to achieve both objectives. In this paper, based on that empathic responses are modulated by inferred social relationships between agents, we propose LASE Learning to balance Altruism and Self-interest based on Empathy), a distributed multi-agent reinforcement learning algorithm that fosters altruistic cooperation through gifting while avoiding exploitation by other agents in mixed-motive games. LASE allocates a portion of its rewards to co-players as gifts, with this allocation adapting dynamically based on the social relationship -- a metric evaluating the friendliness of co-players estimated by counterfactual reasoning. In particular, social relationship measures each co-player by comparing the estimated $Q$-function of current joint action to a counterfactual baseline which marginalizes the co-player's action, with its action distribution inferred by a perspective-taking module. Comprehensive experiments are performed in spatially and temporally extended mixed-motive games, demonstrating LASE's ability to promote group collaboration without compromising fairness and its capacity to adapt policies to various types of interactive co-players.
Efficient Adaptation in Mixed-Motive Environments via Hierarchical Opponent Modeling and Planning
Jun 12, 2024



Despite the recent successes of multi-agent reinforcement learning (MARL) algorithms, efficiently adapting to co-players in mixed-motive environments remains a significant challenge. One feasible approach is to hierarchically model co-players' behavior based on inferring their characteristics. However, these methods often encounter difficulties in efficient reasoning and utilization of inferred information. To address these issues, we propose Hierarchical Opponent modeling and Planning (HOP), a novel multi-agent decision-making algorithm that enables few-shot adaptation to unseen policies in mixed-motive environments. HOP is hierarchically composed of two modules: an opponent modeling module that infers others' goals and learns corresponding goal-conditioned policies, and a planning module that employs Monte Carlo Tree Search (MCTS) to identify the best response. Our approach improves efficiency by updating beliefs about others' goals both across and within episodes and by using information from the opponent modeling module to guide planning. Experimental results demonstrate that in mixed-motive environments, HOP exhibits superior few-shot adaptation capabilities when interacting with various unseen agents, and excels in self-play scenarios. Furthermore, the emergence of social intelligence during our experiments underscores the potential of our approach in complex multi-agent environments.
Map Optical Properties to Subwavelength Structures Directly via a Diffusion Model
Apr 09, 2024



Subwavelength photonic structures and metamaterials provide revolutionary approaches for controlling light. The inverse design methods proposed for these subwavelength structures are vital to the development of new photonic devices. However, most of the existing inverse design methods cannot realize direct mapping from optical properties to photonic structures but instead rely on forward simulation methods to perform iterative optimization. In this work, we exploit the powerful generative abilities of artificial intelligence (AI) and propose a practical inverse design method based on latent diffusion models. Our method maps directly the optical properties to structures without the requirement of forward simulation and iterative optimization. Here, the given optical properties can work as "prompts" and guide the constructed model to correctly "draw" the required photonic structures. Experiments show that our direct mapping-based inverse design method can generate subwavelength photonic structures at high fidelity while following the given optical properties. This may change the method used for optical design and greatly accelerate the research on new photonic devices.
EXACT-Net:EHR-guided lung tumor auto-segmentation for non-small cell lung cancer radiotherapy
Feb 21, 2024



Lung cancer is a devastating disease with the highest mortality rate among cancer types. Over 60% of non-small cell lung cancer (NSCLC) patients, which accounts for 87% of diagnoses, require radiation therapy. Rapid treatment initiation significantly increases the patient's survival rate and reduces the mortality rate. Accurate tumor segmentation is a critical step in the diagnosis and treatment of NSCLC. Manual segmentation is time and labor-consuming and causes delays in treatment initiation. Although many lung nodule detection methods, including deep learning-based models, have been proposed, there is still a long-standing problem of high false positives (FPs) with most of these methods. Here, we developed an electronic health record (EHR) guided lung tumor auto-segmentation called EXACT-Net (EHR-enhanced eXACtitude in Tumor segmentation), where the extracted information from EHRs using a pre-trained large language model (LLM), was used to remove the FPs and keep the TP nodules only. The auto-segmentation model was trained on NSCLC patients' computed tomography (CT), and the pre-trained LLM was used with the zero-shot learning approach. Our approach resulted in a 250% boost in successful nodule detection using the data from ten NSCLC patients treated in our institution.
Active Learning in Brain Tumor Segmentation with Uncertainty Sampling, Annotation Redundancy Restriction, and Data Initialization
Feb 05, 2023



Deep learning models have demonstrated great potential in medical 3D imaging, but their development is limited by the expensive, large volume of annotated data required. Active learning (AL) addresses this by training a model on a subset of the most informative data samples without compromising performance. We compared different AL strategies and propose a framework that minimizes the amount of data needed for state-of-the-art performance. 638 multi-institutional brain tumor MRI images were used to train a 3D U-net model and compare AL strategies. We investigated uncertainty sampling, annotation redundancy restriction, and initial dataset selection techniques. Uncertainty estimation techniques including Bayesian estimation with dropout, bootstrapping, and margins sampling were compared to random query. Strategies to avoid annotation redundancy by removing similar images within the to-be-annotated subset were considered as well. We determined the minimum amount of data necessary to achieve similar performance to the model trained on the full dataset ({\alpha} = 0.1). A variance-based selection strategy using radiomics to identify the initial training dataset is also proposed. Bayesian approximation with dropout at training and testing showed similar results to that of the full data model with less than 20% of the training data (p=0.293) compared to random query achieving similar performance at 56.5% of the training data (p=0.814). Annotation redundancy restriction techniques achieved state-of-the-art performance at approximately 40%-50% of the training data. Radiomics dataset initialization had higher Dice with initial dataset sizes of 20 and 80 images, but improvements were not significant. In conclusion, we investigated various AL strategies with dropout uncertainty estimation achieving state-of-the-art performance with the least annotated data.
Deep-learning-based on-chip rapid spectral imaging with high spatial resolution
Jan 16, 2023Spectral imaging extends the concept of traditional color cameras to capture images across multiple spectral channels and has broad application prospects. Conventional spectral cameras based on scanning methods suffer from low acquisition speed and large volume. On-chip computational spectral imaging based on metasurface filters provides a promising scheme for portable applications, but endures long computation time for point-by-point iterative spectral reconstruction and mosaic effect in the reconstructed spectral images. In this study, we demonstrated on-chip rapid spectral imaging eliminating the mosaic effect in the spectral image by deep-learning-based spectral data cube reconstruction. We experimentally achieved four orders of magnitude speed improvement than iterative spectral reconstruction and high fidelity of spectral reconstruction over 99% for a standard color board. In particular, we demonstrated video-rate spectral imaging for moving objects and outdoor driving scenes with good performance for recognizing metamerism, where the concolorous sky and white cars can be distinguished via their spectra, showing great potential for autonomous driving and other practical applications in the field of intelligent perception.
MetaBalance: Improving Multi-Task Recommendations via Adapting Gradient Magnitudes of Auxiliary Tasks
Mar 14, 2022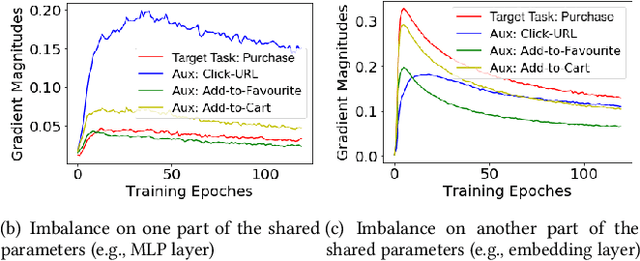

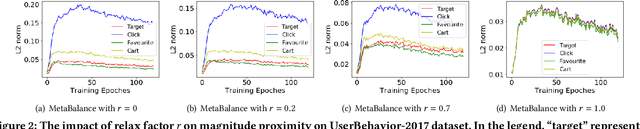
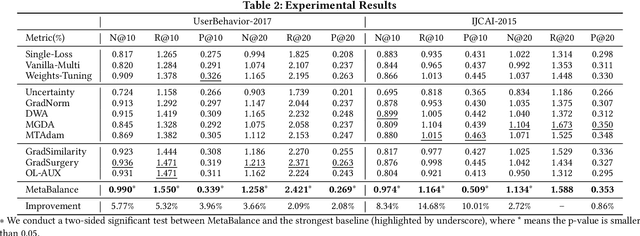
In many personalized recommendation scenarios, the generalization ability of a target task can be improved via learning with additional auxiliary tasks alongside this target task on a multi-task network. However, this method often suffers from a serious optimization imbalance problem. On the one hand, one or more auxiliary tasks might have a larger influence than the target task and even dominate the network weights, resulting in worse recommendation accuracy for the target task. On the other hand, the influence of one or more auxiliary tasks might be too weak to assist the target task. More challenging is that this imbalance dynamically changes throughout the training process and varies across the parts of the same network. We propose a new method: MetaBalance to balance auxiliary losses via directly manipulating their gradients w.r.t the shared parameters in the multi-task network. Specifically, in each training iteration and adaptively for each part of the network, the gradient of an auxiliary loss is carefully reduced or enlarged to have a closer magnitude to the gradient of the target loss, preventing auxiliary tasks from being so strong that dominate the target task or too weak to help the target task. Moreover, the proximity between the gradient magnitudes can be flexibly adjusted to adapt MetaBalance to different scenarios. The experiments show that our proposed method achieves a significant improvement of 8.34% in terms of NDCG@10 upon the strongest baseline on two real-world datasets. The code of our approach can be found at here: https://github.com/facebookresearch/MetaBalance
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021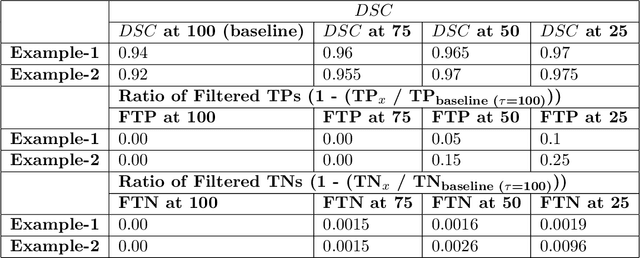
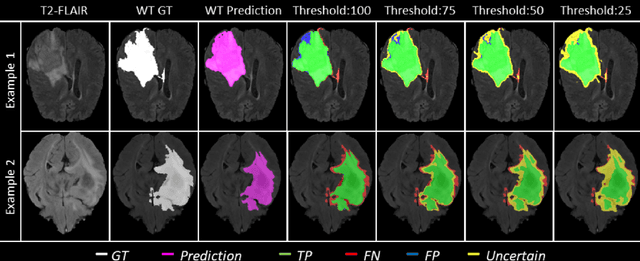
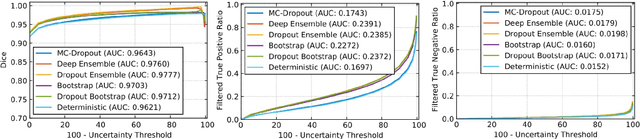
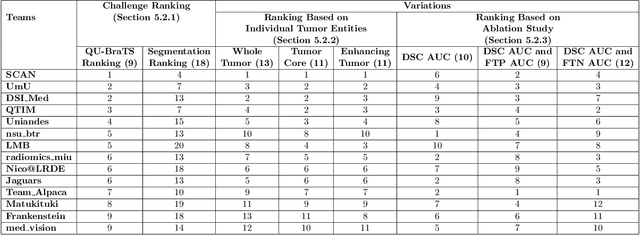
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.