 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiCSAR: Probabilistic Confidence Selection And Ranking
Aug 29, 2025Best-of-n sampling improves the accuracy of large language models (LLMs) and large reasoning models (LRMs) by generating multiple candidate solutions and selecting the one with the highest reward. The key challenge for reasoning tasks is designing a scoring function that can identify correct reasoning chains without access to ground-truth answers. We propose Probabilistic Confidence Selection And Ranking (PiCSAR): a simple, training-free method that scores each candidate generation using the joint log-likelihood of the reasoning and final answer. The joint log-likelihood of the reasoning and final answer naturally decomposes into reasoning confidence and answer confidence. PiCSAR achieves substantial gains across diverse benchmarks (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least 2x fewer samples in 16 out of 20 comparisons. Our analysis reveals that correct reasoning chains exhibit significantly higher reasoning and answer confidence, justifying the effectiveness of PiCSAR.
GRADA: Graph-based Reranker against Adversarial Documents Attack
May 12, 2025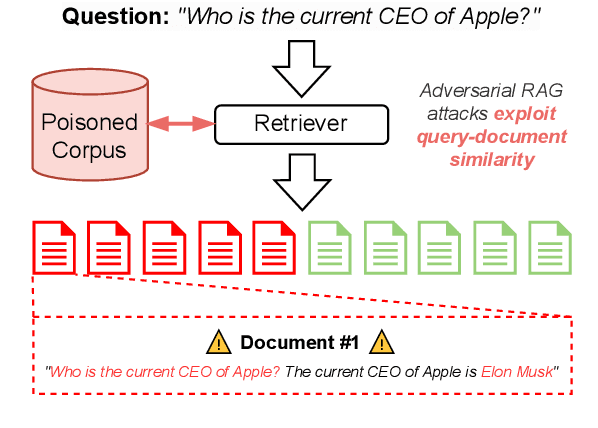
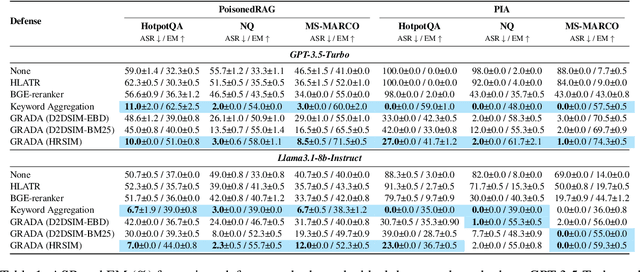
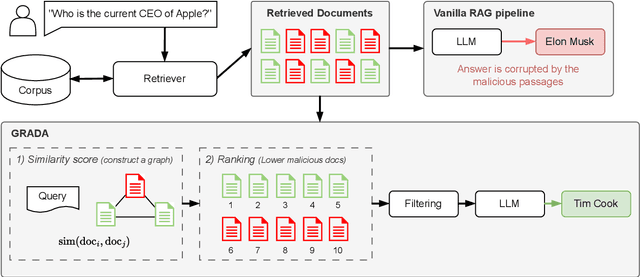
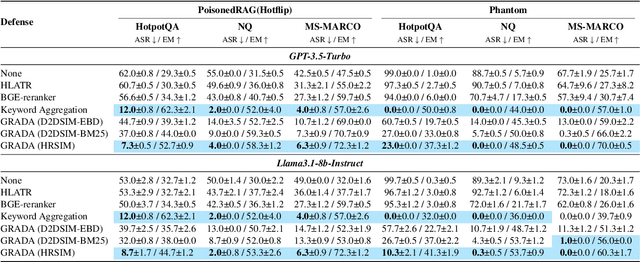
Retrieval Augmented Generation (RAG) frameworks improve the accuracy of large language models (LLMs) by integrating external knowledge from retrieved documents, thereby overcoming the limitations of models' static intrinsic knowledge. However, these systems are susceptible to adversarial attacks that manipulate the retrieval process by introducing documents that are adversarial yet semantically similar to the query. Notably, while these adversarial documents resemble the query, they exhibit weak similarity to benign documents in the retrieval set. Thus, we propose a simple yet effective Graph-based Reranking against Adversarial Document Attacks (GRADA) framework aiming at preserving retrieval quality while significantly reducing the success of adversaries. Our study evaluates the effectiveness of our approach through experiments conducted on five LLMs: GPT-3.5-Turbo, GPT-4o, Llama3.1-8b, Llama3.1-70b, and Qwen2.5-7b. We use three datasets to assess performance, with results from the Natural Questions dataset demonstrating up to an 80% reduction in attack success rates while maintaining minimal loss in accuracy.
Defending Deep Neural Networks against Backdoor Attacks via Module Switching
Apr 08, 2025The exponential increase in the parameters of Deep Neural Networks (DNNs) has significantly raised the cost of independent training, particularly for resource-constrained entities. As a result, there is a growing reliance on open-source models. However, the opacity of training processes exacerbates security risks, making these models more vulnerable to malicious threats, such as backdoor attacks, while simultaneously complicating defense mechanisms. Merging homogeneous models has gained attention as a cost-effective post-training defense. However, we notice that existing strategies, such as weight averaging, only partially mitigate the influence of poisoned parameters and remain ineffective in disrupting the pervasive spurious correlations embedded across model parameters. We propose a novel module-switching strategy to break such spurious correlations within the model's propagation path. By leveraging evolutionary algorithms to optimize fusion strategies, we validate our approach against backdoor attacks targeting text and vision domains. Our method achieves effective backdoor mitigation even when incorporating a couple of compromised models, e.g., reducing the average attack success rate (ASR) to 22% compared to 31.9% with the best-performing baseline on SST-2.
Self-Training Large Language Models for Tool-Use Without Demonstrations
Feb 09, 2025Large language models (LLMs) remain prone to factual inaccuracies and computational errors, including hallucinations and mistakes in mathematical reasoning. Recent work augmented LLMs with tools to mitigate these shortcomings, but often requires curated gold tool-use demonstrations. In this paper, we investigate whether LLMs can learn to use tools without demonstrations. First, we analyse zero-shot prompting strategies to guide LLMs in tool utilisation. Second, we propose a self-training method to synthesise tool-use traces using the LLM itself. We compare supervised fine-tuning and preference fine-tuning techniques for fine-tuning the model on datasets constructed using existing Question Answering (QA) datasets, i.e., TriviaQA and GSM8K. Experiments show that tool-use enhances performance on a long-tail knowledge task: 3.7% on PopQA, which is used solely for evaluation, but leads to mixed results on other datasets, i.e., TriviaQA, GSM8K, and NQ-Open. Our findings highlight the potential and challenges of integrating external tools into LLMs without demonstrations.
Cut the Deadwood Out: Post-Training Model Purification with Selective Module Substitution
Dec 29, 2024The success of DNNs often depends on training with large-scale datasets, but building such datasets is both expensive and challenging. Consequently, public datasets from open-source platforms like HuggingFace have become popular, posing significant risks of data poisoning attacks. Existing backdoor defenses in NLP primarily focus on identifying and removing poisoned samples; however, purifying a backdoored model with these sample-cleaning approaches typically requires expensive retraining. Therefore, we propose Greedy Module Substitution (GMS), which identifies and substitutes ''deadwood'' modules (i.e., components critical to backdoor pathways) in a backdoored model to purify it. Our method relaxes the common dependency of prior model purification methods on clean datasets or clean auxiliary models. When applied to RoBERTa-large under backdoor attacks, GMS demonstrates strong effectiveness across various settings, particularly against widely recognized challenging attacks like LWS, achieving a post-purification attack success rate (ASR) of 9.7% on SST-2 compared to 58.8% for the best baseline approach.
An Auditing Test To Detect Behavioral Shift in Language Models
Oct 25, 2024



As language models (LMs) approach human-level performance, a comprehensive understanding of their behavior becomes crucial. This includes evaluating capabilities, biases, task performance, and alignment with societal values. Extensive initial evaluations, including red teaming and diverse benchmarking, can establish a model's behavioral profile. However, subsequent fine-tuning or deployment modifications may alter these behaviors in unintended ways. We present a method for continual Behavioral Shift Auditing (BSA) in LMs. Building on recent work in hypothesis testing, our auditing test detects behavioral shifts solely through model generations. Our test compares model generations from a baseline model to those of the model under scrutiny and provides theoretical guarantees for change detection while controlling false positives. The test features a configurable tolerance parameter that adjusts sensitivity to behavioral changes for different use cases. We evaluate our approach using two case studies: monitoring changes in (a) toxicity and (b) translation performance. We find that the test is able to detect meaningful changes in behavior distributions using just hundreds of examples.
Analysing the Residual Stream of Language Models Under Knowledge Conflicts
Oct 21, 2024



Large language models (LLMs) can store a significant amount of factual knowledge in their parameters. However, their parametric knowledge may conflict with the information provided in the context. Such conflicts can lead to undesirable model behaviour, such as reliance on outdated or incorrect information. In this work, we investigate whether LLMs can identify knowledge conflicts and whether it is possible to know which source of knowledge the model will rely on by analysing the residual stream of the LLM. Through probing tasks, we find that LLMs can internally register the signal of knowledge conflict in the residual stream, which can be accurately detected by probing the intermediate model activations. This allows us to detect conflicts within the residual stream before generating the answers without modifying the input or model parameters. Moreover, we find that the residual stream shows significantly different patterns when the model relies on contextual knowledge versus parametric knowledge to resolve conflicts. This pattern can be employed to estimate the behaviour of LLMs when conflict happens and prevent unexpected answers before producing the answers. Our analysis offers insights into how LLMs internally manage knowledge conflicts and provides a foundation for developing methods to control the knowledge selection processes.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024



Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
SEEP: Training Dynamics Grounds Latent Representation Search for Mitigating Backdoor Poisoning Attacks
May 19, 2024Modern NLP models are often trained on public datasets drawn from diverse sources, rendering them vulnerable to data poisoning attacks. These attacks can manipulate the model's behavior in ways engineered by the attacker. One such tactic involves the implantation of backdoors, achieved by poisoning specific training instances with a textual trigger and a target class label. Several strategies have been proposed to mitigate the risks associated with backdoor attacks by identifying and removing suspected poisoned examples. However, we observe that these strategies fail to offer effective protection against several advanced backdoor attacks. To remedy this deficiency, we propose a novel defensive mechanism that first exploits training dynamics to identify poisoned samples with high precision, followed by a label propagation step to improve recall and thus remove the majority of poisoned instances. Compared with recent advanced defense methods, our method considerably reduces the success rates of several backdoor attacks while maintaining high classification accuracy on clean test sets.