 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak Foundry: From Papers to Runnable Attacks for Reproducible Benchmarking
Mar 05, 2026Jailbreak techniques for large language models (LLMs) evolve faster than benchmarks, making robustness estimates stale and difficult to compare across papers due to drift in datasets, harnesses, and judging protocols. We introduce JAILBREAK FOUNDRY (JBF), a system that addresses this gap via a multi-agent workflow to translate jailbreak papers into executable modules for immediate evaluation within a unified harness. JBF features three core components: (i) JBF-LIB for shared contracts and reusable utilities; (ii) JBF-FORGE for the multi-agent paper-to-module translation; and (iii) JBF-EVAL for standardizing evaluations. Across 30 reproduced attacks, JBF achieves high fidelity with a mean (reproduced-reported) attack success rate (ASR) deviation of +0.26 percentage points. By leveraging shared infrastructure, JBF reduces attack-specific implementation code by nearly half relative to original repositories and achieves an 82.5% mean reused-code ratio. This system enables a standardized AdvBench evaluation of all 30 attacks across 10 victim models using a consistent GPT-4o judge. By automating both attack integration and standardized evaluation, JBF offers a scalable solution for creating living benchmarks that keep pace with the rapidly shifting security landscape.
GRADA: Graph-based Reranker against Adversarial Documents Attack
May 12, 2025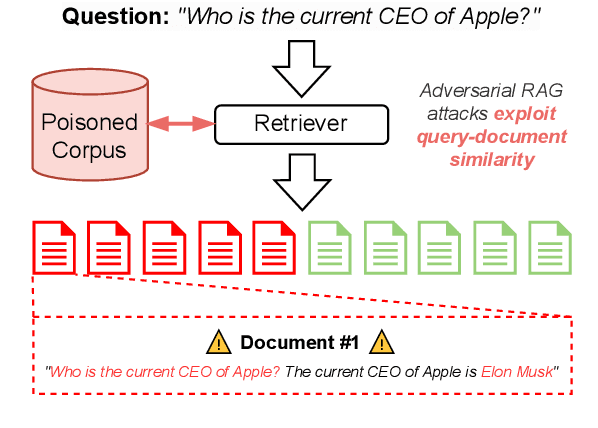
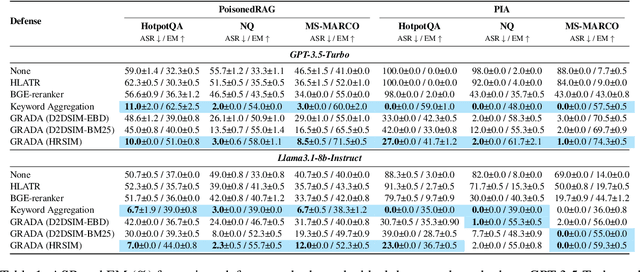
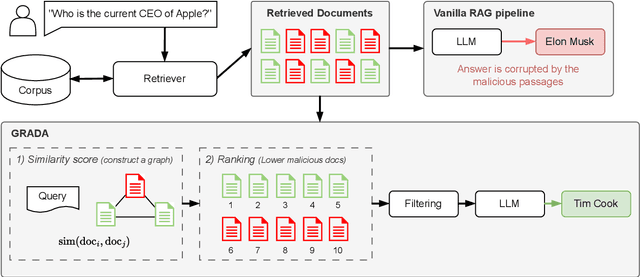
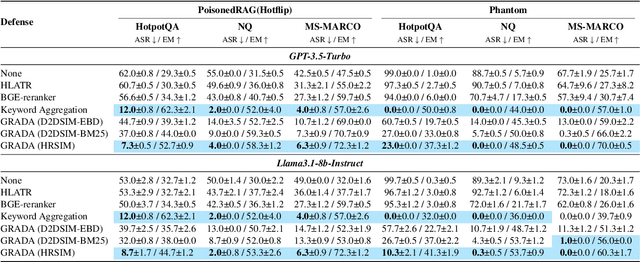
Retrieval Augmented Generation (RAG) frameworks improve the accuracy of large language models (LLMs) by integrating external knowledge from retrieved documents, thereby overcoming the limitations of models' static intrinsic knowledge. However, these systems are susceptible to adversarial attacks that manipulate the retrieval process by introducing documents that are adversarial yet semantically similar to the query. Notably, while these adversarial documents resemble the query, they exhibit weak similarity to benign documents in the retrieval set. Thus, we propose a simple yet effective Graph-based Reranking against Adversarial Document Attacks (GRADA) framework aiming at preserving retrieval quality while significantly reducing the success of adversaries. Our study evaluates the effectiveness of our approach through experiments conducted on five LLMs: GPT-3.5-Turbo, GPT-4o, Llama3.1-8b, Llama3.1-70b, and Qwen2.5-7b. We use three datasets to assess performance, with results from the Natural Questions dataset demonstrating up to an 80% reduction in attack success rates while maintaining minimal loss in accuracy.
MUG: Interactive Multimodal Grounding on User Interfaces
Sep 29, 2022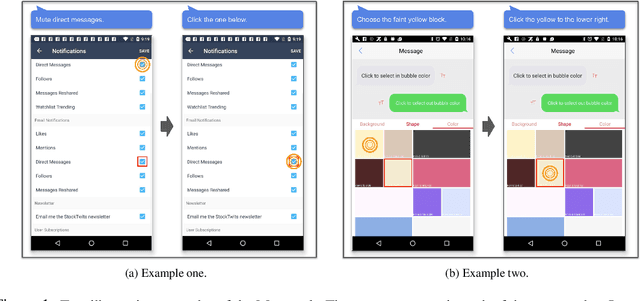
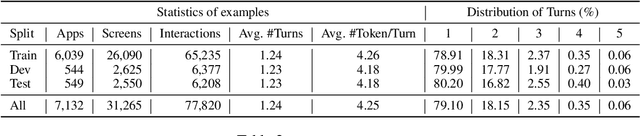
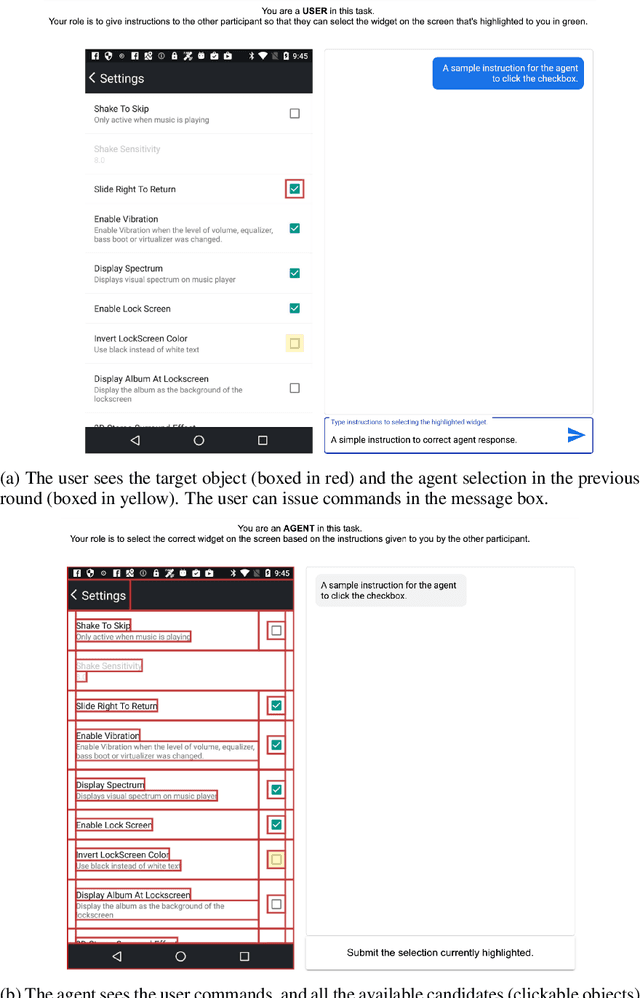
We present MUG, a novel interactive task for multimodal grounding where a user and an agent work collaboratively on an interface screen. Prior works modeled multimodal UI grounding in one round: the user gives a command and the agent responds to the command. Yet, in a realistic scenario, a user command can be ambiguous when the target action is inherently difficult to articulate in natural language. MUG allows multiple rounds of interactions such that upon seeing the agent responses, the user can give further commands for the agent to refine or even correct its actions. Such interaction is critical for improving grounding performances in real-world use cases. To investigate the problem, we create a new dataset that consists of 77,820 sequences of human user-agent interaction on mobile interfaces in which 20% involves multiple rounds of interactions. To establish our benchmark, we experiment with a range of modeling variants and evaluation strategies, including both offline and online evaluation-the online strategy consists of both human evaluation and automatic with simulators. Our experiments show that allowing iterative interaction significantly improves the absolute task completion by 18% over the entire test dataset and 31% over the challenging subset. Our results lay the foundation for further investigation of the problem.
Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements
Oct 08, 2020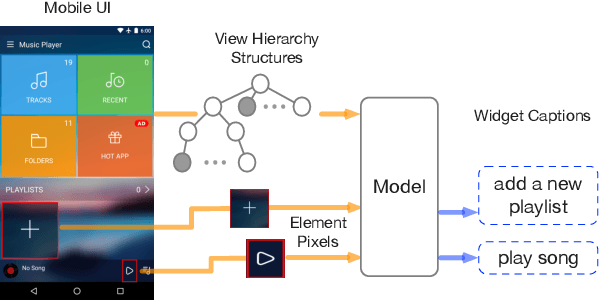

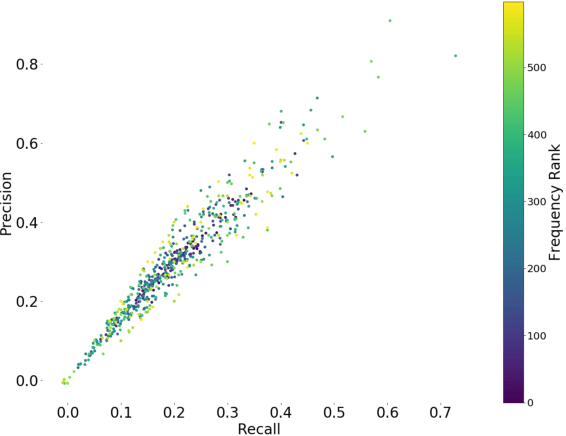

Natural language descriptions of user interface (UI) elements such as alternative text are crucial for accessibility and language-based interaction in general. Yet, these descriptions are constantly missing in mobile UIs. We propose widget captioning, a novel task for automatically generating language descriptions for UI elements from multimodal input including both the image and the structural representations of user interfaces. We collected a large-scale dataset for widget captioning with crowdsourcing. Our dataset contains 162,859 language phrases created by human workers for annotating 61,285 UI elements across 21,750 unique UI screens. We thoroughly analyze the dataset, and train and evaluate a set of deep model configurations to investigate how each feature modality as well as the choice of learning strategies impact the quality of predicted captions. The task formulation and the dataset as well as our benchmark models contribute a solid basis for this novel multimodal captioning task that connects language and user interfaces.