 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribution
Oct 01, 2025



Memory consumption of the Key-Value (KV) cache represents a major bottleneck for efficient large language model inference. While attention-score-based KV cache pruning shows promise, it faces critical practical limitations: attention scores from future tokens are unavailable during compression, and modern implementations like Flash Attention do not materialize the full attention matrix, making past scores inaccessible. To overcome these challenges, we introduce $\textbf{Expected Attention, a training-free compression method}$ that estimates KV pairs importance by predicting how future queries will attend to them. Our approach leverages the distributional properties of LLM activations to compute expected attention scores in closed form for each KV pair. These scores enable principled ranking and pruning of KV pairs with minimal impact on the residual stream, achieving effective compression without performance degradation. Importantly, our method operates seamlessly across both prefilling and decoding phases, consistently outperforming state-of-the-art baselines in both scenarios. Finally, $\textbf{we release KVPress, a comprehensive library to enable researchers to implement and benchmark KV cache compression methods, already including more than 20 techniques}$.
Adaptive Semantic Token Communication for Transformer-based Edge Inference
May 23, 2025
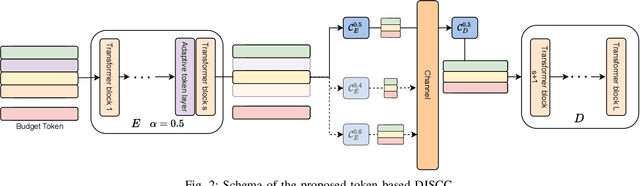


This paper presents an adaptive framework for edge inference based on a dynamically configurable transformer-powered deep joint source channel coding (DJSCC) architecture. Motivated by a practical scenario where a resource constrained edge device engages in goal oriented semantic communication, such as selectively transmitting essential features for object detection to an edge server, our approach enables efficient task aware data transmission under varying bandwidth and channel conditions. To achieve this, input data is tokenized into compact high level semantic representations, refined by a transformer, and transmitted over noisy wireless channels. As part of the DJSCC pipeline, we employ a semantic token selection mechanism that adaptively compresses informative features into a user specified number of tokens per sample. These tokens are then further compressed through the JSCC module, enabling a flexible token communication strategy that adjusts both the number of transmitted tokens and their embedding dimensions. We incorporate a resource allocation algorithm based on Lyapunov stochastic optimization to enhance robustness under dynamic network conditions, effectively balancing compression efficiency and task performance. Experimental results demonstrate that our system consistently outperforms existing baselines, highlighting its potential as a strong foundation for AI native semantic communication in edge intelligence applications.
Q-Filters: Leveraging QK Geometry for Efficient KV Cache Compression
Mar 04, 2025Autoregressive language models rely on a Key-Value (KV) Cache, which avoids re-computing past hidden states during generation, making it faster. As model sizes and context lengths grow, the KV Cache becomes a significant memory bottleneck, which calls for compression methods that limit its size during generation. In this paper, we discover surprising properties of Query (Q) and Key (K) vectors that allow us to efficiently approximate attention scores without computing the attention maps. We propose Q-Filters, a training-free KV Cache compression method that filters out less crucial Key-Value pairs based on a single context-agnostic projection. Contrarily to many alternatives, Q-Filters is compatible with FlashAttention, as it does not require direct access to attention weights. Experimental results in long-context settings demonstrate that Q-Filters is competitive with attention-based compression methods such as SnapKV in retrieval tasks while consistently outperforming efficient compression schemes such as Streaming-LLM in generation setups. Notably, Q-Filters achieves a 99% accuracy in the needle-in-a-haystack task with a x32 compression level while reducing the generation perplexity drop by up to 65% in text generation compared to Streaming-LLM.
Mixture-of-Experts Graph Transformers for Interpretable Particle Collision Detection
Jan 08, 2025



The Large Hadron Collider at CERN produces immense volumes of complex data from high-energy particle collisions, demanding sophisticated analytical techniques for effective interpretation. Neural Networks, including Graph Neural Networks, have shown promise in tasks such as event classification and object identification by representing collisions as graphs. However, while Graph Neural Networks excel in predictive accuracy, their "black box" nature often limits their interpretability, making it difficult to trust their decision-making processes. In this paper, we propose a novel approach that combines a Graph Transformer model with Mixture-of-Expert layers to achieve high predictive performance while embedding interpretability into the architecture. By leveraging attention maps and expert specialization, the model offers insights into its internal decision-making, linking predictions to physics-informed features. We evaluate the model on simulated events from the ATLAS experiment, focusing on distinguishing rare Supersymmetric signal events from Standard Model background. Our results highlight that the model achieves competitive classification accuracy while providing interpretable outputs that align with known physics, demonstrating its potential as a robust and transparent tool for high-energy physics data analysis. This approach underscores the importance of explainability in machine learning methods applied to high energy physics, offering a path toward greater trust in AI-driven discoveries.
Goal-oriented Communications based on Recursive Early Exit Neural Networks
Dec 27, 2024

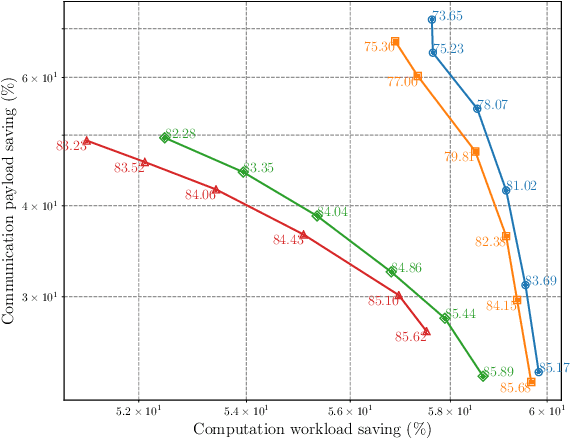
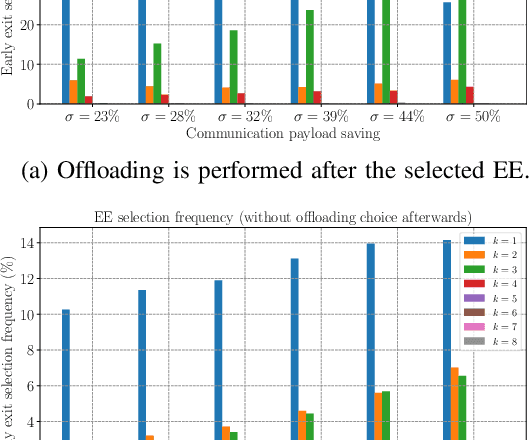
This paper presents a novel framework for goal-oriented semantic communications leveraging recursive early exit models. The proposed approach is built on two key components. First, we introduce an innovative early exit strategy that dynamically partitions computations, enabling samples to be offloaded to a server based on layer-wise recursive prediction dynamics that detect samples for which the confidence is not increasing fast enough over layers. Second, we develop a Reinforcement Learning-based online optimization framework that jointly determines early exit points, computation splitting, and offloading strategies, while accounting for wireless conditions, inference accuracy, and resource costs. Numerical evaluations in an edge inference scenario demonstrate the method's adaptability and effectiveness in striking an excellent trade-off between performance, latency, and resource efficiency.
Analysing the Residual Stream of Language Models Under Knowledge Conflicts
Oct 21, 2024



Large language models (LLMs) can store a significant amount of factual knowledge in their parameters. However, their parametric knowledge may conflict with the information provided in the context. Such conflicts can lead to undesirable model behaviour, such as reliance on outdated or incorrect information. In this work, we investigate whether LLMs can identify knowledge conflicts and whether it is possible to know which source of knowledge the model will rely on by analysing the residual stream of the LLM. Through probing tasks, we find that LLMs can internally register the signal of knowledge conflict in the residual stream, which can be accurately detected by probing the intermediate model activations. This allows us to detect conflicts within the residual stream before generating the answers without modifying the input or model parameters. Moreover, we find that the residual stream shows significantly different patterns when the model relies on contextual knowledge versus parametric knowledge to resolve conflicts. This pattern can be employed to estimate the behaviour of LLMs when conflict happens and prevent unexpected answers before producing the answers. Our analysis offers insights into how LLMs internally manage knowledge conflicts and provides a foundation for developing methods to control the knowledge selection processes.
Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering
Oct 21, 2024



Large language models (LLMs) can store a significant amount of factual knowledge in their parameters. However, their parametric knowledge may conflict with the information provided in the context -- this phenomenon, known as \emph{context-memory knowledge conflicts}, can lead to undesirable model behaviour, such as reliance on outdated or incorrect information. Analysing the internal activations of LLMs, we find that they can internally register the signals of knowledge conflict at mid-layers. Such signals allow us to detect whether a knowledge conflict occurs and use \emph{inference-time} intervention strategies to resolve it. In this work, we propose \textsc{SpARE}, a \emph{training-free} representation engineering method that uses pre-trained sparse auto-encoders (SAEs) to control the knowledge selection behaviour of LLMs. \textsc{SpARE} identifies the functional features that control the knowledge selection behaviours and applies them to edit the internal activations of LLMs at inference time. Our experimental results show that \textsc{SpARE} can effectively control the usage of either knowledge source to resolve knowledge conflict in open-domain question-answering tasks, surpassing existing representation engineering methods ($+10\%$) as well as contrastive decoding methods ($+15\%$).
Adaptive Layer Selection for Efficient Vision Transformer Fine-Tuning
Aug 16, 2024



Recently, foundation models based on Vision Transformers (ViTs) have become widely available. However, their fine-tuning process is highly resource-intensive, and it hinders their adoption in several edge or low-energy applications. To this end, in this paper we introduce an efficient fine-tuning method for ViTs called $\textbf{ALaST}$ ($\textit{Adaptive Layer Selection Fine-Tuning for Vision Transformers}$) to speed up the fine-tuning process while reducing computational cost, memory load, and training time. Our approach is based on the observation that not all layers are equally critical during fine-tuning, and their importance varies depending on the current mini-batch. Therefore, at each fine-tuning step, we adaptively estimate the importance of all layers and we assign what we call ``compute budgets'' accordingly. Layers that were allocated lower budgets are either trained with a reduced number of input tokens or kept frozen. Freezing a layer reduces the computational cost and memory usage by preventing updates to its weights, while discarding tokens removes redundant data, speeding up processing and reducing memory requirements. We show that this adaptive compute allocation enables a nearly-optimal schedule for distributing computational resources across layers, resulting in substantial reductions in training time (up to 1.5x), FLOPs (up to 2x), and memory load (up to 2x) compared to traditional full fine-tuning approaches. Additionally, it can be successfully combined with other parameter-efficient fine-tuning methods, such as LoRA.
A Simple and Effective $L_2$ Norm-Based Strategy for KV Cache Compression
Jun 17, 2024



The deployment of large language models (LLMs) is often hindered by the extensive memory requirements of the Key-Value (KV) cache, especially as context lengths increase. Existing approaches to reduce the KV cache size involve either fine-tuning the model to learn a compression strategy or leveraging attention scores to reduce the sequence length. We analyse the attention distributions in decoder-only Transformers-based models and observe that attention allocation patterns stay consistent across most layers. Surprisingly, we find a clear correlation between the $L_2$ and the attention scores over cached KV pairs, where a low $L_2$ of a key embedding usually leads to a high attention score during decoding. This finding indicates that the influence of a KV pair is potentially determined by the key embedding itself before being queried. Based on this observation, we compress the KV cache based on the $L_2$ of key embeddings. Our experimental results show that this simple strategy can reduce the KV cache size by 50% on language modelling and needle-in-a-haystack tasks and 90% on passkey retrieval tasks without losing accuracy.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.