 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHAGE: Patent Heterogeneous Attention-Guided Graph Encoder for Representation Learning
May 11, 2026Patent claims form a directed dependency structure in which dependent claims inherit and refine the scope of earlier claims; however, existing patent encoders linearize claims as text and discard this hierarchy. Directly encoding this structure into self-attention poses two challenges: claim dependencies mix relation types that differ in semantics and extraction reliability, and the dependency graph is defined over claims while Transformers attend over tokens. PHAGE addresses the first challenge through a deterministic graph construction pipeline that separates near-deterministic legal citations from noisier rule-based technical relations, preserving type distinctions as heterogeneous edges. It addresses the second through a connectivity mask and learnable relation-aware biases that lift claim-level topology into token-level attention, allowing the encoder to differentially weight each relation type. A dual-granularity contrastive objective then aligns representations with both inter-patent taxonomy and intra-patent topology. PHAGE outperforms all baselines on classification, retrieval, and clustering, showing that intra-document claim topology is a stronger inductive bias than inter-document structure and that this bias persists in the encoder weights after training.
Adaptive Cost-Efficient Evaluation for Reliable Patent Claim Validation
Apr 05, 2026Automated validation of patent claims demands zero-defect tolerance, as even a single structural flaw can render a claim legally defective. Existing evaluation paradigms suffer from a rigidity-resource dilemma: lightweight encoders struggle with nuanced legal dependencies, while exhaustive verification via Large Language Models (LLMs) is prohibitively costly. To bridge this gap, we propose ACE (Adaptive Cost-efficient Evaluation), a hybrid framework that uses predictive entropy to route only high-uncertainty claims to an expert LLM. The expert then executes a Chain of Patent Thought (CoPT) protocol grounded in 35 U.S.C. statutory standards. This design enables ACE to handle long-range legal dependencies more effectively while preserving efficiency. ACE achieves the best F1 among the evaluated methods at 94.95\%, while reducing operational costs by 78\% compared to standalone LLM deployments. We also construct ACE-40k, a 40,000-claim benchmark with MPEP-grounded error annotations, to facilitate further research.
Who Wrote the Book? Detecting and Attributing LLM Ghostwriters
Mar 30, 2026In this paper, we introduce GhostWriteBench, a dataset for LLM authorship attribution. It comprises long-form texts (50K+ words per book) generated by frontier LLMs, and is designed to test generalisation across multiple out-of-distribution (OOD) dimensions, including domain and unseen LLM author. We also propose TRACE -- a novel fingerprinting method that is interpretable and lightweight -- that works for both open- and closed-source models. TRACE creates the fingerprint by capturing token-level transition patterns (e.g., word rank) estimated by another lightweight language model. Experiments on GhostWriteBench demonstrate that TRACE achieves state-of-the-art performance, remains robust in OOD settings, and works well in limited training data scenarios.
Beyond Theoretical Bounds: Empirical Privacy Loss Calibration for Text Rewriting Under Local Differential Privacy
Mar 24, 2026The growing use of large language models has increased interest in sharing textual data in a privacy-preserving manner. One prominent line of work addresses this challenge through text rewriting under Local Differential Privacy (LDP), where input texts are locally obfuscated before release with formal privacy guarantees. These guarantees are typically expressed by a parameter $\varepsilon$ that upper bounds the worst-case privacy loss. However, nominal $\varepsilon$ values are often difficult to interpret and compare across mechanisms. In this work, we investigate how to empirically calibrate across text rewriting mechanisms under LDP. We propose TeDA, which formulates calibration via a hypothesis-testing framework that instantiates text distinguishability audits in both surface and embedding spaces, enabling empirical assessment of indistinguishability from privatized texts. Applying this calibration to several representative mechanisms, we demonstrate that similar nominal $\varepsilon$ bounds can imply very different levels of distinguishability. Empirical calibration thus provides a more comparable footing for evaluating privacy-utility trade-offs, as well as a practical tool for mechanism comparison and analysis in real-world LDP text rewriting deployments.
Fault-Tolerant Evaluation for Sample-Efficient Model Performance Estimators
Feb 06, 2026In the era of Model-as-a-Service, organizations increasingly rely on third-party AI models for rapid deployment. However, the dynamic nature of emerging AI applications, the continual introduction of new datasets, and the growing number of models claiming superior performance make efficient and reliable validation of model services increasingly challenging. This motivates the development of sample-efficient performance estimators, which aim to estimate model performance by strategically selecting instances for labeling, thereby reducing annotation cost. Yet existing evaluation approaches often fail in low-variance settings: RMSE conflates bias and variance, masking persistent bias when variance is small, while p-value based tests become hypersensitive, rejecting adequate estimators for negligible deviations. To address this, we propose a fault-tolerant evaluation framework that integrates bias and variance considerations within an adjustable tolerance level ${\varepsilon}$, enabling the evaluation of performance estimators within practically acceptable error margins. We theoretically show that proper calibration of ${\varepsilon}$ ensures reliable evaluation across different variance regimes, and we further propose an algorithm that automatically optimizes and selects ${\varepsilon}$. Experiments on real-world datasets demonstrate that our framework provides comprehensive and actionable insights into estimator behavior.
Semantic Leakage from Image Embeddings
Jan 30, 2026Image embeddings are generally assumed to pose limited privacy risk. We challenge this assumption by formalizing semantic leakage as the ability to recover semantic structures from compressed image embeddings. Surprisingly, we show that semantic leakage does not require exact reconstruction of the original image. Preserving local semantic neighborhoods under embedding alignment is sufficient to expose the intrinsic vulnerability of image embeddings. Crucially, this preserved neighborhood structure allows semantic information to propagate through a sequence of lossy mappings. Based on this conjecture, we propose Semantic Leakage from Image Embeddings (SLImE), a lightweight inference framework that reveals semantic information from standalone compressed image embeddings, incorporating a locally trained semantic retriever with off-the-shelf models, without training task-specific decoders. We thoroughly validate each step of the framework empirically, from aligned embeddings to retrieved tags, symbolic representations, and grammatical and coherent descriptions. We evaluate SLImE across a range of open and closed embedding models, including GEMINI, COHERE, NOMIC, and CLIP, and demonstrate consistent recovery of semantic information across diverse inference tasks. Our results reveal a fundamental vulnerability in image embeddings, whereby the preservation of semantic neighborhoods under alignment enables semantic leakage, highlighting challenges for privacy preservation.1
PatentMind: A Multi-Aspect Reasoning Graph for Patent Similarity Evaluation
May 25, 2025Patent similarity evaluation plays a critical role in intellectual property analysis. However, existing methods often overlook the intricate structure of patent documents, which integrate technical specifications, legal boundaries, and application contexts. We introduce PatentMind, a novel framework for patent similarity assessment based on a Multi-Aspect Reasoning Graph (MARG). PatentMind decomposes patents into three core dimensions: technical feature, application domain, and claim scope, to compute dimension-specific similarity scores. These scores are dynamically weighted through a four-stage reasoning process which integrates contextual signals to emulate expert-level judgment. To support evaluation, we construct PatentSimBench, a human-annotated benchmark comprising 500 patent pairs. Experimental results demonstrate that PatentMind achieves a strong correlation ($r=0.938$) with expert annotations, significantly outperforming embedding-based models and advanced prompt engineering methods.These results highlight the effectiveness of modular reasoning frameworks in overcoming key limitations of embedding-based methods for analyzing patent similarity.
PatentScore: Multi-dimensional Evaluation of LLM-Generated Patent Claims
May 25, 2025Natural language generation (NLG) metrics play a central role in evaluating generated texts, but are not well suited for the structural and legal characteristics of patent documents. Large language models (LLMs) offer strong potential in automating patent generation, yet research on evaluating LLM-generated patents remains limited, especially in evaluating the generation quality of patent claims, which are central to defining the scope of protection. Effective claim evaluation requires addressing legal validity, technical accuracy, and structural compliance. To address this gap, we introduce PatentScore, a multi-dimensional evaluation framework for assessing LLM-generated patent claims. PatentScore incorporates: (1) hierarchical decomposition for claim analysis; (2) domain-specific validation patterns based on legal and technical standards; and (3) scoring across structural, semantic, and legal dimensions. Unlike general-purpose NLG metrics, PatentScore reflects patent-specific constraints and document structures, enabling evaluation beyond surface similarity. We evaluate 400 GPT-4o-mini generated Claim 1s and report a Pearson correlation of $r = 0.819$ with expert annotations, outperforming existing NLG metrics. Furthermore, we conduct additional evaluations using open models such as Claude-3.5-Haiku and Gemini-1.5-flash, all of which show strong correlations with expert judgments, confirming the robustness and generalizability of our framework.
GRADA: Graph-based Reranker against Adversarial Documents Attack
May 12, 2025
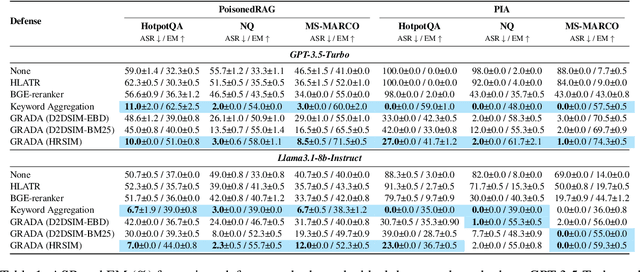
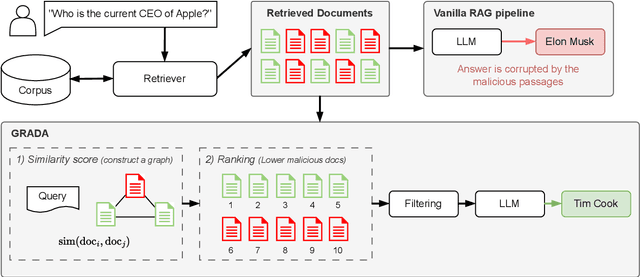
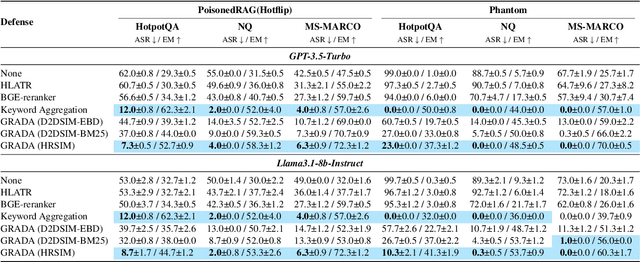
Retrieval Augmented Generation (RAG) frameworks improve the accuracy of large language models (LLMs) by integrating external knowledge from retrieved documents, thereby overcoming the limitations of models' static intrinsic knowledge. However, these systems are susceptible to adversarial attacks that manipulate the retrieval process by introducing documents that are adversarial yet semantically similar to the query. Notably, while these adversarial documents resemble the query, they exhibit weak similarity to benign documents in the retrieval set. Thus, we propose a simple yet effective Graph-based Reranking against Adversarial Document Attacks (GRADA) framework aiming at preserving retrieval quality while significantly reducing the success of adversaries. Our study evaluates the effectiveness of our approach through experiments conducted on five LLMs: GPT-3.5-Turbo, GPT-4o, Llama3.1-8b, Llama3.1-70b, and Qwen2.5-7b. We use three datasets to assess performance, with results from the Natural Questions dataset demonstrating up to an 80% reduction in attack success rates while maintaining minimal loss in accuracy.
Defending Deep Neural Networks against Backdoor Attacks via Module Switching
Apr 08, 2025The exponential increase in the parameters of Deep Neural Networks (DNNs) has significantly raised the cost of independent training, particularly for resource-constrained entities. As a result, there is a growing reliance on open-source models. However, the opacity of training processes exacerbates security risks, making these models more vulnerable to malicious threats, such as backdoor attacks, while simultaneously complicating defense mechanisms. Merging homogeneous models has gained attention as a cost-effective post-training defense. However, we notice that existing strategies, such as weight averaging, only partially mitigate the influence of poisoned parameters and remain ineffective in disrupting the pervasive spurious correlations embedded across model parameters. We propose a novel module-switching strategy to break such spurious correlations within the model's propagation path. By leveraging evolutionary algorithms to optimize fusion strategies, we validate our approach against backdoor attacks targeting text and vision domains. Our method achieves effective backdoor mitigation even when incorporating a couple of compromised models, e.g., reducing the average attack success rate (ASR) to 22% compared to 31.9% with the best-performing baseline on SST-2.