 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Mitigating Interference in Neural Architecture Search
Aug 29, 2021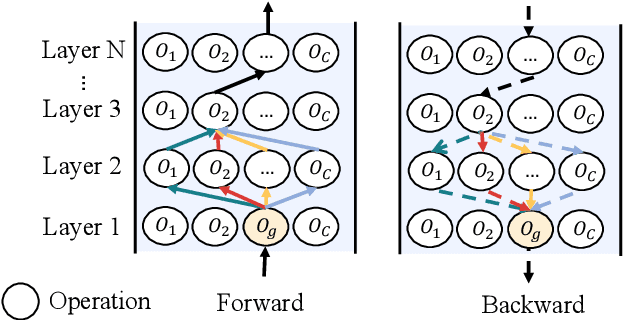
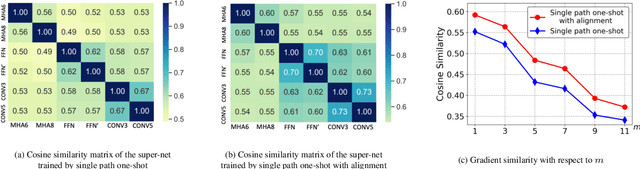
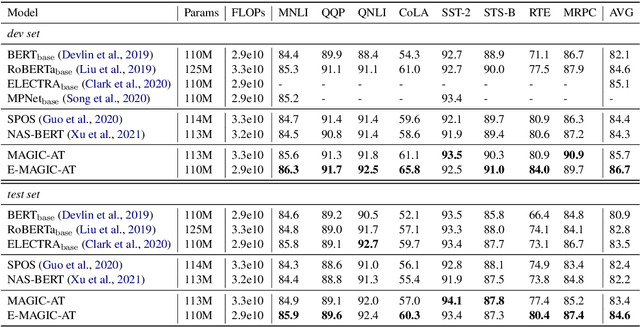
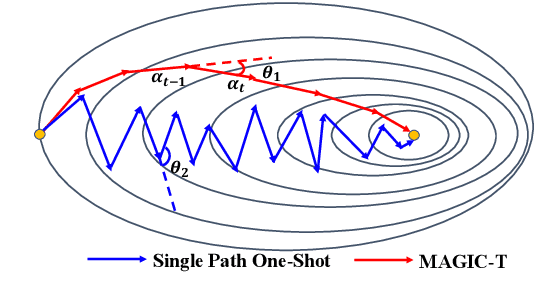
Weight sharing has become the \textit{de facto} approach to reduce the training cost of neural architecture search (NAS) by reusing the weights of shared operators from previously trained child models. However, the estimated accuracy of those child models has a low rank correlation with the ground truth accuracy due to the interference among different child models caused by weight sharing. In this paper, we investigate the interference issue by sampling different child models and calculating the gradient similarity of shared operators, and observe that: 1) the interference on a shared operator between two child models is positively correlated to the number of different operators between them; 2) the interference is smaller when the inputs and outputs of the shared operator are more similar. Inspired by these two observations, we propose two approaches to mitigate the interference: 1) rather than randomly sampling child models for optimization, we propose a gradual modification scheme by modifying one operator between adjacent optimization steps to minimize the interference on the shared operators; 2) forcing the inputs and outputs of the operator across all child models to be similar to reduce the interference. Experiments on a BERT search space verify that mitigating interference via each of our proposed methods improves the rank correlation of super-pet and combining both methods can achieve better results. Our searched architecture outperforms RoBERTa$_{\rm base}$ by 1.1 and 0.6 scores and ELECTRA$_{\rm base}$ by 1.6 and 1.1 scores on the dev and test set of GLUE benchmark. Extensive results on the BERT compression task, SQuAD datasets and other search spaces also demonstrate the effectiveness and generality of our proposed methods.
A Survey on Neural Speech Synthesis
Jul 23, 2021

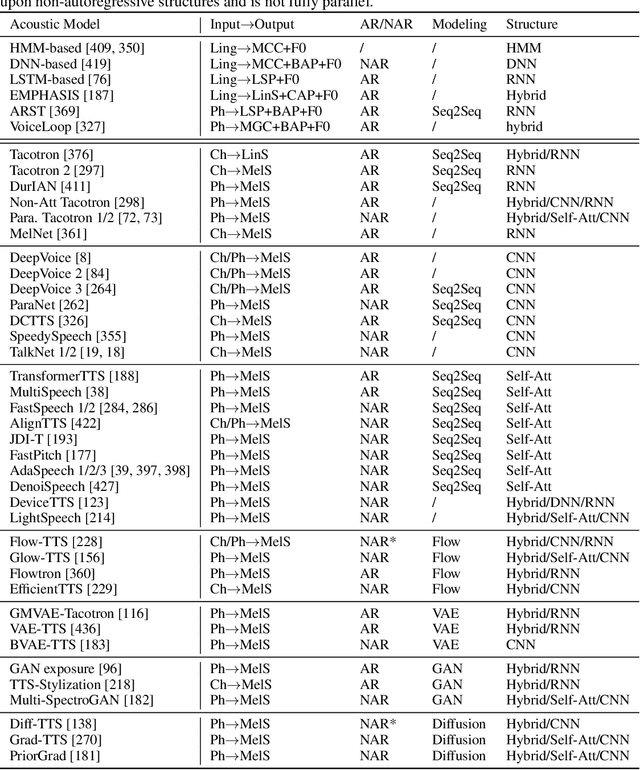
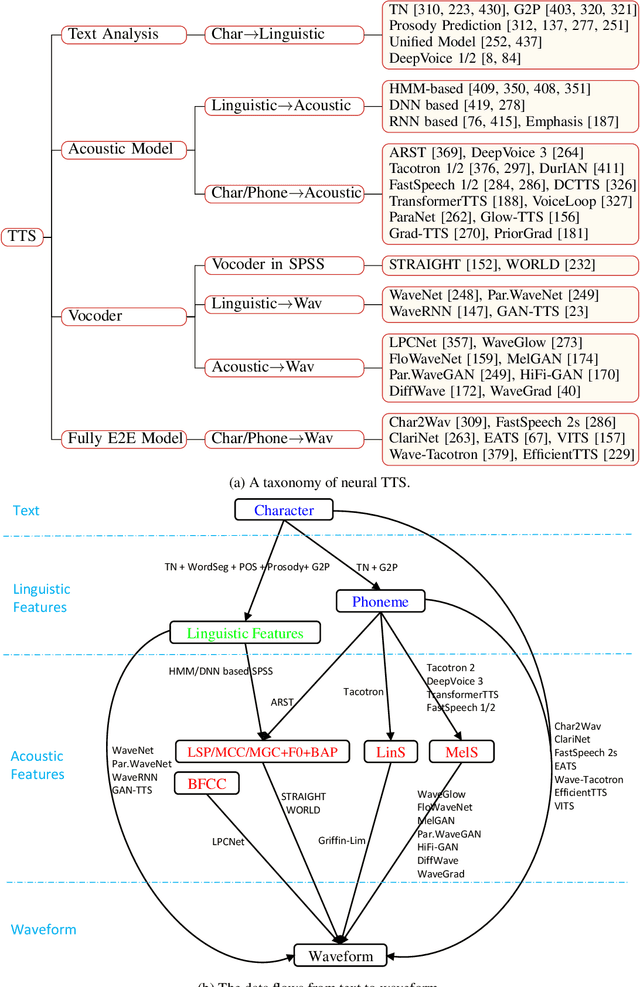
Text to speech (TTS), or speech synthesis, which aims to synthesize intelligible and natural speech given text, is a hot research topic in speech, language, and machine learning communities and has broad applications in the industry. As the development of deep learning and artificial intelligence, neural network-based TTS has significantly improved the quality of synthesized speech in recent years. In this paper, we conduct a comprehensive survey on neural TTS, aiming to provide a good understanding of current research and future trends. We focus on the key components in neural TTS, including text analysis, acoustic models and vocoders, and several advanced topics, including fast TTS, low-resource TTS, robust TTS, expressive TTS, and adaptive TTS, etc. We further summarize resources related to TTS (e.g., datasets, opensource implementations) and discuss future research directions. This survey can serve both academic researchers and industry practitioners working on TTS.
A Survey on Low-Resource Neural Machine Translation
Jul 09, 2021



Neural approaches have achieved state-of-the-art accuracy on machine translation but suffer from the high cost of collecting large scale parallel data. Thus, a lot of research has been conducted for neural machine translation (NMT) with very limited parallel data, i.e., the low-resource setting. In this paper, we provide a survey for low-resource NMT and classify related works into three categories according to the auxiliary data they used: (1) exploiting monolingual data of source and/or target languages, (2) exploiting data from auxiliary languages, and (3) exploiting multi-modal data. We hope that our survey can help researchers to better understand this field and inspire them to design better algorithms, and help industry practitioners to choose appropriate algorithms for their applications.
AdaSpeech 3: Adaptive Text to Speech for Spontaneous Style
Jul 06, 2021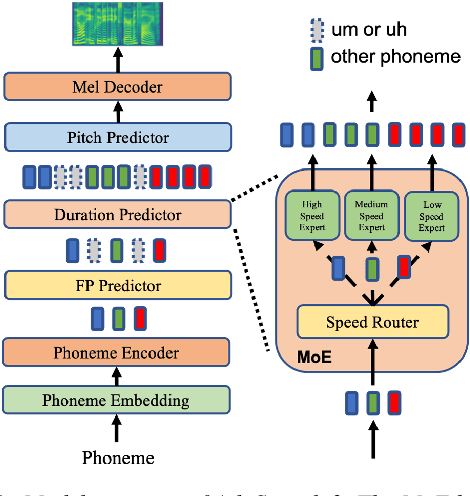
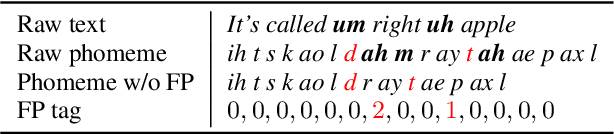

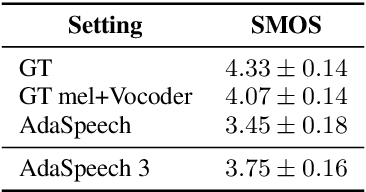
While recent text to speech (TTS) models perform very well in synthesizing reading-style (e.g., audiobook) speech, it is still challenging to synthesize spontaneous-style speech (e.g., podcast or conversation), mainly because of two reasons: 1) the lack of training data for spontaneous speech; 2) the difficulty in modeling the filled pauses (um and uh) and diverse rhythms in spontaneous speech. In this paper, we develop AdaSpeech 3, an adaptive TTS system that fine-tunes a well-trained reading-style TTS model for spontaneous-style speech. Specifically, 1) to insert filled pauses (FP) in the text sequence appropriately, we introduce an FP predictor to the TTS model; 2) to model the varying rhythms, we introduce a duration predictor based on mixture of experts (MoE), which contains three experts responsible for the generation of fast, medium and slow speech respectively, and fine-tune it as well as the pitch predictor for rhythm adaptation; 3) to adapt to other speaker timbre, we fine-tune some parameters in the decoder with few speech data. To address the challenge of lack of training data, we mine a spontaneous speech dataset to support our research this work and facilitate future research on spontaneous TTS. Experiments show that AdaSpeech 3 synthesizes speech with natural FP and rhythms in spontaneous styles, and achieves much better MOS and SMOS scores than previous adaptive TTS systems.
DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling
Jul 05, 2021
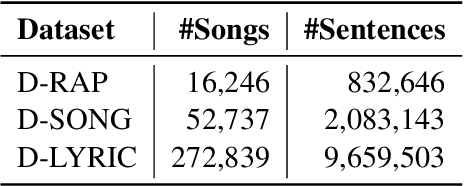
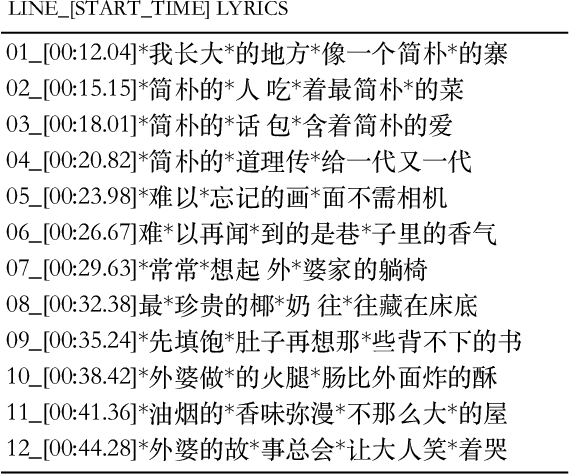

Rap generation, which aims to produce lyrics and corresponding singing beats, needs to model both rhymes and rhythms. Previous works for rap generation focused on rhyming lyrics but ignored rhythmic beats, which are important for rap performance. In this paper, we develop DeepRapper, a Transformer-based rap generation system that can model both rhymes and rhythms. Since there is no available rap dataset with rhythmic beats, we develop a data mining pipeline to collect a large-scale rap dataset, which includes a large number of rap songs with aligned lyrics and rhythmic beats. Second, we design a Transformer-based autoregressive language model which carefully models rhymes and rhythms. Specifically, we generate lyrics in the reverse order with rhyme representation and constraint for rhyme enhancement and insert a beat symbol into lyrics for rhythm/beat modeling. To our knowledge, DeepRapper is the first system to generate rap with both rhymes and rhythms. Both objective and subjective evaluations demonstrate that DeepRapper generates creative and high-quality raps with rhymes and rhythms. Code will be released on GitHub.
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Driven Adaptive Prior
Jun 11, 2021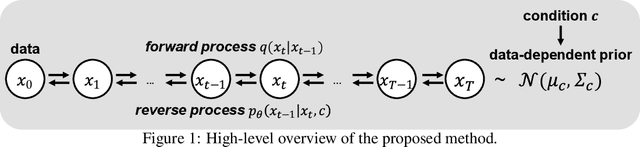
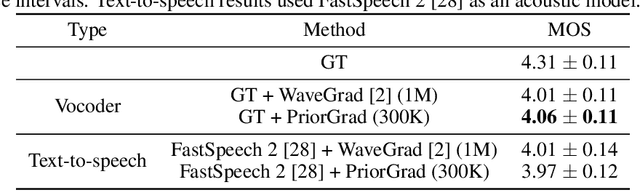


Denoising diffusion probabilistic models have been recently proposed to generate high-quality samples by estimating the gradient of the data density. The framework assumes the prior noise as a standard Gaussian distribution, whereas the corresponding data distribution may be more complicated than the standard Gaussian distribution, which potentially introduces inefficiency in denoising the prior noise into the data sample because of the discrepancy between the data and the prior. In this paper, we propose PriorGrad to improve the efficiency of the conditional diffusion model (for example, a vocoder using a mel-spectrogram as the condition) by applying an adaptive prior derived from the data statistics based on the conditional information. We formulate the training and sampling procedures of PriorGrad and demonstrate the advantages of an adaptive prior through a theoretical analysis. Focusing on the audio domain, we consider the recently proposed diffusion-based audio generative models based on both the spectral and time domains and show that PriorGrad achieves a faster convergence leading to data and parameter efficiency and improved quality, and thereby demonstrating the efficiency of a data-driven adaptive prior.
MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training
Jun 10, 2021
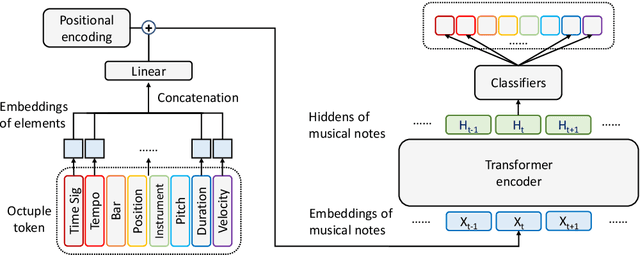
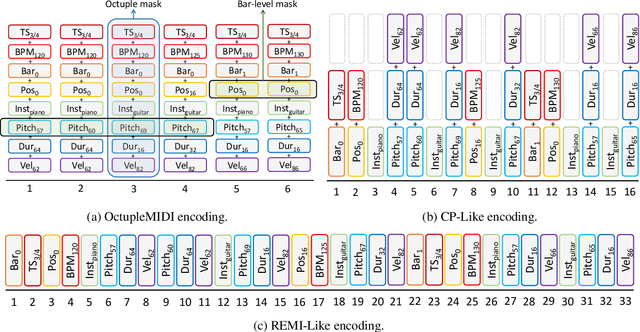
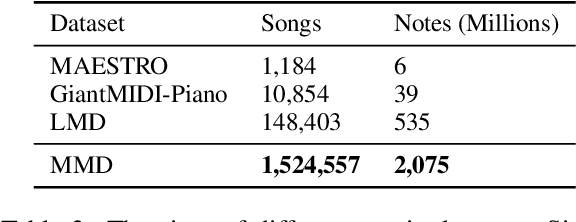
Symbolic music understanding, which refers to the understanding of music from the symbolic data (e.g., MIDI format, but not audio), covers many music applications such as genre classification, emotion classification, and music pieces matching. While good music representations are beneficial for these applications, the lack of training data hinders representation learning. Inspired by the success of pre-training models in natural language processing, in this paper, we develop MusicBERT, a large-scale pre-trained model for music understanding. To this end, we construct a large-scale symbolic music corpus that contains more than 1 million music songs. Since symbolic music contains more structural (e.g., bar, position) and diverse information (e.g., tempo, instrument, and pitch), simply adopting the pre-training techniques from NLP to symbolic music only brings marginal gains. Therefore, we design several mechanisms, including OctupleMIDI encoding and bar-level masking strategy, to enhance pre-training with symbolic music data. Experiments demonstrate the advantages of MusicBERT on four music understanding tasks, including melody completion, accompaniment suggestion, genre classification, and style classification. Ablation studies also verify the effectiveness of our designs of OctupleMIDI encoding and bar-level masking strategy in MusicBERT.
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
Jun 03, 2021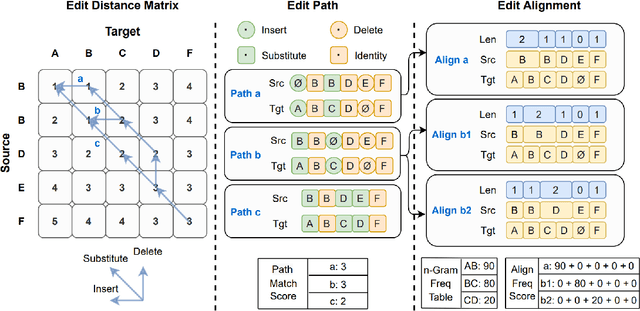
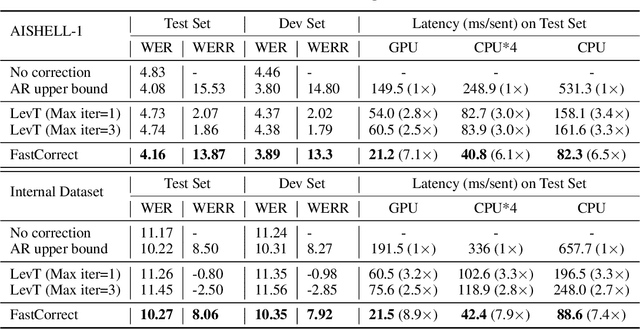
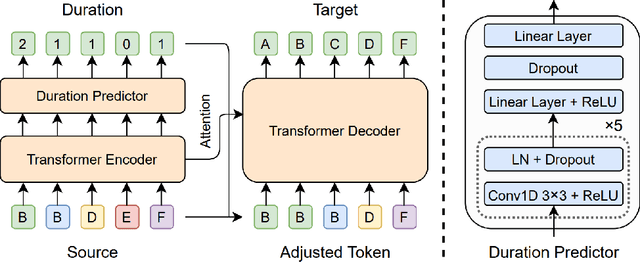
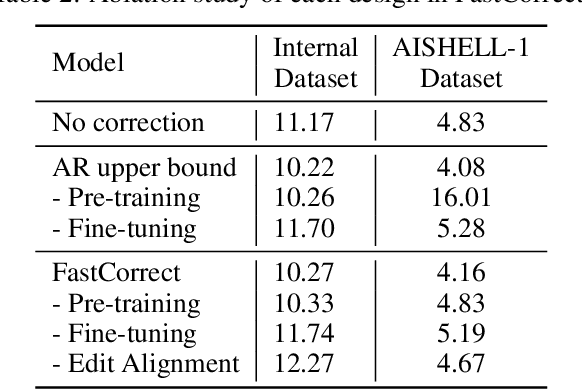
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the popular NAR models adopted in neural machine translation and text edition by a large margin.
NAS-BERT: Task-Agnostic and Adaptive-Size BERT Compression with Neural Architecture Search
May 30, 2021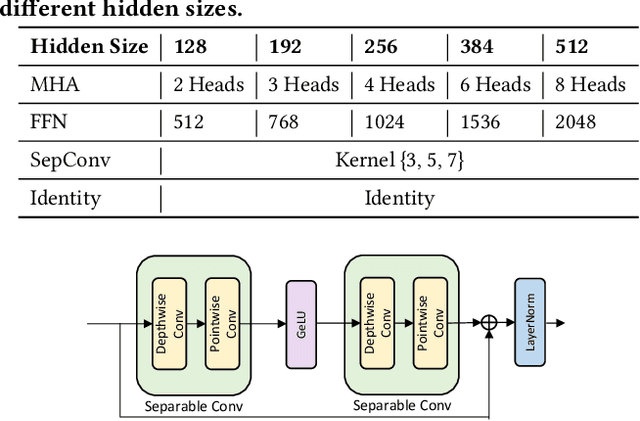
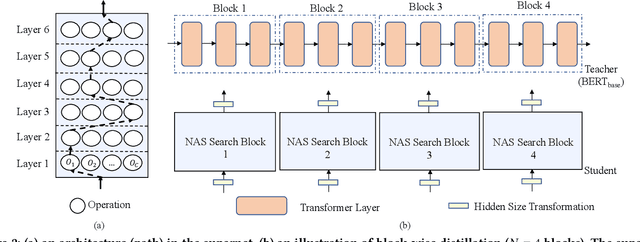
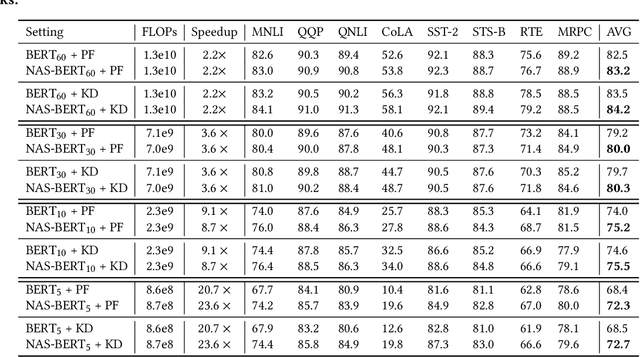
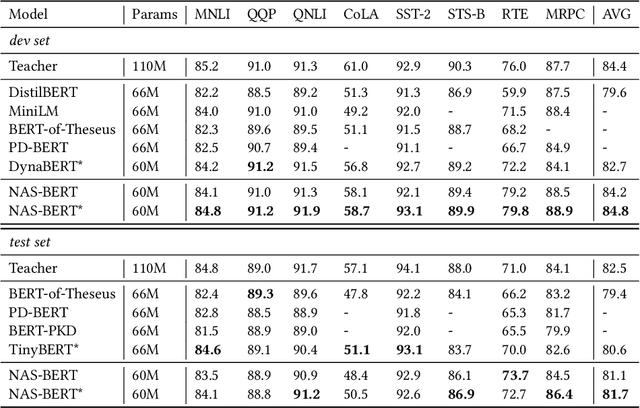
While pre-trained language models (e.g., BERT) have achieved impressive results on different natural language processing tasks, they have large numbers of parameters and suffer from big computational and memory costs, which make them difficult for real-world deployment. Therefore, model compression is necessary to reduce the computation and memory cost of pre-trained models. In this work, we aim to compress BERT and address the following two challenging practical issues: (1) The compression algorithm should be able to output multiple compressed models with different sizes and latencies, in order to support devices with different memory and latency limitations; (2) The algorithm should be downstream task agnostic, so that the compressed models are generally applicable for different downstream tasks. We leverage techniques in neural architecture search (NAS) and propose NAS-BERT, an efficient method for BERT compression. NAS-BERT trains a big supernet on a search space containing a variety of architectures and outputs multiple compressed models with adaptive sizes and latency. Furthermore, the training of NAS-BERT is conducted on standard self-supervised pre-training tasks (e.g., masked language model) and does not depend on specific downstream tasks. Thus, the compressed models can be used across various downstream tasks. The technical challenge of NAS-BERT is that training a big supernet on the pre-training task is extremely costly. We employ several techniques including block-wise search, search space pruning, and performance approximation to improve search efficiency and accuracy. Extensive experiments on GLUE and SQuAD benchmark datasets demonstrate that NAS-BERT can find lightweight models with better accuracy than previous approaches, and can be directly applied to different downstream tasks with adaptive model sizes for different requirements of memory or latency.
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
Apr 20, 2021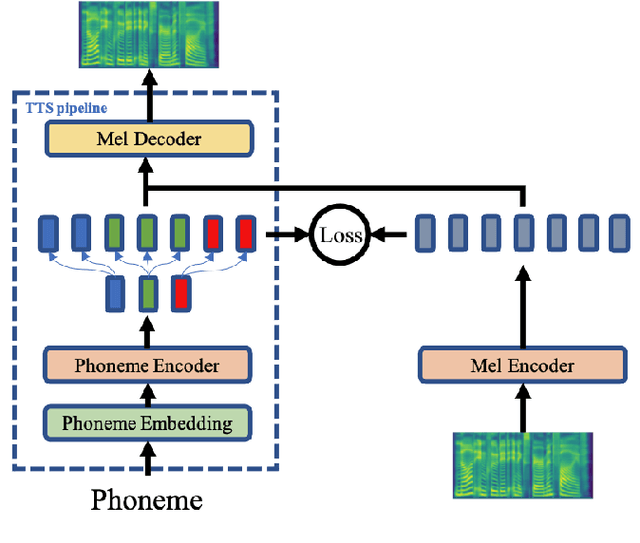
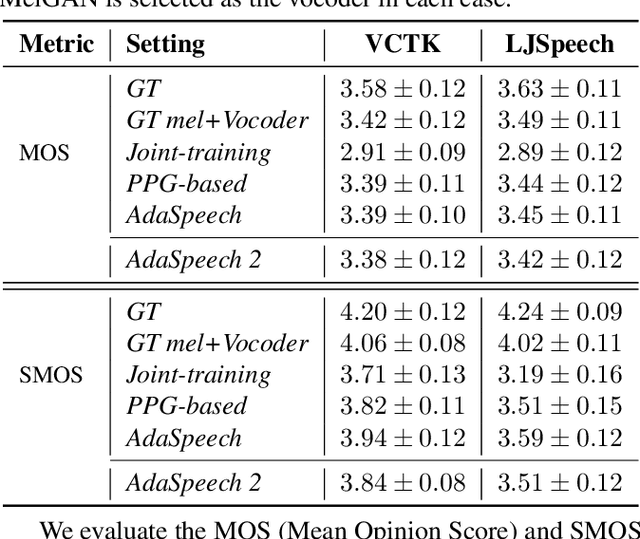
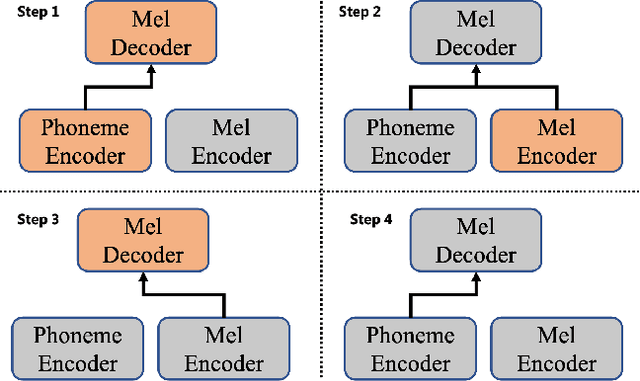

Text to speech (TTS) is widely used to synthesize personal voice for a target speaker, where a well-trained source TTS model is fine-tuned with few paired adaptation data (speech and its transcripts) on this target speaker. However, in many scenarios, only untranscribed speech data is available for adaptation, which brings challenges to the previous TTS adaptation pipelines (e.g., AdaSpeech). In this paper, we develop AdaSpeech 2, an adaptive TTS system that only leverages untranscribed speech data for adaptation. Specifically, we introduce a mel-spectrogram encoder to a well-trained TTS model to conduct speech reconstruction, and at the same time constrain the output sequence of the mel-spectrogram encoder to be close to that of the original phoneme encoder. In adaptation, we use untranscribed speech data for speech reconstruction and only fine-tune the TTS decoder. AdaSpeech 2 has two advantages: 1) Pluggable: our system can be easily applied to existing trained TTS models without re-training. 2) Effective: our system achieves on-par voice quality with the transcribed TTS adaptation (e.g., AdaSpeech) with the same amount of untranscribed data, and achieves better voice quality than previous untranscribed adaptation methods. Synthesized speech samples can be found at https://speechresearch.github.io/adaspeech2/.