 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIS-MAE: A Self-Supervised Modulation Classification Method Based on Raw IQ Signals and Masked Autoencoder
Aug 01, 2025Automatic modulation classification (AMC) is a basic technology in intelligent wireless communication systems. It is important for tasks such as spectrum monitoring, cognitive radio, and secure communications. In recent years, deep learning methods have made great progress in AMC. However, mainstream methods still face two key problems. First, they often use time-frequency images instead of raw signals. This causes loss of key modulation features and reduces adaptability to different communication conditions. Second, most methods rely on supervised learning. This needs a large amount of labeled data, which is hard to get in real-world environments. To solve these problems, we propose a self-supervised learning framework called RIS-MAE. RIS-MAE uses masked autoencoders to learn signal features from unlabeled data. It takes raw IQ sequences as input. By applying random masking and reconstruction, it captures important time-domain features such as amplitude, phase, etc. This helps the model learn useful and transferable representations. RIS-MAE is tested on four datasets. The results show that it performs better than existing methods in few-shot and cross-domain tasks. Notably, it achieves high classification accuracy on previously unseen datasets with only a small number of fine-tuning samples, confirming its generalization ability and potential for real-world deployment.
Structure Learning of Deep Networks via DNA Computing Algorithm
Oct 25, 2018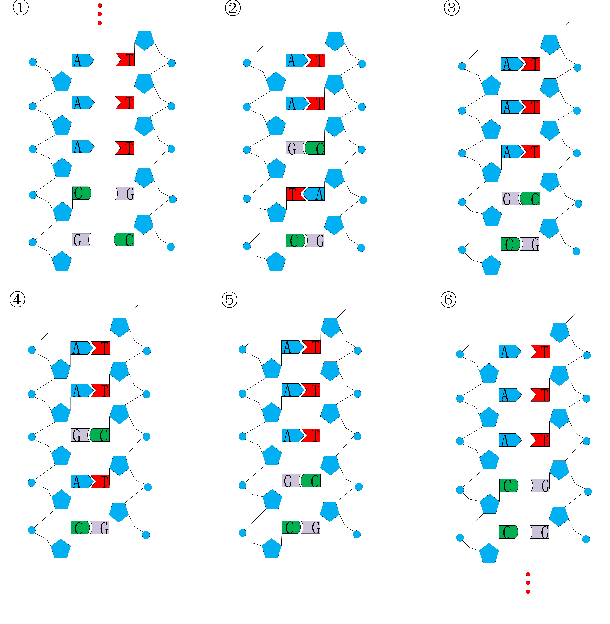
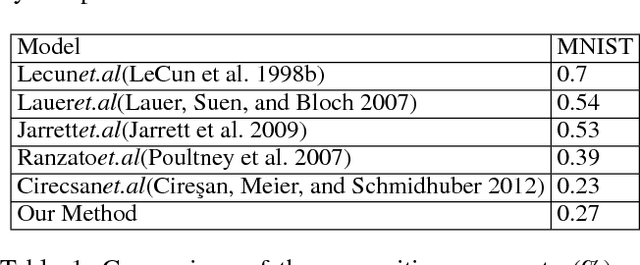
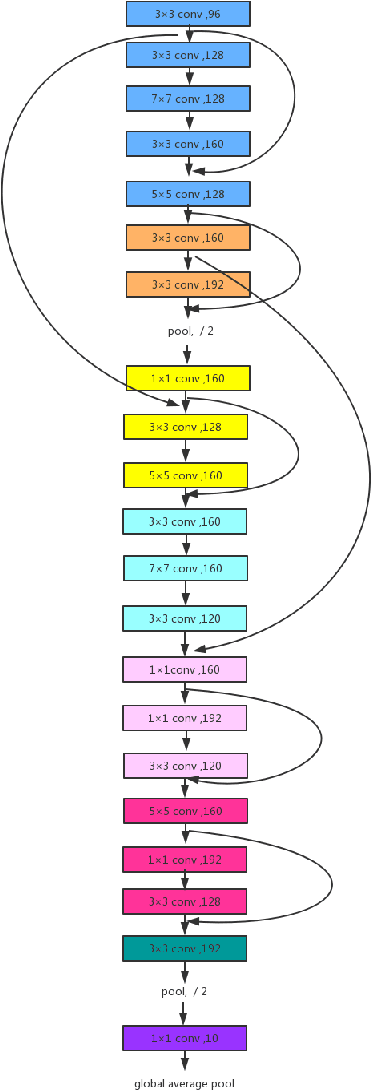
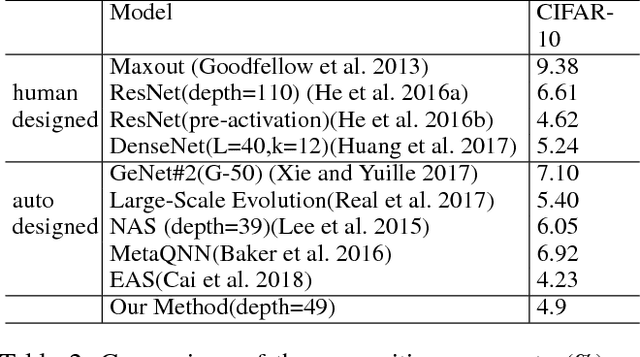
Convolutional Neural Network (CNN) has gained state-of-the-art results in many pattern recognition and computer vision tasks. However, most of the CNN structures are manually designed by experienced researchers. Therefore, auto- matically building high performance networks becomes an important problem. In this paper, we introduce the idea of using DNA computing algorithm to automatically learn high-performance architectures. In DNA computing algorithm, we use short DNA strands to represent layers and long DNA strands to represent overall networks. We found that most of the learned models perform similarly, and only those performing worse during the first runs of training will perform worse finally than others. The indicates that: 1) Using DNA computing algorithm to learn deep architectures is feasible; 2) Local minima should not be a problem of deep networks; 3) We can use early stop to kill the models with the bad performance just after several runs of training. In our experiments, an accuracy 99.73% was obtained on the MNIST data set and an accuracy 95.10% was obtained on the CIFAR-10 data set.